



 本文详细介绍正则表达式的高级用法,包括速率筛选、前瞻断言等技巧,通过实例解析帮助读者掌握复杂数据的匹配与提取。
本文详细介绍正则表达式的高级用法,包括速率筛选、前瞻断言等技巧,通过实例解析帮助读者掌握复杂数据的匹配与提取。
给有需要学习完整版的同学推荐这个帖子:你是如何学会正则表达式的? - 老刘的回答 - 知乎 https://www.zhihu.com/question/48219401/answer/742444326
-------------------------------------开始正文分割线----------------------------------------
有以下数据,筛出当中速率≥100且<1000的上传数据。
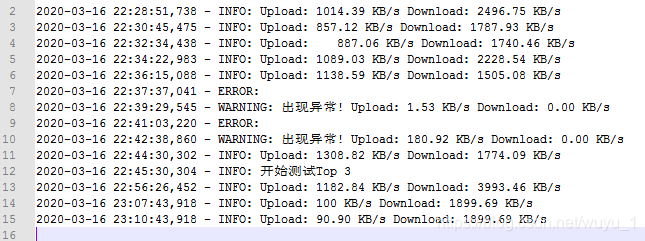
表达式:(?<=Upload:) *(100|[1-9]\d{2}.\d{1,2})
查询结果:

(?<=Upload: ) 匹配Upload:后面的内容
* 匹配零次或更多次,此处前面加了个空格,表示匹配零个或更多个空格
| 或的意思
[1-9] 匹配1~9中的任意数字
\d{2} 匹配连续的2个数字,每个数字的取值范围均是0~9,比如08,71均在匹配范围内
\d{1,2} 匹配1个数字或2个数字
.(100|[1-9]\d{2}.\d{1,2}) 匹配100或1~9开头的带1~2个小数点的3位数。不加小括号的匹配结果会是下边这样↓ 具体为啥我得请教下我家大朋友
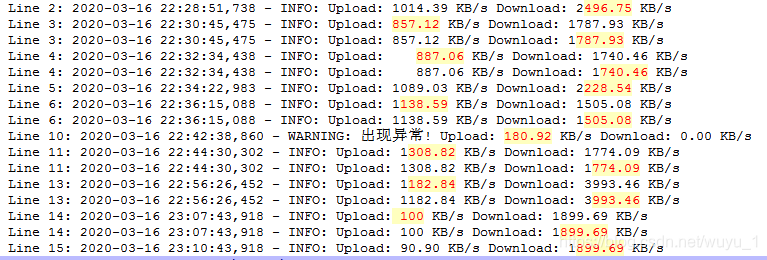
([1-4][0-9])(?=% idle) 匹配字符串% idle前面的两位数数字,数字的 第一位时1~4,第二位是0~9
(?=% idle) 匹配字符串% idle前面的内容
------------------------------------------------分割线---------------------------------------------------------
- 匹配后面不带xx字符/字符串的字符/字符串(负前瞻)
语法:(?!pattern)
作用:匹配非pattern表达式的前面内容,不返回本身。
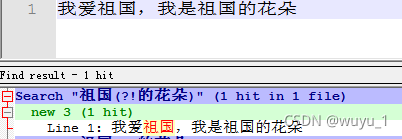
例句 “我爱祖国,我是祖国的花朵”
目标:匹配“祖国”,但不匹配“的花朵”前面的祖国
正则:祖国(?!pattern)
匹配结果:
- 匹配后面带xx字符/字符串的字符/字符串(正前瞻)
语法:(?=pattern)
作用:匹配pattern表达式的前面内容,不返回本身。
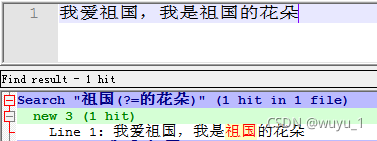
例句 “我爱祖国,我是祖国的花朵”
目标:匹配后面跟有的花朵的“祖国”
正则:祖国(?=pattern)

















 2317
2317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









