







Lucene全文检索
Lucene的介绍
全文检索的概念:将非结构化的数据(大小不定,格式不定)中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索比较快的目的。这部分从非结构化的数据中提取出的然后重新组织的信息,我们称之为索引。这种先建立索引,再对索引进行搜素的过程就叫全文索引。
lucece的下载地址:http://lucene.apache.org/core/downloads.html
Lucene的应用场景
对于数据量大,数据结构不固定的数据可以采用全文检索的方式搜素,比如百度,Google等搜索引擎,论坛内搜索,电商网站站内搜索等。
Lucene实现全文检索的过程
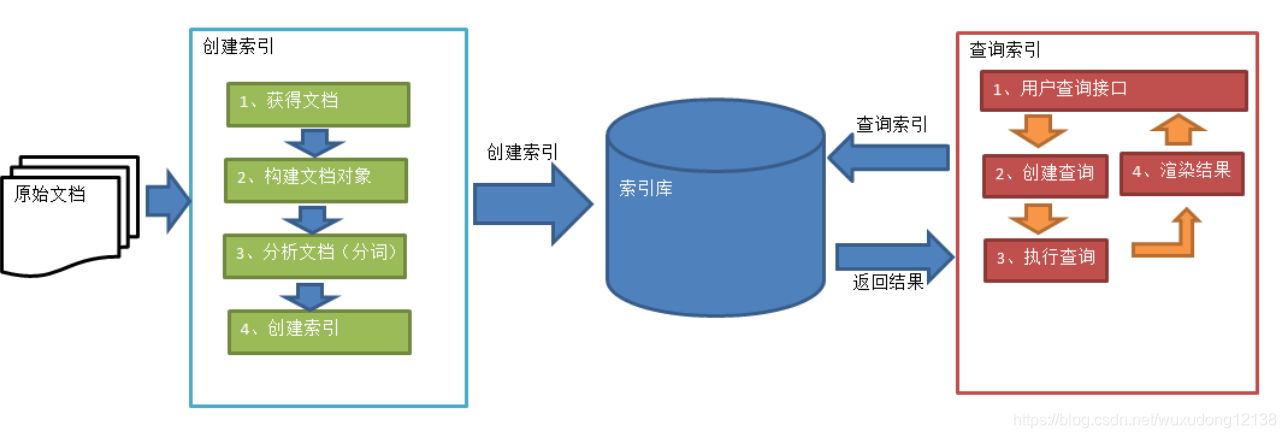
- 绿色表示创建索引的过程
- 红色表示搜索过程
创建索引的过程
1. 获得原始文档
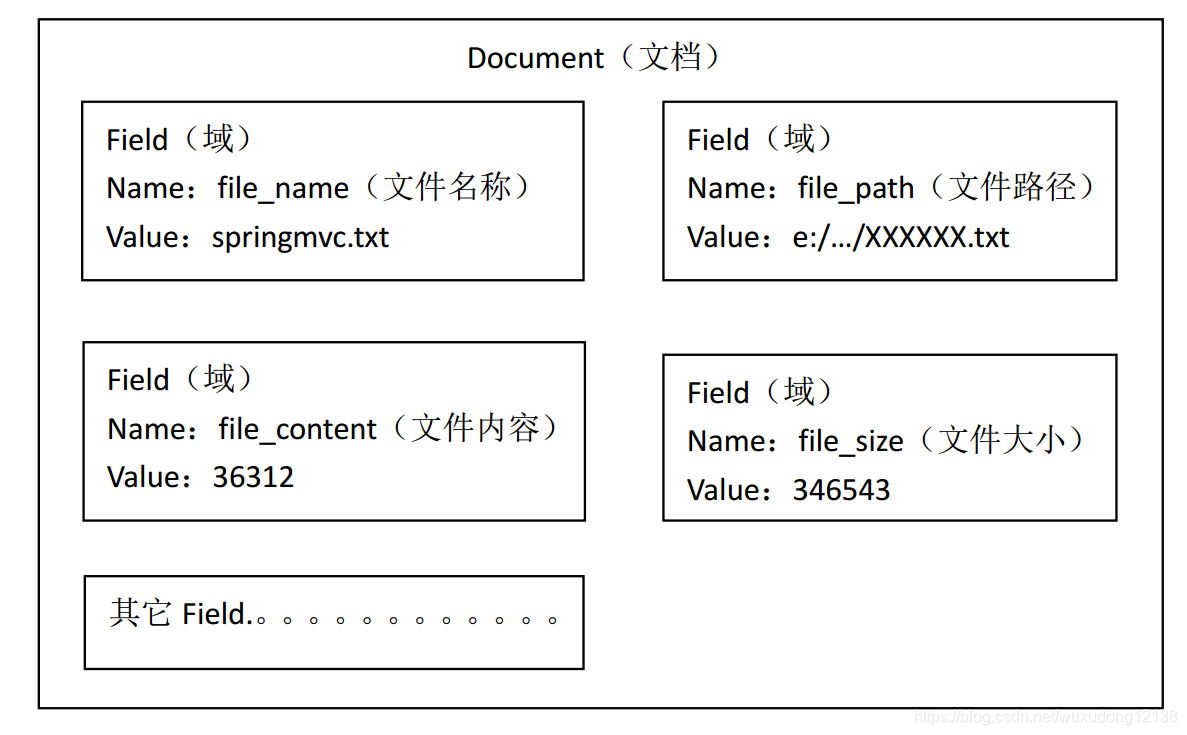
2.创建文档对象
对于原始文档中的每一个文件,我们都可以创建一个对象来表示。
文档对象中存储的是键值对,键是域(Field)类似于数据库中的字段,值(value)表示的是存储的内容。
3.分析文档
将原始内容创建为包含域的文档,需要对域中的内容进行分析,分析的过程是经过对原始文档提取单词,将字母转为小写,去除标点符号,去除停用词等过程生成最终的语汇单元,可以将语义单词理解为一个一个的单词。
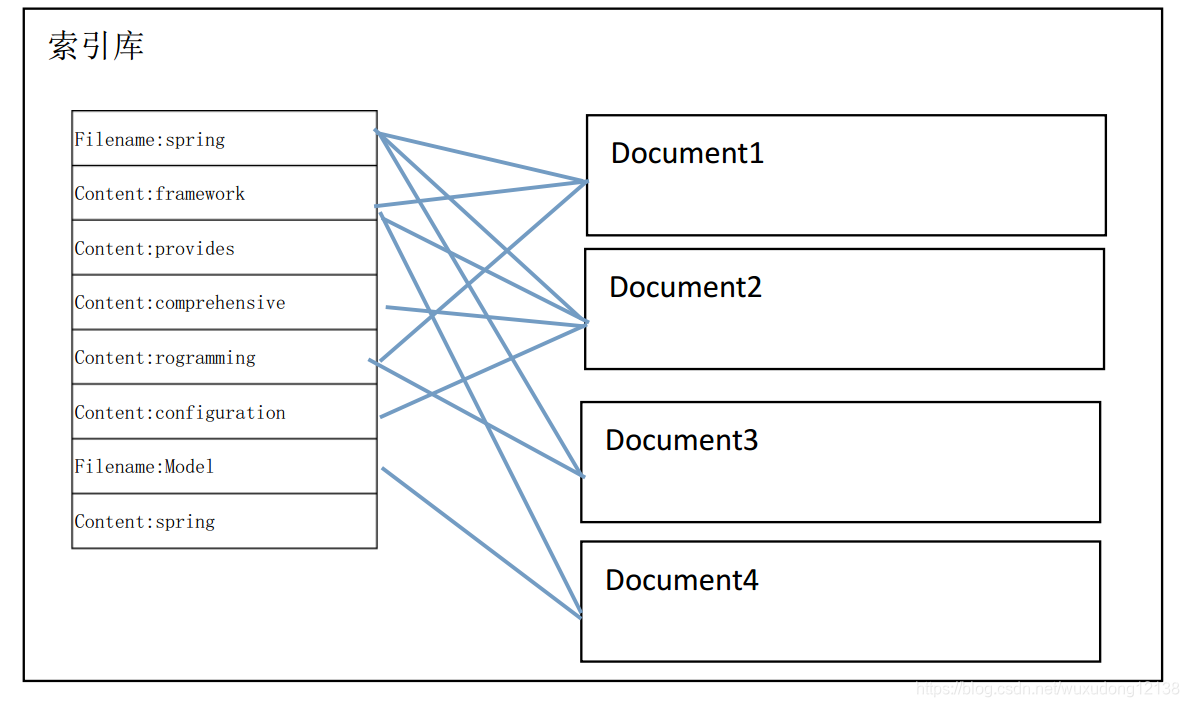
4.创建索引
5.查询索引
查询索引就是搜索的过程。搜索就是用户输入关键字,从索引中进行搜索的过程。
代码实现
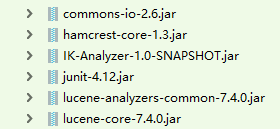
需要导入的jar包
@Test
public void createIndex() throws Exception {
//指定索引库存放的路径
//F://temp//index
//1.将索引存储到磁盘中
Directory directory= FSDirectory.open(new File("F:\\所有的jar包\\temp\\index").toPath());
//2.创建indexwriterconfig对象
IndexWriterConfig config= new IndexWriterConfig(new IKAnalyzer());
//3.创建indexwriter对象
