






前言:
在达梦数据库中,存储过程和存储函数是两种非常强大的工具,它们能够封装复杂的数据库操作,提高代码的重用性和执行效率。
一、存储过程
-
定义:
- 存储过程是一组预编译的SQL语句和逻辑控制语句的集合,被存储在数据库中,可以被反复调用。
- 存储过程可以接受输入参数,根据这些参数执行不同的操作,并且可以返回输出结果(通过OUT或INOUT参数)。
-
特点:
- 可以包含多条SQL语句以及流程控制语句(如IF-ELSE、循环等)。
- 不返回值,但可以通过参数向调用者传值。
- 安全性高,源代码对用户不可见,仅需提供接口供调用。
- 执行效率高,因为存储过程经编译后以二进制代码存储在数据库中,无需每次执行都重新编译。
-
应用示例:
- 创建一个存储过程,用于查询某个表中满足特定条件的记录数。
CREATE OR REPLACE PROCEDURE count_records(
table_name VARCHAR(100),
condition VARCHAR(200)
) AS
record_count INT;
BEGIN
EXECUTE IMMEDIATE 'SELECT COUNT(*) FROM ' || table_name || ' WHERE ' || condition INTO record_count;
DBMS_OUTPUT.PUT_LINE('The number of records is: ' || record_count);
END;二、存储函数
-
定义:
- 存储函数是一种特殊的存储过程,它主要用于计算并返回一个值。
- 函数可以接受零个或多个输入参数,并且必须返回一个确定的值。
-
特点:
- 必须包含返回值定义,且执行部分内只能包含一个返回语句。
- 可以在SQL语句中直接调用,如SELECT column FROM table WHERE column = function(param1, param2)。
- 和存储过程一样,存储函数也是预编译的,执行效率高。
-
应用示例:
- 创建一个函数,用于计算两个数的和。
CREATE OR REPLACE FUNCTION add_numbers(
num1 INT,
num2 INT
) RETURN INT AS
BEGIN
RETURN num1 + num2;
END;
三、存储过程与存储函数的区别
-
返回值:
- 存储过程没有返回值,调用者只能通过访问OUT或INOUT参数来获得执行结果。
