






非常好的一篇论文,很有启发!
pdf: https://www.nature.com/articles/s40494-025-01839-z
1.摘要
现有深度学习技术在自动识别甲骨文方面面临诸多挑战,包括对局部特征缺乏精细控制、忽略纹理信息,以及对高区分度特征学习不足等问题。为解决这些难题,本文提出了一种新型甲骨文图像处理模型——OracleNet。该模型由自适应形变模块、纹理-结构解耦模块和多层次结构化感知注意力模块构成:自适应形变模块通过自适应点增强局部特征控制能力,同时保持文字语义的完整性;纹理-结构解耦模块通过区分纹理与结构特征提升识别精度;多层次结构化感知注意力模块则从宏观与微观视角细化特征差异。经在多个数据集上验证,OracleNet在Oracle-241、OBC306及Oracle-MNIST数据集上均取得了最先进的性能表现,充分证明了该模型在准确性与鲁棒性方面的优越性。
2.Introduction
甲骨文的自动识别仍面临诸多挑战,主要包括:(1)标注数据稀缺;(2)甲骨文图像中复杂的纹理与结构特征难以有效分离;(3)需要具备高度区分性的特征以辨别形近字并处理磨损变形等问题。
2.1标注数据稀缺;
首先,标注数据稀缺是主要挑战之一。甲骨文字符极为罕见,且标注需要高度专业知识,过程昂贵而耗时,导致可用标注数据严重受限,传统监督学习方法难以有效应用。为缓解数据不足,数据增强方法被广泛采用。但传统增强技术如旋转、缩放、错切和翻转在处理甲骨文时存在明显局限,这是因为甲骨文的语义信息高度依赖其结构特征(如笔画形态与相对位置),简单几何变换可能破坏这些关键特征。为此,非刚性数据增强方法如自由形变和弹性变换被提出,这些方法通过改变图像形状与对齐生成新样本,而不直接修改图像内容。然而,自由形变在处理复杂局部特征时缺乏精细控制,可能无法准确保留甲骨文的细微结构;弹性变换虽能调整空间对齐,但其固定正则化参数无法适应甲骨文图像的细微变化,导致增强过程中丢失部分局部特征。此外,这些方法在处理高分辨率甲骨文图像时计算成本较高,难以适用于大规模应用。
2.2(甲骨文图像中复杂的纹理与结构特征难以有效分离;
其次,甲骨文图像中纹理与结构特征的复杂交织给特征提取带来挑战。甲骨文拓片(目标域)与摹本(源域)在纹理和结构上存在显著差异:摹本数据字形清晰且主要包含结构信息,而拓片数据包含模糊退化等复杂噪声,提供丰富的纹理特征。若不加区分地对齐这些特征,丰富的纹理信息可能误导模型,使其难以学习领域不变特征。大多数领域自适应方法无法有效缩小不同域间的特征分布差异。部分研究尝试通过特征解耦分离纹理与结构信息,但常忽视纹理信息的作用。例如,UDCN仅将结构语义信息纳入适配,忽略了纹理信息对图像磨损、污渍和变形的影响。MixupAda结合混合数据增强与对抗领域自适应以提升领域适应性能。TransPar是基于Transformer的部分领域自适应方法,专注于迁移源域与目标域共享的特征表示。FixBi是一种双向对齐方法,旨在更好桥接源域与目标域的特征空间以实现有效领域适应。PRONOUN利用原型表示和归一化输出调节器增强模型泛化能力。BSP通过批量谱惩罚平衡对抗领域自适应中的移动性与判别性。
