







 本文介绍了Logistic Regression的基本原理,作为有监督学习的一种,它通过Sigmoid函数将连续输入转化为离散输出。文章讲解了Sigmoid函数的数学表达式及其图像,并指出Logistic Regression的代价函数采用交叉熵。文中还提供了Python和R实现Logistic Regression的代码示例,以及讨论了其优缺点和适用场景。
本文介绍了Logistic Regression的基本原理,作为有监督学习的一种,它通过Sigmoid函数将连续输入转化为离散输出。文章讲解了Sigmoid函数的数学表达式及其图像,并指出Logistic Regression的代价函数采用交叉熵。文中还提供了Python和R实现Logistic Regression的代码示例,以及讨论了其优缺点和适用场景。
logistic regression 基本原理
logistic regression 是机器学习的一种,从大的分类上来看属于有监督式学习,也就是说每个训练样本都有标识。
在最简单的逻辑回归中,我们一般分两类,并且在二维。(二维主要为的是可视化方便,便于理解)这个两类就是输出,从两类可以的得知这个输出是离散的。而输入的数据是连续。
怎么将输入的数据从连续的数据变成输出的离散的数据尼,这是基于logistic regression的sigmod 函数。从简单的二维来说,sigmod 函数是将 待求的参数[a,b]的转置与[x,1]想乘 然后映射到一个状态p上,然后根据状态p的大小进行分类,状态p的分类阈值通常为0.5。
sigmod 函数:1/𝑒^(−𝑎T𝑋)
这里的aT为[a,b] ,横的vector,参数为[a,b]
这里的x为[x,1]T, 竖的vector, 参数为[x,1]
sigmod 函数图像为:
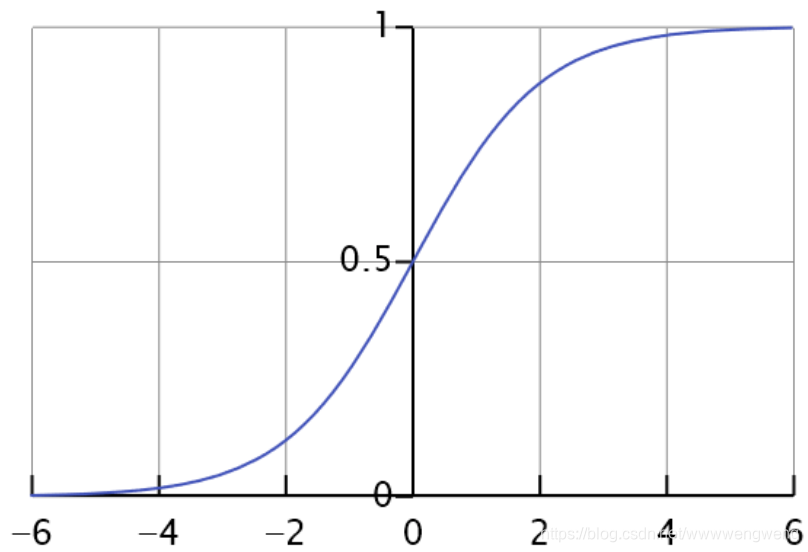
logistic regression 的cost function 使用的是交叉熵,交叉熵衡量的是对一个事件的信息量的衡量,这个事件出乎意料的程度是什么。比如说明天周日要上学这个信息量比明天周一要上学信息量大。
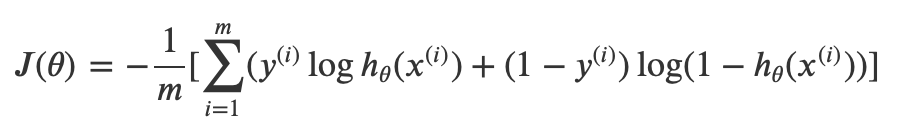
交叉熵的解释可以参考:https://blog.youkuaiyun.com/rtygbwwwerr/article/details/50778098
实现logistic regression的python代码:
##准备数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
np.random.seed(2)
X1=np.random.rand(500,2)*3
#Criterion
def c1(X1):
for i in range(len(X1)):
temp=(X1[i][0]*X1[i][1]>= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









