







 本文探讨JavaScript中深浅拷贝的概念,特别是在处理引用数据类型时遇到的问题。文章介绍了基本数据类型与引用数据类型的区别,重点讲解了深拷贝与浅拷贝,并通过实例分析了concat、slice、Object.assign()以及...展开符等方法在拷贝时的行为。此外,还讨论了JSON.stringify/parse实现深拷贝的限制和递归实现深拷贝的常见方案。
本文探讨JavaScript中深浅拷贝的概念,特别是在处理引用数据类型时遇到的问题。文章介绍了基本数据类型与引用数据类型的区别,重点讲解了深拷贝与浅拷贝,并通过实例分析了concat、slice、Object.assign()以及...展开符等方法在拷贝时的行为。此外,还讨论了JSON.stringify/parse实现深拷贝的限制和递归实现深拷贝的常见方案。
一直以来倒是没有仔细的思考过深浅拷贝的问题,最近有听到小伙伴在讨论,全面了解了一下,深拷贝并没有那么简单。现在让我们来一起探讨深浅拷贝相关的内容吧。
基本数据类型、引用数据类型
为什么会出现深浅拷贝的问题,主要因为在于js中所有的数据类型分为基本数据类型和引用数据类型两大类。
那么基本数据类型有哪些呢:Number、String、Boolean、Undefined、Null、Symbol、BigInt
引用数据类型,就是Object了,但是js封装了几个继承了Object原型属性的一些对象,Array、Function、Data、Error、Map、Set等
基本数据类型与引用数据类型的区别
存储方式
基本数据类型和引用数据类型是根据存储方式划分的。基本数据类型在内存中占据固定大小,保存在栈内存中。引用数据类型的值是对象,保存在堆内存中,并会在栈内存中存储该对象的变量标识符以及对象在堆内存中的存储地址。
赋值方式
所以在使用基本数据类型和引用数据类型的时候,关于赋值问题就需要多多思量了。
基本数据类型
基本数据类型的赋值方式,是从一个变量向另一个新变量复制基本类型的值,会创建这个值的一个副本,并将该副本赋值给新变量。
let a = 2;
let b = a;
console.log(a)
console.log(b)
// 修改b的值不会影响a的值
b = 3;
console.log(a)
console.log(b)
引用数据类型
引用数据类型从一个变量向另一个新变量复制引用数据类型的地址,将新复制的地址赋值给新变量,最终两个变量存储的是相同的地址,指向的是堆内存中同一块存储空间。通过一个变量修改对象属性,就会影响另一个变量指向的对象内容。
let c = {
a: 1,
b: 2,
c: 3
}
let d = c
c.c = 5
console.log(d.c)
我们可以看到,通过c变量去修改该对象的c属性,d变量会被影响。那么引用数据类型的这种赋值方式就会对我们的开发造成一定影响。如果我们只想要一个和当前对象一样的对象,但修改数据时不会互相影响,这时候该怎么办呢?
深拷贝、浅拷贝
根据前面讲到的一些简单的知识普及,大家应该都知道了,所谓的深浅拷贝一定是针对于引用数据类型来说的,那么什么是深浅拷贝呢?