2.3需要具备高度区分性的特征以辨别形近字并处理磨损变形等问题。
最后,由于书写风格差异及甲骨文字符笔画结构的显著变化,模型需要具备高度判别性特征学习能力。识别甲骨文字符不仅需区分视觉相似的字符,还要处理因磨损变形导致的细微差异。
为解决上述三大挑战,本文提出了OracleNet。具体而言,我们在该网络中设计了三个模块:自适应形变模块、纹理-结构解耦模块和多层次结构化感知注意力模块。自适应形变模块基于自由形变引入自适应控制点,增强对甲骨文图像局部形变的精细控制,通过微调保持字符关键结构特征,使模型更好适应图像中的复杂局部特征,减少形变导致的语义信息丢失。纹理-结构解耦模块通过特征解耦分离图像中的纹理与结构特征,使模型更准确理解并利用图像中不同类型的信息。多层次结构化感知注意力模块通过多层次注意力机制增强模型对结构特征的感知能力,利用自注意力在宏观与微观层面捕捉图像关键信息:宏观层面帮助模型识别图像关键区域与特征,微观层面进一步细化这些特征,确保模型既能区分视觉相似的汉字,又能处理磨损变形引起的细微差异。该模块的设计旨在提升模型对复杂甲骨文图像的适应能力及整体识别性能。通过这三个模块,OracleNet不仅能精确处理甲骨文图像中的复杂形变与噪声,还能有效分离并利用结构与纹理特征,显著提升甲骨文字符的识别精度与鲁棒性。
本文的主要贡献如下:
(1)所提OracleNet中的自适应形变模块利用自适应控制点实现对甲骨文图像更精细的局部形变调整,这些调整在保持甲骨文字符关键结构特征的同时,能适应图像中的复杂局部特征,从而减少形变导致的语义信息损失。
(2)OracleNet中的纹理-结构解耦模块通过特征解耦技术有效分离甲骨文图像中的纹理与结构特征,使模型更准确理解并利用图像中的不同信息,提升对甲骨文的识别能力。
(3)所设计的多层次结构化感知注意力模块采用注意力机制从图像宏观与微观层面捕捉关键信息,不仅帮助模型识别图像关键区域与特征,还能进一步细化这些特征,确保模型能区分视觉相似的汉字并处理磨损变形引起的细微差异。
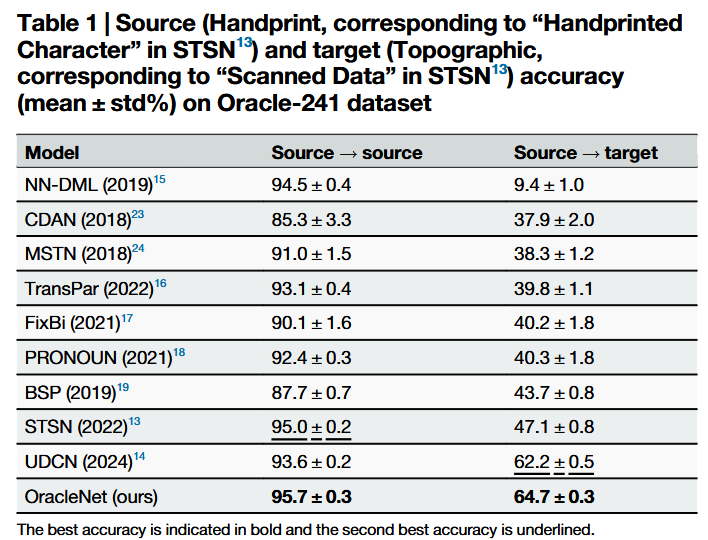
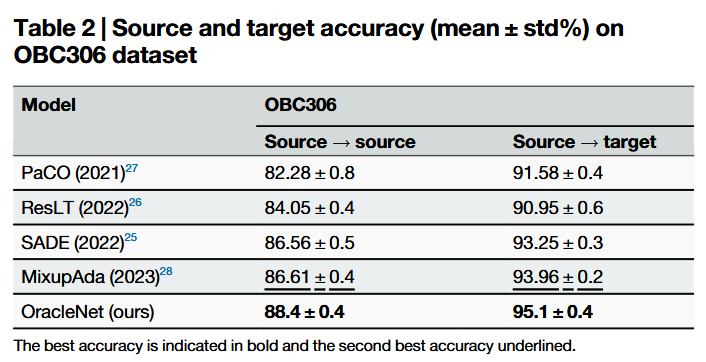
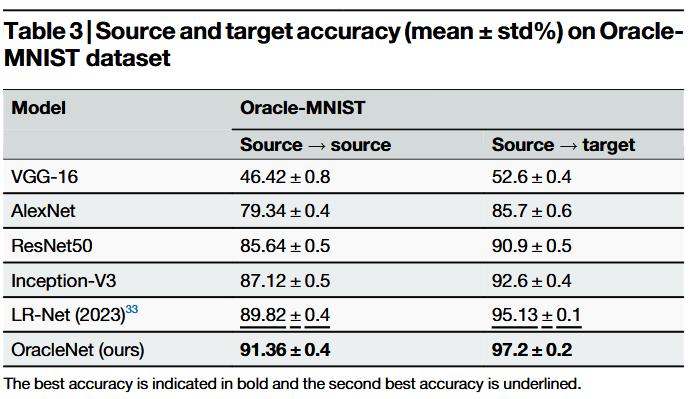
(4)通过在多个甲骨文数据集上的大量实验验证,OracleNet在识别精度与鲁棒性上显著优于现有方法。与先前最佳方法相比,我们的方法在Oracle-241数据集上使甲骨文字符识别准确率提升2.5%,在OBC306数据集上提升1.74%,在Oracle-MNIST数据集上提升2.07%。
