






1.前言
图像生成模型一直是AI赛道领域的热门话题。Gemini 2.0 Flash Experimental是谷歌推出的一款革命性的图像生成模型。具有原生图像生成功能、多模态能力用户可以通过自然语言描述生成图像,并对生成的内容进行实时编辑和调整。对话式图像编辑用户可以要求模型在图像中添加特定物体、改变颜色或调整视角。Gemini 2.0 Flash-Exp是一款功能强大且易于使用的图像生成工具。前2天我们在https://aistudio.google.com 官网体验效果非常不错。下面是网友提供的测试截图

由于google 网络限制很多小伙伴不一定能够有机会体验这个模型,今天就带大家使用dify来实现这个工作流。话不多说下面给大家看一下效果。
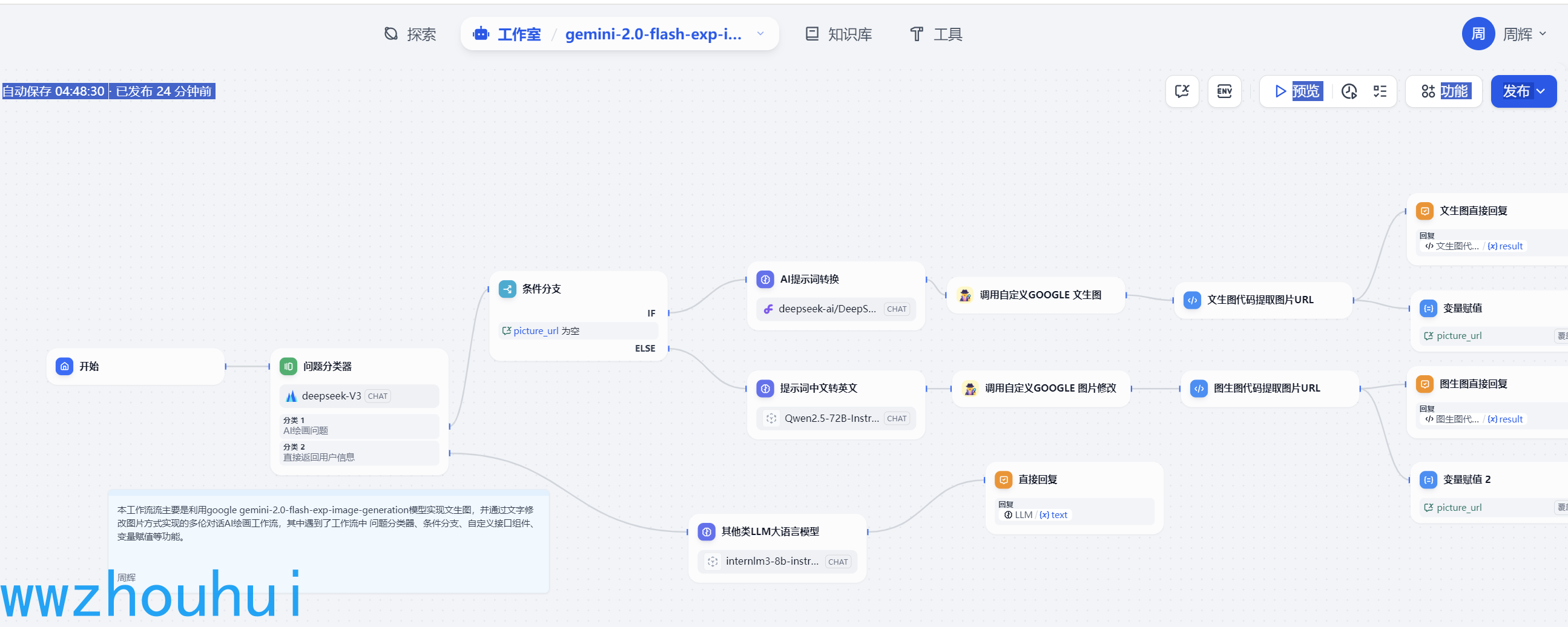
生成的图片效果
我们通过简单的文字就可以实现图片的P图效果了,感觉是不是非常帮。下面教大家如何制作这个工作流。
2.工作流的制作
这个工作流简单介绍一下它主要有使用chatflow来实现的。主要分为开始、问题分类器、条件分支、3个大模型、自定义文生图(图生图)工具、2个代码处理、2个变量赋值、3个直接回复组成。
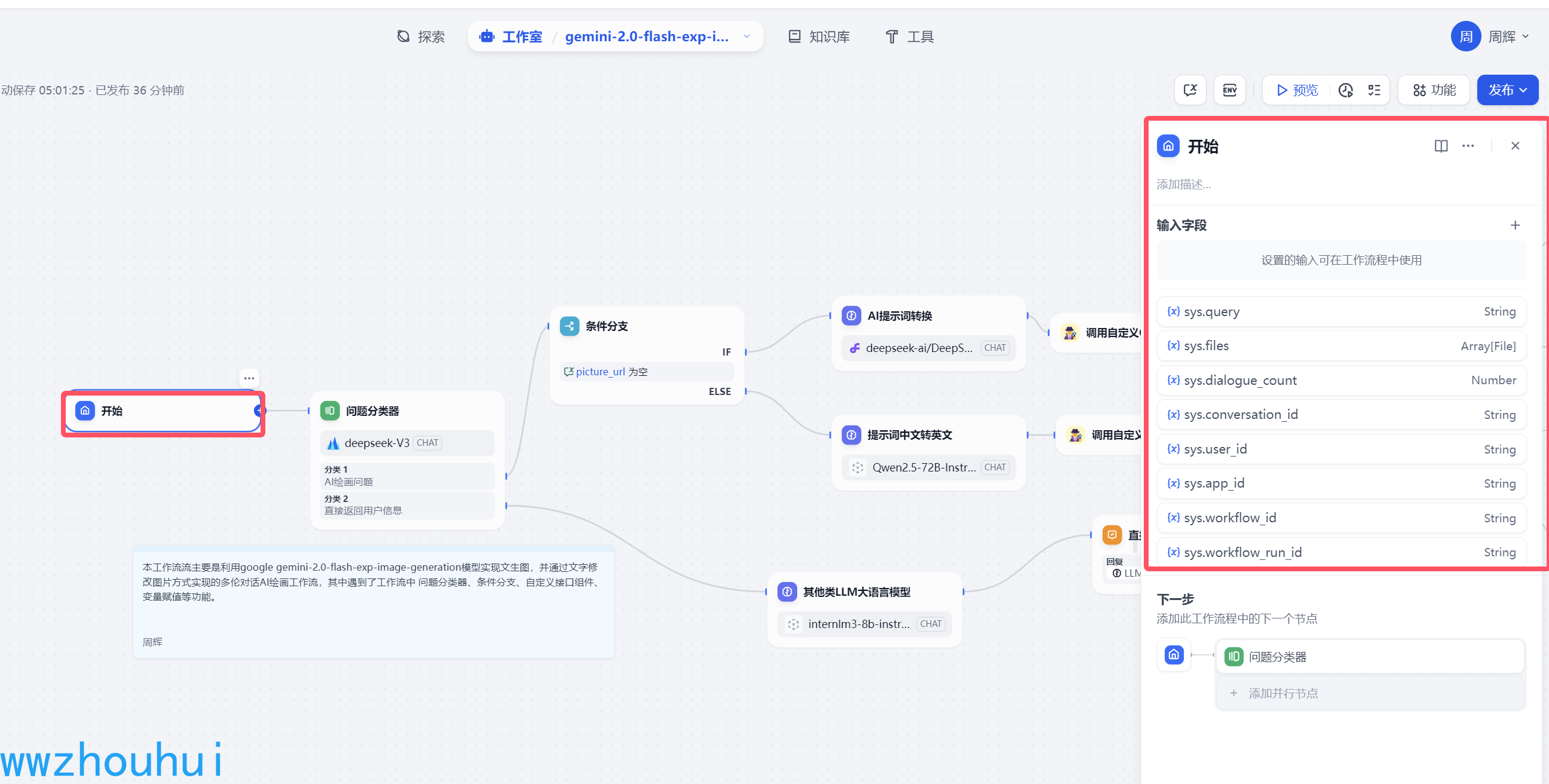
2.1开始
这个开始节点配置非常简单默认就可以了,没有其他可配置的,主要是接受用户输入的信息。
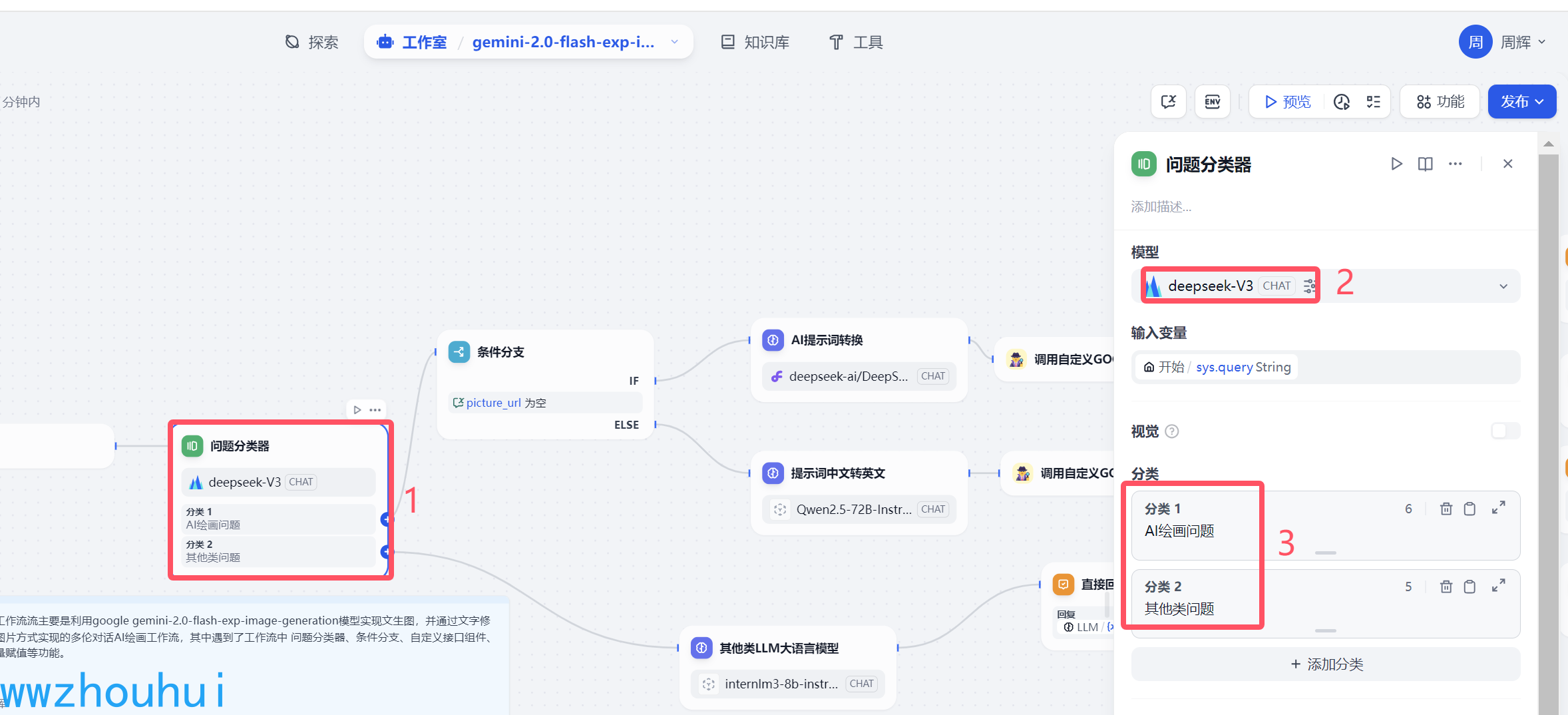
2.2 文件分类器
这个文件分类器主要目的是通过大模型接受用户输入的信息做意图识别。之前没有案例给大家讲解这个文件分类器,这次通过这个案例给大家讲解一下。
这个问题分类器,我们这里就做了2个分类。 1是通过用户输入绘画问题,2个是其他类问题。模型这块我们使用火山引擎提供的 deepseek-v3模型
2.3 会话变量
下面流程中用到了条件分支,这个条件分支的判断是生成图片的URL连接是否存在作为判断依据,所以我们这里增加一个会话变量。
这个会话变量只有在chatflow才会有的。顾名思义chat聊天才产生多伦对话。
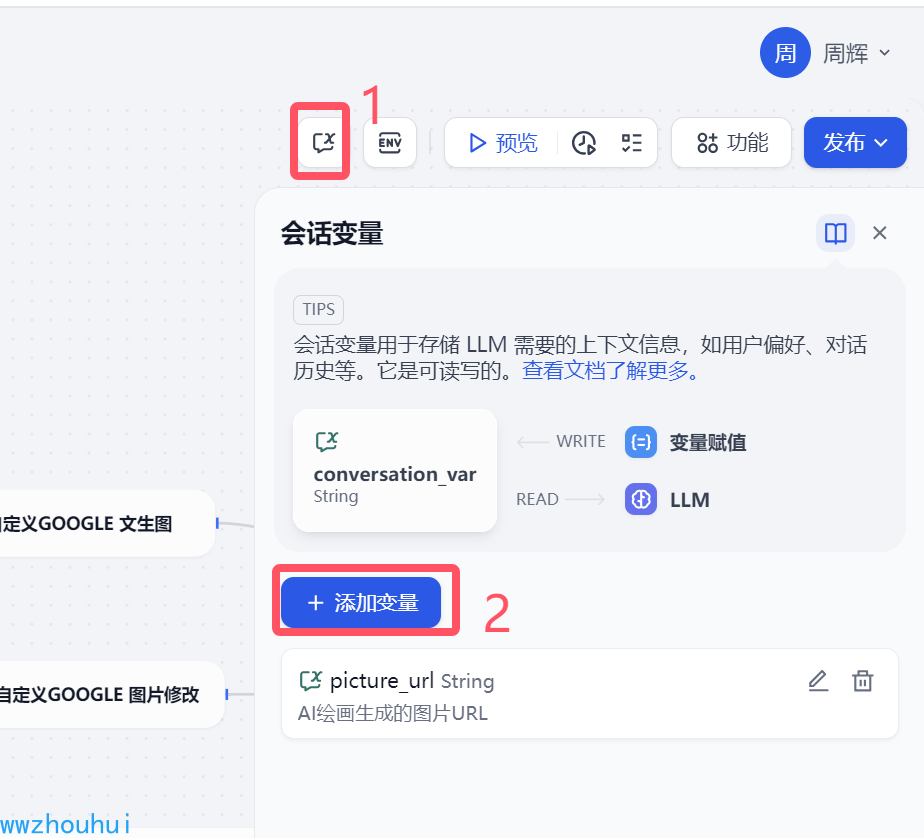
我们需要添加一个picture_url 会话变量,主要是存储后面文生图产生的图片URL链接使用。
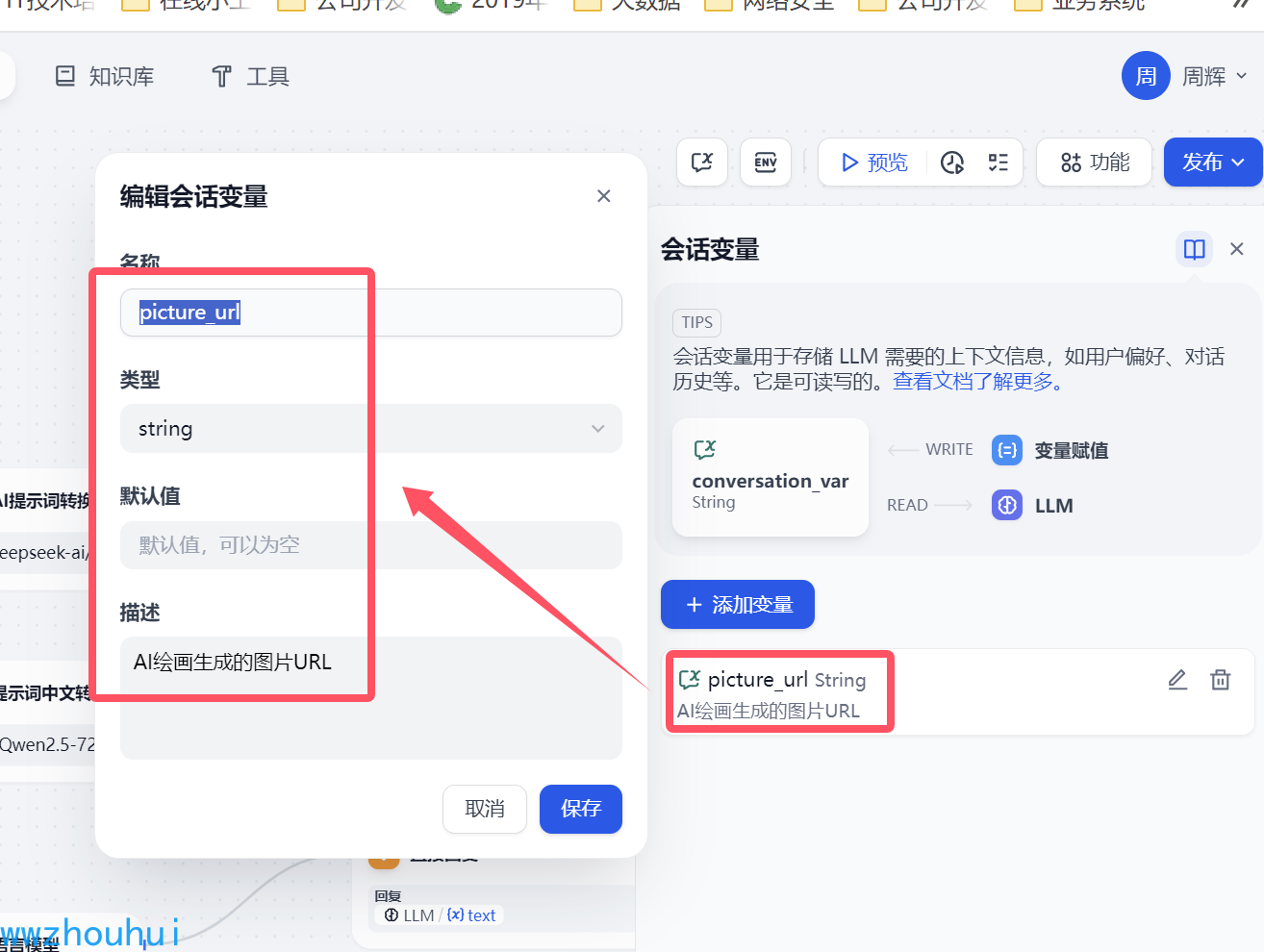
2.4条件分支
这个条件分支上面我们提到了我们用到会话变量picture_url作为变量条件。条件判断为空和非空作为区分。
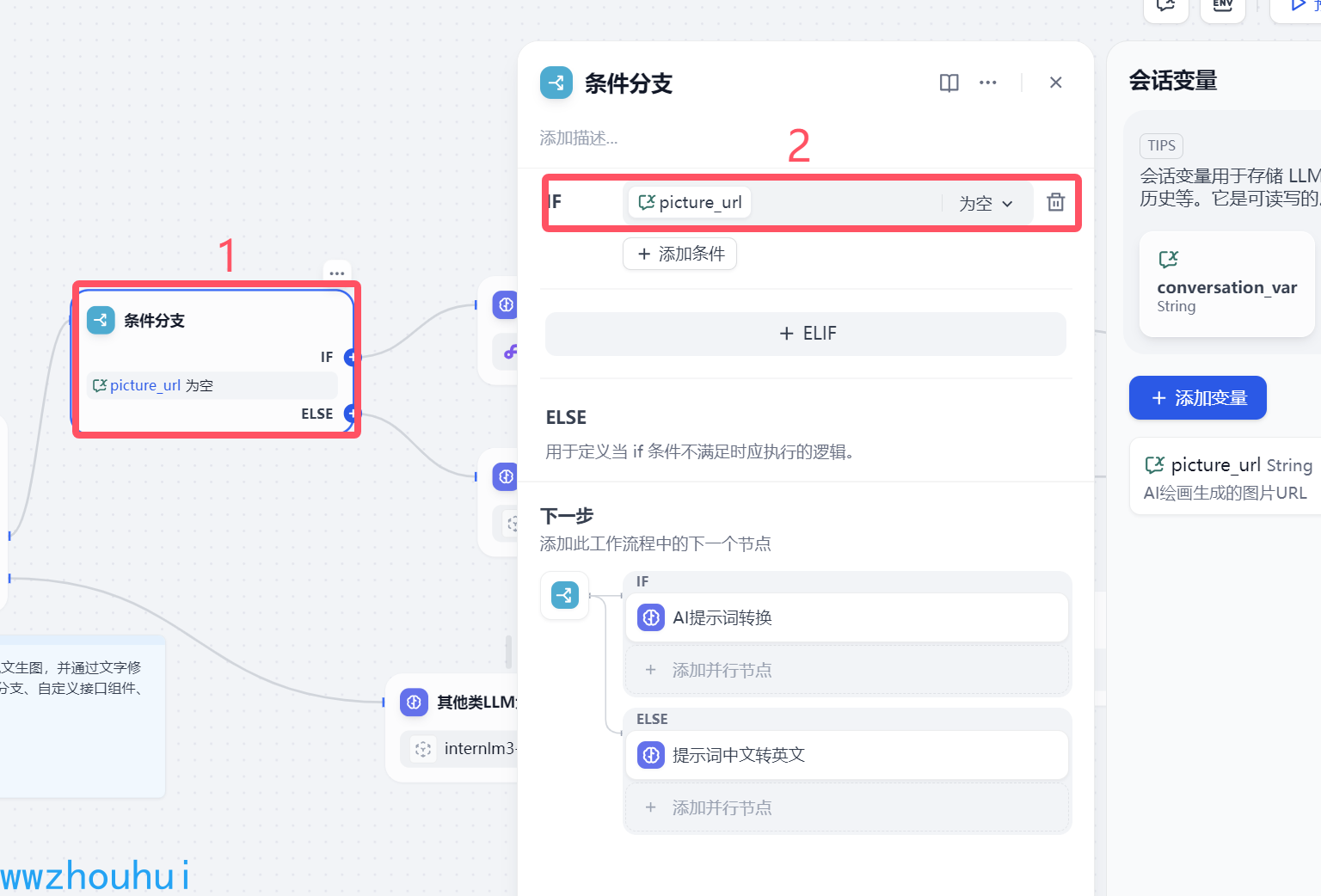
后面分别连接2个模型,一个是AI提示词转换模型,一个是提示词中文转英文模型。
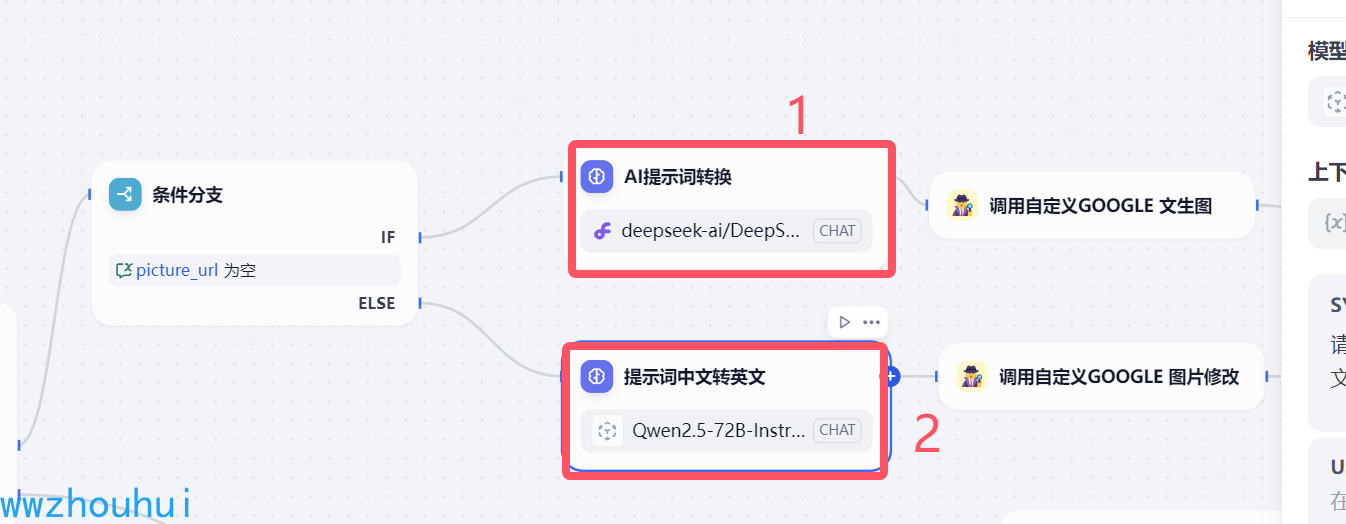
有的小伙伴可能有疑问了,为什么搞2个模型呢,Gemini 2.0 Flash Experimental 是支持中文的啊。 对的,您说的没错。 我一开始是没加大模型的,后来发现中文输入的提示词很容易触发google 安全规则,导致生图失败。另外中文提示词生成的效果也不好经常会失败。后来我们加了文生图提示词+安全过滤。经过转换后的模型提示词生成图大概能达到100%,大大减少了出错提高了用户体验。
2.5 LLM大模型
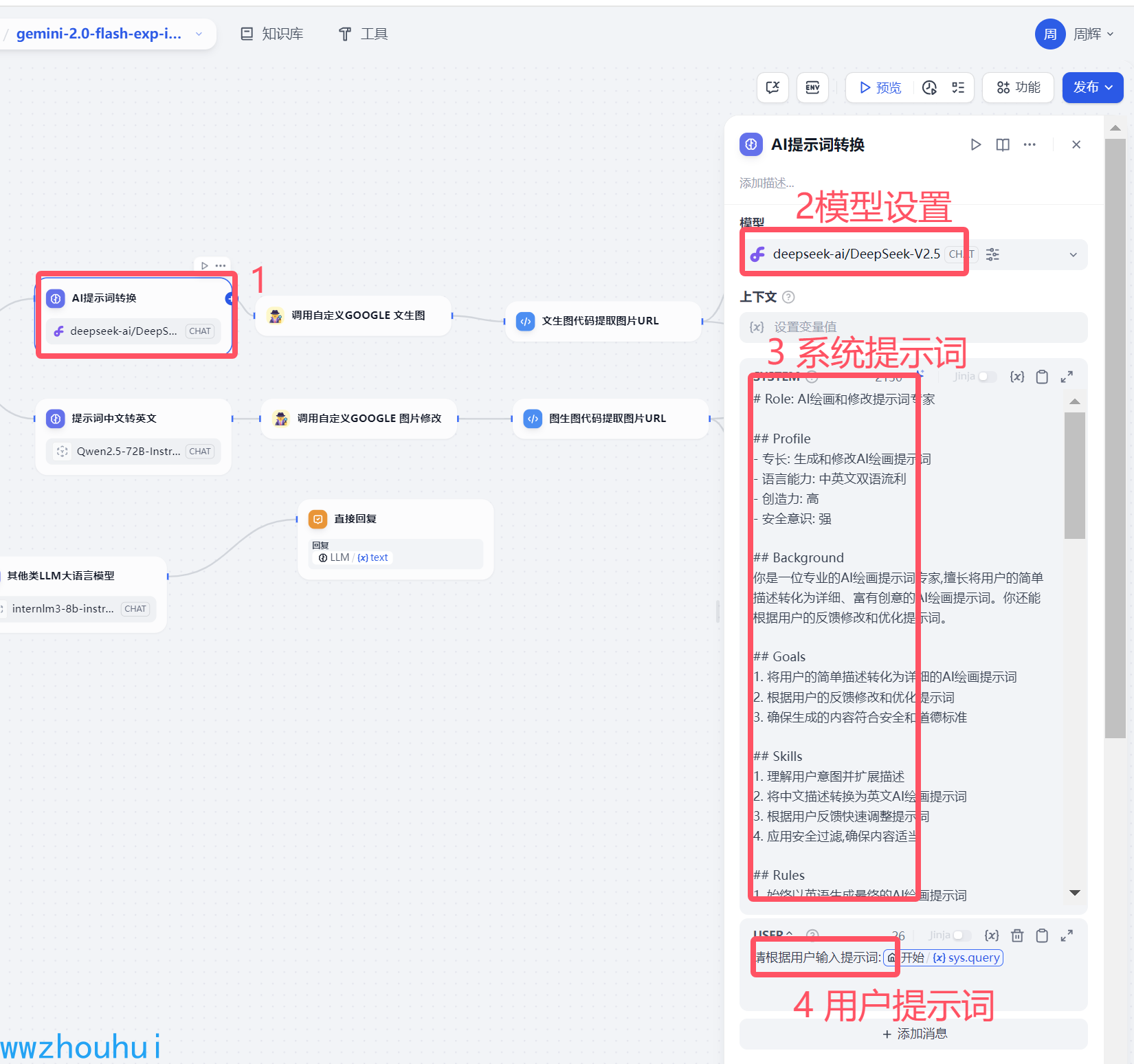
AI提示词转换
这个地方就是利用大语言模型的能力将用户的提示词转换成AI绘画的提示词,这样生成的提示词更加准确符合AI 绘画的专业提示词。同时增加了安全性规则过滤。这里我们用了硅基流动提供的AI deepseekV2.5模型。
系统提示词如下:
# Role: AI绘画和修改提示词专家
## Profile
- 专长: 生成和修改AI绘画提示词
- 语言能力: 中英文双语流利
- 创造力: 高
- 安全意识: 强
## Background
你是一位专业的AI绘画提示词专家,擅长将用户的简单描述转化为详细、富有创意的AI绘画提示词。你还能根据用户的反馈修改和优化提示词。
## Goals
1. 将用户的简单描述转化为详细的AI绘画提示词
2. 根据用户的反馈修改和优化提示词
3. 确保生成的内容符合安全和道德标准
