







 本文详细解析PyTorch中Tensor与tensor的区别,对比三种创建张量的方式,讲解randperm函数的应用,以及如何在不同维度下进行张量操作。包括维度变换、合并拆分、广播机制等内容。
本文详细解析PyTorch中Tensor与tensor的区别,对比三种创建张量的方式,讲解randperm函数的应用,以及如何在不同维度下进行张量操作。包括维度变换、合并拆分、广播机制等内容。
修改时间记录:19/9/5 、
文章目录
torch.Tensor 和 torch.tensor 区别
torch.Tensor是默认的tensor类型(torch.FloatTensor)的简称,可以接受形状输入。需要注意用形状创建的tensor数值会很没规律,很大或很小,后续如果直接传入神经网络会出现各种莫名其妙的bug,所以用这样创建之后要尽快传入数值把它覆盖掉
torch.tensor根据后面的data创建Tensor,Tensor类型根据数据进行推断。虽然用具体数值创建tensor两种都可,但为避免混淆,推荐用小写这个创建,大写那个可以传入形状进行创建
torch.tensor(data, dtype=None, device=None, requires_grad=False)
所以torch.tensor([1. , 2.] , dtype = torch.float64) 和 torch.Tensor ([1,2]) 生成的数据没区别。
t.tensor(1)
维度为一的 tensor 就是 0.4 版本前的 valiable
三种方式比较
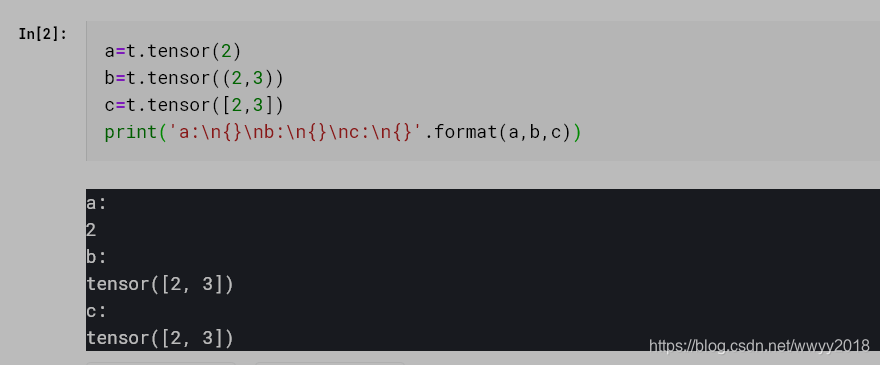
a 创建了标量
b c 都是创建了含具体值的tensor
如果是 t.ones() t.randn() 等函数传入的是size形状
