 Redis深度实践:安装配置到集群搭建
Redis深度实践:安装配置到集群搭建




Redis
这里是Redis7.0.9版本 下载地址:https://redis.io/download/
这里以linux下载:
wget https://github.com/redis/redis/archive/7.2-rc1.tar.gz
安装gcc编译器
yum install -y gcc-c++
tar xf 7.2-rc1.tar.gz
cd redis-7.2-rc1
make && make install
cd /usr/local/bin #默认安装位置
创建配置文件目录
mkdir /redis
cp /root/redis-7.2-rc1/redis.conf /redis/ #复制配置文件
修改/myredis目录下redis7.conf配置文件做初始化设置
vim /redis/redis.conf
redis.conf配置文件,改完后确保生效,记得重启,记得重启
默认daemonize no 改为 daemonize yes
默认protected-mode yes 改为 protected-mode no
默认bind 127.0.0.1 改为 直接注释掉(默认bind 127.0.0.1只能本机访问)或改成本机IP地址,否则影响远程IP连接
添加redis密码 改为 requirepass 你自己设置的密码
requirepass foobared
requirepass "qiya123"
341 pidfile /var/run/redis_6379.pid #运行的pid
342
343 # Specify the server verbosity level.
344 # This can be one of:
345 # debug (a lot of information, useful for development/testing)
346 # verbose (many rarely useful info, but not a mess like the debug level)
347 # notice (moderately verbose, what you want in production probably)
348 # warning (only very important / critical messages are logged)
349 loglevel notice
350
351 # Specify the log file name. Also the empty string can be used to force
352 # Redis to log on the standard output. Note that if you use standard
353 # output for logging but daemonize, logs will be sent to /dev/null
354 logfile "/redis/logs/redis6379.log" #运行的日志文件存放位置
启动redis
redis-server /redis/redis.conf
redis-cli -a 设置的密码 -p 6379
测试 ping pong
常用数据类型
keys * //当前库的所有key
exists key //判断某个key是否存在
type key //查看你的key是什么类型
del key //删除指定的key数据
unlink key //非阻塞删除,仅将keys从keyspace元数据中删除,没真正的删除会在后续异步中操作
ttl key // 查看还有多少秒过期 -1表示永不过期 -2 表示已过期
expire key 秒 // 给key设置过期时间
move key dbindex [0-15] // 将当前数据库的key移动到指定的数据库中 redis默认是有16个数据库的
select dbindex [0-15] // 切换数据库[0-15],默认为0
dbsize // 查看当前数据库key的数量
flushadd // 清空当前库
flushall // 清空16个数据库 慎用
10大数据类型
1.字符串(String)
- string是redis最基本的类型,一个key对应一个value。
- string类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象 。
- string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
set k1 v1 #默认就是存在则改变,不存在创建
set k1 v1 nx #不存在则建值
set k1 v1 xx #存在则创建值
set k1 v1 ex 10 #设置值的过期时间
ttl k1 #查看过期时间
显示-1是不过期,-2是已经过期了
同时设置,获取多个值
mset k1 v1 k2 v2 k3 v3
mget k1 k2 k3
1) "v1"
2) "v2"
3) "v3"
截取范围内的字符串
set k1 abcd123
GETRANGE k1 0 -1 #截取全部
"abcd123"
GETRANGE k1 0 3 #截取前4个,从0开始
"abcd"
SETRANGE k1 1 xxxx #从第二个字符开始替换
get k1
"axxxx23"
数字增值,减值 INCRBY k1 1 DECRBY k1 1
只有数字可以增值
set k1 100
INCRBY k1 1 #增值 用于用户点赞,+1
(integer) 101
INCRBY k1 1
(integer) 102
INCRBY k1 1 #减值
(integer) 101
追加值
APPEND k1 xxx
在k1的值后面添加xxx
应用
- dy点赞某个视频或商品,点一次加一次
- 使用incr key 获得多少人喜欢
- 对于文章是否喜欢
- 使用incr key 获得多少人喜欢
2.列表(list)
一个双端链表的结构,容量是2的32次方减1个元素,大概40多亿,主要功能有push/pop等,一般用在栈、队列、消息队列等场景
left、right都可以插入添加;
如果键不存在,创建新的链表
如果键已存在,新增内容
如果键全移除,对应的键也就消失了
底层就是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差
RPUSH list1 10 11 12 13 14 15 #从左到右依次取值
LPUSH list2 1 2 3 4 5 #从右到左取值
LRANGE list1 0 -1
1) "10"
2) "11"
3) "12"
4) "13"
5) "14"
6) "15"
RANGE list2 0 -1
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
取某一个值
LINDEX list1 0 #取第0个值
"10"
改变一段的值
LRANGE list1 0 -1
1) "10"
2) "11"
3) "12"
4) "13"
5) "14"
6) "15"
7) "16"
8) "17"
LTRIM list1 4 7 #0开始到4-7
LRANGE list1 0 -1 #查看
1) "14"
2) "15"
3) "16"
4) "17"
RPOPLPUSH list1 list2 #把list1的最后一个值传输到list2的开头
lset list1 0 mysql #设置第一个值为mysql
127.0.0.1:6379> LRANGE list1 0 -1
1) "mysql"
2) "15"
3) "16"
LINSERT list1 before mysql java #指定插入到已有数据的前(before)|后(after)
(integer) 4 #把java插入到mysql前面
127.0.0.1:6379> LRANGE list1 0 -1
1) "java"
2) "mysql"
3) "15"
4) "16"
应用
- 公众号的订阅的消息
- 关注的人发布文章,就会到我的List lpush likearticle:id 文章id
- 查看自己订阅的文章 lrange likearticle:id 0 9
3.哈希(hash)
hmset user id 12 name li4 age 23 #一次性设置多个值
OK
127.0.0.1:6379> hmget user id name age #查看值
1) "12"
2) "li4"
3) "23"
hgetall user #查询所有值
1) "id"
2) "12"
3) "name"
4) "li4"
5) "age"
6) "23"
HKEYS user #查询所有的键
1) "id"
2) "name"
3) "age"
127.0.0.1:6379> HVALS user #查看所有的值
1) "12"
2) "li4"
3) "23"
应用
- 早期购物车设计,基本不用了,中小厂可用
4.集合(set)
和list相似,但是不能有重复值,单值多value,且不重复
sadd set1 1 1 1 2 2 2 3 3 4 5 #设置多值,但是自动去重
(integer) 5
SMEMBERS set1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
SRANDMEMBER set1 #随机出现一个值,不删除
SRANDMEMBER set1 3
1) "3"
2) "2"
3) "1"
SMEMBERS set1 #查看集合内的所有值
1) "1"
2) "3"
3) "4"
4) "5"
集合运算
sadd set1 a b c 1 2 #设置set1和set2的值
sadd set2 1 2 3 a x
差集
sdiff set1 set2 #set1和set2的差集
1) "b"
2) "c"
sdiff set2 set1 #set2和set1的差集
1) "3"
2) "x"
并集
SUNION set1 set2
1) "a"
2) "b"
3) "c"
4) "1"
5) "2"
6) "3"
7) "x"
交集
SINTER set1 set2
1) "a"
2) "1"
3) "2"
集合常用于社交,你可能认识的人,微信朋友圈点赞查看同赞的朋友
1 新增点赞
sadd pub:msgID 点赞用户ID1 点赞用户ID2
2 取消点赞
srem pub:msgID 点赞用户ID
3 展现所有点赞过的用户
SMEMBERS pub:msgID
4 点赞用户数统计,就是常见的点赞红色数字
scard pub:msgID
5 判断某个朋友是否对楼主点赞过
SISMEMBER pub:msgID 用户ID
应用
抽象小程序
- 将所有抽奖用户 sadd key 用户ID
- 显示多少人参加 SCARD key
- 从set中任意选取N个中奖人
- SRANDMEMBER key 2 随机抽奖两个人,元素不删除
- SPOP key 2 随机抽奖两个人,元素会删除
朋友圈点赞
新增点赞 SADD pub:msgID 点赞用户Id1 点赞用户Id2
取消点赞 SREM pub:msgID 点赞用户Id
展现所有点赞过的用户 SMEMBERS pub:msgID
点赞用户统计 SCARD pub:msgID
判断某个朋友是否对楼主点赞过 SISMEMBER pub:msgID 用户Id
- 可能认识的人
- 求两个人的差集 SDIFF user1 user2
5.有序集合(zset)
zadd set1 60 v1 70 v2 80 v3 90 v4 100 v5 #添加值
ZRANGE set1 0 -1 #仅查看值
1) "v1"
2) "v2"
3) "v3"
4) "v4"
5) "v5"
ZRANGE set1 0 -1 withscores #查看键值
1) "v1"
2) "60"
3) "v2"
4) "70"
5) "v3"
6) "80"
7) "v4"
8) "90"
9) "v5"
10) "100"
取值(包含)
ZRANGEBYSCORE set1 60 90 withscores #取60-90的值
1) "v1"
2) "60"
3) "v2"
4) "70"
5) "v3"
6) "80"
7) "v4"
8) "90"
取值(不包含)
RANGEBYSCORE set1 (60 90 withscores #取值不在60-90内的值
1) "v2"
2) "70"
3) "v3"
4) "80"
5) "v4"
6) "90"
常用于对商品进行排序
应用:
根据商品销售对商品进行排序显示
6.位图(bitmap)
由0和1状态表现的二进制位的bit数组
常用于签到判断
bitmap的偏移量是从0开始的!