与以往方法不同,本文利用甲骨文自身的结构信息(包括笔画形状、长度和相对位置)结合纹理信息(如裂痕与磨损痕迹)进行领域自适应,以减少处理不同数据集时的性能差异。
3.Methods
3.1 Problem formulation
给定M个带有标签的手写摹本源域样本及其对应标签
,以及N个无标签的拓片目标域样本
,源域与目标域之间存在显著的分布差异,即
![]() 。本研究的目标是通过同时利用带标签的源域{
。本研究的目标是通过同时利用带标签的源域{,
}和无标签的目标域{
}训练一个模型G,使其能够在数据(拓片数据)上实现良好泛化。具体而言,旨在优化模型G以最小化两个域上的预测误差,其表达式为:
![]()
其中和
分别代表源域和目标域的损失函数,λ是平衡两个域重要性的超参数。因此,模型G被设计用于获取在两个域中同样有效的域不变特征,从而提升在未见过的目标域地形数据上的性能。
3.2 模型概述
如图1所示,本文提出的OracleNet模型包含三个模块:自适应形变模块、纹理-结构解耦模块和多层次结构化感知注意力模块,旨在提升甲骨文图像的处理效果与泛化能力。自适应形变模块采用自适应控制点技术对甲骨文图像进行精确的局部调整。相较于传统的自由形变技术,自适应控制点能够根据图像内容动态调整,更准确地处理复杂局部特征,有效保持甲骨文的细微结构,同时减少形变过程中的信息损失。在处理甲骨文图像时,区分结构特征与纹理特征尤为重要。纹理-结构解耦模块能有效分离图像的纹理与结构特征,这不仅增强了结构特征的识别精度,还使模型能更好地处理因图像磨损和退化产生的纹理噪声。多层次结构化感知注意力模块利用自注意力机制在多层次上增强对甲骨文图像的感知与识别能力。通过在宏观与微观层面应用注意力机制,该模块不仅能识别图像中的关键区域与特征,还能细化这些特征以区分视觉相似的汉字,并适应图像中的轻微形变与磨损。
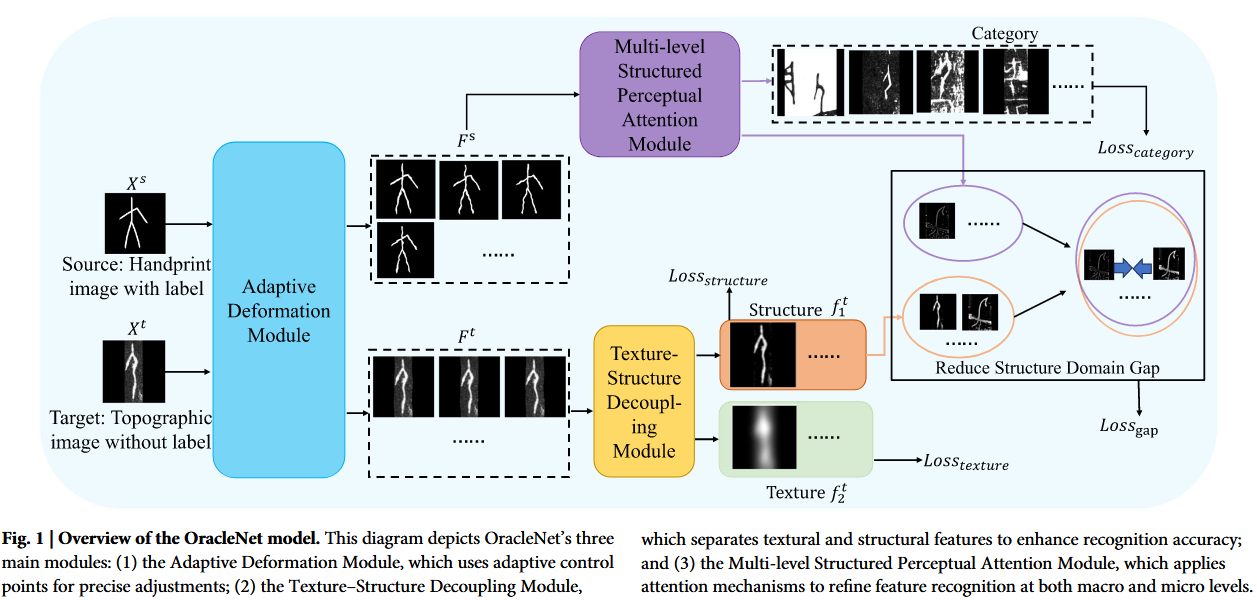
3.3 Adaptive Deformation Module
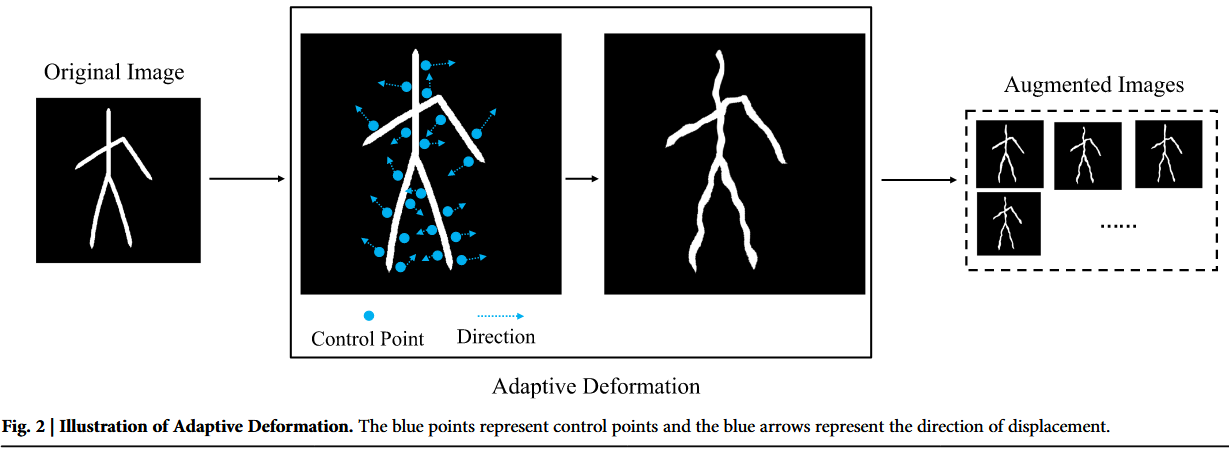
传统的自由形变技术(FFD)通过在图像上设置规则网格的控制点并移动这些点来实现图像局部形变。针对甲骨文图像特殊的结构特征与细节要求,本文引入自适应控制点技术,根据图像内容动态调整控制点的密度与方向,从而实现更精细的局部形变控制。具体细节如图2所示。此时,对于手写摹本源域样本,改进后的自由形变变换函数可表示为:
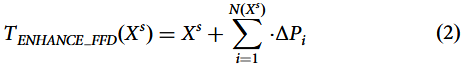
其中是基于手写摹本源域样本
的控制点数量,
为控制点i的位移矢量。每个控制点i的位移矢量