IndexWriter indexWriter=new IndexWriter(directory,config);
//4. 将原始文档写入到索引库
//原始文档的路径
File dir=new File("F:\\所有的jar包\\searchsource");
for (File f: dir.listFiles()){
//文件名
String fileName=f.getName();
//文件内容
String fileContent= FileUtils.readFileToString(f,"utf-8");
//文件路径
String filePath=f.getPath();
//文件的大小
long fileSize=FileUtils.sizeOf(f);
//创建文件名域:第一个参数:域的名称 第二个参数:域的内容 第三个参数:是否存储
Field fileNameField= new TextField("fileName",fileName, Field.Store.YES);
//创建文件内容域
Field fileContentField=new TextField("fileContent",fileContent, Field.Store.YES);
//创建文件路径域
Field filePathField=new TextField("filePath",filePath, Field.Store.YES);
//创建文件大小域
Field fileSizeField=new TextField("fileSize",fileSize+"", Field.Store.YES);
//创建Document对象
Document document=new Document();
document.add(fileNameField);
document.add(fileContentField);
document.add(filePathField);
document.add(fileSizeField);
//创建索引,并写入索引库
indexWriter.addDocument(document);
}
//关闭indexwriter
indexWriter.close();
}
查询索引的过程
1.用户查询接口
全文检索系统提供用户搜索的界面供用户提交搜索的关键字,搜索完成展示搜索的结果。
2.创建查询
用户输入查询关键字执行搜索之前需要构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域,查询关键字等等
3.执行查询
根据查询语法在倒排索引词典表中分别找出对应搜索词的索引,从而找出索引所链接的文档链表。
4.渲染结果
以一个友好的页面把结果展示给用户。
代码
@Test
public void searchIndex() throws Exception{
//指定索引库存放的路径
//F://temp//index
Directory directory=FSDirectory.open(new File("F:\\所有的jar包\\temp\\index").toPath());
//创建indexReader对象
IndexReader indexReader= DirectoryReader.open(directory);
//创建indexSearcher对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//创建查询
Query query=new TermQuery(new Term("fileContent","spring"));
//执行查询
//第一个参数是查询对象,第二个参数是查询结果返回的最大值
TopDocs topDocs=indexSearcher.search(query,10);
//查询结果的总条数
System.out.println("查询结果的总条数:"+topDocs.totalHits);
//遍历查询结果
//topDocs.scoreDocs存储了document对象的id
for (ScoreDoc scoreDoc:topDocs.scoreDocs){
//scoreDoc.doc属性就是对象的id
//根据document的Id找到document对象
Document document=indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("fileName"));
System.out.println(document.get("filePath"));
System.out.println(document.get("fileSize"));
System.out.println("-------------");
}
//关闭indexReader对象
indexReader.close();
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









