



 本文介绍了如何为Elasticsearch安装IK分词器以支持中文搜索。首先从GitHub下载对应版本的IK插件并解压到plugins目录,然后重启Elasticsearch。接着,在新建index时配置mapping,特别是对需要中文搜索的字段如'content',设置ik_max_word和ik_smart两种分词器。注意,已导入数据的index无法直接修改mapping。在Java中,搜索时应避免使用TermQueryBuilder,而改用MatchPhraseQueryBuilder进行完全匹配。最后,通过示例展示了查询语句的正确写法,成功解决了中文搜索问题。
本文介绍了如何为Elasticsearch安装IK分词器以支持中文搜索。首先从GitHub下载对应版本的IK插件并解压到plugins目录,然后重启Elasticsearch。接着,在新建index时配置mapping,特别是对需要中文搜索的字段如'content',设置ik_max_word和ik_smart两种分词器。注意,已导入数据的index无法直接修改mapping。在Java中,搜索时应避免使用TermQueryBuilder,而改用MatchPhraseQueryBuilder进行完全匹配。最后,通过示例展示了查询语句的正确写法,成功解决了中文搜索问题。
1.问题原因:ES默认分词规则不能支持中文,通过安装IK Analysis for Elasticsearch支持中文分词。
2.下载地址https://github.com/medcl/elasticsearch-analysis-ik/releases 对应elasticsearch版本下载相应的IK版本
3.下载后解压到elasticsearch的plugins文件下(这里我建立一个ik文件)
4. 重启elasticsearch
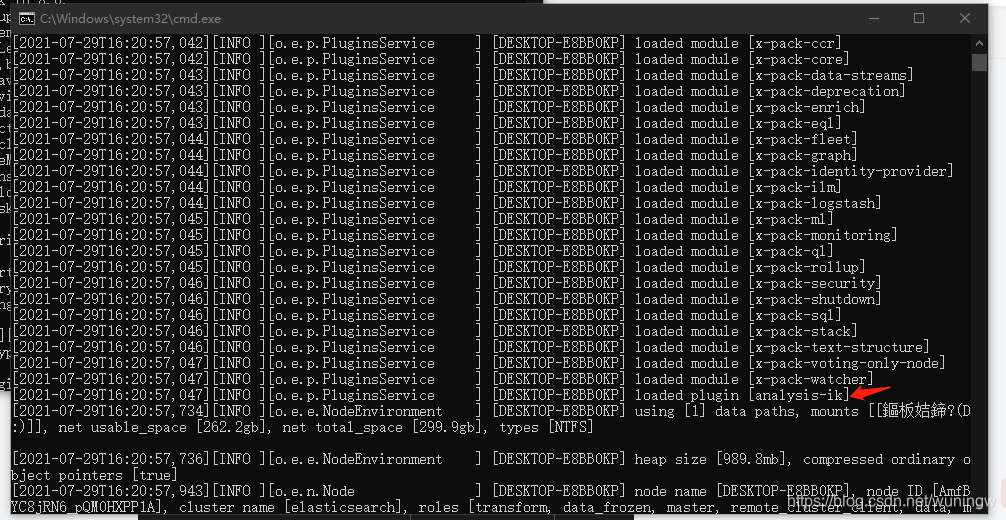
出现图中这个说明插件ik安装成功
5.elasticsearch不能再已经导入数据的index中去修改mapping,所以建立index之后立即配置分词器字段,然后再导入数据。
6.映射字段
PUT /chatting/_mapping
{
"properties": {
"create_time":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"update_time":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"content": {
"type": "text",
"fields": {
"ik_max_analyzer": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"ik_smart_analyzer": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
} }其中的content字段就是需要中文搜索的字段
7.term不会分词,keyword字段也不分词,安装了ik分词器,ik分词器是会默认分词的,所以java中就不能再使用TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery(“title”,keyword);这种方法了,应该换成 MatchPhraseQueryBuilder matchPhraseQueryBuilder = QueryBuilders.matchPhraseQuery(“title”, keyword);完全匹配的模式!!!
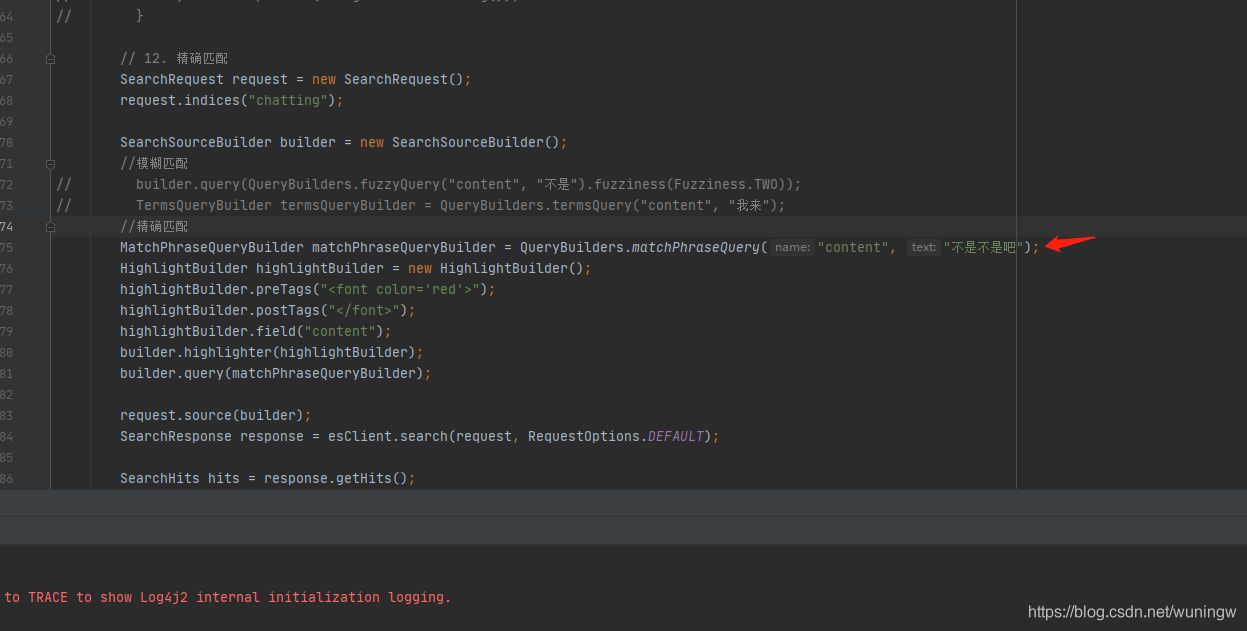
若是通过工具命令就换成这种查询
GET /chatting/_search
{
"query": {
"match_phrase": {
"content": {
"query": "不是不是吧"
}
}
},
"from": 0,
"size": 20
}最后就解决了。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