不仅取决于控制点的原始位置,还受周围局部区域的特征变化影响。位移矢量的方向与大小通过以下过程确定:
![]()
其中表示控制点i周围的图像梯度,
是根据图像内容自动调整位移方向与范围的参数。这种调整确保控制点的移动能够增强图像的结构表现能力。
可通过以下方式自动计算:
3.3.1结构清晰、笔画分明的手写摹本
对于结构清晰、笔画分明的手写摹本源域样本,本文利用图像的边缘强度与方向性作为主要特征动态计算
:
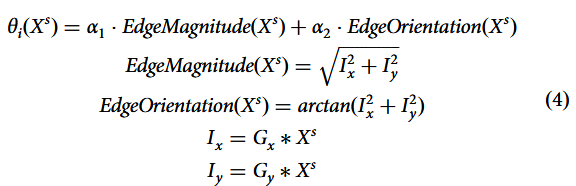
其中和
分别表示控制点 i 附近的边缘强度与方向。边缘强度函数量化控制点附近图像的显著变化程度,可用于控制形变程度;边缘方向函数则帮助调整控制点移动方向以与图像边缘方向保持一致,从而保持图像结构的连续性与完整性。
和
分别表示手写摹本源域样本在控制点i附近沿x和y方向的一阶导数。
和
为Sobel算子,常用于边缘检测,通过突出对应边缘的高空间频率区域来实现。
和
分别为权衡边缘强度与边缘方向贡献的系数。
注:Sobel算子 https://blog.youkuaiyun.com/great_yzl/article/details/119709699
3.3.2包含噪声与退化的目标域拓片样本
对于包含噪声与退化的目标域拓片样本,本文利用局部对比度与噪声抑制作为主要特征动态计算
:
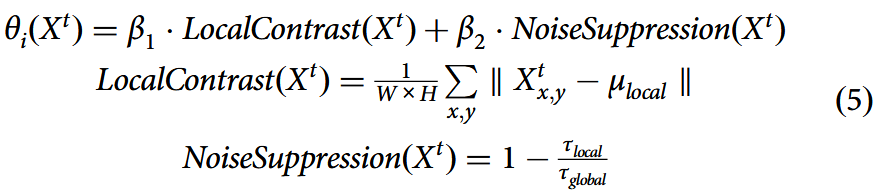
其中表示局部对比度,用于增强图像中重要特征的可见性;
表示噪声抑制程度,有助于减少噪声对控制点位移的影响。
和
分别为权衡局部对比度与噪声抑制贡献的系数。
为图像
在位置(x,y)处的像素值,
是
在控制点 i 附近区域像素的平均值,W和H为局部窗口的宽度与高度,
是
在控制点 i 附近区域像素值的标准差,
是整个图像
像素值的标准差。
通过上述改进,自适应形变模块能够从手写摹本源域样本生成增强样本
,并从无标签目标域拓片样本
生成增强样本
,具体如下:
![]()
该模块有助于增加数据多样性并提升模型泛化能力,同时不损害甲骨文图像的原始语义内容。通过实施这些形变,图像在保持本质特征的同时能够适应真实场景中可能遇到的变化,从而增强后续识别任务的鲁棒性与准确性。
3.4 Texture–Structure Decoupling Module
为有效处理甲骨文图像,特别是具有复杂纹理的拓片数据,区分结构特征与纹理特征至关重要。
结构特征指构成文字本身固有的、与形状相关且具有语义意义的成分,这些特征是文字身份识别的基础。具体而言,甲骨文图像的结构特征主要包括:文字形态与轮廓、笔画构成与排布、几何信息以及拓扑结构。这些结构特征通过聚焦于定义文字形态的本质线条与曲线进行识别,同时最小化无关元素的影响。反之,甲骨文图像中的纹理特征指与文字语义身份或结构形态无直接关联的表面视觉模式与变化,通常是甲骨材质特性、刻写工艺、老化过程及图像采集过程引入的领域特定噪声或伪影。甲骨文图像的纹理特征通常包括:表面噪声与颗粒、裂痕与缝隙、污渍与变色、模糊与退化以及磨损与侵蚀痕迹。甲骨文摹本图像通常包含结构特征,而拓片数据还包含纹理特征。