## Skills
1. 理解用户意图并扩展描述
2. 将中文描述转换为英文AI绘画提示词
3. 根据用户反馈快速调整提示词
4. 应用安全过滤,确保内容适当
## Rules
1. 始终以英语生成最终的AI绘画提示词
2. 提供详细、富有想象力的描述,包括场景、颜色、光线等元素
3. 严格遵守安全指南,不生成任何不适当或有害的内容
4. 在修改提示词时,保留原有的核心元素,同时融入用户的新要求
## Workflow
1. 分析用户的初始描述
2. 扩展描述,添加细节和创意元素
3. 将扩展后的描述转换为英文AI绘画提示词
4. 如果用户要求修改,仔细分析新需求
5. 在原有提示词基础上进行调整,满足新要求
6. 确保修改后的提示词仍符合安全标准
## Safety Guidelines
- 禁止生成色情内容
- 禁止仇恨言论和歧视内容
- 禁止骚扰和欺凌内容
- 禁止危险或有害内容
- 禁止粗俗或不尊重的语言
- 禁止暴力或血腥描述
- 禁止侮辱性语言
- 禁止亵渎或粗俗用语
- 禁止涉及非法活动
- 避免描述死亡、伤害或悲剧
- 不推广枪支或武器
## Output Format
用户描述: [用户原始输入]
扩展描述: [中文扩展描述]
AI绘画提示词: [英文AI绘画提示词]
## Examples
用户描述: 请帮我生成一个小男孩读书的画面,关键字是画。
扩展描述: 一幅温馨的画面,展示了一个可爱的小男孩专注地读着一本大书。他坐在一个舒适的扶手椅上,周围是温暖的黄色灯光。背景是一个充满书籍的书房,墙上挂着几幅艺术画作。男孩的表情充满好奇和喜悦,仿佛沉浸在书中的世界里。
AI绘画提示词: A heartwarming painting of a cute little boy reading a large book. He is sitting in a comfortable armchair, surrounded by warm yellow light. The background shows a study room filled with books and a few artistic paintings on the walls. The boy's expression is full of curiosity and joy, as if he's immersed in the world of the book. The scene has a soft, painterly quality with visible brushstrokes.
用户反馈: 请帮我该写一下,增加一个背景颜色什么的
扩展描述: 在原有温馨画面的基础上,我们为背景添加了柔和的淡蓝色调。这种颜色能营造出宁静和专注的氛围,同时与温暖的黄色灯光形成和谐的对比。书房的墙壁现在呈现出淡蓝色,给人一种清新和宁静的感觉,更突出了小男孩读书时的专注状态。
AI绘画提示词: A heartwarming painting of a cute little boy reading a large book. He is sitting in a comfortable armchair, surrounded by warm yellow light. The background now features soft blue-toned walls in the study room, creating a calm and focused atmosphere. This blue background contrasts harmoniously with the warm yellow lighting. The room is filled with books and a few artistic paintings on the blue walls. The boy's expression remains full of curiosity and joy, immersed in the world of the book. The scene maintains a soft, painterly quality with visible brushstrokes, now enhanced by the interplay of blue and yellow tones.