setbit k1 0 1 #第一天 1表示签到,0表示为签到
(integer) 1
setbit k1 1 1 #第二天
(integer) 1
setbit k1 2 0 #第三天
(integer) 1
setbit k1 3 0 #第四天
(integer) 0
setbit k1 4 1 #第五天
(integer) 1
bitcount k1 0 30 #统计用户一个月签到了多少天
(integer) 7
7.基数统计(HyperLogLog)
- 去重复统计功能的基数估计算法就是 HyperLogLog
- 基数
- 是一种数据集,去重复后的真实个数
- 基数统计
- 用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算
pfadd set1 1 3 4 5 7 9 #设值
(integer) 1
pfadd set2 1 2 4 4 4 5 9 10 #设值
(integer) 1
pfcount set1 #取set1里面的不相同的值有多少个
(integer) 6
pfcount set2 #取set2里面的不相同的值有多少个
(integer) 6
PFMERGE hllresult set1 set2 #将多个hyperloglog合并为一个hyperloglog
OK
PFCOUNT hllresult #取出合并的不相同的个数
(integer) 8
应用
- 统计某个网页的UV、某个文章的UV
- UV Unique Visitor 独立访客,一般理解为客户端IP,需要去重
- 用户搜索网站关键词数量
- 统计用户每天搜索不同词条个数
8.地理空间(GEO)
介绍
地球上的地理位置是使用二维的经纬度表示,经度范围 (-180, 180],纬度范围 (-90, 90],只要我们确定一个点的经纬度就可以名取得他在地球的位置。
例如滴滴打车,最直观的操作就是实时记录更新各个车的位置
然后当我们要找车时,在数据库中查找距离我们(坐标x0,y0)附近r公里范围内部的车辆
基本命令
经纬度去地图上直接复制
添加地点和坐标
GEOADD city 116.403963 39.915119 "天安门" 116.403414 39.924091 "故宫" 116.024067 40.362639 "长城"
ZRANGE city 0 -1 #显示地点
天安门
故宫
长城 #解决乱码 redis-cli -a qiya123 --raw
GEOPOS city 天安门 故宫 长城 #显示经纬度
GEOHASH city 天安门 故宫 长城 #将经纬度转换为字符串
wx4g0f6f2v0
wx4g0gfqsj0
wx4t85y1kt0
GEODIST city 天安门 长城 km #天安门距离长城的距离KM单位
59.3390
georadius 以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord count 10 withhash desc
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord withhash count 10 desc
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。WITHCOORD: 将位置元素的经度和维度也一并返回。WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大COUNT 限定返回的记录数。
#这个经纬度 10KM以内的 取前10个地址
GEORADIUS city 116.418017 39.914402 10 km withdist withcoord count 10 withhash desc
故宫
1.6470 #距离
4069885568908290
116.40341609716415405
39.92409008156928252
天安门
1.2016 #距离
4069885555089531
116.40396326780319214
39.91511970338637383
应用
- 美团附近的饭店、酒店
- 高德地图附近的店
9.流(Stream)
介绍
- 实现消息队列的三个方式
- List实现消息队列
- Pub/Sub 发布订阅
- Stream流 (Redis版的MQ消息中间件+阻塞队列)
用的很少,省略
10.位域(bitfield)
介绍
- 将很多小的整数存储到一个长度较大的位图中,又或者将一个非常庞大的键分割位多个较小的键来进行储存,从而高效利用内存
- 也就是将 Redis 字符串看作是一个 由二进制位组成的数组 并能对变长位宽和任意没有字节对齐的指定整型位域进行寻址和修改
用的很少,省略
Redis持久化
RDB(Redis Data Base)持久化
RDB(Redis 数据库):RDB 持久性以指定的时间间隔执行数据集的时间点快照。
在指定的时间间隔,执行数据集的时间点快照
实现类似照片记录效果的方式,就是把某一时刻的数据和状态以文件的形式写到磁盘上,也就是快照。这样一来即使故障宕机,快照文件也不会丢失,数据的可靠性也就得到了保证。
这个快照文件就称为RDB文件(dump.rdb),其中,RDB就是Redis DataBase的缩写。
将内存数据全部保存到磁盘dump.rdb文加中。
vim /redis/redis.conf
################################ SNAPSHOTTING ################################
# Save the DB to disk.
# save <seconds> <changes> [<seconds> <changes> ...]
# Redis will save the DB if the given number of seconds elapsed and it
# surpassed the given number of write operations against the DB.
# Snapshotting can be completely disabled with a single empty string argument
# as in following example:
# save ""
# Unless specified otherwise, by default Redis will save the DB:
# * After 3600 seconds (an hour) if at least 1 change was performed
# * After 300 seconds (5 minutes) if at least 100 changes were performed
# * After 60 seconds if at least 10000 changes were performed
#
# You can set these explicitly by uncommenting the following line.
#
# save 3600 1 300 100 60 10000
save 3600 1 300 100 60 100 // 3600秒 修改一次 100秒 修改60次 60秒 修改10000次 触发保存
......
# The filename where to dump the DB
486 dbfilename dump6379.rdb #dump文件名称
......
# The working directory.
502 #
503 # The DB will be written inside this directory, with the filename specified
504 # above using the 'dbfilename' configuration directive.
505 #
506 # The Append Only File will also be created inside this directory.
507 #
508 # Note that you must specify a directory here, not a file name.
509 dir /redis/dumpfile #dump.rdb文件的保存地址
mkdir /redis/dumpfile
注意:
shutdown和FLUSHDB会生成新的dump文件!
