






使用pca和机器学习算法,完成不同字体的分类模型,详细代码请私信,包含数据集,完整的jupyter代码,英文报告。
1 数据集介绍
数据集来源于:https://www.kaggle.com/datasets/nikbearbrown/tmnist-alphabet-94-characters?datasetId=1564532&sortBy=voteCount ,这是两种不同的字体,我们需要对其进行分类。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import OneHotEncoder
x1 = df[df["names"] == "Teko-Light"]
x2 = df[df["names"] == "SpectralSC-Medium"]
#我们选择x1和x2数据集中的ABCD分别展示出来
def get_alpha_image(x, label):
alpha = x[x["labels"] == label]
alpha_image = alpha.iloc[0, 2:].values.reshape((28, 28))
return np.asarray(alpha_image, dtype=int)
A = get_alpha_image(x1, "A")
B = get_alpha_image(x1, "B")
C = get_alpha_image(x1, "C")
D = get_alpha_image(x1, "D")
fig = plt.figure()
ax = fig.subplots(1, 4)
plt.title("Teko-Light", x=-1.5, y=1.5)
ax[0].imshow(A)
ax[1].imshow(B)
ax[2].imshow(C)
ax[3].imshow(D)
plt.show()
A = get_alpha_image(x2, "A")
B = get_alpha_image(x2, "B")
C = get_alpha_image(x2, "C")
D = get_alpha_image(x2, "D")
fig = plt.figure()
ax = fig.subplots(1, 4)
plt.title("SpectralSC-Medium", x=-1.5, y=1.5)
ax[0].imshow(A)
ax[1].imshow(B)
ax[2].imshow(C)
ax[3].imshow(D)
plt.show()
2 PCA
from sklearn.decomposition import PCA
pca = PCA(100)
pca.fit(x_train)
new_x_train = pca.transform(x_train)
new_x_test = pca.transform(x_test)
3 SVM
from sklearn.svm import SVC
model = SVC()
model.fit(new_x_train, y_train)
train_y_pred = model.predict(new_x_train)
test_y_pred = model.predict(new_x_test)
from sklearn.metrics import accuracy_score, confusion_matrix
print("train acc {}".format(round(accuracy_score(y_train, train_y_pred),4 )))
print("test acc {}".format(round(accuracy_score(y_test, test_y_pred),4 )))
print("train confusion_matrix: ")
print(confusion_matrix(y_train, train_y_pred))
print("test confusion_matrix: ")
print(confusion_matrix(y_test, test_y_pred))

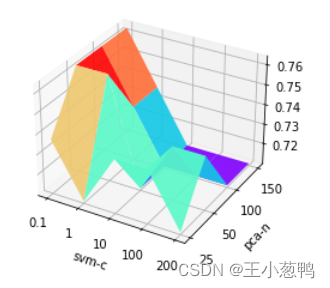
4 参数调优
pca_n = [25, 50, 100,150]
svm_c = [0.1, 1, 10,100,200]
acc_result = []
for n in pca_n:
acc_one = []
for c in svm_c:
pca = PCA(n)
pca.fit(x_train)
new_x_train = pca.transform(x_train)
new_x_test = pca.transform(x_test)
model = SVC(C = c)
model.fit(new_x_train, y_train)
test_y_pred = model.predict(new_x_test)
test_acc = round(accuracy_score(y_test, test_y_pred),4 )
print("pca-N: {:<5} svm-C: {:<5} test-acc: {:<5}".format(n, c, test_acc))
acc_one.append(test_acc)
acc_result.append(acc_one)





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