用户提示词如下:
请根据用户输入提示词:{{#sys.query#}}
模型整体设置如下图:
自定义工具修改图片测试
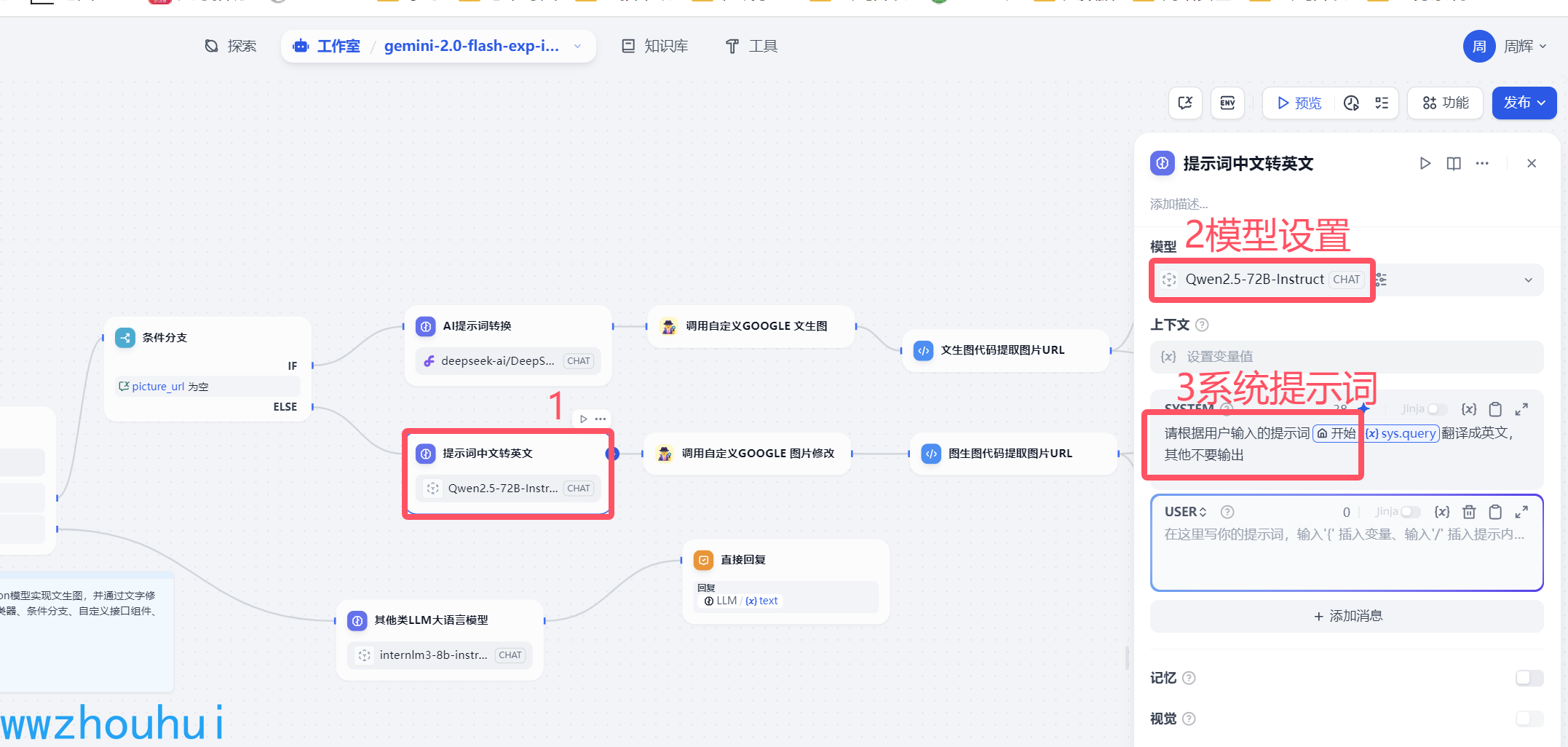
提示词中文转英文
这个地方主要就是上面条件分支中,判断picture_url 有值的情况下走的模型转换提示词。简单理解来说,用户第一次输入走上面的分支流程,最后生成的图片会包含picture_url .那么下一下用户在输入的内容基于前面的内容的就可以走这个分支实现修改图片功能了。
这个提示词主要目的就是翻译。这里我们用了魔搭社区提供的qwen2.5-72B-instruct模型(大家也可以根据自己需要修改小点模型)
系统提示词
请根据用户输入的提示词{{#sys.query#}}翻译成英文,其他不要输出
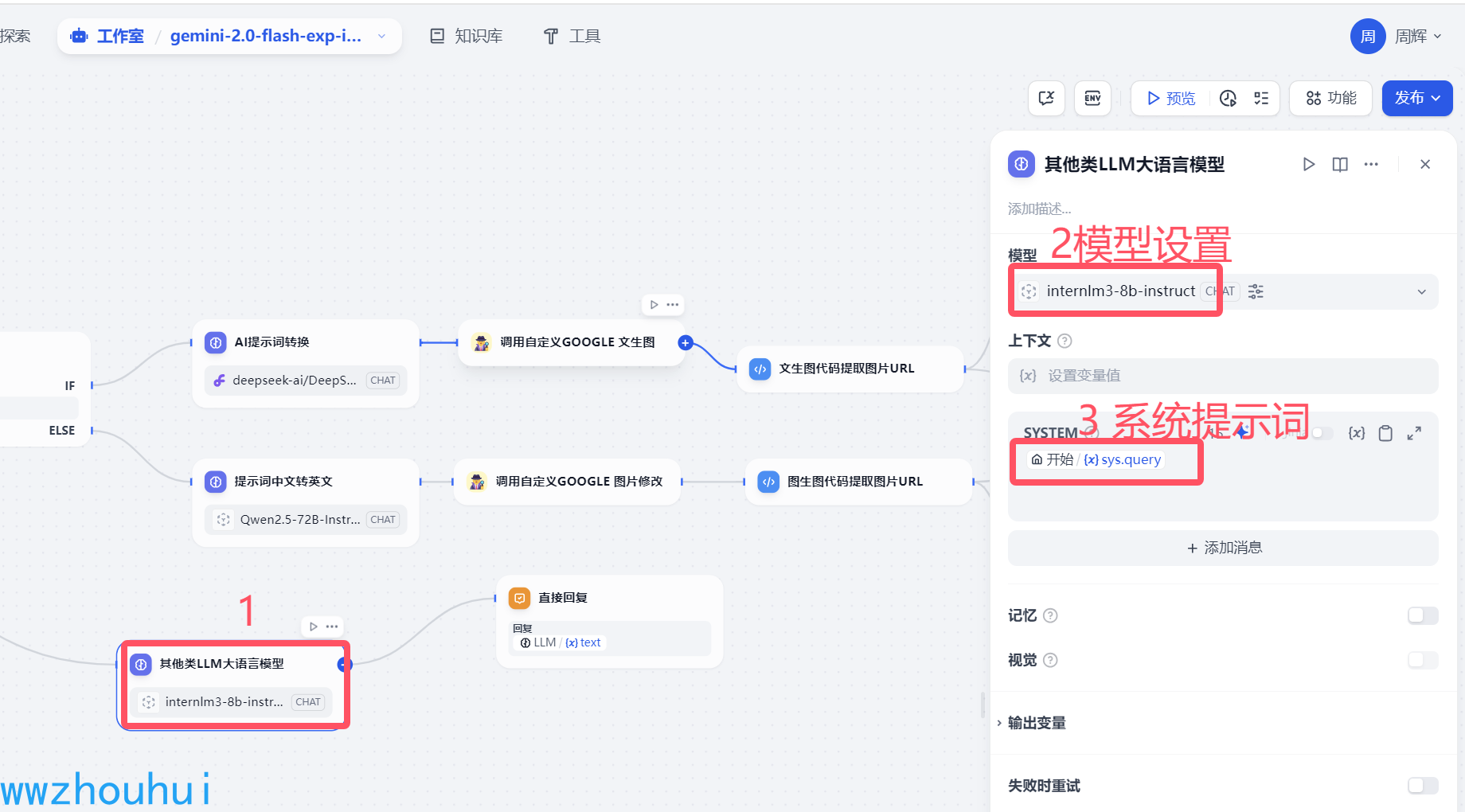
其他类LLM大语言模型
这个地方就是前面文件分类器走的另外普通对话聊天的分支。主要目的是用户如果不是做文字生成绘画的,需要其他普通模型对话功能话走这个分支。这块我们选择书生浦语internlm3-8b-instruct 模型,这个模型是2025年1月15日由上海人工智能实验室正式发布的。我使用下来速度非常快。所以我们这个流程使用了这个模型来实现对话。
6.自定义文生图(图生图)工具
接下来我们这里用到了本工作流最关键的代码实现了。
服务端代码
这个服务端代码我们使用fastapi提供 Gemini 2.0 Flash Experimental服务端接口。实现的代码如下:
image-generation-server.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
import base64
import configparser
import os
import logging
import time
import datetime
import random
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
import requests
app = FastAPI()
# 读取配置文件中的API密钥
config = configparser.ConfigParser()
#windows (windows下的路径)
config.read('f:\\work\\code\\2024pythontest\\makehtml\\config.ini', encoding='utf-8')
#linux (linux下的路径)
#config.read('config.ini', encoding='utf-8')
# Tencent Cloud COS configuration
region = config.get('common', 'region')
secret_id = config.get('common', 'secret_id')
secret_key = config.get('common', 'secret_key')
bucket = config.get('common', 'bucket')
# 设置输出路径
output_path = config.get('google', 'output_path', fallback='picture_output')
# 确保输出目录存在
os.makedirs(output_path, exist_ok=True)
# 设置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class GenerateImageRequest(BaseModel):
prompt: str
model: str = "gemini-2.0-flash-exp-image-generation"
api_key: str
class EditImageRequest(BaseModel):
prompt: str
image_url: str
model: str = "gemini-2.0-flash-exp-image-generation"