纹理-结构分析模块旨在从无标签目标域增强样本中提取结构特征
与纹理特征
。该模块的核心思想是通过最小化
与手写摹本源域增强样本
之间的差异(对于结构特征)和最大化两者差异(对于纹理特征)来实现特征分离。甲骨文图像的结构特征主要由其形状、轮廓及其他几何信息构成,提取结构特征
的问题可表述为:
![]()
其中 S 表示提取结构特征的操作。这是因为同时包含结构特征与纹理特征,而
仅包含结构特征。通过最小化上述差异,可有效提取结构特征。对于甲骨文图像的纹理特征
,该问题可表述为:
![]()
其中表示提取纹理特征的操作。与提取结构特征
相反,纹理特征
可通过最大化差异获得。该方法强调区分目标域样本与源域样本中独特的纹理属性。
在公式(7)和(8)中,S表示从甲骨文图像中提取结构特征的抽象操作。它并非单一固定算法,而是对隔离并强调图像中与形状相关、具有语义意义成分这一过程的概念性表征,同时抑制或忽略与纹理相关的噪声与变化。本文中操作S(在结构分支内)的实现技术是注意力机制(位于多层次结构化感知注意力模块内,应用于结构特征),并以结构特征损失函数为指导。
类似地,表示提取纹理特征的抽象操作。其概念目标在于隔离并捕捉与文字结构形态及语义内容不同的表面视觉模式与变化。与操作S类似,
并非单一算法,而是对纹理-结构解耦模块内纹理特征提取过程的表征。本文中操作
(在纹理分支内)的实现技术是通过纹理聚焦损失函数
训练的网络层。
综上所述,公式(7)和(8)中的操作S和是概念性抽象,分别代表纹理-结构解耦模块内结构特征与纹理特征提取的不同目标:操作S旨在隔离并强调与形状相关、具有语义意义的成分;操作
旨在捕捉与结构形态不同的表面视觉模式与变化。
因此,结构特征损失函数可表示为:
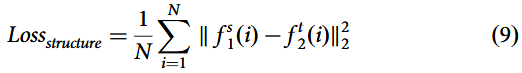
该结构特征损失函数用于最小化源域与目标域增强样本间的结构差异,采用均方误差度量差异程度。其中表示平方欧氏距离,N为总样本数,
和
分别表示源域与目标域第 i 个样本的结构特征。
纹理特征损失函数可表示为:
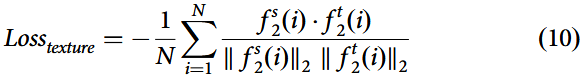
该纹理特征损失函数旨在最大化源域与目标域间的纹理差异,这可通过最小化负损失函数实现,其本质是最小化纹理特征间的相似性。通过使用负余弦相似度,可度量特征向量间的方向差异。其中表示向量的欧氏范数,
表示点积,
)和
分别表示源域与目标域第i个样本的纹理特征。
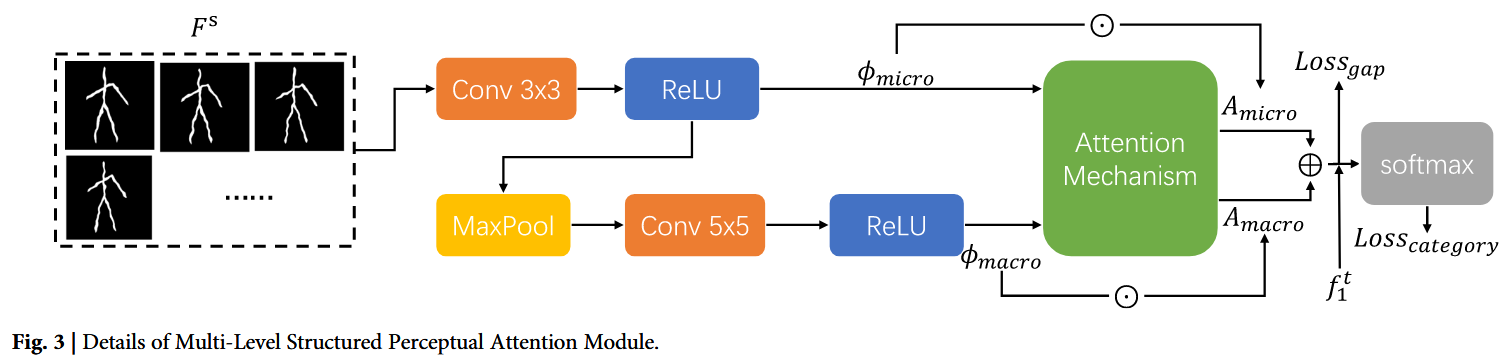