备注:不可以把备份文件dump.rdb和生产redis服务器放在同一台机器,必须分开各自存储,
以防生产机物理损坏后备份文件也挂了。
手动触发备份
物理恢复,一定服务和备份分机隔离,各自存储
恢复备份手动操作
-
Save
- 在主线程中执行会阻塞redis服务器,直到持久化工作完成才能处理其他命令, 线上禁止使用
-
BGSAVE(默认)
- Redis 会在后台异步进行快照操作,不阻塞快照同时还可以响应客户端请求,该触发过程会 fork 一个子进程由子进程复制持久化过程
- lastsave 命令可以获取最后一次成功执行快照的时间
优劣势
优势
- 适合大规模的数据恢复
- 按照业务定时备份
- 对数据完整性和一致性要求不高
- RDB 文件在内存中的加载速度比AOF快得多
劣势
-
在一定间隔时间做一次备份,如果redis意外down机,就会丢掉最近一次快照到down机时的数据
-
内存数量的全量同步,如果数据量过大会导致IO严重影响服务器性能
-
RDB依赖于主进程的 fork ,在更大的数据集中,这可能会导致服务器请求的瞬间延迟
-
fork 的时候内存中的数据被克隆了一份,大致2倍的膨胀性,需要考虑
哪些情况会触发RDB快照
- 配置文件中默认的快照配置
- 手动 save/bgsave 命令
- 执行flush / flushdb 命令也会产生 dump.rdb 文件,但里面是空的,无意义
- 执行 shutdown 且没有设置开启 AOF 持久化
- 主从复制时,主节点自动触发
AOF 持久化
介绍
-
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
-
默认情况下,redis是没有开启AOF的
- 开启AOF 功能需要设置配置 : appendonly yes
AOF 缓冲区三种写回策略
三种写回策略
- always 同步写回,每个写命令执行完立刻同步地将日志写回磁盘
- everysec 每秒写回,每个写命令执行完,只是先把日志写到AOF缓冲区,每隔1s把缓存区地数据写入磁盘
- 操作系统控制协会,只是将日志先写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
AOF粗略的说就是记住写命令到文件,恢复就是把文件里面的命令重新执行一遍
1425 # Redis supports three different modes:
1426 #
1427 # no: don't fsync, just let the OS flush the data when it wants. Faster.
1428 # always: fsync after every write to the append only log. Slow, Safest.
1429 # everysec: fsync only one time every second. Compromise.
1430 #
1431 # The default is "everysec", as that's usually the right compromise between
1432 # speed and data safety. It's up to you to understand if you can relax this to
1433 # "no" that will let the operating system flush the output buffer when
1434 # it wants, for better performances (but if you can live with the idea of
1435 # some data loss consider the default persistence mode that's snapshotting),
1436 # or on the contrary, use "always" that's very slow but a bit safer than
1437 # everysec.
1438 #
1439 # More details please check the following article:
1440 # http://antirez.com/post/redis-persistence-demystified.html
1441 #
1442 # If unsure, use "everysec".
1443
1444 #appendfsync always
1445 appendfsync everysec #模式
always 同步写回 可靠性高,数据基本不丢失 每个写命令都记录到磁盘,对性能有影响
everysec 每秒写会 性能适中 宕机丢失1秒内的数据
no 操作系统控制 性能好 宕机丢失数据很多
AOF文件保存地址
508 # Note that you must specify a directory here, not a file name.
509 # dir /redis/dumpfile #dump.rdb文件的保存地址
dir /redis #添加aof文件的保存地址
........
1380 # AOF and RDB persistence can be enabled at the same time without problems.
1381 # If the AOF is enabled on startup Redis will load the AOF, that is the file
1382 # with the better durability guarantees.
1383 #
1384 # Please check https://redis.io/topics/persistence for more information.
1385
1386 appendonly yes #修改为yes
..................
1411 # - appendonly.aof.manifest as a manifest file.
1412
1413 appendfilename "appendonly.aof" #文件名称
1414
1415 # For convenience, Redis stores all persistent append-only files in a dedicated
1416 # directory. The name of the directory is determined by the appenddirname
1417 # configuration parameter.
1418
1419 appenddirname "appendonlydir" #文件夹名称
所以完整保存路径是: /redis/appendonlydir/appendonly.aof
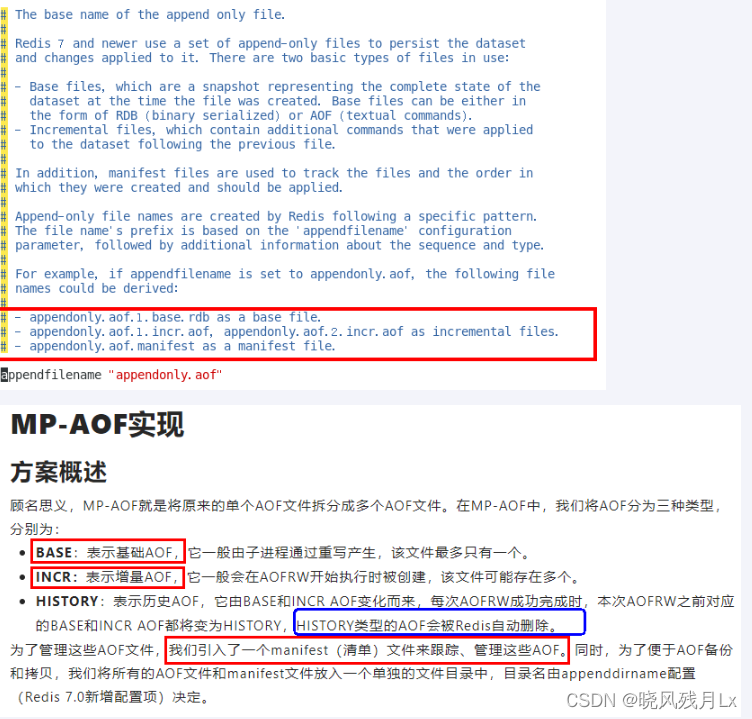
重启redis,随便设置几个值
[root@10 redis]#ll appendonlydir/
total 12
-rw-r--r-- 1 root root 90 Apr 8 02:05 appendonly.aof.1.base.rdb
-rw-r--r-- 1 root root 110 Apr 8 02:06 appendonly.aof.1.incr.aof #命令文件
-rw-r--r-- 1 root root 88 Apr 8 02:05 appendonly.aof.manifest
#可以看到文件已经生成
如果命令文件有错误可进行修复 redis-check-aof --fix appendonly.aof.1.incr.aof
优劣势
优势
- 更好的保护数据不丢失、性能高、可做紧急恢复
劣势
- 相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb
- aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
AOF重写机制
启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集
1487 auto-aof-rewrite-percentage 100 #同时满足才会触发重写机制
1488 auto-aof-rewrite-min-size 64mb
自动触发
- 满足配置文件中的选项后,Redis会记录上次重写时地AOF大小
- 默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时
手动触发
- 客户端向服务器发送 bgrewriteaof 命令
**现象:**也就是一旦重写就会生成新的base、incr文件,去替换之前的,把incr里面的数据压缩导入到base里面
RDB - AOF混合持久化(建议)
数据恢复顺序和加载流程
共存听AOF的
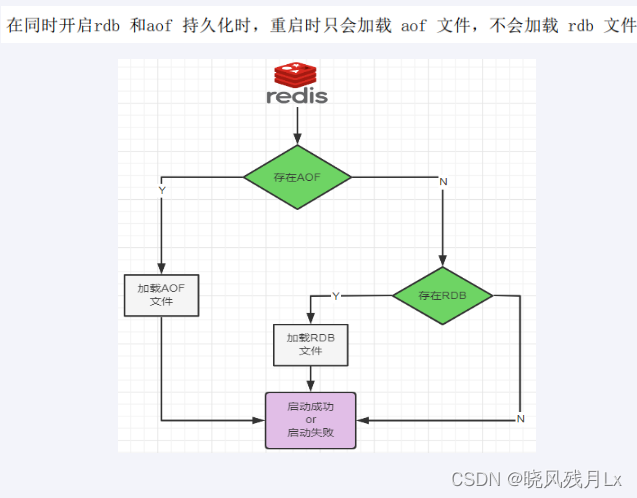
同时开启两种持久化方式
- 当redis 重启时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整
- RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。
- 那要不要只使用AOF呢
- 安特雷兹建议不要
- 因为RDB更适合用于备份数据库(AOF不断变化不好备份),留着AOF作为一个万一的手段
- 那要不要只使用AOF呢
开启混合方式设置
设置aof-use-rdb-preamble的值为 yes yes表示开启,设置为no表示禁用
aof-use-rdb-preamble yes
2 RDB+AOF的混合方式---------> 结论:RDB镜像做全量持久化,AOF做增量持久化
纯缓存模式(不建议)
同时关闭RDB + AOF
-
save " "
- 禁用rdb
- 禁用db持久化模式下,我们仍然可以使用命令save、bgsave生成rdb文件
-
appendonly no
- 禁用aof
- 禁用aof持久化模式下,我们仍然可以使用命令 bgrewriteaof生成aof文件
Redis 事务
介绍
- 可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化, 按顺序地串行化执行而不会被其他命令插入,不许加塞
- 一个队列中,一次性、顺序性、排他性的执行一系列命令
1.单独的隔离操作:redis的事务仅仅是保证事务里的操作会被连续独占的执行,redis命令执行的单线程架构,在执行完事务内所有指令前是不可能再去同时执行其他客户端的请求的
2.没有隔离级别的概念因为事务提交前任何指令都不会被实际执行,也不会存在“事务内的查询要看到事务里的更新,在事务外查询不能看到这种问题了”
3.不保证原子性redis的事务不保证原子性,也就是不保证所有指令同时成功或者同时失败,只有决定是否开始执行全部指令的能力,没有执行到一般回滚的能力