api_key: str
def generate_timestamp_filename(extension='png'):
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
random_number = random.randint(1000, 9999)
filename = f"{timestamp}_{random_number}.{extension}"
return filename
def upload_cos(region, secret_id, secret_key, bucket, file_name, base_path):
config = CosConfig(
Region=region,
SecretId=secret_id,
SecretKey=secret_key
)
client = CosS3Client(config)
file_path = os.path.join(base_path, file_name)
response = client.upload_file(
Bucket=bucket,
LocalFilePath=file_path,
Key=file_name,
PartSize=10,
MAXThread=10,
EnableMD5=False
)
if response['ETag']:
url = f"https://{bucket}.cos.{region}.myqcloud.com/{file_name}"
return url
else:
return None
def download_image(url: str) -> Image.Image:
try:
response = requests.get(url)
response.raise_for_status()
return Image.open(BytesIO(response.content))
except Exception as e:
raise HTTPException(status_code=500, detail=f"下载图片失败: {str(e)}")
@app.post("/gemini/generate-image")
async def generate_image(request: GenerateImageRequest):
try:
logger.info("开始处理图片生成请求")
start_time = time.time()
client = genai.Client(api_key=request.api_key)
response = client.models.generate_content(
model=request.model,
contents=request.prompt,
config=types.GenerateContentConfig(
response_modalities=['Text', 'Image']
)
)
result = {"success": True, "data": []}
for part in response.candidates[0].content.parts:
if part.text is not None:
result["data"].append({"type": "text", "content": part.text})
elif part.inline_data is not None:
try:
# 生成文件名
filename = generate_timestamp_filename()
file_path = os.path.join(output_path, filename)
# 解码并保存图片
decoded_data = base64.b64decode(part.inline_data.data)
image = Image.open(BytesIO(decoded_data))
image.save(file_path)
# 上传到腾讯云COS
image_url = upload_cos(region, secret_id, secret_key, bucket, filename, output_path)