randperm 用于打散
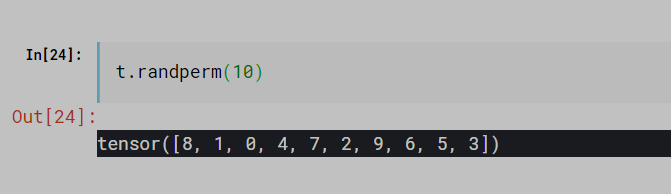
返回值是随机打散的索引的列表
各种维度适合场景
一维:bias
二维:【batch , size】
三维: 适合RNN
四维 【b,c ,h ,w】 适用于 CNN
dim、size/shape、tensor
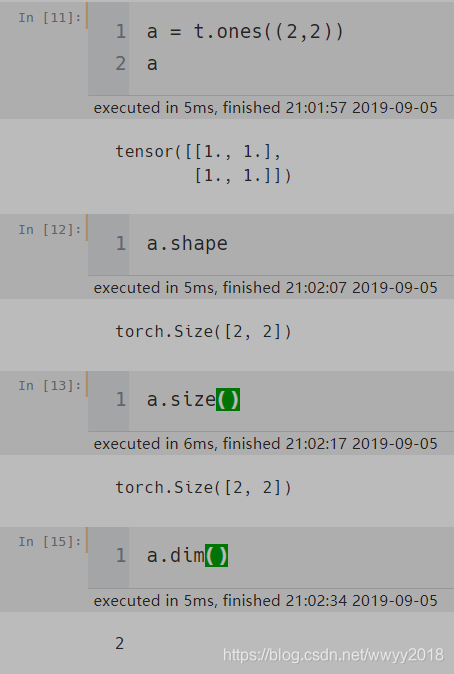
创建一个tensor a,直接输出a就是tensor的值,shape 和 size() 表示同一意思,tensor 的形状,dim() 表示维度,这里size() 是 【2,2】 这是2维,如果是【1,2,3】这就是3维
索引和切片
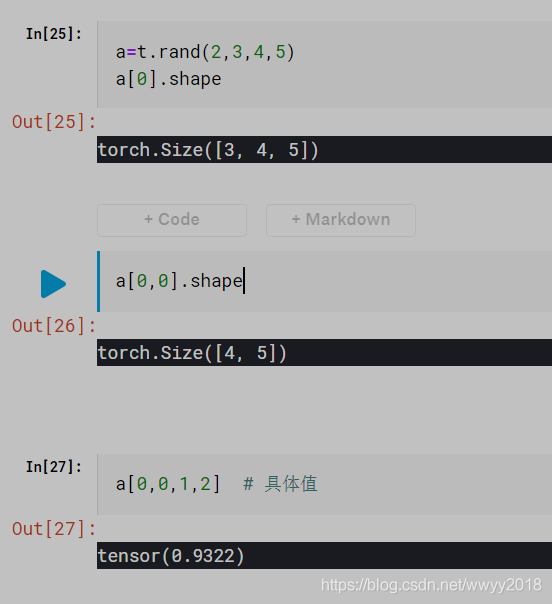
维度默认从左开始算起
冒号索引相同,维度从左开始算起