- 浅拷贝:仅仅是复制了引用,彼此之间的操作会相互影响,指向的是同一块堆内存空间。前面讲到的=赋值就是浅拷贝。
- 深拷贝:在堆中重新分配内存,不同的地址,相同的值,互不影响。
JavaScript中的拷贝
讲到了深浅拷贝,一定会有些疑问,js中有不少的拷贝方法,那么这些方法它们。。。到底是深拷贝还是浅拷贝。毕竟如果连这都搞不懂,在用的时候就很容易出一些乌龙事件。
concat
concat,用于连接两个或多个数组。
concat,方法不会更改现有数组,而是返回一个新数组,其中包含已连接数组的值。
看定义应该是深拷贝,我们可以来测试一下:
let a = [1,2,3,5,6]
let b = [7,8,9]
let c = a.concat(b)
console.log(c) //[1, 2, 3, 5, 6, 7, 8, 9]
a[0] = 2;
console.log(a) //[2,2,3,5,6]
console.log(c) //[1, 2, 3, 5, 6, 7, 8, 9]
这么一看,诶,这concat好像是深拷贝呀,我们修改a的元素,c不会跟着变,真的是重新生成了一个数组。但是这个时候就要仔细想想,如果元素是一个数组,或者是个对象呢,总之就是如果元素是一个引用数据类型,concat还能保持互不影响吗?我们来测试一下。
let b = [7,8,9]
let d = [1,[2,3,4],{e: 1}]
let f = b.concat(d)
d[1][1] = 5;
d[2].e = 2;
console.log(f) //[7,8,9,1,[2,5,4],{e: 2}]
我们可以看到当元素为引用数据类型,concat虽然在合并数组时,生成了新数组,将两个数组的元素合并在了新数组中。但是在元素赋值时对于引用数据类型,仍然是使用了浅拷贝的方式。
slice
slice()方法以新的数组对象,返回数组中被选中的元素。
slice()方法选择从给定的start参数开始的元素,并在给定的end参数
其实原理和concat是一样的,在截取的时候是新生成了一个数组,并将满足条件的元素复制元素,赋值给新数组,但是如果元素是引用数据类型,仍然是进行的浅拷贝赋值。我们就不一一举例了。
Object.assign()
Object.assign()方法用于将所有可枚举属性的值从一个或多个源对象分配到目标对象。它将返回目标对象。
说起来也就是将源对象的可遍历属性复制给新的目标对象,那么它到底是浅拷贝还是深拷贝呢?我们来测试一下
let a = {
b: 1,
c: {
d: 2
}
}
let e = Object.assign({},a)
console.log(e) // {b: 1, c: {d: 2}}
a.c.d = 3;
console.log(e) // {b: 1, c: {d: 3}}
所以Object.assign()拷贝的是属性值,如果源对象的属性值是一个指向对象的引用地址,拷贝的也只是该引用地址,为浅拷贝。
…展开符
就不多说了,直接上案例:
let a = [1,[2,3],{b: 4}]
let b = [1, ...a]
consoloe.log(b) // [1, 1, [2, 3], {b: 4}]
a[1][0] = 5
a[2].b = 6
consoloe.log(b) // [1, 1, [5, 3], {b: 6}]
所以说同concat一样,…展开符对于引用数据类型的元素也是进行了浅拷贝。最多是对第一层对象对的深拷贝,生成了新的对象新的数组,但是对于属性和元素做的仍然是浅拷贝。
深拷贝实现方案
JSON.stringfiy/parse实现
在项目开发中会使用到JSON.parse(JSON.stringfiy(某个对象))来实现重新生成一个完全互不影响的对象。那么我们先来看看JSON.parse()和JSON.stringfiy()两个函数。
JSON.stringfiy()方法用于将JavaScript值转换为JSON字符串.