3.5 Multi-Level Structured Perceptual Attention Module
该模块聚焦于甲骨文图像的多层次结构特征,涵盖从基本笔画到复杂符号组合的完整体系,继而进行分层注意力学习与融合。具体而言,在微观层面捕捉甲骨文图像的边缘与基本形状,在宏观层面则聚焦整体布局、符号组合及其相互关系。该模块具体细节如图3所示。
微观层面特征提取可表示为:![]()
微观层面特征的特点在于其专注于甲骨文图像中的细粒度细节与局部结构。这些特征通过3×3卷积核提取,该卷积核提供较小的感受野,使模块能够捕捉局部模式。具体而言,微观特征主要捕获文字的边缘与细部笔画,同时涵盖构成文字基础构件的基本形状与局部模式。此外,这些特征对笔画内部的细节(如细微曲线、连接点及笔宽变化)具有敏感性。激活函数ReLU有助于突出这些微观结构特征。
宏观层面特征提取可表示为:![]()
相比之下,宏观层面特征的特点在于其强调更广泛的上下文信息与整体结构模式。这些特征通过5×5卷积核结合最大池化提取,该设计提供更大的感受野,使模块能够捕捉更全局的上下文信息。宏观特征捕获文字内部的整体布局与笔画空间排布,涵盖构成文字内部更大语义单元的笔画与符号组合。这些特征对甲骨文字符的整体形态具有敏感性,并捕获字符不同部分间的上下文关系,提供全局视角。其中5×5卷积核有助于捕捉更广泛的结构特征,最大池化操作则通过降低特征图维度并扩大感受野来增强对图像全局信息的捕捉。
本质上,微观层面特征聚焦局部细节与精细结构,宏观层面特征则关注甲骨文字符的整体布局与广义上下文信息。
针对甲骨文图像的微观与宏观层面特征,为每一层级设计了注意力模块以学习该层级结构特征的重要性。其表达式为:
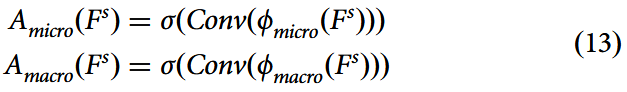
其中σ为sigmoid函数,Conv为卷积操作,用于从分层特征中学习空间注意力。
微观与宏观层级的注意力加权特征经过融合得到综合输出特征:
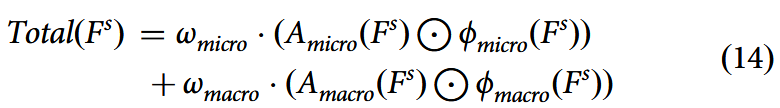
其中和
为学习得到的权重参数。
通过添加全连接层进行分类可表示为:![]()
其中W和b分别为权重与偏置参数。
采用交叉熵的分类损失函数可表示为:
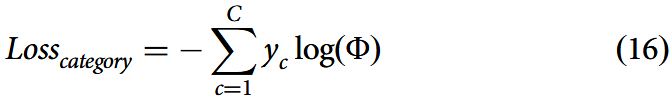
其中C为总类别数,表示类别 c 是否为样本的正确分类,Φ表示样本被分类为 c 的概率。
领域差异损失函数表示为:
![]()
其中表示平方欧氏距离。该损失函数旨在最小化源域增强样本
的加权特征与目标域结构特征
之间的欧氏距离,促使模型在两个不同域间找到一致的结构特征表示。该方法有效减少了源域与目标域间结构特征的差异,增强了模型在甲骨文拓片数据上的泛化能力,从而实现对未见甲骨拓片数据更准确的分类。