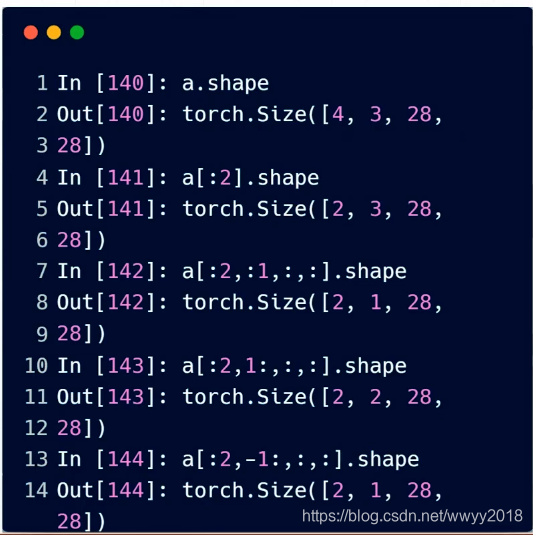
间隔选取
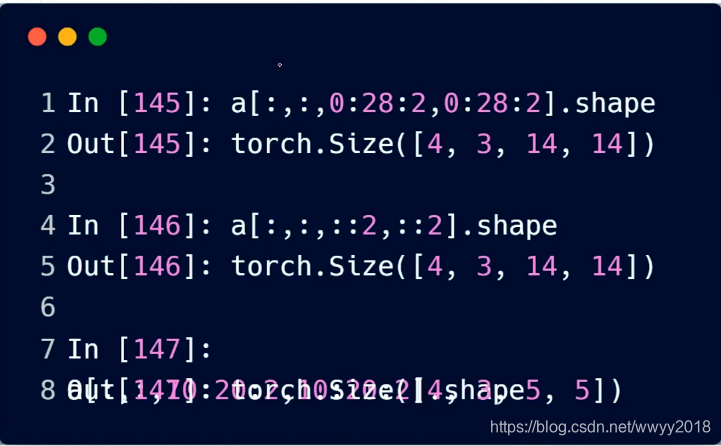
按照具体索引号进行采样:
用 torch.index_select( dim , [index] )
dim: 第几个维度上
index: 在该维度上想要取得内容的索引号
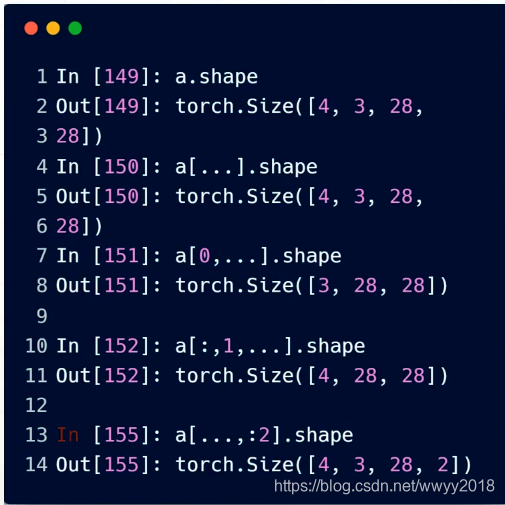
… 表示任意多的维度
维度变换
reshpe 和 view 用法相同
保证变换前后各个维度乘积相等 如 torch.size([2,3,4]) 234=24
那么变换后也要保证 各维度相乘的24
推荐使用reshpe,当处理内存不连续的tensor时,用view()进行变换会报错,需要用tensor.contiguous().view() 的写法,用reshape相当于tensor.contiguous().view()