JSON.parse()我们可以使用JSON.parse方法将数据转换为JavaScript对象。
但是在使用JSON.parse(JSON.stringfiy())实现深拷贝会出现一些问题。
Date时间对象
let obj = {
str: '1234',
data: new Date()
}
let jsonObj = JSON.parse(JSON.stringify(obj))
console.log(jsonObj) // {str: '1234', data: '2021-10-26T07:21:22.091Z'}
我们可以看到json对date数据进行序列化反序列化后,会得到一个字符串格式的时间字符串,我们需要进行格式转换来得到对应的date数据。
RegExp、Error对象
let obj = {
str: '1234',
regExp: new RegExp(),
error: new Error('error')
}
let jsonObj = JSON.parse(JSON.stringify(obj))
console.log(obj) // {str: '1234', regExp: /(?:)/, error: Error: error}
console.log(jsonObj) // {str: '1234', regExp: {}, error: {}}
我们可以看到json对RegExp、Error对象进行序列化反序列化,会得到一个空的Object对象。
undefine、function
let obj = {
a: undefined,
b: null,
str: '124',
arr: [1,24,5,3],
fun: function(){
console.log(1)
},
fun2: () => {
console.log(2)
}
}
let json = JSON.parse(JSON.stringify(obj))
{b: null, str: '124', arr: [1,24,5,3]}
我们可以看到,值为undefined以及function的属性会被json序列化忽略掉,包括箭头函数也会被忽略。
NaN、Infinity、-Infinity
先科普一下关于Infinity和-Infinity相关内容。
Infinity属性用于存放表示无穷大的数值。-Infinity是用于存放负无穷大的一个数字值,在JavaScript中,超出1.7976931348623157E+103088的数值即为Infinity,小于-1.7976931348623157E+103088的数值为无穷小。
那么关于NaN类型,以及Infinity、-Infinity的数据,JSON序列化会有什么样的效果呢,我们开看一下代码:
let obj = {
infi: 1.7976931348623157E+103088,
minusInfi: -1.7976931348623157E+103088,
nanNum: Number.parseInt('sfd')
}
let json = JSON.parse(JSON.stringify(obj))
console.log(json) // {infi: null, minusInfi: null, nanNum: null}
我们可以看出NaN类型,以及Infinity、-Infinity的数据经过序列化会变成null值。
如果json里有对象是由构造函数生成的,则序列化的结果会丢弃对象的 constructor,js内置的一些比如Array这些的构造函数除外
function Func(name){
this.name = name;
}
let obj = {
f: new Func('22'),
arr: new Array()
}
let json = JSON.parse(JSON.stringify(obj))
console.log(json)
```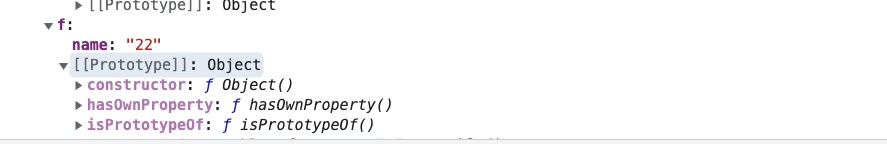

#### 循环引用情况
例如`obj.b = obj`就属于循环引用。
```javascript
let obj = {}
obj.b = obj;
let json = JSON.parse(JSON.stringify(obj))
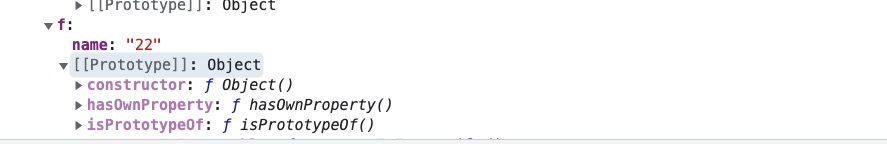
未捕获类型错误:将循环结构转换为JSON。当我们把一个循环引用的对象做序列化会报错。
递归实现
普通情况下我们可以使用JSON.parse(JSON.stringify())去实现深拷贝,但是当出现以上的情况时,只能通过递归实现深拷贝。
如果我们使用for in去遍历对象属性的话,这个对象的原型链上有我们自定义的其他构造函数,会将构造函数显示原型的属性也遍历出来。我们必须使用hasOwnProperty来查询是否是本身的元素。
我们这里实现一个简单的深拷贝,借鉴的是其他文章的实现方案。
function clone(source) {
var target = {};
for(var i in source) {
if (source.hasOwnProperty(i)) {
if (typeof source[i] === 'object') {
target[i] = clone(source[i]); // 注意这里
} else {
target[i] = source[i];
}
}
}
return target;
}
但是依旧存在一些问题
- 没有对参数做校验
- 判断是否对象的逻辑不够严谨
- 没有考虑数组的兼容
关于其他详细的内容可以看看这篇文章深拷贝的终极探索(99%的人都不知道)

















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