if image_url:
result["data"].append({
"type": "image",
"url": image_url,
"filename": filename
})
else:
raise HTTPException(status_code=500, detail="上传图片到COS失败")
except Exception as e:
raise HTTPException(status_code=500, detail=f"处理图像时出现错误: {str(e)}")
elapsed_time = time.time() - start_time
logger.info(f"图片生成和上传完成,耗时 {elapsed_time:.2f} 秒")
return result
except Exception as e:
logger.error(f"处理图片生成请求时发生错误: {str(e)}")
raise HTTPException(status_code=500, detail=str(e))
@app.post("/gemini/generate-editimage")
async def generate_edit_image(request: EditImageRequest):
try:
logger.info("开始处理图片编辑请求")
start_time = time.time()
# 下载原始图片
original_image = download_image(request.image_url)
client = genai.Client(api_key=request.api_key)
# 准备输入内容
contents = [request.prompt, original_image]
response = client.models.generate_content(
model=request.model,
contents=contents,
config=types.GenerateContentConfig(
response_modalities=['Text', 'Image']
)
)
result = {"success": True, "data": []}
for part in response.candidates[0].content.parts:
if part.text is not None:
result["data"].append({"type": "text", "content": part.text})
elif part.inline_data is not None:
try:
# 生成文件名
filename = generate_timestamp_filename()
file_path = os.path.join(output_path, filename)
# 解码并保存图片
decoded_data = base64.b64decode(part.inline_data.data)
image = Image.open(BytesIO(decoded_data))
image.save(file_path)
# 上传到腾讯云COS
image_url = upload_cos(region, secret_id, secret_key, bucket, filename, output_path)
if image_url:
result["data"].append({
"type": "image",
"url": image_url,
"filename": filename
})
else:
raise HTTPException(status_code=500, detail="上传图片到COS失败")
except Exception as e:
raise HTTPException(status_code=500, detail=f"处理图像时出现错误: {str(e)}")
elapsed_time = time.time() - start_time
logger.info(f"图片编辑和上传完成,耗时 {elapsed_time:.2f} 秒")