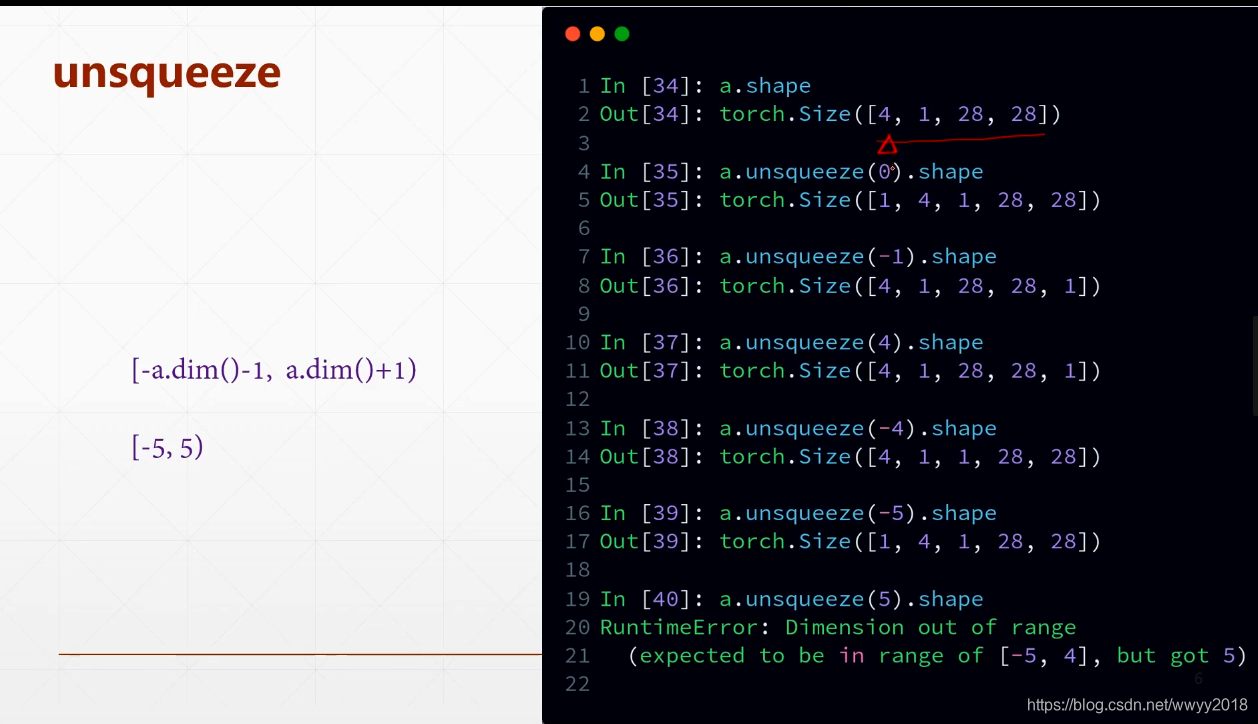
squeeze/unsqueeze
suqeeze 减少维度 ,输入想要删减的维度索引,如果不给参数,则会把属性为1的都去掉
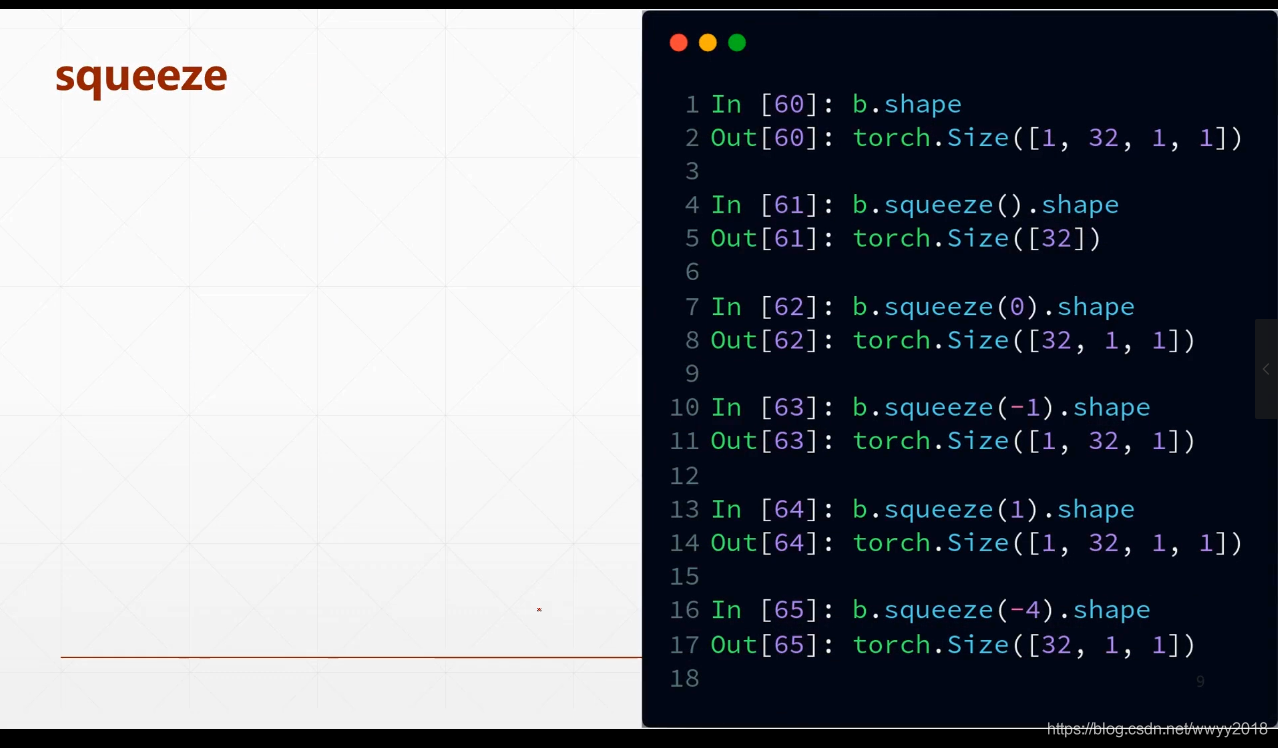
unsqueeze 增加维度,在正索引之前插入(建议不用负索引)
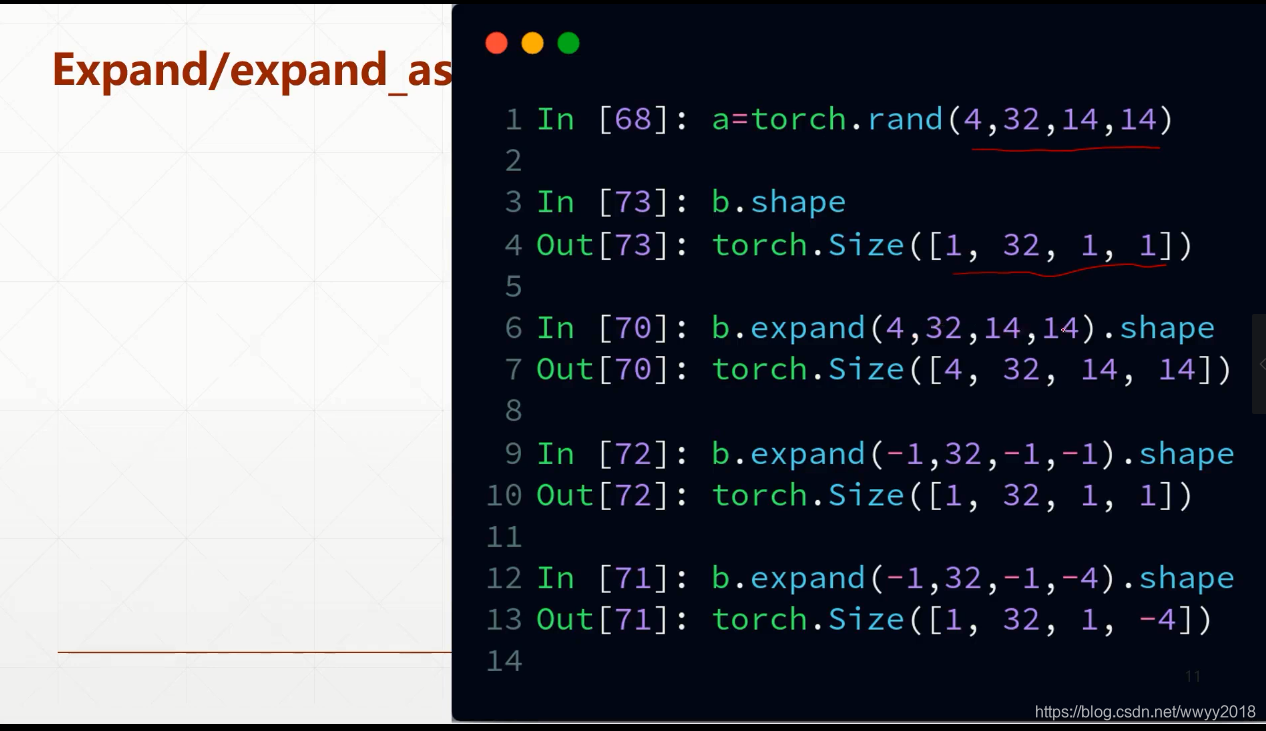
expand / repeat
expand:不会主动复制(速度快、节约内存,但无法扩展值不为1的维度)
只会扩展原属性值为1的size
-1 表示保持不变,
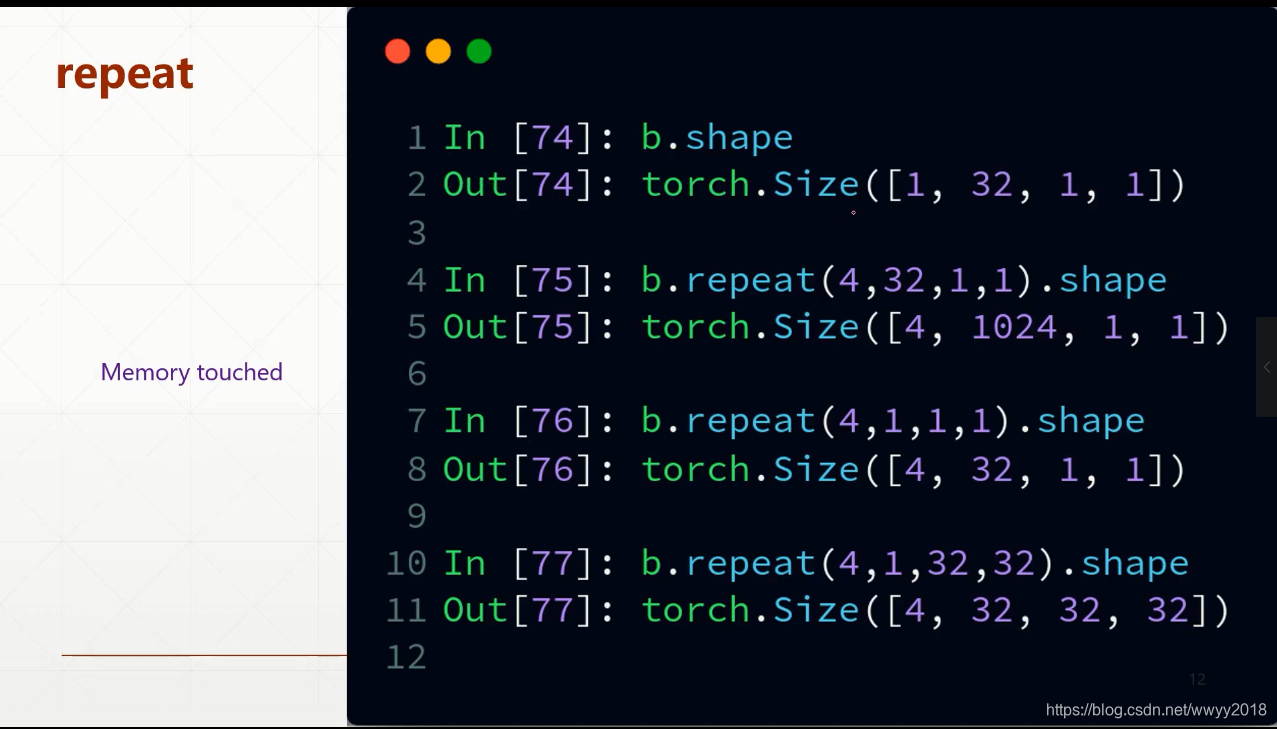
repeat:会主动复制
参数为各个维度上复制的次数