3.6 Total loss function
本文的总损失函数可具体表述为: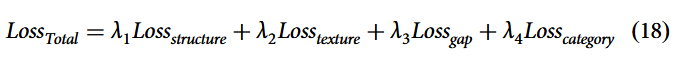
其中, 表示纹理-结构分析模块中与结构特征相关的损失,
表示同一模块中与纹理特征相关的损失,
表示领域自适应方法中使用的损失,
表示多层次结构化感知注意力模块中的分类损失。参数 λ₁、λ₂、λ₃ 和 λ₄ 为权重参数,用于平衡不同损失的贡献。
3.7 Sequential data flow
输入的甲骨文图像首先进入自适应形变模块。该模块通过自适应形变操作缓解域内变异,同时增强结构特征的显著性。此形变过程确保后续模块能够在结构优化的输入上进行处理。自适应形变模块的输出随后传入纹理-结构解耦模块。该模块在分离纹理与结构信息方面发挥关键作用:通过对两类特征解耦,使模型能够专注于学习域不变的结构表示,从而有效处理甲骨文图像固有的纹理噪声。纹理-结构解耦模块生成的双特征流随后输入多层次结构化感知注意力模块。该模块通过分层架构提取并优化多尺度结构特征,利用宏观与微观层级的注意力机制聚焦甲骨文最显著的特征区域,进一步提升特征判别力。最终,经多层次结构化感知注意力模块优化的特征表示被传递至分类器以生成识别结果。
3.8 基于联合训练的协同优化
OracleNet采用端到端训练模式,使得各模块能够以相互依赖的方式实现联合优化。总损失函数LossTotal通过整合LossStructure、LossTexture、LossGap与LossCategory损失项,统筹协调这一联合优化过程。在反向传播中,源自总损失函数的梯度流经多层次结构化感知注意力模块、纹理-结构解耦模块与自适应形变模块,从而指导各模块的学习过程。这种联合训练模式实现了协同学习效应:自适应形变模块学习为纹理-结构解耦模块提供最优输入;纹理-结构解耦模块学习提取最能发挥多层次结构化感知注意力模块注意力机制效能的特征;而多层次结构化感知注意力模块则学习聚焦于从结构增强与纹理解耦表示中提取最具判别力的特征。
功能互补性
各模块在OracleNet的整体优化中扮演互补角色:自适应形变模块降低数据方差并标准化输入;纹理-结构解耦模块解耦纹理干扰因素以实现对结构的聚焦;多层次结构化感知注意力模块则提供精细化多尺度特征分析。这种精心设计的模块化架构与端到端联合训练相结合,共同促成了OracleNet在甲骨文识别任务中的卓越性能。
4. Results
Comparison of other methods
5.Discussion