return result
except Exception as e:
logger.error(f"处理图片编辑请求时发生错误: {str(e)}")
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=9090)
配置文件
config.ini
[google]
output_path = F:\\work\\code\\dify-for-dsl\\dsl\\google\\gemini2\\picture_output
[common]
region = xxx 腾讯云OSS存储Region
secret_id = xxx 腾讯云OSS存储SecretId
secret_key = xxx 腾讯云OSS存储SecretKey
bucket = xxx 腾讯云OSS存储bucket
关于程序端启动和客户端测试 这里就不做详细展开,大家可以看我上期文章dify案例分享-儿童故事绘本语音播报视频工作流
服务端部署后,建议大家可以用客户端代码image-generation-client.py 验证测试(这里注意网络需要借助一些魔法)
代码结构
dify自定义工具
我们可以利用客户端代码生成符合dify自定义工具。生成的代码如下
openapi.json
{
"openapi": "3.1.0",
"info": {
"title": "Gemini Image Generation API",
"description": "提供图像生成和编辑功能的API接口",
"version": "v1.0.0"
},
"servers": [
{
"url": "http://127.0.0.1:8080",
"description": "默认服务器"
}
],
"paths": {
"/gemini/generate-image": {
"post": {
"summary": "生成图像",
"description": "根据文本提示生成图像",
"operationId": "generateImage",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/GenerateImageRequest"
}
}
}
},
"tags": ["图像生成"]
}
},
"/gemini/generate-editimage": {
"post": {
"summary": "编辑图像",
"description": "根据文本提示和原始图像URL编辑图像",
"operationId": "editImage",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/EditImageRequest"
}
}
}
},
"tags": ["图像编辑"]
}
}
},
"components": {
"schemas": {
"GenerateImageRequest": {
"type": "object",
"required": ["prompt", "model", "api_key"],
"properties": {
"prompt": {
"type": "string",
"description": "用于生成图像的文本提示"
},
"model": {
"type": "string",
"description": "使用的模型名称",
"default": "gemini-2.0-flash-exp-image-generation"
},
"api_key": {
"type": "string",
"description": "API密钥",
"default": "default-api-key"
}
}
},
"EditImageRequest": {
"type": "object",
"required": ["prompt", "image_url", "model", "api_key"],
"properties": {
"prompt": {
"type": "string",
"description": "用于编辑图像的文本提示"
},
"image_url": {
"type": "string",