4.排它性redis会保证一哈事务的命令依次执行,而不会被其他命令插入
正常执行
MULTI // 事务开始
set k1 v1 #中间写命令
set k2 v2
set k3 v3
EXEC // 执行事务
放弃事务
MULTI // 事务开始
DISCARD // 放弃事务
全体连坐
MULTI // 事务开始
#在MULTI 和 EXEC 之间有一个指令语法错误,所有的命令都不会执行,
EXEC // 执行
冤头债主
- Redis 不提供事务回滚的功能,开发者必须在事务执行出错后,自行恢复数据库状态
- 注意和传统数据库事务区别,不一定要么一起成功要么一起失败
MULTI // 事务开始
#成功的成功,错误的错误,不会影响整体
EXEC // 执行
管道
cat test.txt
set k1 v1
set k2 v2
set k3 v3
set k4 v4
hset k300 name haha
hset k300 age 20
hset k300 gender male
cat test.txt |redis-cli -a qiya123 --pipe #通过管道符将数据输入到redis中
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 7
小总结
-
Pipeline 与原生批量
-
原生批量命令是原子性(如:mset,mget),pipeline是非原子性
-
原生批量命令一次只能执行一种命令,pipeline支持批量执行不同命令
-
原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
Pipeline 与事务对比
- 事务具有原子性,管道不具有原子性
- 管道一次性将多条命令发送到服务器,事务是一条一条发的,事务只有在接收到exec命令后才会执行,管道不会
- 执行事务时会阻塞其他命令的执行,而执行管道中的命令时不会
Pipeline 注意事项
- pipeline缓冲的指令只是会依次执行,不保证原子性,如果执行中指令发生异常,将会继续执行后续的指令
- 使用pipeline组装的命令个数不能太多,不然数据量过大客户端阻塞的时间可能过久,同时服务器也被迫回复一个队列答复,占用很多内存
Redis主从复制
介绍
基本操作
- 配从不配主
- 权限细节
- master如果配置了 requirepass 参数,需要密码登录
- slave 需要配置 masterauth来设置检验密码,否则的话master会拒绝slave的访问请求
- 权限细节
实验:一主二从
10.0.0.11 端口为:6379 主
10.0.0.12 端口为:6380 从
10.0.0.13 端口为:6381 从
3台主机都安装开启redis
从机配置
默认daemonize no 改为 daemonize yes
默认protected-mode yes 改为 protected-mode no
默认bind 127.0.0.1 改为 直接注释掉(默认bind 127.0.0.1只能本机访问)或改成本机IP地址,否则影响远程IP连接
port 改为相对应的端口
添加redis密码 改为 requirepass 你自己设置的密码
requirepass "qiya123"
341 pidfile /var/run/redis_6379.pid #运行的pid
354 logfile "/redis/logs/redis6379.log" #运行的日志文件存放位置
486 dbfilename dump6379.rdb
dir /redis #指定aof文件存放位置
appendonly yes
533 # replicaof <masterip> <masterport>
replicaof 10.0.0.11 6379 #写主服务器的ip地址和端口号
540 # masterauth <master-password>
masterauth "qiya123" #主服务器的redis密码
mkdir /redis/logs/ #创建日志目录
依次启动主master --从–从
登陆至master机器上
info #显示机器信息
# Replication
role:master
connected_slaves:2
slave0:ip=10.0.0.12,port=6379,state=online,offset=98,lag=0 #从机器上线
slave1:ip=10.0.0.13,port=6379,state=online,offset=98,lag=0 #从机器上线
master_failover_state:no-failover
master_replid:fa1fba80056b3f7683ae6180e1d66c3146929056
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:98
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:98
如果有报错信息请看日志文件
-
方案2 命令操作手动指定
- 去掉配置文件中配置的从属关系
- replicaof/slaveof no one 升级为主机
- replicaof/slaveof 主库IP 主库端口 称为主库的从机
- 配置VS命令的区别
- 配置,持久稳定
- 命令,当次生效
薪火相传
- 上一个slave可以是下一个slave的master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master,可以有效减轻主master的写压力
- 中途变更转向:会清除之前的数据,重新建立拷贝最新的
- slaveof/replicaof 新主库IP 新主库端口
反客为主
- slaveof/replicaof no one 使当前数据库停止与其他数据库的同步,转成主数据库
复制原理
-
slave启动成功连接到master后会发送一个sync命令
-
slave首次全新连接master,一次完全同步(全量复制)将被自动执行,slave自身原有数据会被master数据覆盖清除
-
首次连接,全量复制
-
master节点收到sync命令后会在后台开始保存快照(即RDB持久化,主从复制会触发RDB),同时收集所有接收到的用于修改数据集命令缓存起来,master节点执行RDB持久化后,master将rdb快照文件和缓存的命令发送到所有slave,已完成一次完全同步
-
而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中,从而完成复制初始化
-
-
心跳持续,保持通信
-
repl-ping-replica-period 10
-
master发出PING包的周期,默认是10秒
-
进入平稳,增量复制
-
master 继续将新的所有收集到的修改命令自动一次传给slave,完成同步
-
从机下线,重连续传
- master 会检查backlog里面的offset,master和slave都会保存一个复制的offset怀有一个masterId
- offset 是保存在backlog 中的。master只会把已经复制的offset后面的数据赋值给slave,类似断电续传
缺点
- master 会检查backlog里面的offset,master和slave都会保存一个复制的offset怀有一个masterId
复制延时,信号衰减
- 由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
- master挂了
- 默认情况下不会在slave节点自动重选一个master
- 需要人工干预
Redis哨兵
-
哨兵巡查监控后台master主机是否故障,如果故障了根据投票数自动将某一个从库转换为新主库,继续对外服务,俗称无人值守运维
-
作用
- 监控redis运行状态,包括master和slave
- 当master down机,能自动将slave切换成新master
哨兵的四个功能
主从监控
监控主从redis库运行是否正常
消息通知
哨兵可以将故障转移的结果发送到客户端
故障转移
如果master异常,则会进行主从切换,将其中一个slave作为新master
配置中心
客户端通过连接哨兵来获得当前Redis服务的主节点地址
- 3个哨兵
- 自动监控和维护集群,不存放数据,只是监控
- 1主2从
- 用于数据读取和存放
机器架构说明
共6台机器
10.0.0.11 port 6379 主master
10.0.0.12 port 6380 从slave
10.0.0.13 port 6381 从slave
10.0.0.14 port 26389 哨兵(监控,不存放数据)
10.0.0.15 port 26389 哨兵(监控,不存放数据)
10.0.0.16 port 26389 哨兵(监控,不存放数据)
在哨兵机器上
cp /root/redis-7.2-rc1/sentinel.conf /redis/ #拷贝哨兵的配置文件
默认daemonize no 改为 daemonize yes
默认protected-mode yes 改为 protected-mode no
port 改为相对应的端口
pidfile /var/run/redis-sentinel.pid #运行的pid
logfile "/redis/logs/redis-sentinel.log" #运行的日志文件存放位置
dir /redis #指定aof文件存放位置
sentinel monitor <master-name> <ip> <redis-port> <quorum> 哨兵的配置
<quorum>:投票数,要几个票数来决定master主机是否下线了3台机器投票数为2,哨兵机器数量一定为奇数
sentinel auth-pass mymaster qiya123 #master主机的密码
sentinel notification-script <master-name> <script-path>
配置当某一事件发生时所需要执行的脚本
sentinel client-reconfig-script <master-name> <script-path>
客户端重新配置主节点参数脚本
bind 0.0.0.0
daemonize yes
protected-mode no
port 26379
logfile "/redis/logs/redis-sentinel.log"
pidfile /var/run/redis-sentinel.pid
dir /redis
sentinel monitor master 10.0.0.11 6379 2
sentinel auth-pass master qiya123
在master主机上设置
masterauth "qiya123" #因为主master下线后上线会变成从,所以需要配置密码
然后分别启动master和两台slave
redis-server /redis/redis.conf #master和2个从机器都启动
连接master机器