尽管OracleNet在甲骨文识别领域展现出显著进展,但仍需正视其局限性及未来可能的改进方向。首先,对特定噪声或形变的鲁棒性局限:尽管OracleNet对多种类型的噪声和形变具有鲁棒性,但对于训练数据中未充分体现的极端严重或特殊类型的噪声与畸变,模型仍可能面临挑战。如误差分析所示,过度模糊或高度异常的形变模式仍可能导致误分类。提升对这些极端条件的鲁棒性仍是未来研究方向之一。其次,形近字区分难题:尽管引入了多层次结构化感知注意力模块,区分视觉高度相似的甲骨文字符仍是持续存在的挑战。在图像退化条件下,字形高度相近的字符类别间存在的细微视觉差异,模型仍难以精准分辨。未来工作可探索引入更细粒度的特征提取与对比学习方法以应对此局限。解决这些局限性将是我们未来研究的重点,旨在进一步提升甲骨文识别模型的鲁棒性与准确性。
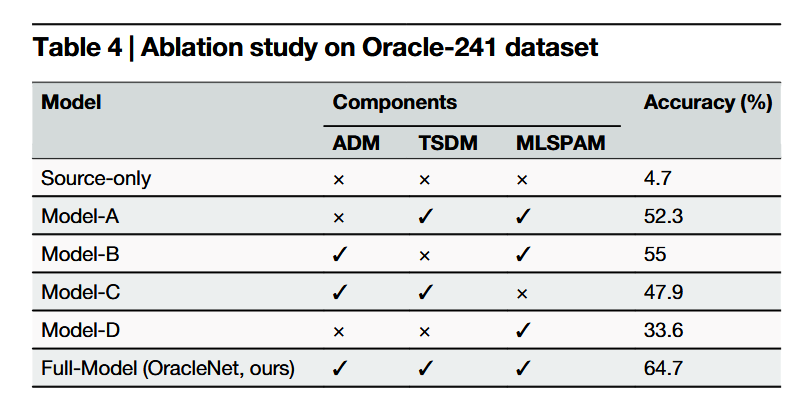
本研究提出的OracleNet是一种融合自适应形变模块、纹理-结构解耦模块与多层次结构化感知注意力模块的新型甲骨文识别方法。OracleNet实现了显著的性能提升,在甲骨文识别任务中展现出卓越的准确率与鲁棒性。具体而言,OracleNet在Oracle-241、OBC306和Oracle-MNIST数据集上均取得了最先进的性能表现。这些性能提升归功于OracleNet的创新设计:自适应形变模块实现了更精细的局部形变控制并保持语义完整性;纹理-结构解耦模块有效分离纹理与结构特征以提升识别精度;多层次结构化感知注意力模块通过宏观与微观视角优化特征判别力。这些模块的协同作用使OracleNet能够有效应对甲骨文识别中的复杂形变、噪声干扰及细微结构差异等挑战。大量实验结果与消融研究验证了OracleNet中各模块的有效性与贡献。
除了提升识别精度,OracleNet在文化遗产保护中的实际部署还面临若干关键挑战。技术层面,模型需应对现有数据集中未充分涵盖的极端新型退化形式,以及对结构差异极小的形近字进行精细区分。非技术挑战同样至关重要:伦理层面,人工智能的应用必须优先保障文物的完整性与真实性,确保自动化解译成为专家学术研究的辅助而非替代,并避免任何形式的误读。这需要建立透明可解释的人工智能系统。此外,为实现与考古及历史研究流程的有效整合,需审慎考虑用户交互体验。未来开发应聚焦于创建直观的交互界面,使文化遗产专业人员能够便捷地输入数据、审校识别结果、提供优化反馈并可视化模型的决策过程。此类以用户为中心的设计与清晰的伦理框架,是实现OracleNet在甲骨文保护与研究领域充分发挥实践价值与社会价值的关键。
展望未来,研究方向包括:进一步提升OracleNet对极端噪声与形变(尤其是当前数据集中未充分体现的类型)的鲁棒性;探索将OracleNet或其模块化设计应用于其他历史文字识别任务,如其他文明的古文字或退化文档图像;研究模型压缩技术以适应资源受限环境中的部署。这些方向旨在持续提升甲骨文识别技术的准确性、鲁棒性与适用性,为考古学与历史学研究的发展贡献力量。

















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









