




 本文介绍如何在JMeter中利用CSV文件配置参数数据,对百度、搜狗、好搜进行搜索性能对比测试。包括设置测试计划、线程组、HTTP请求的Sampler,使用参数配置关键字,配置搜索引擎,执行测试并查询结果。
本文介绍如何在JMeter中利用CSV文件配置参数数据,对百度、搜狗、好搜进行搜索性能对比测试。包括设置测试计划、线程组、HTTP请求的Sampler,使用参数配置关键字,配置搜索引擎,执行测试并查询结果。
本篇文章主要对如何在JMeter中进行URL的参数进行配置进行介绍,通过CSV文件配置参数数据,对baidu、sogou、haosou进行搜索性能对比测试。
1.建立测试计划、线程组,并在线程组下添加一个HTTP请求的Sampler
2.在测试中使用参数
这里我们先在浏览器中打开调试工具,进行一下搜索,并查看进行搜索时所需的参数。

其中wd:测试 是搜素偶的关键字,ie:utf-8是编码格式,如果使用其它的编码格式,将会出现非期望的搜索结果,例如,使用gb2312进行编码,结果如下:

我们将正确的参数配置到HTTP请求的Sampler中

3.检查配置是否正确
添加一个“查看结果树”的监听器,运行测试,检查测试是否正确运行

4.使用csv参数文件
这里我们先建立一个CSV文件,内容如下(作为演示,这里我写了两列数据,并且只用到了第2列数据):

