







 本文介绍了某大健康公司在医疗大数据背景下,如何利用CloudCanal数据同步工具和StarRocks MPP数据库解决原有技术架构痛点,提升数据实时性能和降低运维成本。通过改造,他们在数据分析效率、服务器资源利用和人力成本上都得到了显著改善。
本文介绍了某大健康公司在医疗大数据背景下,如何利用CloudCanal数据同步工具和StarRocks MPP数据库解决原有技术架构痛点,提升数据实时性能和降低运维成本。通过改造,他们在数据分析效率、服务器资源利用和人力成本上都得到了显著改善。
简述
本案例为国内某大健康领域头部公司真实案例(因用户保密要求,暂不透露用户相关信息)。希望文章内容对各位读者使用 CloudCanal 构建实时数仓带来一些帮助。
业务背景
大健康背景下,用户对报表和数据大屏的实时性能要求越来越高。以核酸检测为例,检测结果需要实时统计分析,并在决策大屏中进行可视化展现。数据的及时性直接关系到区域疫情防控的精准布施从而有效防止疫情的扩散,不容半点闪失。在此之上,业务的多样性和复杂性也对公司的研发和运维成本要求也越来越高。
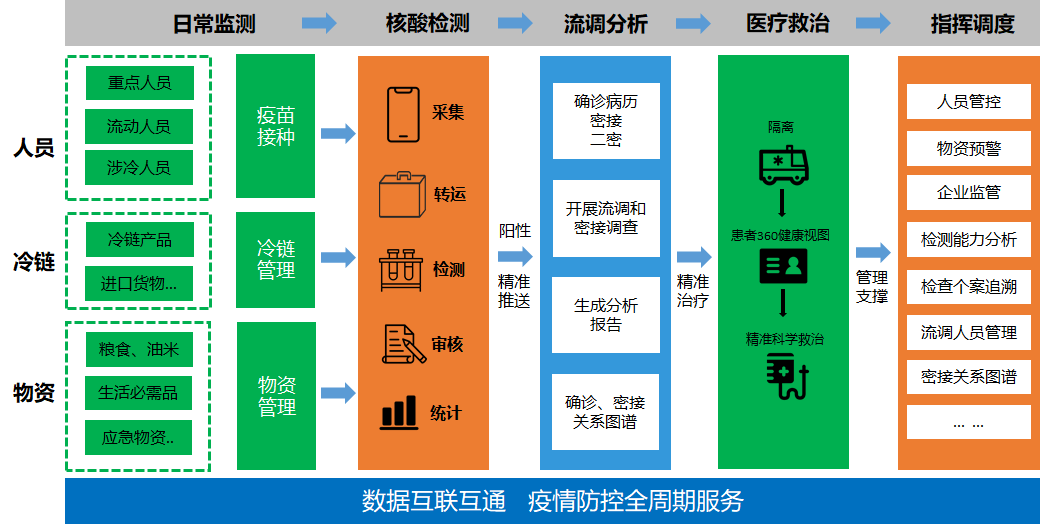
例如疫情防控指挥决策大屏中,数据包括流调溯源数据、物资冷链数据、居住人口数据、重点人群数据、风险排查、隔离管控、核酸检测数据、疫苗接种数据。这些来源数据标准不一,分散的数据引发数据冗余、数据不一致、数据应用困难等问题,导致研发和运维成本的上升,需要通过一个良好的接入层将这些数据做汇总和统一管理。
在此背景下,我司在更高效数据ETL方式以及高性能数据分析工具选型方面不断尝试和创新。通过引入了 CloudCanal 和 StarRocks,在数仓建设、实时数据分析、数据查询加速等业务上实现了效率最大化。