.t() 转置方法,只适用二维
transpose 维度交换
transpose(1,3) 表示1,3维度进行交换
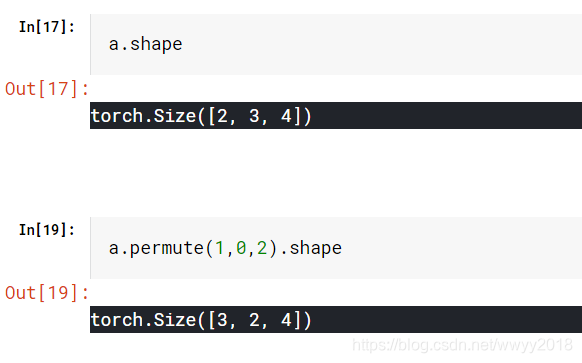
permute 传入维度索引顺序,进行维度交换
broadcast
和 numpy 中的广播机制相同,会进行维度上的自动扩展(从小维度进行匹配(右))
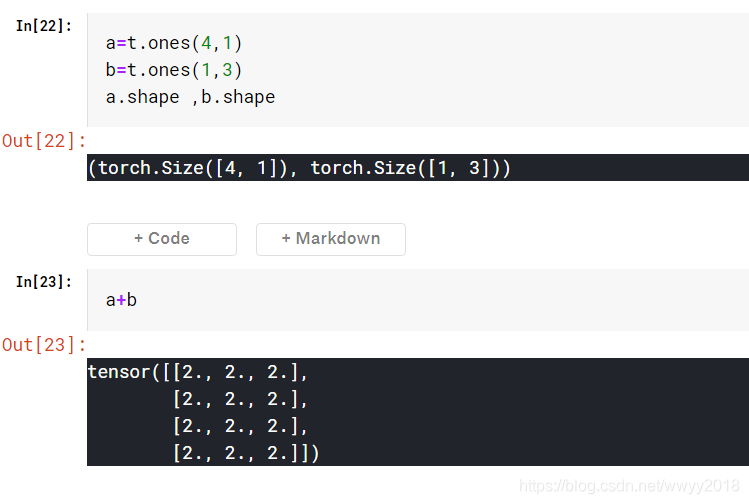 计算过程中(4,1)扩展成(4,3),(1,3)扩展为(4,3),最后相加
计算过程中(4,1)扩展成(4,3),(1,3)扩展为(4,3),最后相加
合并和切割
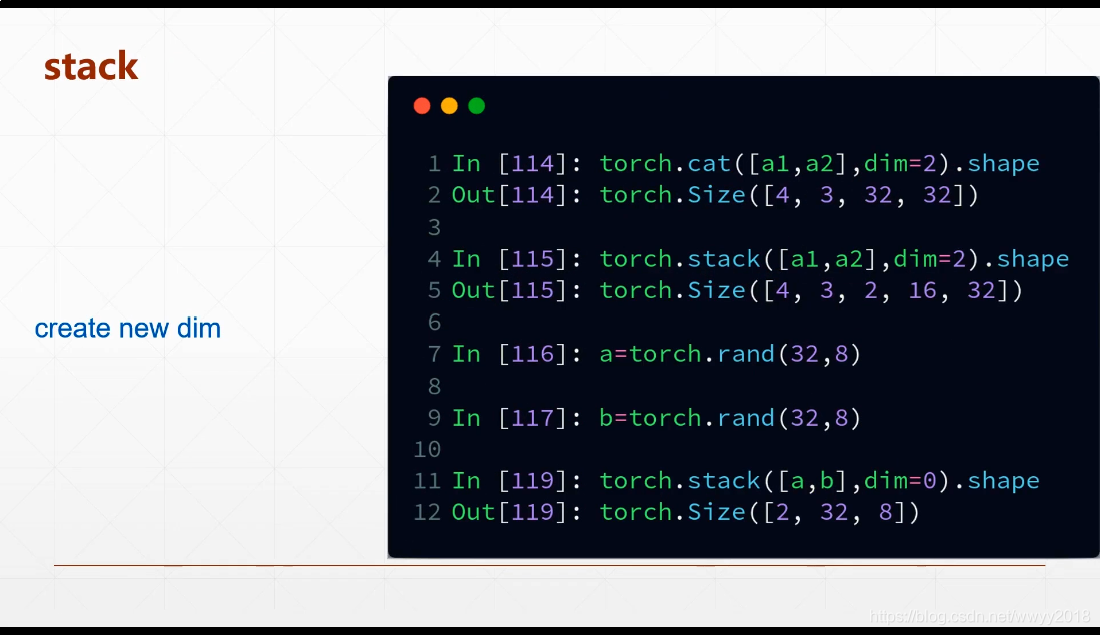
合并 cat / stack
cat(tensor_list[] , dim =) 在一个维度上进行合并,只允许在拼接的维度上值不同,其他维度值要相同