- 存储函数有返回值,它把执行结果直接返回给调用者。
-
调用方式:
- 存储过程通常通过EXEC执行。
- 存储函数可以在SQL语句中直接调用。
-
应用场景:
- 存储过程适用于实现一些复杂逻辑的批量操作。
- 存储函数通常用于实现一些单一逻辑运算,比如对数据进行计算、格式化等,并返回计算结果。
四、存储过程与存储函数的安全性和维护
-
安全性:
- 存储过程和存储函数的源代码对用户不可见,这增加了数据库操作的安全性。
- 可以通过权限管理来控制用户对存储过程和存储函数的访问。
-
维护:
- 存储过程和存储函数一旦创建,可以重复使用,减少了代码的重复编写和维护成本。
- 当数据库结构或业务逻辑发生变化时,只需要修改相应的存储过程或存储函数即可。
五、实际应用例题
以下是关于达梦数据库存储过程与存储函数应用,以及异常处理的例题
例一:
题目:
1.设计一个不带参数的存储过程p1_staffsum_bycityname,用于统计公司在各大城市的员工数之和,并显示各城市名称和总人数。
2.接着,调用该存储过程。
3.展示包括DM管理工具登录服务端的IP、DMHR模式的存储过程p1_staffsum_bycityname、设计存储过程的语句、调用存储过程的语句及返回结果。
代码如下:
CREATE OR REPLACE PROCEDURE dmhr.p1_staffsum_bycityname AS
-- 定义游标,获取城市信息
CURSOR city_cursor IS
SELECT region_id, city_id, city_name FROM dmhr.city ORDER BY region_id;
-- 定义变量用于存储员工总数
v_staffsum NUMBER;
BEGIN
-- 遍历游标
FOR city_rec IN city_cursor LOOP
-- 统计每个城市的员工总数
SELECT COUNT(a.employee_id) INTO v_staffsum FROM dmhr.employee a WHERE a.department_id IN (
SELECT department_id FROM dmhr.department WHERE location_id = city_rec.region_id);
-- 输出城市名称和员工总数
PRINT city_rec.city_name || ',' || v_staffsum;
END LOOP;
END;
-- 调用存储过程
