







1. CPU调度
CPU调度就是当前进程需要进行IO操作或者时间片结束了,如何从就绪队列中选择下一个执行的过程。
1.1 FIFO
先入先出,根据队列的前后顺序执行。类似于银行和食堂排队,但是有问题,如果一个人只是简单的询问这样的算法肯定对他不公平。
1.2 Priority(优先级)
给每个进程都设置优先级,根据优先级来选取下一个执行的进程。对于一些时间短的任务可以适当增加它的优先级,但是事先怎么知道它要执行多长时间也是个问题;而且如果一个人询问的时间越来越长怎么办?其实也就是不知道它具体的时间,这样优先级还要可变,对于上述这些问题如何设计其调度策略呢?
1.3 调度算法的优劣
对于银行,调度算法设计的目标应该是让客户满意,让客户满意就不能让他等太久;对于CPU,就是让进程满意,即不能让进程在就绪队列里面很久都没有执行。如何能让进程满意?
1)尽快结束任务:周转时间(任务进入到结束的时间)短。
2)用户操作尽快响应:响应时间(从操作发生到响应)短。
3)系统内耗时间少:吞吐量(任务的完成量)大。
总原则:系统专注于任务执行,又能合理调配任务。
1.4 冲突
响应时间小-》切换次数多-》系统内耗大-》吞吐量小
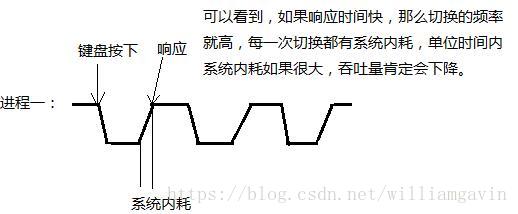
因此调度算法需要折中、综合。
1.5 前台任务与后台任务
前台任务指的是与用户交互的任务,这部分任务要求响应时间小。后台任务指的是在CPU的任务,要求周转时间小。因此调度算法必须考虑这点。
1.6 IO约束型和CPU约束型
IO约束型的任务指的是经常要进行IO操作的任务,这些任务每次使用CPU的时间短,但是频率高,相应的优先级就得高,这样才能实现CPU与IO的并行操作。
CPU约束型的任务指每次使用CPU的时间都比较长,切换次数少,这样的任务就优先级就相对低一些;其实前台任务就属于IO约束型任务,后台任务属于CPU约束型任务。
2. 调度算法
2.1 SJF:短作业优先
作业执行时间短的放在前面先执行,这种方式可以较好的满足周转时间,但是响应时间不好。
2.2 RR:按时间片来轮转调度
这种方式可以较好的满足响应时间,但是时间片的选取时间要好好考虑。
时间片大:响应时间太长;时间片小:吞吐量少,因为内耗大了。
折衷:时间片10 ~ 100ms,切换时间0.1~1ms(1%)
2.3 响应时间与周转时间同时存在
直观想法:定义前台任务和后台任务两个队列,因为前台任务更看重响应时间,所以使用RR,后台任务更看重周转时间,采用SJF,只有当前台任务没有的时候才调度后台任务,但是这样会有很多问题?比如前台任务一直存在,那么后台任务是不是永远不执行了?执行一个后台任务的时间一般比较长,那么是不是这段时间就不响应前台任务?
对于第一个问题,给任务设置优先级,前台任务的优先级大于后台任务优先级,首先执行优先级高的任务,随着时间的增长,后台任务优先级动态升高,这样后台任务才有执行的机会。
对于第二个问题,采用时间片的方式,后台任务执行一段时间之后就跳到下一个任务。
除此之外还有很多其他的问题?例如:
1)我们怎么知道哪些是前台任务,哪些是后台任务,fork时告诉我们吗?
2)gcc就一点不需要交互吗? Ctrl+C按键怎么工作?
3)word就不会执行一段批处理吗? Ctrl+F按键?
4)SJF中的短作业优先如何体现? 如何判断作业的长度?