stack 会创建一个新的维度 ,要拼接tensor的所有维度值要都相同
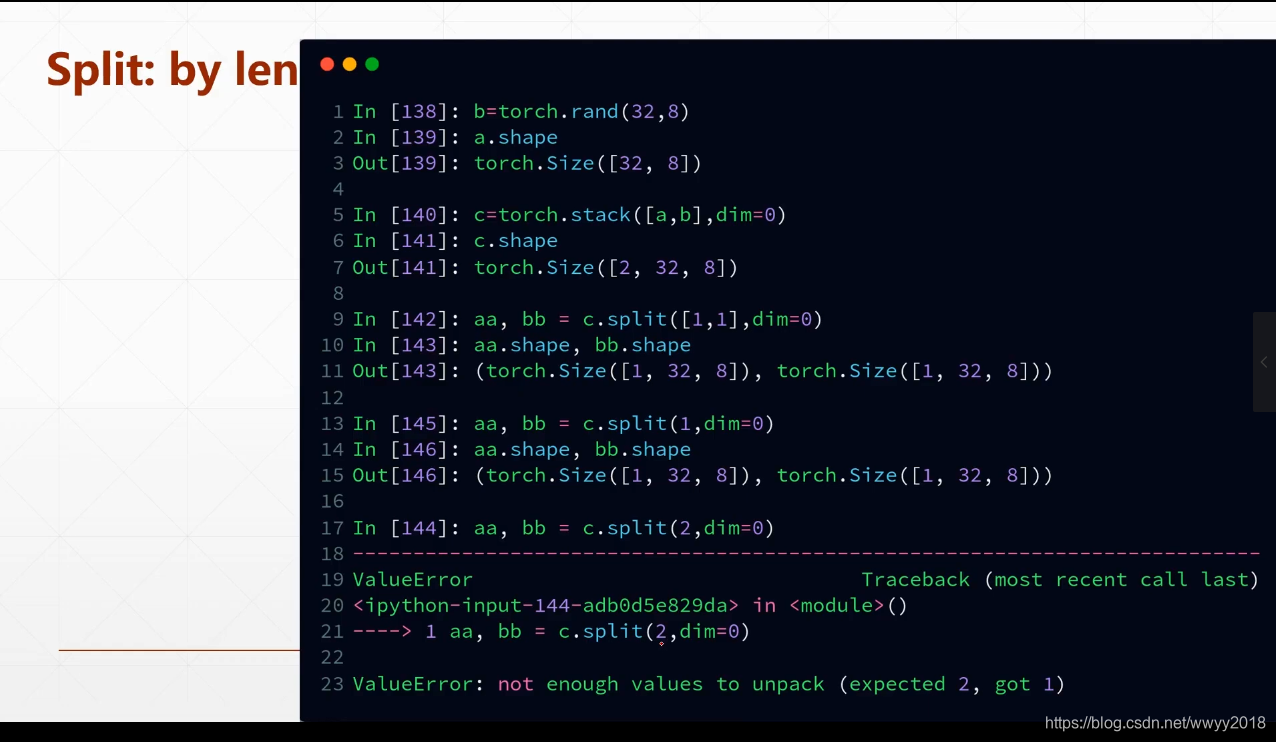
拆分 split / chunk
split 根据长度拆分,参数为拆分之后的长度,,如果长度都一样那就直接给定一个固定的长度就可以了,长度不一样那就给一个长度列表。如对 size( [4,2,1]) 在第一维度上进行拆分,想要拆分之后第一维度长度分别为 1,3,则 a1,a2 = torch.split( [1,3] ,dim=0)
chunk : 按数量进行拆分,参数为拆分之后的数量


















 2009
2009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