redis-cli -a qiya123
info
# Replication
role:master
connected_slaves:2
slave0:ip=10.0.0.12,port=6380,state=online,offset=70,lag=0 #从机上线了
slave1:ip=10.0.0.13,port=6381,state=online,offset=70,lag=0 #从机上线了
master_failover_state:no-failover
master_replid:d9e19886de23483d3df7893f00e1af79238c6692
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:70
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:70
启动哨兵监控主机
redis-sentinel sentinel.conf --sentinel #在哨兵机器上执行
查看端口
ss -tunl |grep 26379
tcp LISTEN 0 128 *:26379 *:*
tcp LISTEN 0 128 [::]:26379 [::]:*
-
关闭6379服务器,模仿master挂了
- 两台从机的数据不会丢失
- 会从其他两台从机选出一个新的master
- 挂掉的master重连回来,直接变成新master的从机
哨兵运行流程和选举原理
当一个主从配置中的master失效之后,sentinel可以选举出一个新的master,用于接替原master的工作,主从配置中其他redis服务器自动指向新的master同步数据。一般建议sentinel采用奇数台,防止某一台sentinel无法连接到master导致误切换。
选举出领导者哨兵
- 当主节点被判断客观下线以后,各个哨兵节点会进行协商,县选举出一个领导者哨兵节点并由该领导者节点进行failover(故障迁移)
- Raft算法 选出领导者节点

-
由领导者节点开始推动故障切换并选出一个新master
-
新主登基
- 某个slave 备选成为新 master
-
群臣俯首
- 一朝天子一朝臣,重新认老大
-
旧主拜服
- 老master回来也得怂
-
-
以上的failover都是sentinel自己独立完成,完全无需人工干预
使用建议
- 哨兵节点的数量应为多个,哨兵本身应该集群,保证高可用
- 哨兵节点的数量应该是奇数个
- 各个哨兵节点的配置应该一致
- 如果哨兵节点部署在Docker等容器里,要注意端口的正确映射
- 哨兵集群+主从复制,并不能保证数据零丢失
Redis集群(重点)
介绍
由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序集.
Redis集群是一个提供在多个Redis节点间共享数据的程序集
Redis集群可以支持多个Master
-
Redis集群支持多个Master,每个Master又可以挂载多个Slave
- 读写分离
- 支持海量数据的高可用
- 支持海量数据的读写存储操作
-
由于Cluster自带Sentinel的故障转移机制,内置了高可用的支持,无需再去使用哨兵功能
-
客户端和Redis的节点连接,不再需要连接集群中所有节点,只需连接集群中的任意一个可用节点即可
-
槽位slot负责分配到各个物理服务节点,由对应的集群来负责维护节点、插槽和数据之间的关系
Redis集群分布式存储
Redis集群分布式存储有大概有3种解决方法
- 哈希取余分区
- 一致性哈希算法分区
- 哈希槽分区
1和2有缺点,不使用
- 第一个缺点:某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
- 第二个缺点:一致性哈希算法的数据倾斜问题,某个机器下线不会hash重新洗牌,但是会造成数据倾斜。
哈希槽分区(使用这个)
- 哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。
- 解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
- 槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配
- 一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。
- 集群会记录节点和槽的对应关系,解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取模,余数是几key就落入对应的槽里。HASH_SLOT = CRC16(key) mod 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
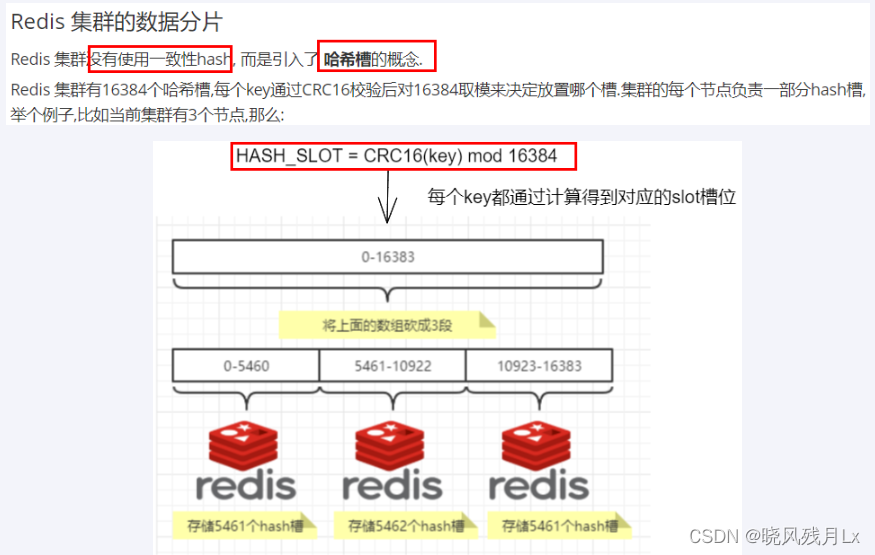
redis的集群主节点数量基本不可能超过1000个。
集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
槽位越小,节点少的情况下,压缩比高,容易传输
Redis主节点的配置信息中它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
集群配置(三主三从)
新建6个独立的redis实例服务
10.0.0.11 主master port 6379
10.0.0.12 主master port 6379
10.0.0.13 主master port 6379
10.0.0.14 从slave port 6379
10.0.0.15 从slave port 6379
10.0.0.16 从slave port 6379
所以机器
mkdir -p /redis/cluster #创建集群目录
所有机器上编写
vim /redis/cluster/redisCluster6379.conf
bind 0.0.0.0
daemonize yes
protected-mode no
port 6379
logfile "/redis/logs/cluster6379.log"
pidfile /redis/cluster6379.pid
dir /redis/cluster
dbfilename dump6379.rdb
appendonly yes
appendfilename "appendonly.aof"
requirepass qiya123
masterauth qiya123
cluster-enabled yes
cluster-config-file nodes6379.conf
cluster-node-timeout 5000
启动6台机器
redis-server /redis/cluster/redisCluster6379.conf
通过redis-cli命令为6台机器构建集群关系
构建主从关系 注意用自己的IP
redis-cli -a qiya123 --cluster create --cluster-replicas 1 10.0.0.11:6379 10.0.0.12:6379 10.0.0.13:6379 10.0.0.14:6379 10.0.0.15:6379 10.0.0.16:6379
#各个机器的ip和端口
# -cluster-replicas 1 表示为每个master创建一个slave节点
[root@10 redis]#redis-cli -a qiya123 --cluster create --cluster-replicas 1 10.0.0.11:6379 10.0.0.12:6379 10.0.0.13:6379 10.0.0.14:6379 10.0.0.15:6379 10.0.0.16:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460 #各个主机掌管不同的哈希槽
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 10.0.0.15:6379 to 10.0.0.11:6379
Adding replica 10.0.0.16:6379 to 10.0.0.12:6379
Adding replica 10.0.0.14:6379 to 10.0.0.13:6379
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379 #主master
slots:[0-5460] (5461 slots) master
M: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379 #主master
slots:[5461-10922] (5462 slots) master
M: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379 #主master
slots:[10923-16383] (5461 slots) master
S: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379 #从slave
replicates 5ea644332c4fc7841367f3c9e5b36d58a40e3536
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379 #从slave
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb
S: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379 #从slave
replicates 990c15af33d03d73992d2d6579197180d44f1c76
Can I set the above configuration? (type 'yes' to accept): yes #输入yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
>>> Performing Cluster Check (using node 10.0.0.11:6379)
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379
slots: (0 slots) slave
replicates 990c15af33d03d73992d2d6579197180d44f1c76
M: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379
slots: (0 slots) slave
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb
S: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379
slots: (0 slots) slave
replicates 5ea644332c4fc7841367f3c9e5b36d58a40e3536
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
如果报错请检查配置文件和是否关闭了哨兵
从上面的id来看
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379
M: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379
M: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379
S: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379 #从slave跟着10.0.0.13
replicates 5ea644332c4fc7841367f3c9e5b36d58a40e3536 (这是master主机的id)
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379 #从slave跟着10.0.0.11
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb((这是master主机的id))
S: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379 #从slave10.0.0.12
replicates 990c15af33d03d73992d2d6579197180d44f1c76 ((这是master主机的id))
现在集群的关系是
10.0.0.13 主master ----- 10.0.0.14 从slave
10.0.0.11 主master ----- 10.0.0.15 从slave
10.0.0.12 主master ----- 10.0.0.16 从slave
任意连接一个作为切入点(集群只需要连一个),并检验集群状态
redis-cli -a qiya123 -p 6379 -c // -c表示集群 不加的话不是按照集群启动的,对于在别的机器上的key,会报错
cluster nodes #查看集群的主从关系
cluster info #查看集群信息
info #查看全部信息
可以登陆各个主机查看,可以查看到相对应的主从关系
info
写入各个值会写到不同的哈希槽,各个master主机掌管不同的哈希槽
set k1 v1
-> Redirected to slot [12706] located at 10.0.0.13:6379 #可以看到写到了12706范围内
OK
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
查看这个key的槽位值
cluster keyslot k1
(integer) 12706
主从容错切换迁移
在我这里我的10.0.0.15是slave,他的master是10.0.0.11(在 cluster nodes 中 看他们的id)
- 把10.0.0.11停了,10.0.0.15会成为master
在10.0.0.11上
127.0.0.1:6379> shutdown
not connected>
10.0.0.15
# Replication
role:master #可以看到10.0.0.15变成master了
connected_slaves:0
master_failover_state:no-failover
master_replid:7ddeddb9b5c0979980ec5d657659f0cb9e1ef5d9
master_replid2:f1bc98b85a32a8a8d21d315ebf35c1748f4e4569
master_repl_offset:20902
second_repl_offset:20609
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:15
repl_backlog_histlen:20888
现在启动10.0.0.11,10.0.0.15还是master,不会让位
现在启动10.0.0.11
redis-server /redis/cluster/redisCluster6379.conf
redis-cli -a qiya123 -p 6379 -c
info
# Replication
role:slave #10.0.0.11变成从,不会变成master
master_host:10.0.0.15
master_port:6379
master_link_status:up
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_read_repl_offset:20916
slave_repl_offset:20916
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:7ddeddb9b5c0979980ec5d657659f0cb9e1ef5d9
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:20916
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:20903
repl_backlog_histlen:14
- Redis集群不保证强一致性,意味着在特定的条件下,Redis集群可能会丢掉一些被系统收到的写入请求命令
- 因为本质还是发送心跳包,需要一些时间判断是否down机,如果down机,对应的slave直接成为master
- 如果想要原先的master继续做master的话
CLUSTER FAILOVER // 让谁上位 就在谁的端口号下执行这个命令
在10.0.0.11上执行
# Replication
role:master #又变成master了
connected_slaves:1
slave0:ip=10.0.0.15,port=6379,state=online,offset=21014,lag=1
master_failover_state:no-failover
master_replid:23128ba2fe24af339046809c73adc0bffcd6894c
master_replid2:7ddeddb9b5c0979980ec5d657659f0cb9e1ef5d9
master_repl_offset:21014
second_repl_offset:21015
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:20903
repl_backlog_histlen:112
主从扩容
- 新建10.0.0.17, 10.0.0.18 两个服务实例配置文件+启动
- 配置文件拷贝上面的模板
mkdir -p /redis/cluster
mkdir /redis/logs
scp redis.conf 10.0.0.17:/redis
scp redis.conf 10.0.0.18:/redis
vim /redis/cluster/redisCluster6379.conf #两个新加的机器都创建
bind 0.0.0.0
daemonize yes
protected-mode no
port 6379
logfile "/redis/logs/cluster6379.log"
pidfile /redis/cluster6379.pid
dir /redis/cluster
dbfilename dump6379.rdb
appendonly yes
appendfilename "appendonly.aof"
requirepass qiya123
masterauth qiya123
cluster-enabled yes
cluster-config-file nodes6379.conf
cluster-node-timeout 5000
redis-server /redis/cluster/redisCluster6379.conf #两台都启动
将新增的10.0.0.17节点作为master加入原集群
redis-cli -a 密码 --cluster add-node 自己实际IP地址:6379 主机群的ip:6379
自己实际IP地址:6379 就是将要作为master新增节点
主机群的ip:6379 就是原来集群节点里面的领路人
redis-cli -a qiya123 --cluster add-node 10.0.0.17:6379 10.0.0.11:6379
将自己的ip加入到集群中
[root@10 redis]#redis-cli -a qiya123 --cluster add-node 10.0.0.17:6379 10.0.0.11:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 10.0.0.17:6379 to cluster 10.0.0.11:6379
>>> Performing Cluster Check (using node 10.0.0.11:6379)
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379
slots: (0 slots) slave
replicates 390ff5b38f37de5766c838603747defc883ff665
S: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379
slots: (0 slots) slave
replicates 3a52b7aab7d0168c2df1084f2da127b043bcc81c
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379
slots: (0 slots) slave
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb
M: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Getting functions from cluster
>>> Send FUNCTION LIST to 10.0.0.17:6379 to verify there is no functions in it
>>> Send FUNCTION RESTORE to 10.0.0.17:6379
>>> Send CLUSTER MEET to node 10.0.0.17:6379 to make it join the cluster.