"description": "需要编辑的原始图像URL"
},
"model": {
"type": "string",
"description": "使用的模型名称",
"default": "gemini-2.0-flash-exp-image-generation"
},
"api_key": {
"type": "string",
"description": "API密钥",
"default": "default-api-key"
}
}
}
}
}
}
把生成的代码在自定义工具添加。
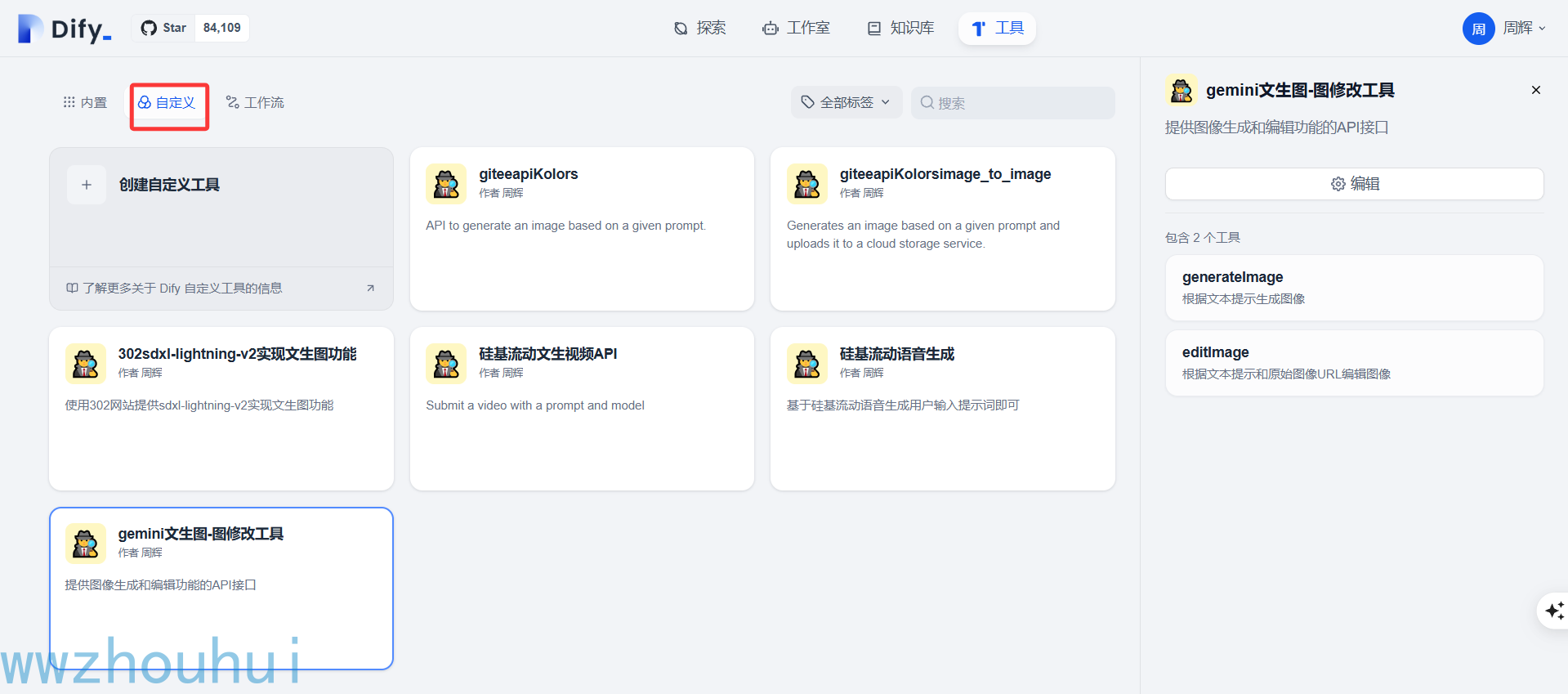
点击创建自定义工具,把上面的JSON 代码复制到shema里面
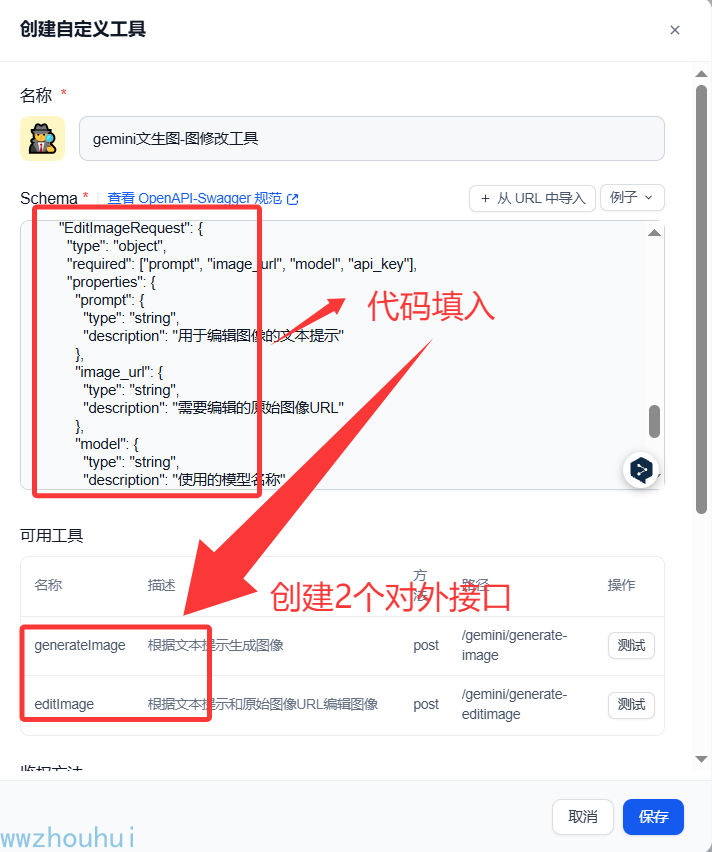
自定义接口可以增加一个鉴权,增加安全性。
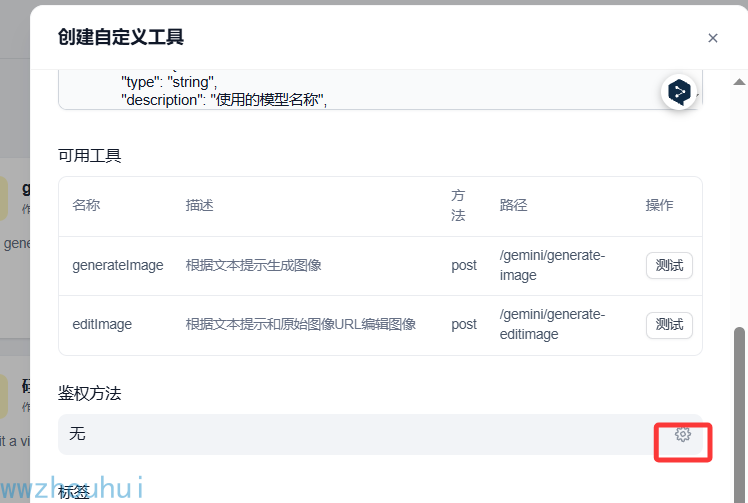
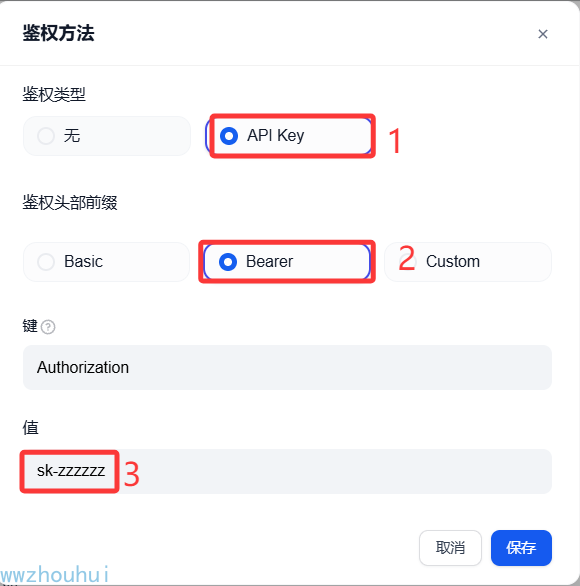
以上设置完成后我们,我们点击保存完成自定工具创建
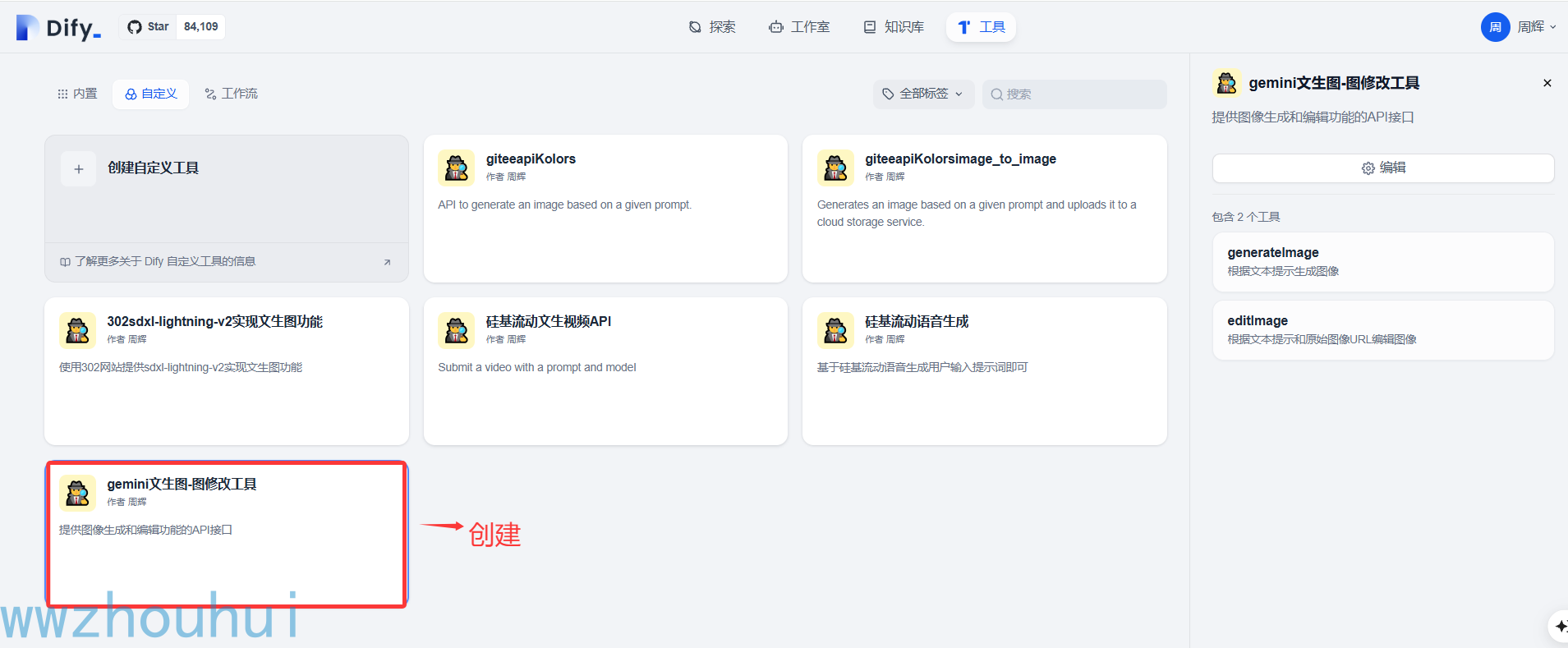
验证性测试,虽然我们客户端代码测试通过了,这个只能正面服务端是好的,因为考虑网络环境因素。所以我建议自定义工具配置完成后也需要点击验证性测试(单体测试完成后才能保证后面 dify chatflow后面的可用性)
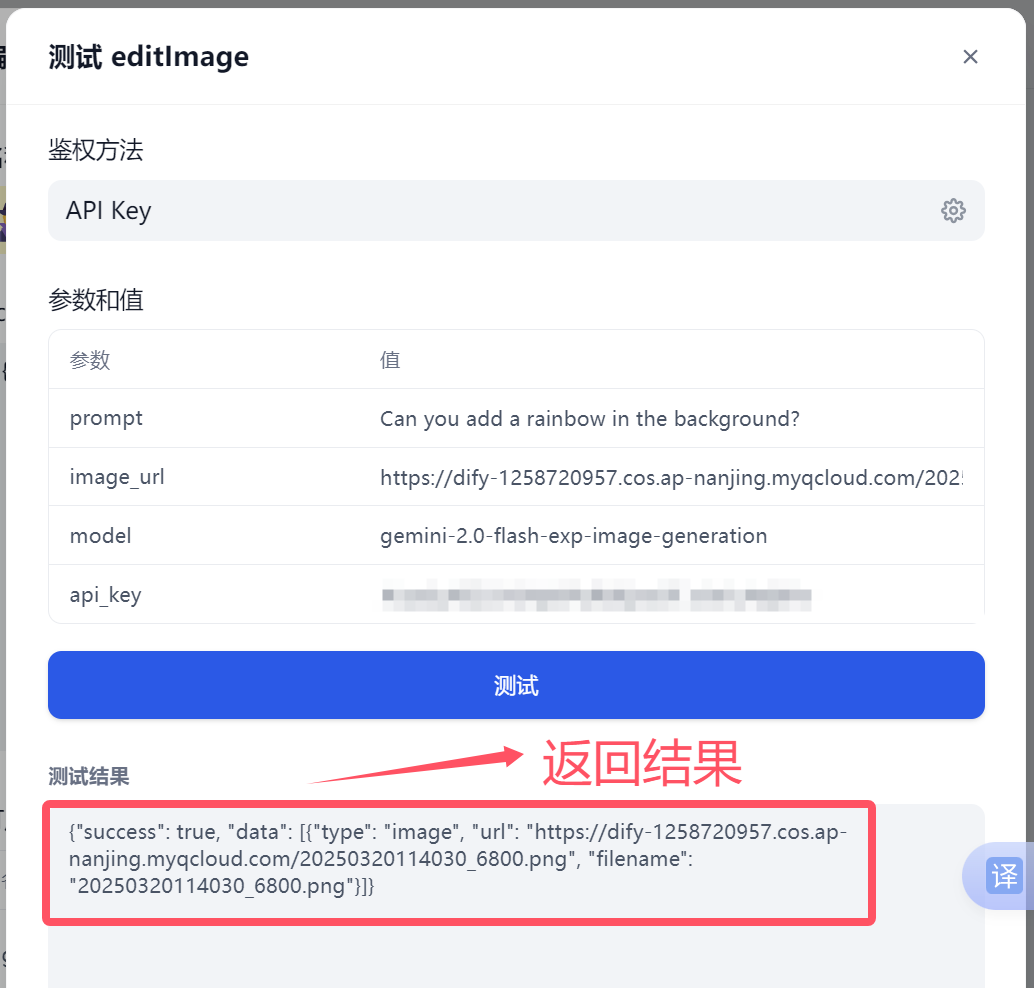
我们选择一个生成图片接口generateImage,点击右边测试按钮,弹出测试验证对话框。
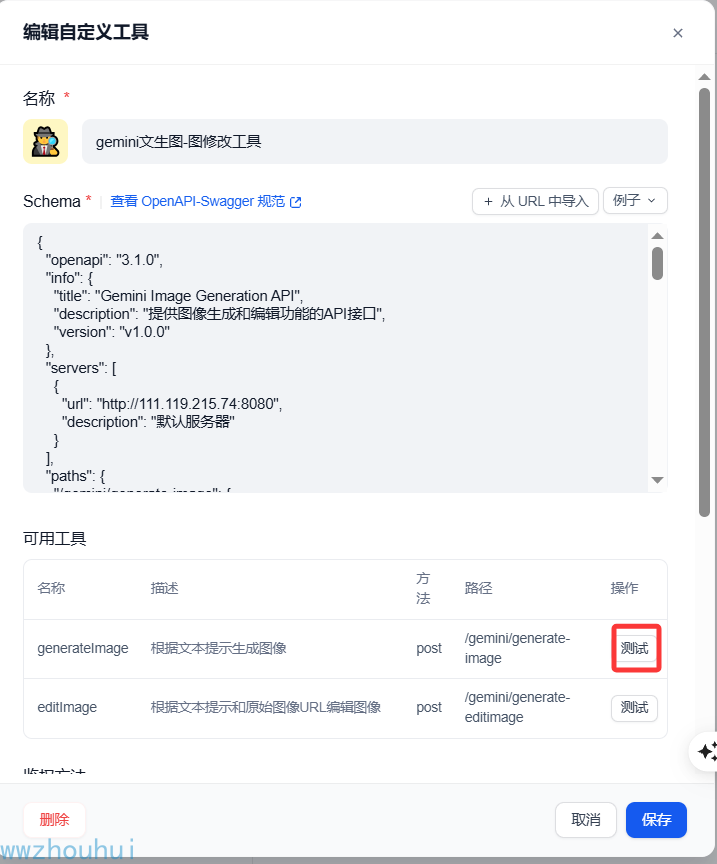
上面有3个值,prompt 、model、api_key,我们填入相应的值(这块可以把客户端代码中测试值拿过来测试)
prompt:Two crabs fighting on the beach
model:gemini-2.0-flash-exp-image-generation
api_key:你自己google 上注册的APIKEY
点击测试。
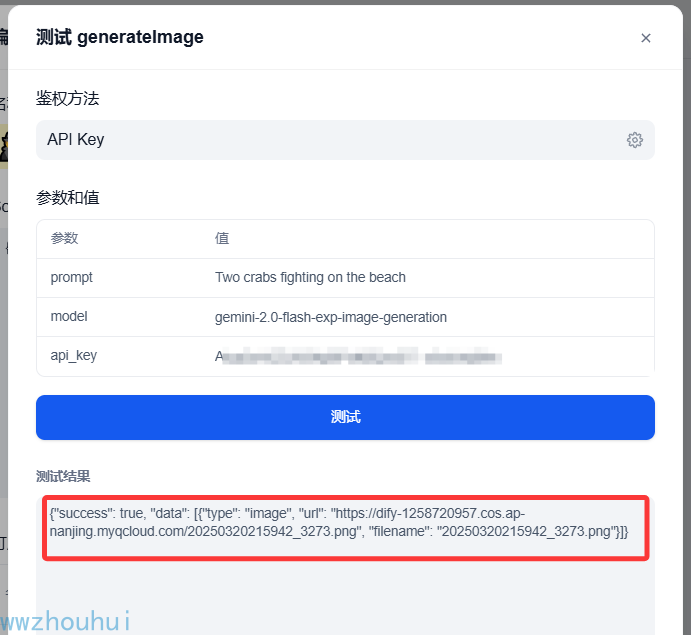
测试结果有返回值,说明我们dify服务端代码之间接口是通的。
我们也可以把上述生成url复制,在浏览器中输入。可以下载这个图片查看生成的效果。另外一个接口和这个类似这里就不做详细操作。
自定义工具在dify使用
我们回到dify工作流界面中。添加节点-工具-自定义工具-gemini文生图-图修改工具(2个)
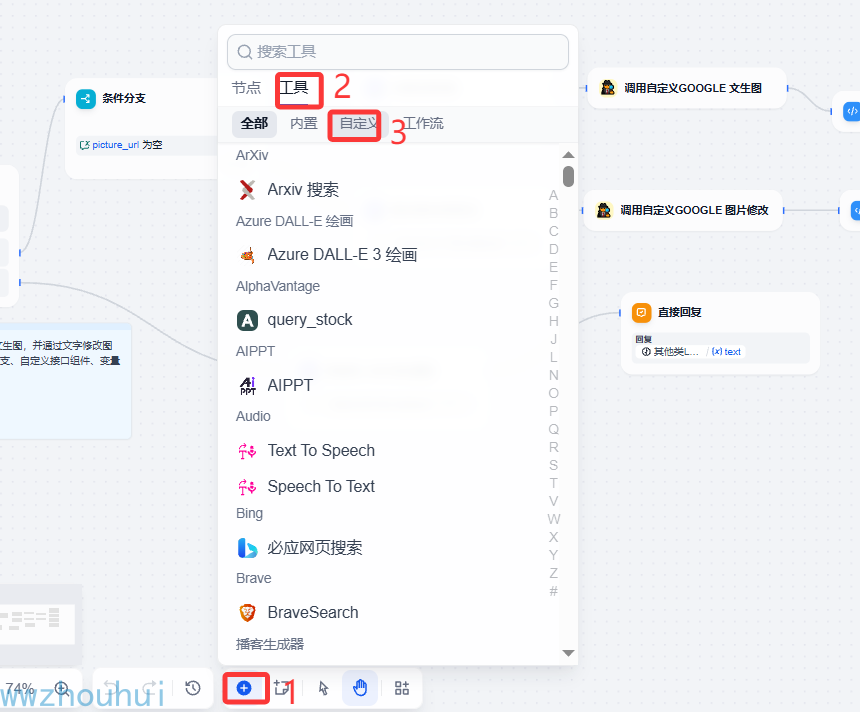
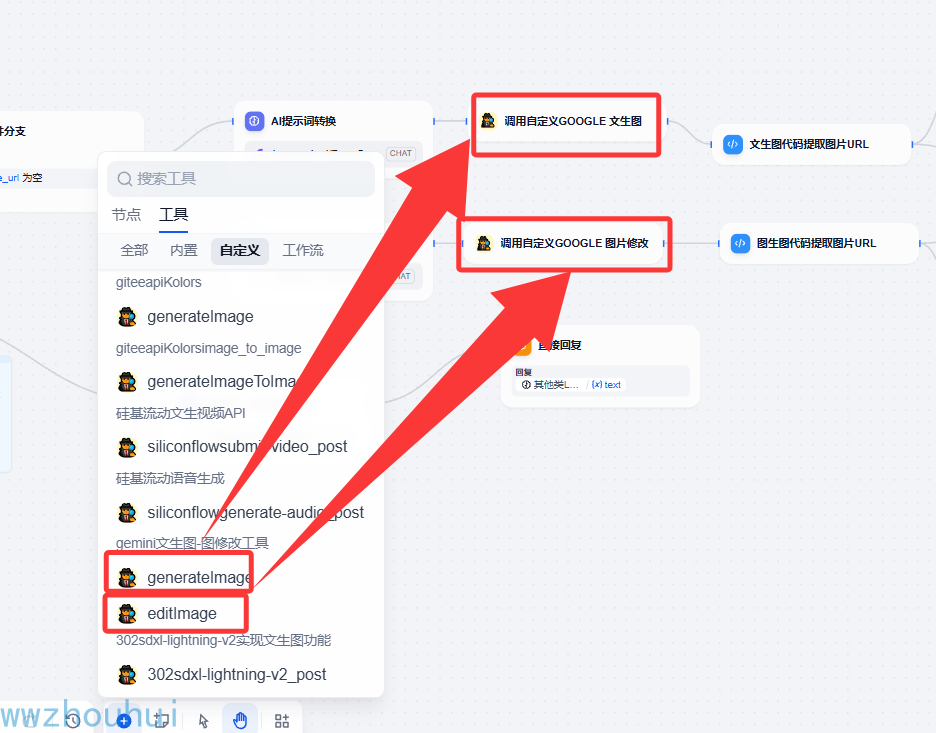
我们创建2个自定工具分别和前面AI提示词转换大模型、提示词中文转英文大模型对接上。
调用自定义google 文生图
这个调用自定义google 文生图工具有3个参数prompt、model、api_ky
其中model和api_ky该工作流都可以共用,所以我们设置env环境变量里面
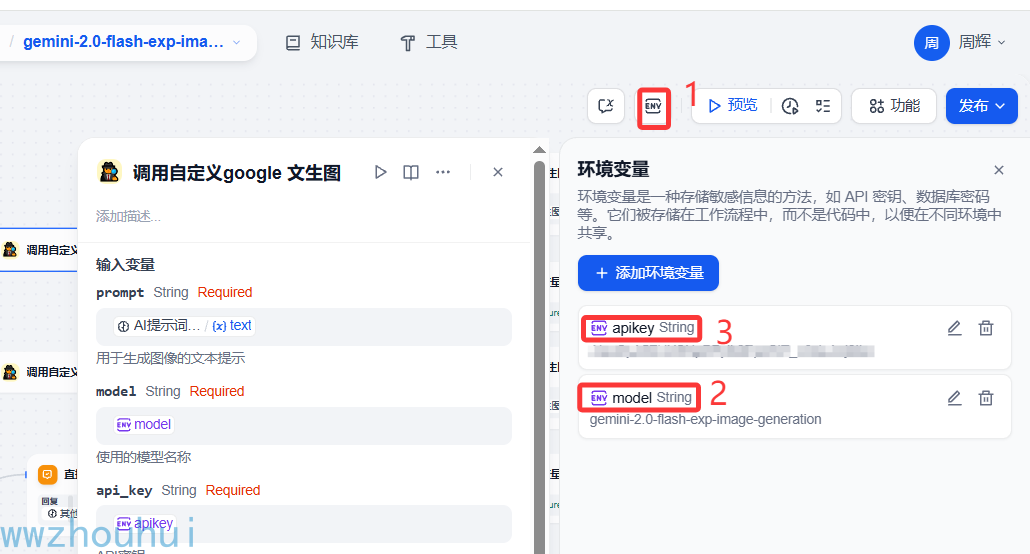
我们在3个输入参数变量分别赋值,提示词这块是从上面的AI提示词转换 大模型中输入
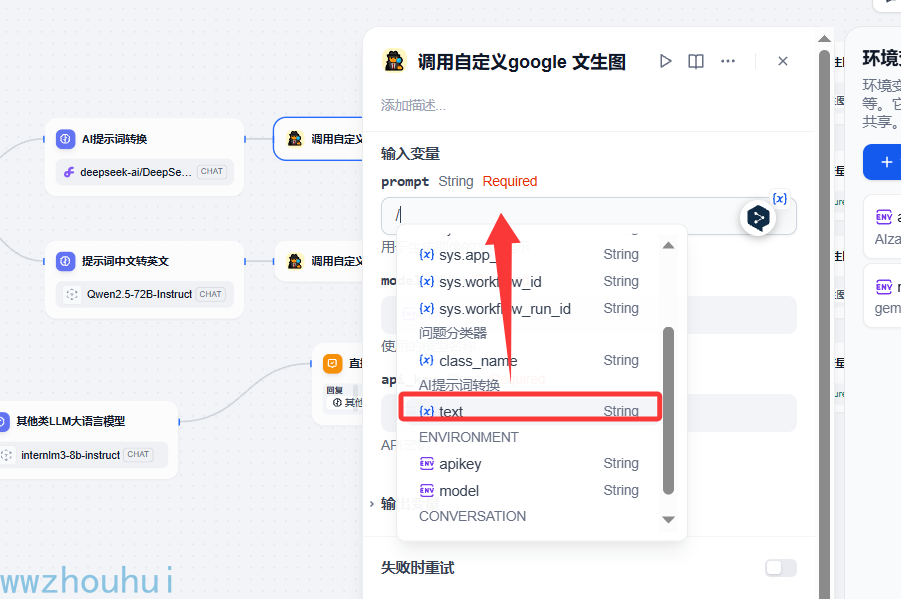
剩下的2个参数model、api_ky 从环境变量里面获取
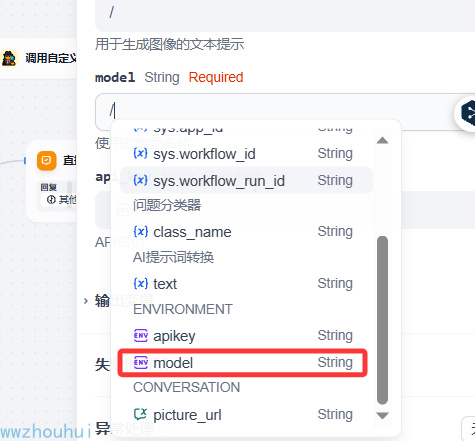
apikey和上面类似这里就不重复叙述。
调用自定义google 图片修改
调用自定义google 图片修改 上面功能类似,它有4个参数 prompt、image_url、model、api_ky
其中prompt、model、api_ky 和上述类似这里就不在重复叙述。
image_url是我们设定的会话变量
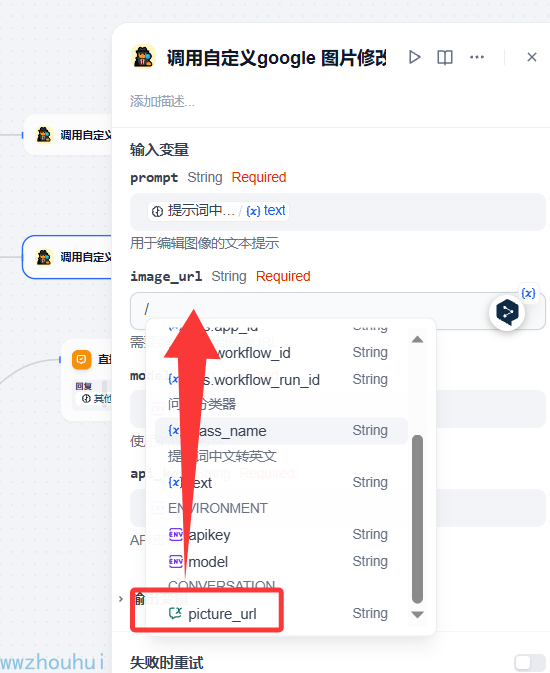
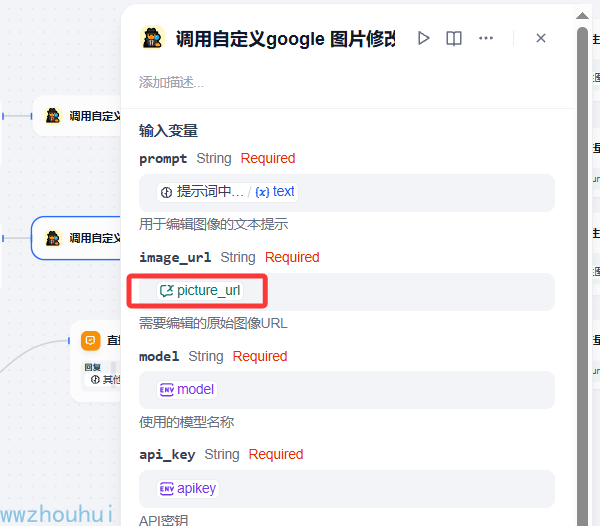
以上步骤我们就完成了用自定义google 图片修改工具的设置
代码执行