CALL dmhr.p1_staffsum_bycityname;执行结果如下:
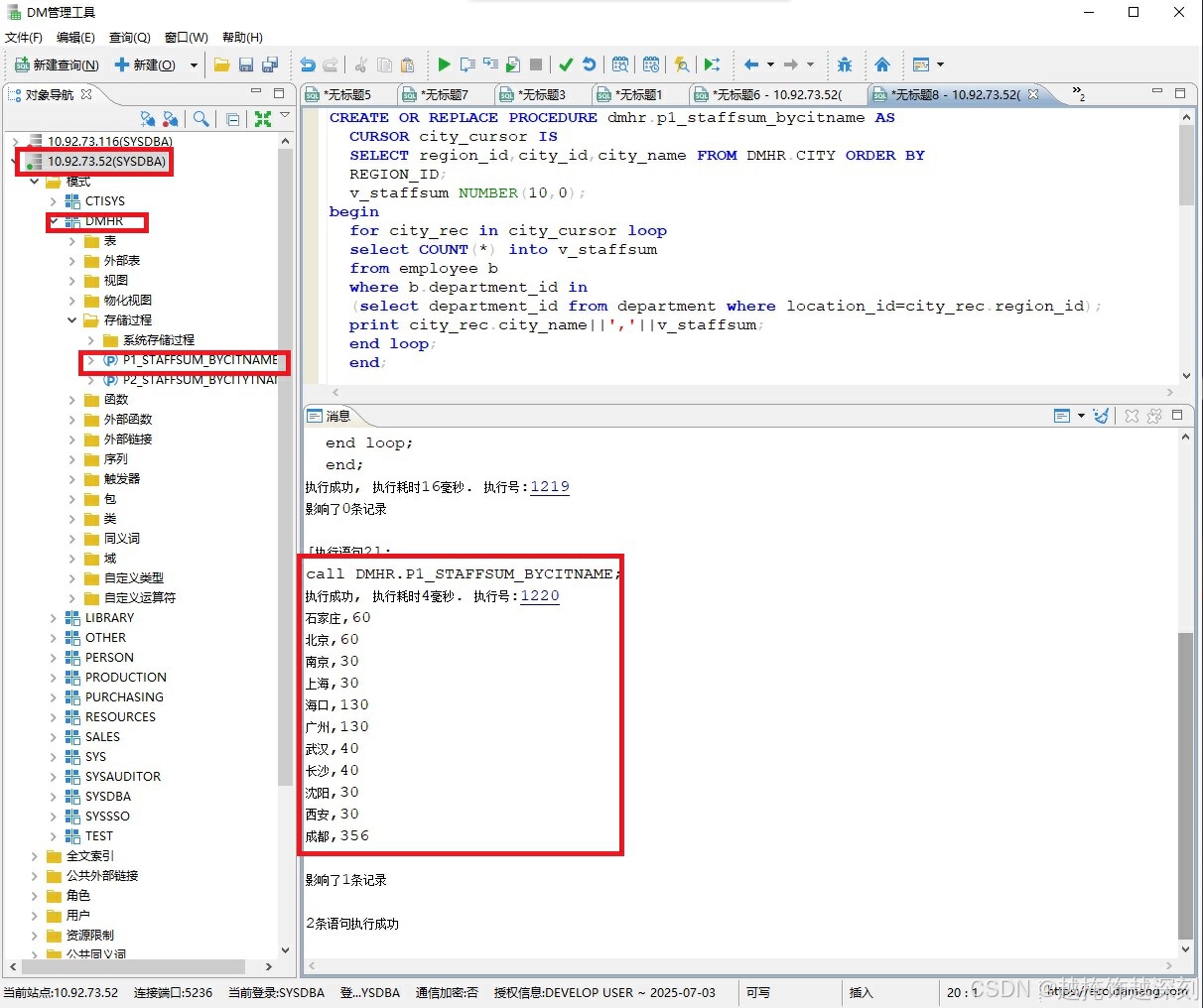
例二:
题目:
1.设计一个带参数的存储过程p2_staffsum_bycityname(v_cityname IN VARCHAR2,staffsum OUT NUMBER),该存储过程根据输入的城市名称统计所属员工的人数之和,并通过输出参数返回员工人数。
2.在 DM SQL 中调用该存储过程,并查询城市名称为“成都”的员工数。
3.包括DM管理工具登录服务端的IP、DMHR模式的存储过程p2_staffsum_bycityname、设计存储过程的语句、调用存储过程的语句及返回结果。
代码如下:
CREATE OR REPLACE PROCEDURE dmhr.p2_staffsum_bycityname(v_cityname IN VARCHAR2, staffsum OUT NUMBER) AS
v_staffsum NUMBER;
v_region_id NUMBER;
BEGIN
-- 获取城市的 region_id
SELECT region_id INTO v_region_id FROM dmhr.city WHERE city_name = v_cityname;
-- 统计该城市所属部门的员工人数
SELECT COUNT(*) INTO v_staffsum FROM dmhr.employee a WHERE a.department_id IN (
SELECT department_id FROM dmhr.department WHERE location_id = v_region_id);
-- 输出城市名称和员工人数
PRINT v_cityname || ',' || v_staffsum;
-- 将统计结果赋值给输出参数
staffsum := v_staffsum;
EXCEPTION
WHEN NO_DATA_FOUND THEN
PRINT '在该城市没有员工';
END;
--接下来,我们需要在 DM SQL 中调用该存储过程,查询城市名称为“成都”的员工数。以下是调用存储过程的代码:
DECLARE
v_staffsum NUMBER;
BEGIN
-- 调用存储过程 p2_staffsum_bycityname
dmhr.p2_staffsum_bycityname('成都', v_staffsum);
-- 输出员工人数