3. 一个schdule()实例
在不同的领域,调度算法各不相同。我们讨论的是在一个普通的PC机上的调度。
看一下Linux0.11的schedule()函数,进程调度的核心就是找到next,并且switch_to(next);
//在kernel/sched.c中
void Schedule(void)
{
while(1)
{
c=-1; next=0; i=NR_TASKS;
p=&task[NR_TASKS];
while(--i)
{
if((*p->state == TASK_RUNNING && (*p)->counter>c)
c=(*p)->counter, next=i;
}
if(c)
break; //找到了最大的counter
for(p=&LAST_TASK;p>&FIRST_TASK;--p)
(*p)->counter=((*p)->counter>>1)+(*p)->priority;
}
switch_to(next);
}
在Linux中,将PCB做成了一个数组,NR_TASKS就是数组的范围。
在schedule中,首先将p指向PCB的最后一个元素,然后遍历整个数组。如果该进程的state为TASK_RUNNING,TASK_RUNNING表示就绪状态,并且该进程的counter>c,就将该进程的counter赋给c,该进程设置为next。
while(--i)
{
if((*p->state == TASK_RUNNING && (*p)->counter>c)
c=(*p)->counter, next=i;
}
也就是说经过这个循环之后,c应该是就绪进程队列中中counter最大的那个进程,
if (c)
break;
如果c大于零,就跳出while(1),执行switch_to(next),即执行counter最大的那个进程。如果c小于等于0,意思就是所有就绪进程的counter都是小于等于零,那么就调用进程0执行。在Linux0.11中进程0会调用pause()把自己置为可中断的睡眠状态并再次调用schedule()。
for(p=&LAST_TASK;p>&FIRST_TASK;--p)
(*p)->counter=((*p)->counter>>1)+(*p)->priority;
这个for循环是设置所有进程的counter,这个for循环执行的条件是,当就绪队列中所有的进程的counter小于等于0才执行。
(*p)->counter=((*p)->counter>>1)+(*p)->priority;
这句话的意思是将所有进程(包括不处于就绪状态的进程)的counter除以2 + 该进程的priority。从上面的分析可以看出,调度就是根据counter来选择的,那这个counter到底是什么呢?
4. counter的作用
4.1 时间片
counter在操作系统里面本就是时间片。
void do_timer(...) //在kernel/sched.c中
{
if((--current->counter>0)
return;
current->counter=0;
schedule();
}
这是一个时钟中断,就是隔多长时间这个函数执行一次。学过单片机的同学就可以理解成一个定时器。
if((--current->counter>0))
return;
如果当前进程的counter大于0,就减一并且结束函数。如果小于等于0,就将当前进程的counter置为0,执行schedule函数。
4.2 优先级
while(--i)
{
if((*p->state == TASK_RUNNING && (*p)->counter>c)
c=(*p)->counter, next=i;
}
这个循环就是从就绪队列里面选择counter最大的进程执行,毫无疑问counter有优先级的含义。
for(p=&LAST_TASK;p>&FIRST_TASK;--p)
(*p)->counter=((*p)->counter>>1)+(*p)->priority;
这个for是设置所有进程的counter,如果当前进程的counter为0,那么一次循环之后,当前进程的counter就为priority;但是如果当前进程不为0呢?换言之就是该进程不处于就绪队列呢,那么经过一次循环之后该进程的counter肯定大于处于就绪队列的进程(当priority相同时);也就是说阻塞的进程再就绪以后优先级高于非阻塞进程;同时进程阻塞的时间越长,该进程的counter越大,为什么?
第一次执行这个for循环时,如果某进程为阻塞状态,那么其counter为priority
第二次执行这个for循环时,如果该进程为阻塞状态,那么其counter为priority+priority/2
如果该进程一直阻塞,那么其counter为 p+p/2+p/4+p/8,这样counter一直增加,当该进程一旦处于就绪状态,它的counter就会变得很大。进程为什么会阻塞,很大可能就是进程IO操作,IO操作不正是前台进程的特征吗?也就是说会优先执行前台进程。
4.3 counter作用整理
1)counter保证了响应时间有界。
前面说过一个进程如果很长时间没有执行,它的counter=p+p/2+p/4+p/8+…… 这个函数收敛,并且一定小于2p,也就是说每个进程的时间片最长就是2p,如果有n个进程,那么响应时间最大也就是2np。
2)后台进程一直按照counter轮转,近似于SJF调度
3)每个进程只用维护一个变量counter,简单、高效。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