[OK] New node added correctly. #添加成功
检查集群情况
redis-cli -a 密码 --cluster check 真实ip地址:6379
redis-cli -a qiya123 --cluster check 10.0.0.17:6379
redis-cli -a qiya123 --cluster check 10.0.0.17:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.17:6379 (ce8369ec...) -> 0 keys | 0 slots | 0 slaves.
#可以看到加入成功了,但是为分配槽位
10.0.0.16:6379 (3a52b7aa...) -> 0 keys | 5462 slots | 1 slaves.
10.0.0.14:6379 (390ff5b3...) -> 1 keys | 5461 slots | 1 slaves.
10.0.0.11:6379 (b594b76e...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 1 keys in 4 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 10.0.0.17:6379)
M: ce8369ec5a29caaa06188fccd0d4740a2ffc699b 10.0.0.17:6379
slots: (0 slots) master
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379
slots: (0 slots) slave
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb
M: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379
slots: (0 slots) slave
replicates 390ff5b38f37de5766c838603747defc883ff665
S: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379
slots: (0 slots) slave
replicates 3a52b7aab7d0168c2df1084f2da127b043bcc81c
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
重新分派槽号
命令
redis-cli -a 密码 --cluster reshard IP地址:端口号
redis-cli -a qiya123 --cluster reshard 10.0.0.17:6379
重新分配成本太高,所以前3家各自匀出来一部分,从三个旧节点分别匀出1364个坑位,注意本机这里经过调整所以我是需要分出4096即可
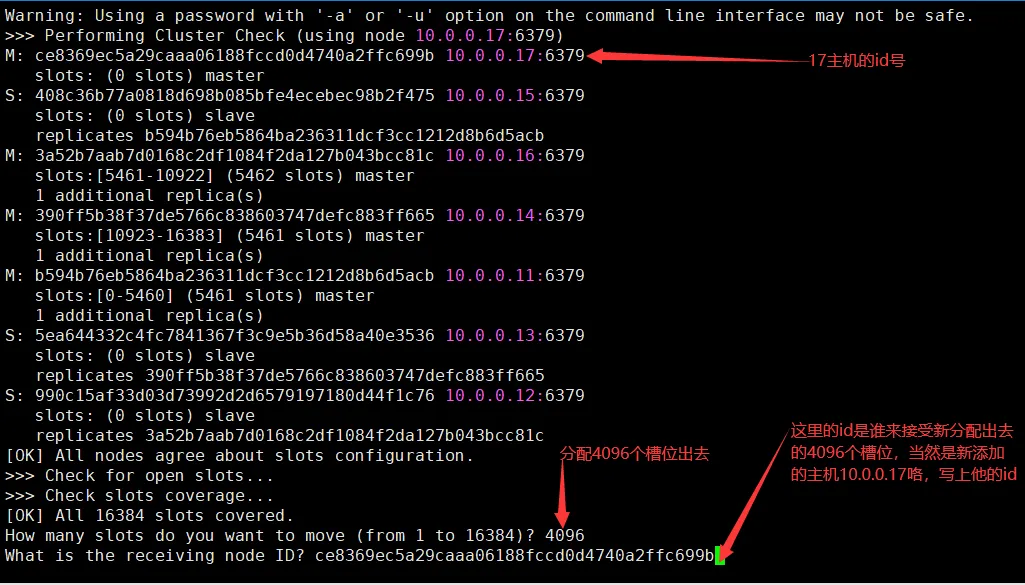
一共是16384个槽位,现在4个master主机了,所以要分配(16384/4)= 4096 平均分摊下来
这里输入节点编号也可以,输入编号后done
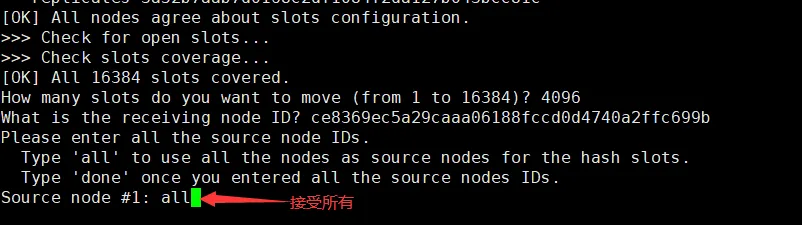
输入all 和 yes进行分配
完成后重新检查集群情况
redis-cli -a qiya123 --cluster check 10.0.0.17:6379
redis-cli -a qiya123 --cluster check 10.0.0.17:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.17:6379 (ce8369ec...) -> 0 keys | 4096 slots | 0 slaves.
#可以看到槽位已经分配了,但是没有从机,所以接下来分配从机
10.0.0.16:6379 (3a52b7aa...) -> 0 keys | 4096 slots | 1 slaves.
10.0.0.14:6379 (390ff5b3...) -> 1 keys | 4096 slots | 1 slaves.
10.0.0.11:6379 (b594b76e...) -> 0 keys | 4096 slots | 1 slaves.
[OK] 1 keys in 4 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 10.0.0.17:6379)
M: ce8369ec5a29caaa06188fccd0d4740a2ffc699b 10.0.0.17:6379
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
#他把其他3家的master里面都分配1364槽位出来
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379
slots: (0 slots) slave
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb
M: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
M: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
S: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379
slots: (0 slots) slave
replicates 390ff5b38f37de5766c838603747defc883ff665
S: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379
slots: (0 slots) slave
replicates 3a52b7aab7d0168c2df1084f2da127b043bcc81c
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
现在10.0.0.17成功配上了master节点,但是没有从机,接下来分配从机
命令:
redis-cli -a 密码 --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
redis-cli -a qiya123 --cluster add-node 10.0.0.18:6379 10.0.0.17:6379 --cluster-slave --cluster-master-id ce8369ec5a29caaa06188fccd0d4740a2ffc699b -------这个是10.0.0.17的编号,按照自己实际情况
redis-cli -a qiya123 --cluster add-node 10.0.0.18:6379 10.0.0.17:6379 --cluster-slave --cluster-master-id ce8369ec5a29caaa06188fccd0d4740a2ffc699b
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Adding node 10.0.0.18:6379 to cluster 10.0.0.17:6379
>>> Performing Cluster Check (using node 10.0.0.17:6379)
M: ce8369ec5a29caaa06188fccd0d4740a2ffc699b 10.0.0.17:6379
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379
slots: (0 slots) slave
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb
M: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
M: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
S: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379
slots: (0 slots) slave
replicates 390ff5b38f37de5766c838603747defc883ff665
S: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379
slots: (0 slots) slave
replicates 3a52b7aab7d0168c2df1084f2da127b043bcc81c
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 10.0.0.18:6379 to make it join the cluster.
Waiting for the cluster to join
>>> Configure node as replica of 10.0.0.17:6379.
