







01上篇回顾
上一篇我们说了生产者加入记录收集器前的一些准备工作,我们再来回顾一下这个图:
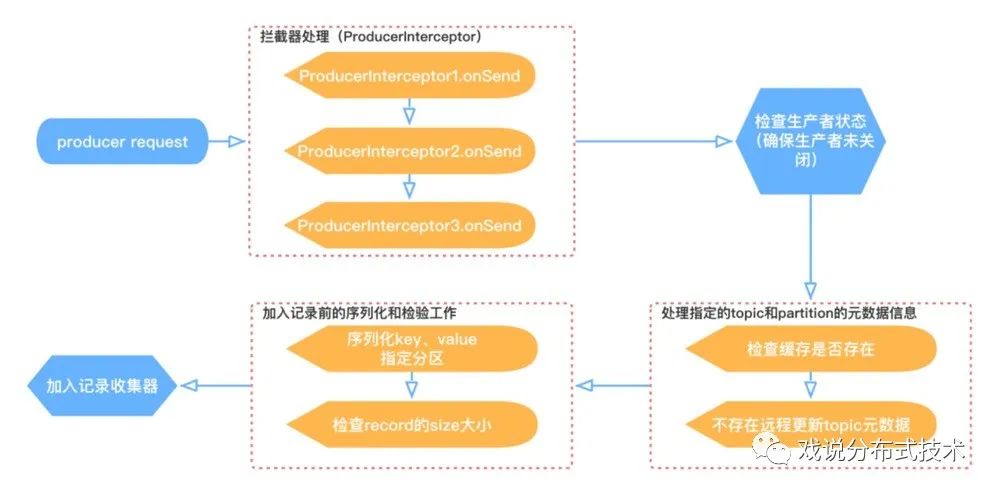
拦截器处理、分区元数据更新、分配分区、key-value序列化环节在上一篇中已经说完,本节继续说下消息的大小检验工作、封装用户callback的过程以及消息写入ProducerBatch的整个过程。
02 消息的大小校验
我们在使用生产的时候有时需要配置一些参数,比如:max.request.size、buffer.memory等,我们看看这两个参数的作用:
max.request.size:每次消息发送时,记录被序列化后的最大字节数,大于此数会抛出RecordTooLargeException
buffer.memory:这个参数指定了生产者记录收集器的最大的buffer的字节数也就是我们后面将要讲到的BufferPool的最大容量。
不同的magic的消息有不同的字段结构以及内存占用情况,在真正写入ProducerBatch前会有一系列的校验工作,按照Magic的版本计算消息预计序列化后占用的空间大小size,校验这个size是否大于max.request.size和buffer.memory,如果大于,则发送消息失败直接返回错误。
注:具体空间占用情况看上一篇中的第6个标题“不同版本消息的内部存储结构”内容。
03用户回调的封装
触发消息的回调有两种途径,一种是我们使用生产者发送消息时可以传递一个callback,另外一个是上一篇提过的生产者的拦截器,kafka producer利用内部类InterceptorCallback聚合了这两个回调,InterceptorCallback实际上会被聚合到一个ProducerBatch的chunk对象中,这样当ProducerBatch发送成功或失败后触发InterceptorCallback#onCompletion,进而触发了我们自定义的callback和拦截器的onAcknowledgement方法。
一般情况下我们使用生产者发送消息时需要附加上我们callback的逻辑(如下图),因为发送过程是异步的,我们需要依赖回调获取消息的metedata,通过metedata我们可以获取到消息所属分区和分区的offset等。
Properties properties = KafkaProducerConfig.createProducerConfig();
KafkaProducer<String,String> producer = new KafkaProducer<>(properties);
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC,"111","test-data");
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(Objects.nonNull(recordMetadata)){
//获取消息的offset
System.out.println(recordMetadata.offset());
//获取消息的分区
System.out.println(recordMetadata.partition());
//获取消息的topic
System.out.println(recordMetadata.topic());
}
}
});当请求完成-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