utf-8,测试 utf-8,Jmeter utf-8,Robot utf-8,LeetTest utf-8,ChinaDjango utf-8,性能测试 utf-8,功能测试 utf-8,测试开发
之后在JMeter的菜单栏中打开“选项”-“函数助手对话框”,选择__CSVRead,配置文件地址及我们要取第几列数据(列数下标从0开始),这里我们取csv文件中的第2列数据作为搜索的关键字,对应的列数下标是1 。
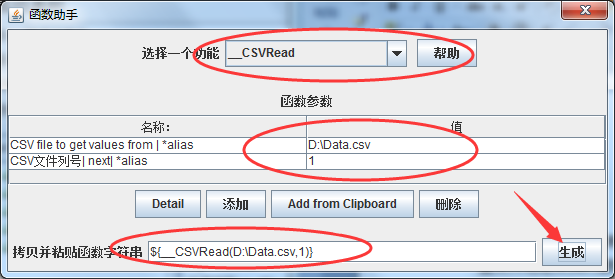
生成被取数据的代码,复制该内容,重新打开“HTTP请求”的Sampler,将参数中的wd的值改为我们刚刚生成的代码 ${__CSVRead(D:\Data.csv,1)}
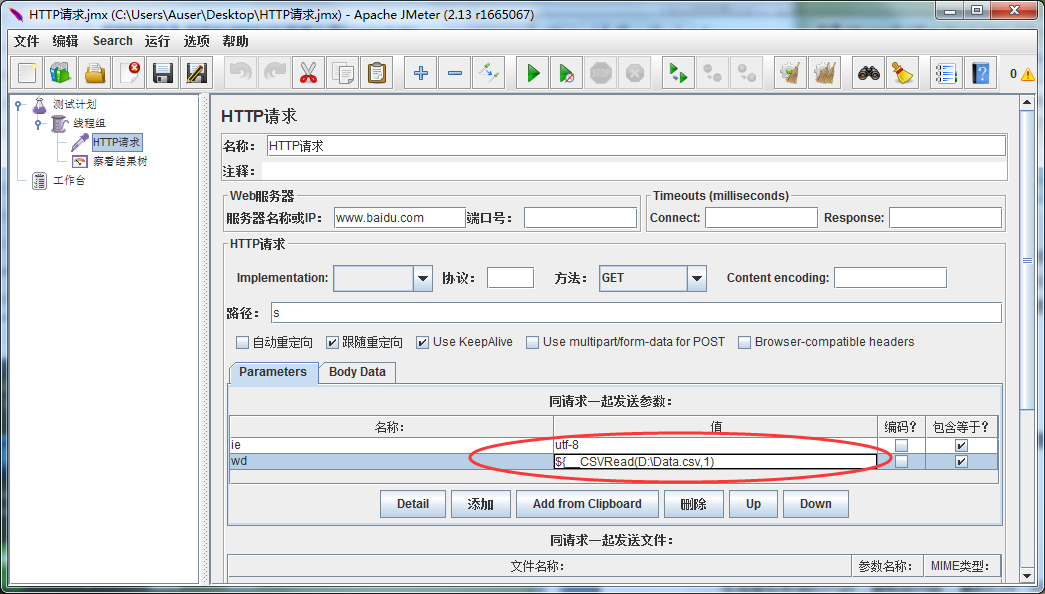
4.配置搜索引擎
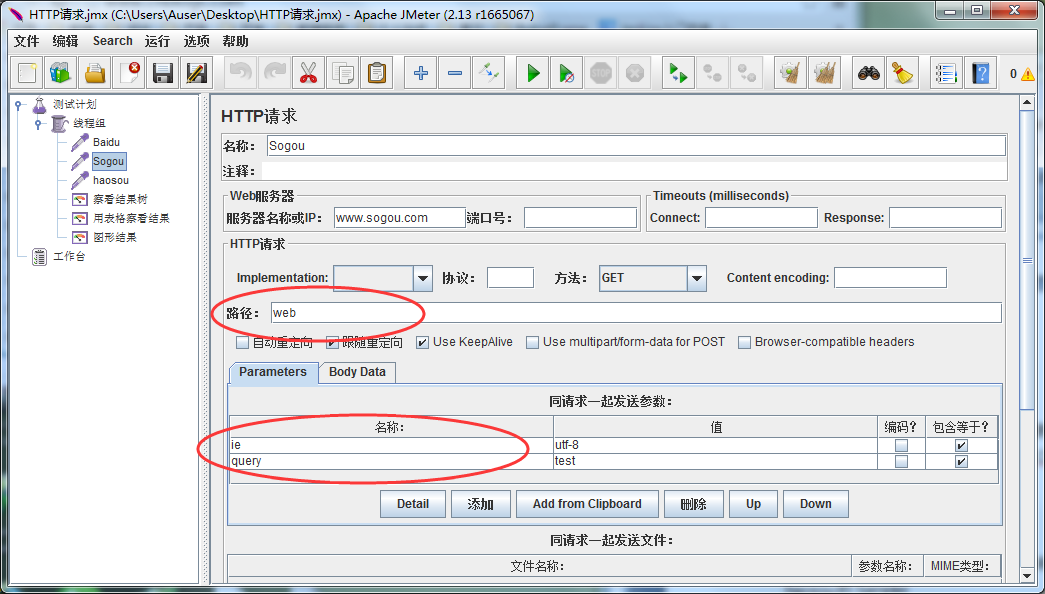
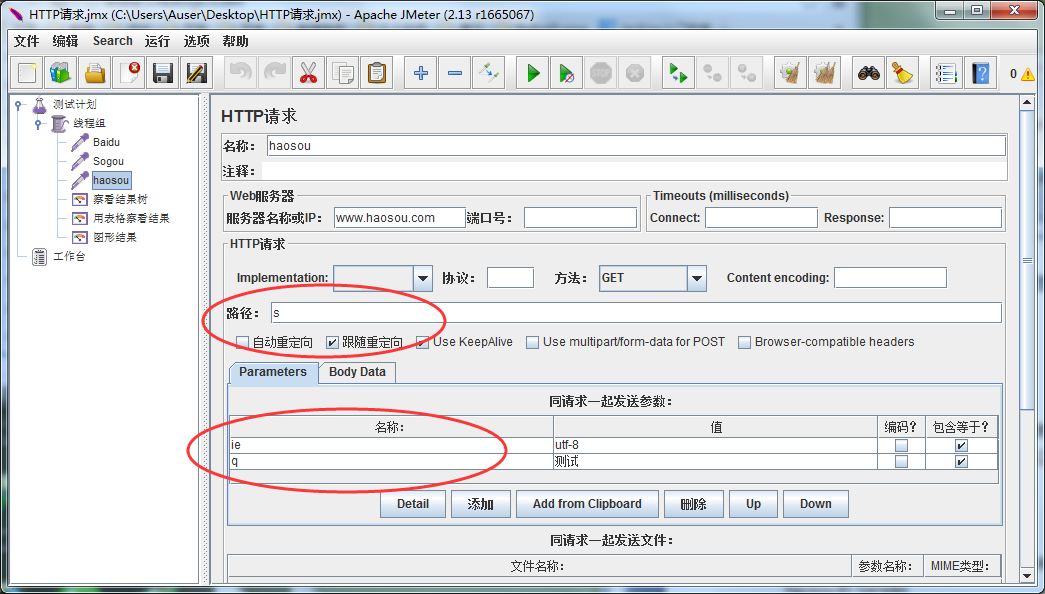
将我们当前的HTTP请求的Sampler名称改为baidu,并以同样的方式建立sogou和haosou的Sampler(注意其中的路径和关键字名称)
sogou:
haosou
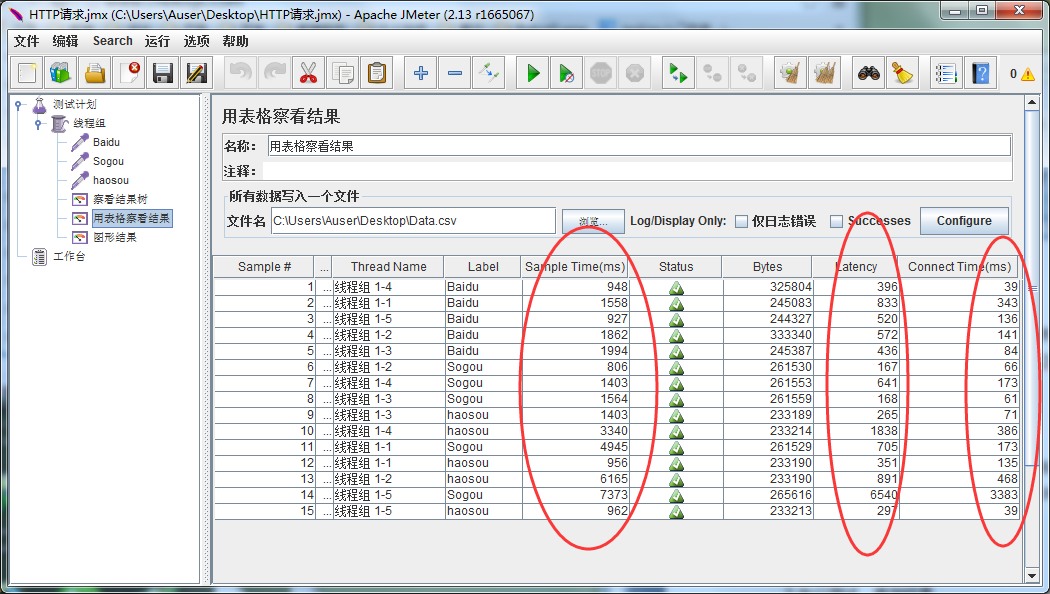
5.执行测试,查询结果
添加监听器,运行测试,查询并对比性能测试结果(作为演示,这里我把线程组的线程数设为了5,实际测试中,需要按照情况评估一个较大的值)

















 1680
1680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