PRINT v_staffsum;
END;执行结果如下:
例三:
题目:
1.创建一个存储函数f1_staffsum_bycityname,用于计算给定城市的员工人数,并返回数字型的结果。
2.异常处理:如果没有找到城市,返回0并打印提示信息“在XX(城市名称)没有员工”,其他异常则返回NULL并打印提示信息“发生错误”。
3.展示包括DM管理工具登录服务端的IP、DMHR模式的存储函数f1_staffsum_bycityname、设计存储函数的语句。
代码如下:
CREATE OR REPLACE FUNCTION dmhr.f1_staffsum_bycityname(v_cityname IN VARCHAR2)
RETURN NUMBER AS
v_staffsum NUMBER;
v_region_id NUMBER;
BEGIN
-- 获取城市的region_id
SELECT region_id INTO v_region_id FROM dmhr.city WHERE city_name = v_cityname;
-- 统计该城市的员工人数
SELECT COUNT(a.employee_id) INTO v_staffsum FROM dmhr.employee a WHERE a.department_id IN (
SELECT department_id FROM dmhr.department WHERE location_id = v_region_id);
-- 返回员工人数
RETURN v_staffsum;
EXCEPTION
WHEN NO_DATA_FOUND THEN
-- 如果没有找到城市,返回0并打印提示信息
PRINT '在' || v_cityname || '没有员工';
RETURN 0;
WHEN OTHERS THEN
-- 处理其他异常
PRINT '发生错误';
RETURN NULL;
END;执行结果如下:
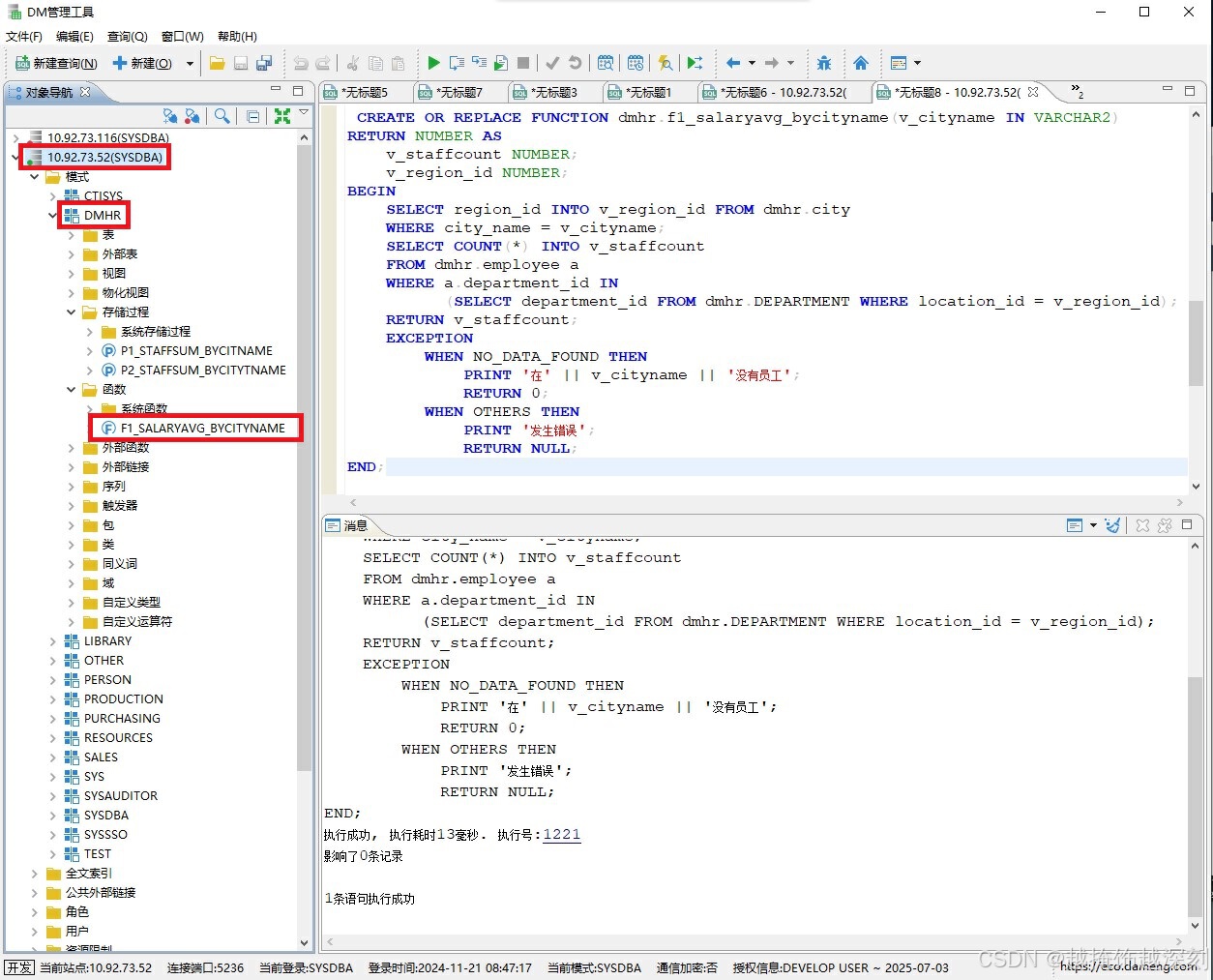
六、结语
综上所述,以及例题展示,可知达梦数据库的存储过程和存储函数是两种非常有用的工具,它们能够封装复杂的数据库操作,提高代码的重用性和执行效率。在实际应用中,应根据具体需求选择合适的工具来实现数据库操作。

















 5919
5919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