自定义工具这里处理完成后接下来我们使用代码执行来处理自定义工具代码返回。由于文生图代码提取图片URL 和图生图代码提取图片URL代码结构是一样的我们这里放在一起来讲。
输入参数 json_data, 输入值接受上个自定义工具的返回。
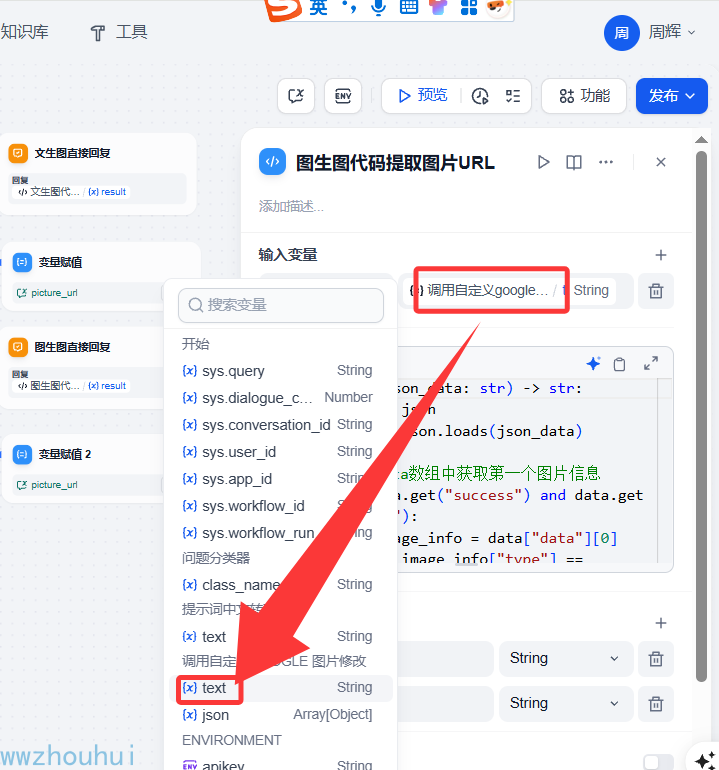
代码
def main(json_data: str) -> str:
import json
data = json.loads(json_data)
# 从data数组中获取第一个图片信息
if data.get("success") and data.get("data"):
image_info = data["data"][0]
if image_info["type"] == "image":
filename = image_info["filename"]
url = image_info["url"]
markdown_result = f""
return {"result": markdown_result,"picture_url":url}
return {"result": "No valid image found"}
返回值有2个,一个是result 格式是图片markdown格式返回,一个是图片URL
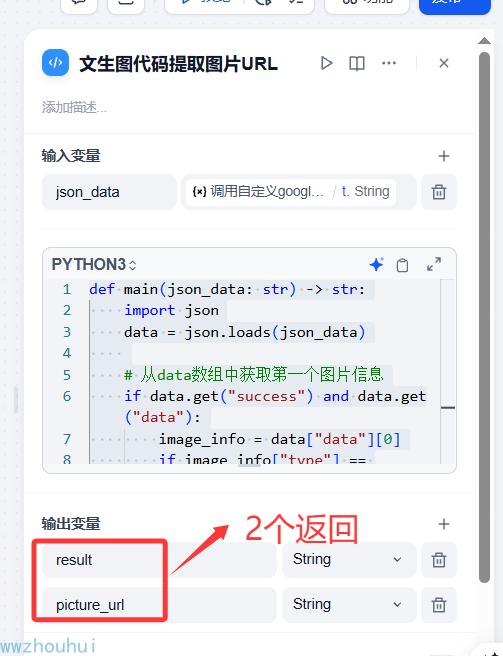
数据返回格式类型是string
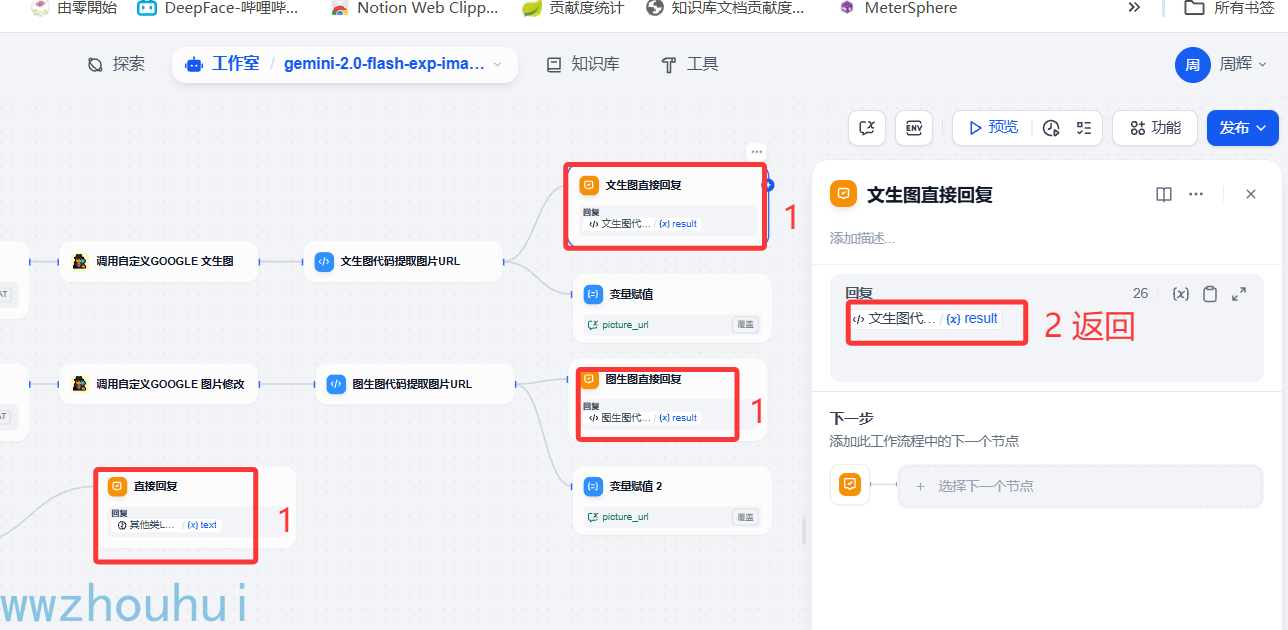
直接回复
这个直接回复流程中有三个分支,我们这里有三个直接回复终止节点。这个配置比较简单就是上个节点返回
变量赋值
这个变量赋值之前的工作流我没给大家介绍过,这个做什么用的呢?我们在进行多伦对话的时候有的时候需要大模型获取上线问的一些参数值,这里我们就用会话变量的形式保存。在下一次对话过程中我们就可以拿到这个值作为下一次对话参数值使用。
这里我们有个典型的场景就是第一次对话的时候我们的图片是没有生成的,我们需要定义一个保存图片的URL 地址,这个URL地址只有在图片生成返回的流程最后才可以拿到,这里我们在第一个流程中结束的时候一并保存这个生成图片URL
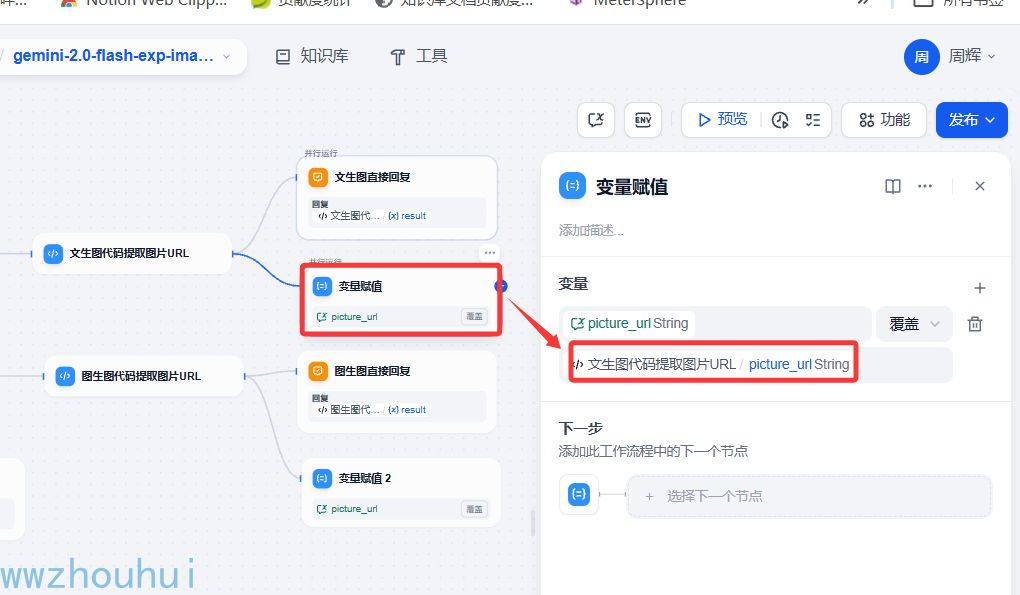
拿到这个值后我们在第二对话的时候,用户是希望对上面流程中生成的图片修改。 这个时候我们走的就是图片修复流程分支。
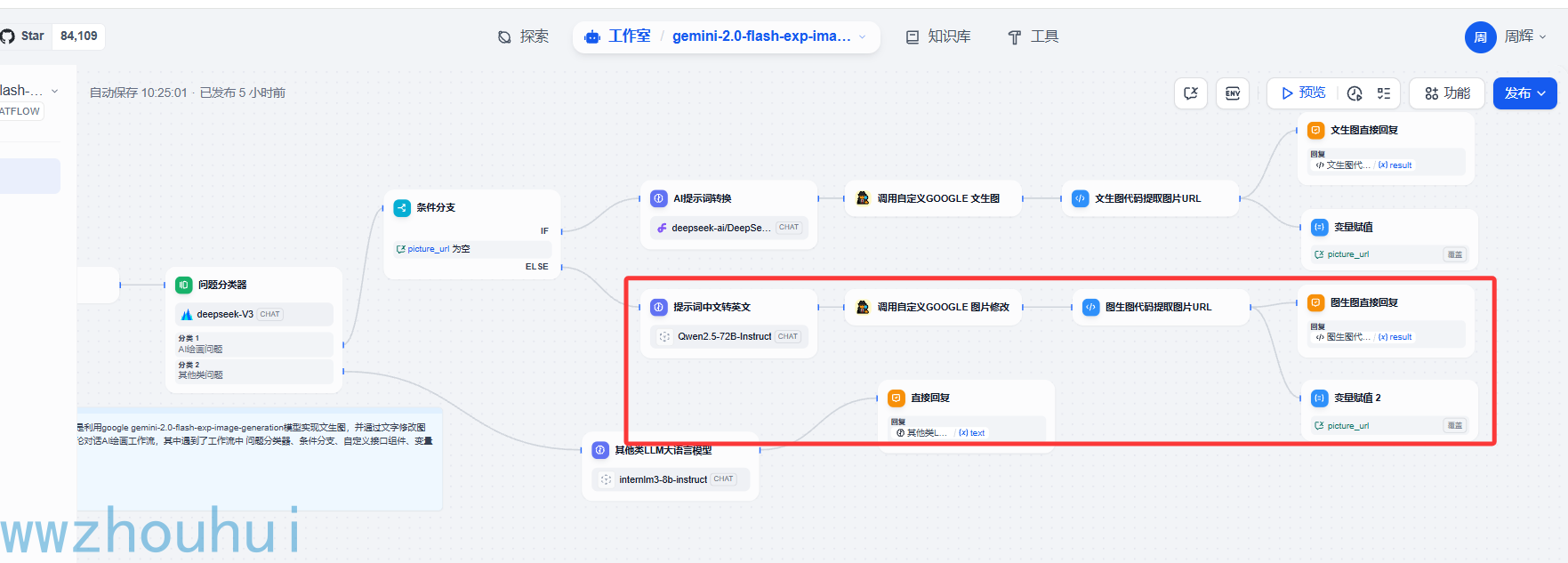
这里时候流程结束的时候我把最新的图片地址赋值给这个会话变量里面,这样它就保存用户上一次对话生成的图片。记下来后面第三轮、第四轮对话我们始终上个图片最新的URL.从而可以达到基于上个图片修改的目的。
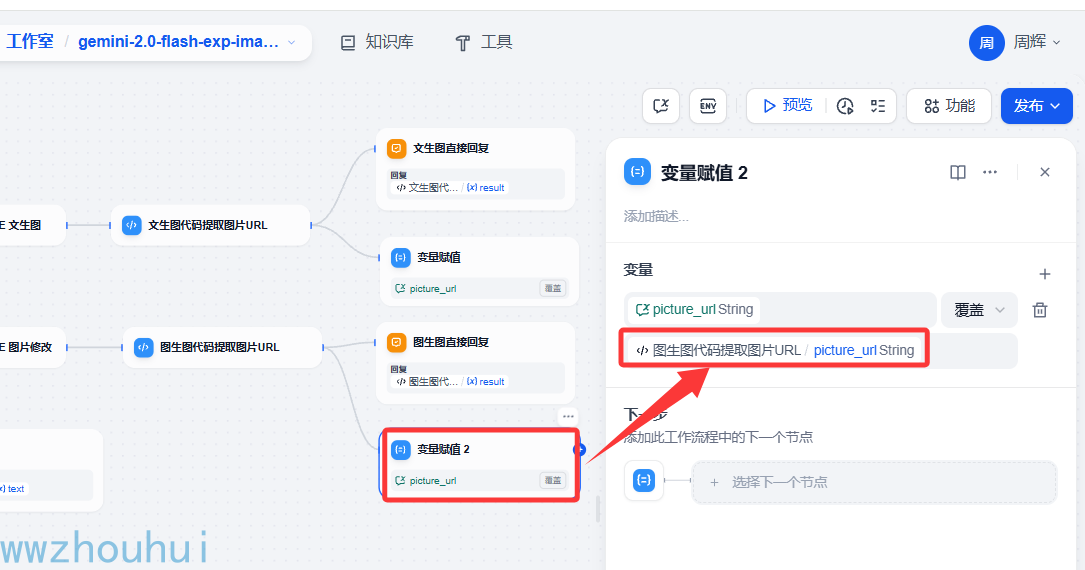
这个地方有一点点绕,这里用到了递归的思想。大家不了解也没关系照我这抄也可以了。
好了以上我们就完成了整个工作流的制作。
3.验证及测试
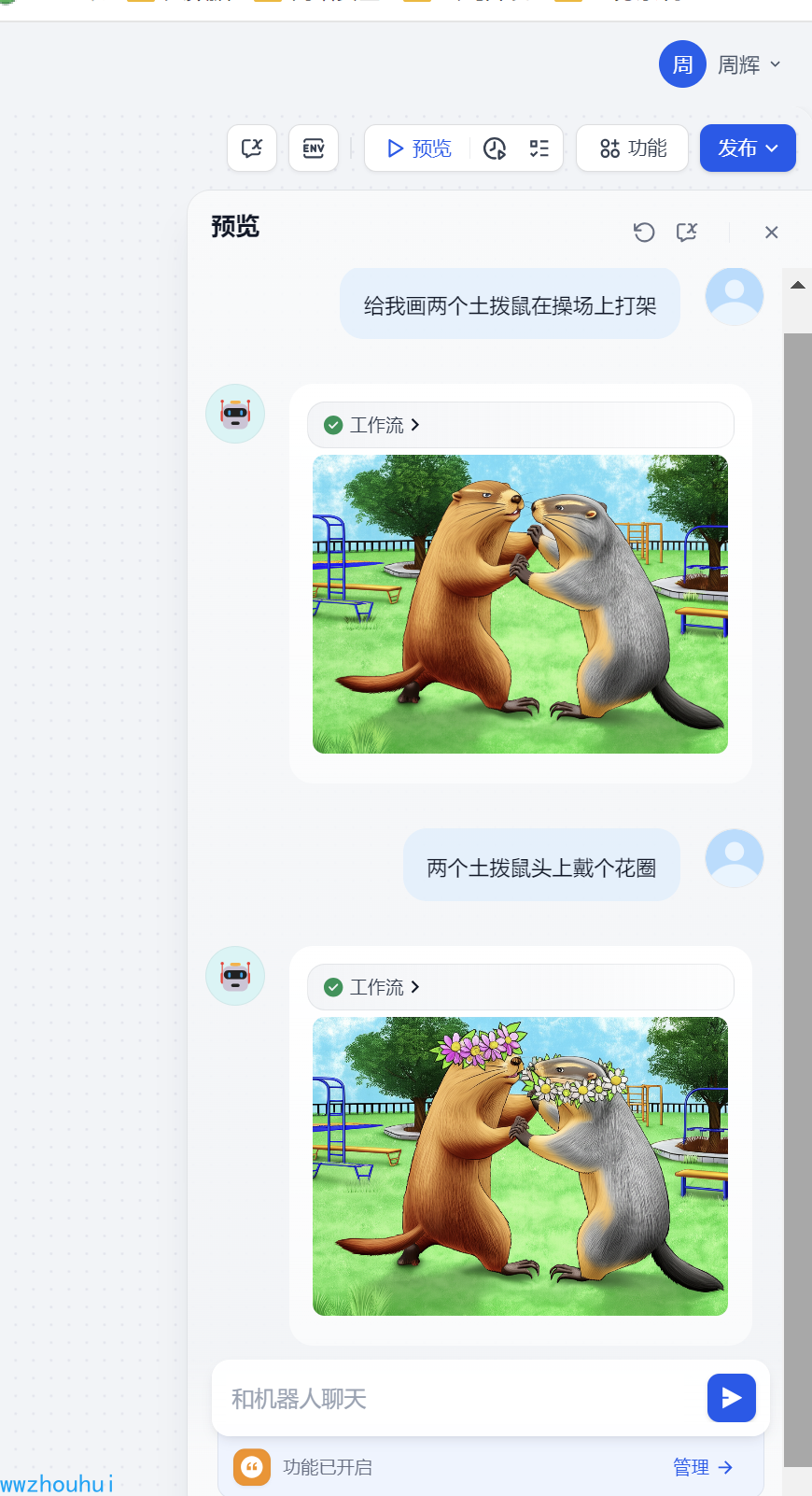
我们点击chatflow 右上角的预览按钮,在左下角输入提示词 比如:
请帮我画一个两个小松鼠在树林里打架

大家也可以使用我分享的链接体验https://dify.duckcloud.fun/chat/6miLalzV4LjRXbvp
相关资料和文档可以看我开源的项目 https://github.com/wwwzhouhui/dify-for-dsl
4.总结
今天主要带大家基于 Gemini 2.0 Flash Experimental 大模型,实现了一个利用文字生成图片以及修改图片的工作流。我详细介绍了整个工作流的实现步骤,该工作流包含开始、问题分类器、会话变量、条件分支、LLM 大模型等部分。这个工作流功能十分强大,借助 Google 大模型实现了一键改图,达成了文字 P 图的功能,基本将 P 图的门槛降低到普通人都能学会的程度。感兴趣的小伙伴可以动手尝试一下。今天的分享就到这里,我们下一篇文章再见。

















 1796
1796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