[OK] New node added correctly. #添加成功
查看集群分配情况
CLUSTER nodes
CLUSTER nodes
5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379@16379,,shard-id=7719296d5f7f71bc7d389642e5dae04967a6825d slave 390ff5b38f37de5766c838603747defc883ff665 0 1681026870545 9 connected #这是从机,后面的id是对应的masterid号
b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379@16379,,shard-id=d378053a084c38a6dc7ad0090af60a748a1b0eb4 myself,master - 0 1681026870000 10 connected 1365-5460
990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379@16379,,shard-id=12a3249adfd76a7a5f1a83deaedce60ed9d1369e slave 3a52b7aab7d0168c2df1084f2da127b043bcc81c 0 1681026871000 7 connected
408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379@16379,,shard-id=d378053a084c38a6dc7ad0090af60a748a1b0eb4 slave b594b76eb5864ba236311dcf3cc1212d8b6d5acb 0 1681026870545 10 connected
390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379@16379,,shard-id=7719296d5f7f71bc7d389642e5dae04967a6825d master - 0 1681026870000 9 connected 12288-16383
ce8369ec5a29caaa06188fccd0d4740a2ffc699b 10.0.0.17:6379@16379,,shard-id=9ca11c9b690925fda52c00a99caf715742054970 master - 0 1681026870545 11 connected 0-1364 5461-6826 10923-12287
3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379@16379,,shard-id=12a3249adfd76a7a5f1a83deaedce60ed9d1369e master - 0 1681026872165 7 connected 6827-10922
ca17868302f794e3699d815160d3a4ad033b66b2 10.0.0.18:6379@16379,,shard-id=9ca11c9b690925fda52c00a99caf715742054970 slave ce8369ec5a29caaa06188fccd0d4740a2ffc699b 0 1681026871626 11 connected
新的分配
10.0.0.13 主master ----- 10.0.0.14 从slave
10.0.0.11 主master ----- 10.0.0.15 从slave
10.0.0.12 主master ----- 10.0.0.16 从slave
10.0.0.17 主master ----- 10.0.0.18 从slave
到此扩容完成
主从缩容
让10.0.0.17和10.0.0.18下线
- 先获得10.0.0.18的节点id,在集群中将10.0.0.18删除,先删除从机,再删除主master
命令:redis-cli -a 密码 --cluster del-node 从机ip:端口 节点ID
redis-cli -a qiya123 --cluster del-node 10.0.0.18:6379 ca17868302f794e3699d815160d3a4ad033b66b2
redis-cli -a qiya123 --cluster del-node 10.0.0.18:6379 ca17868302f794e3699d815160d3a4ad033b66b2
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node ca17868302f794e3699d815160d3a4ad033b66b2 from cluster 10.0.0.18:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
#删除完成
重新查看集群情况
redis-cli -a qiya123 --cluster check 10.0.0.17:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.17:6379 (ce8369ec...) -> 0 keys | 4096 slots | 0 slaves. #17的从机已经没有了
10.0.0.16:6379 (3a52b7aa...) -> 0 keys | 4096 slots | 1 slaves.
10.0.0.14:6379 (390ff5b3...) -> 1 keys | 4096 slots | 1 slaves.
10.0.0.11:6379 (b594b76e...) -> 0 keys | 4096 slots | 1 slaves.
[OK] 1 keys in 4 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 10.0.0.17:6379)
M: ce8369ec5a29caaa06188fccd0d4740a2ffc699b 10.0.0.17:6379
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379
slots: (0 slots) slave
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb
M: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
M: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
S: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379
slots: (0 slots) slave
replicates 390ff5b38f37de5766c838603747defc883ff665
S: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379
slots: (0 slots) slave
replicates 3a52b7aab7d0168c2df1084f2da127b043bcc81c
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
#从机已经没有了
将10.0.0.17的槽位重新分配给其他主机
redis-cli -a 密码 --cluster reshard 分配到那台master主机的ip和端口
redis-cli -a qiya123 --cluster reshard 10.0.0.11:6379 #分配给10.0.0.11master主机上
redis-cli -a qiya123 --cluster reshard 10.0.0.17:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Performing Cluster Check (using node 10.0.0.17:6379)
M: ce8369ec5a29caaa06188fccd0d4740a2ffc699b 10.0.0.17:6379
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
S: 408c36b77a0818d698b085bfe4ecebec98b2f475 10.0.0.15:6379
slots: (0 slots) slave
replicates b594b76eb5864ba236311dcf3cc1212d8b6d5acb
M: 3a52b7aab7d0168c2df1084f2da127b043bcc81c 10.0.0.16:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
M: 390ff5b38f37de5766c838603747defc883ff665 10.0.0.14:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
M: b594b76eb5864ba236311dcf3cc1212d8b6d5acb 10.0.0.11:6379
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
S: 5ea644332c4fc7841367f3c9e5b36d58a40e3536 10.0.0.13:6379
slots: (0 slots) slave
replicates 390ff5b38f37de5766c838603747defc883ff665
S: 990c15af33d03d73992d2d6579197180d44f1c76 10.0.0.12:6379
slots: (0 slots) slave
replicates 3a52b7aab7d0168c2df1084f2da127b043bcc81c
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096 #分配出去4096个槽位
What is the receiving node ID? b594b76eb5864ba236311dcf3cc1212d8b6d5acb #给10.0.0.11主机
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: ce8369ec5a29caaa06188fccd0d4740a2ffc699b #要删除的主机id
Source node #2: done #输入done 和 yes完成
#如果想平均分配的话上面分配槽位需要输入1364个槽位,分别给3个master主机
分配槽位的机器在分配后会变成从机
[root@10 redis]#redis-cli -a qiya123 --cluster check 10.0.0.11:6379
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
10.0.0.12:6379 (338b7f2a...) -> 0 keys | 4096 slots | 1 slaves.
10.0.0.11:6379 (37f6fde8...) -> 0 keys | 8192 slots | 2 slaves. #2个从机
10.0.0.13:6379 (4894b699...) -> 0 keys | 4096 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 10.0.0.17:6379)
S: 84835bce32d0000b3bee26a6d026f561e9f7d4b6 10.0.0.17:6379 #10.0.0.17变成从机了
slots: (0 slots) slave
replicates 37f6fde8935ad0326195319f483f7887aa57fa99
M: 338b7f2a81f5f46368a5425904ad1a606c4981f8 10.0.0.12:6379
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
M: 37f6fde8935ad0326195319f483f7887aa57fa99 10.0.0.11:6379
slots:[0-6826],[10923-12287] (8192 slots) master
2 additional replica(s)
S: fd23f00a9d7756aa3e3eea8df0fa847e2cc9f995 10.0.0.15:6379
slots: (0 slots) slave
replicates 37f6fde8935ad0326195319f483f7887aa57fa99
M: 4894b699b933b50f04c7c9274aa99a500ea518dd 10.0.0.13:6379
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
S: 9ff2eebcea8f77ab0e9ee1dda17994b54599ff0c 10.0.0.16:6379
slots: (0 slots) slave
replicates 338b7f2a81f5f46368a5425904ad1a606c4981f8
S: 94a190e0ed1f9debe3365f19bce3363b1afb8ac5 10.0.0.14:6379
slots: (0 slots) slave
replicates 4894b699b933b50f04c7c9274aa99a500ea518dd
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
分配完成,现在删除10.0.0.17主机
命令:redis-cli -a 密码 --cluster del-node ip:端口 10.0.0.17的节点ID
redis-cli -a qiya123 --cluster del-node 10.0.0.17:6379 ce8369ec5a29caaa06188fccd0d4740a2ffc699b
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Removing node ce8369ec5a29caaa06188fccd0d4740a2ffc699b from cluster 10.0.0.17:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
到此完成!

















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