业务架构
我司旗下拥有多款大健康产品。虽然各款产品的具体业务不同,但是数据流的链路基本一致:数据接入->数据处理与分析->数据应用。
下面以 疫情防控系统 为例简单介绍其中数据流的生命周期:
- 数据接入:首先疫情防控系统的数据主要是三个来源、人员数据、冷链数据、物资数据。这些数据经过统一标准化处理之后才能用于分析
- 数据处理与分析:原始的数据经过整合和标准化,可以从数据分析出密接人员、密接关系图谱等信息
- 数据应用:数据处理与分析的指标可以用于实时监控大屏、以及相关预警
|-
-|
原有技术架构以及痛点
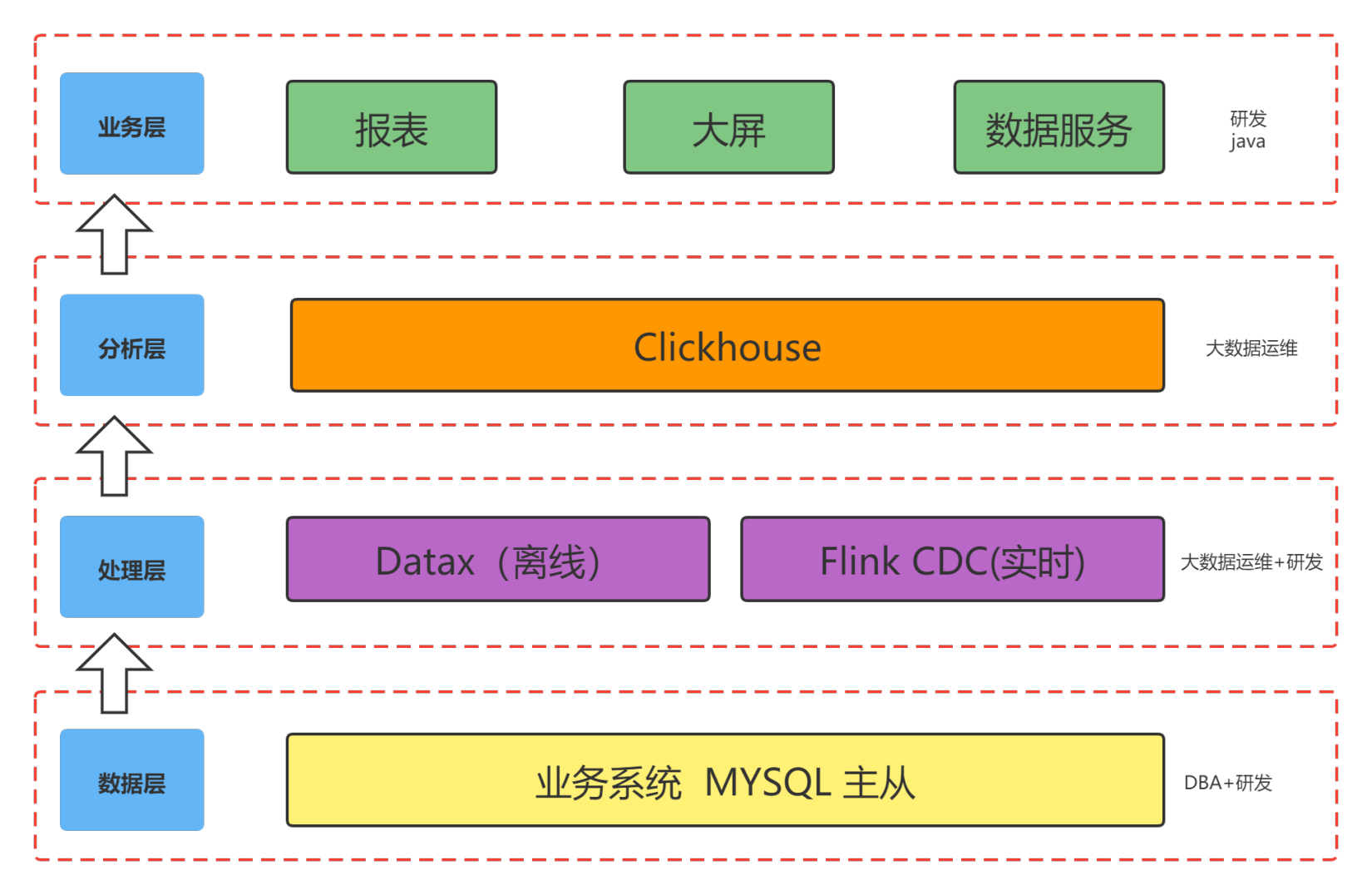
针对疫情防控系统,我们最初选择 ClickHouse 作为分析层,通过 DataX + Flink CDC 的模式实现实时+离线数据同步。随着业务的迭代,这套架构已经无法满足我们的需求。
技术架构
|-
-|
原有疫情防控的架构总体上分为四块,自底向上分别是:
-
数据层:源端数据源主要是 MySQL 为主的关系型数据库。
-
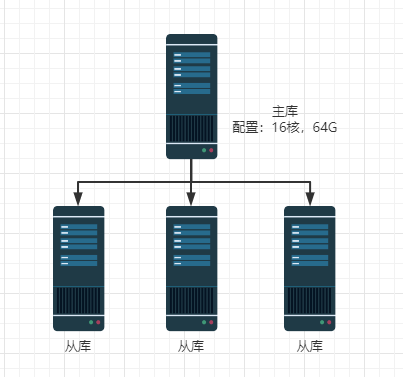
- 业务信息:以核酸检测业务功能为例,需要支撑单日 300万 核酸检测任务。要求支撑每秒 1000 并发
- 技术信息:数据层采用 MySQL 主从同步,配置级架构如下:
|-
 </
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1826
1826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









