 SCSA:空间与通道协同注意力机制
SCSA:空间与通道协同注意力机制







原文链接:【arXiv 2024】最新!空间和通道协同注意力SCSA,即插即用,分类、检测、分割涨点!
论文题目:SCSA: Exploring the Synergistic Effects Between Spatial and Channel Attention
论文链接:https://arxiv.org/pdf/2407.05128
二、论文概要
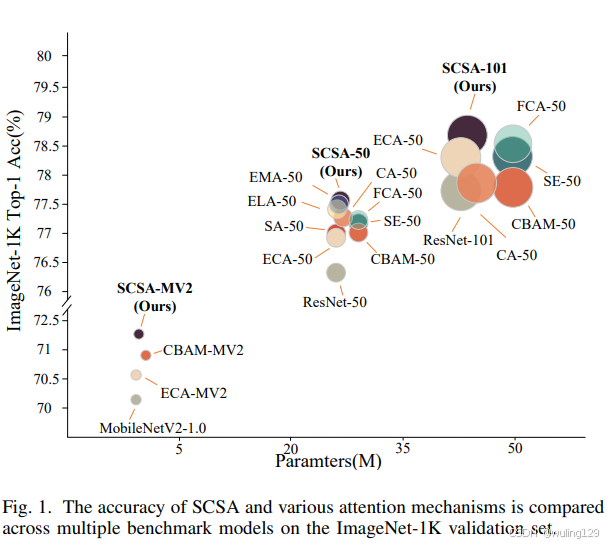
图1. 在ImageNet-1K验证集上,SCSA在Top-1准确率上超越了FCA、ECA、SE、CBAM、EMA、ELA等当前最先进的注意力机制。
研究背景:
-
视觉任务中的注意力机制:在视觉任务中,注意力机制通过增强表示学习,促进了更具区分性的特征学习,并广泛用于重新分配通道关系和空间依赖性。现有的通用注意力方法主要分为三类:通道注意力、空间注意力和混合通道-空间注意力。
-
空间和通道注意力的局限性:尽管空间和通道注意力在提取特征依赖性和空间结构关系方面带来了显著改进,但它们之间的协同效应尚未被充分探索。这导致了在利用多语义信息进行特征引导和缓解语义差异方面的潜力未能得到充分利用。
-
多语义信息的重要性:多语义信息在视觉任务中扮演着重要角色,它能够帮助模型更好地理解复杂场景和对象。有效的注意力机制应该能够整合和利用这些信息,以提高模型的性能。
-
研究动机:鉴于现有方法在处理复杂场景时的局限性,本文试图探索空间和通道注意力之间的协同效应,以期提出一种新的注意力机制,该机制能够更好地利用多语义信息,提高模型在各种视觉任务中的表现。
论文贡献:
-
提出SCSA模块:提出了一种新颖的Spatial and Channel Synergistic Attention(SCSA)模块,该模块由两部分组成:可共享的多语义空间注意力(SMSA)和渐进式通道自注意力(PCSA)。该模块旨在探索空间注意力和通道注意力之间的协同效应,以提升视觉任务中的性能。
-
SMSA:通过多尺度、深度共享的1D卷积来捕捉每个特征通道的多语义空间信息,有效地整合了全局上下文依赖和多语义空间先验。
-
PCSA:利用输入感知的自注意力机制来计算通道之间的相似性和贡献度,从而减轻了SMSA中不同子特征之间的语义差异。
-
实验验证:在七个基准数据集上进行了广泛的实验,包括ImageNet-1K上的分类、MSCOCO 2017上的目标检测、ADE 20K上的分割等,证明了SCSA在各种视觉任务中的有效性。
三、方法
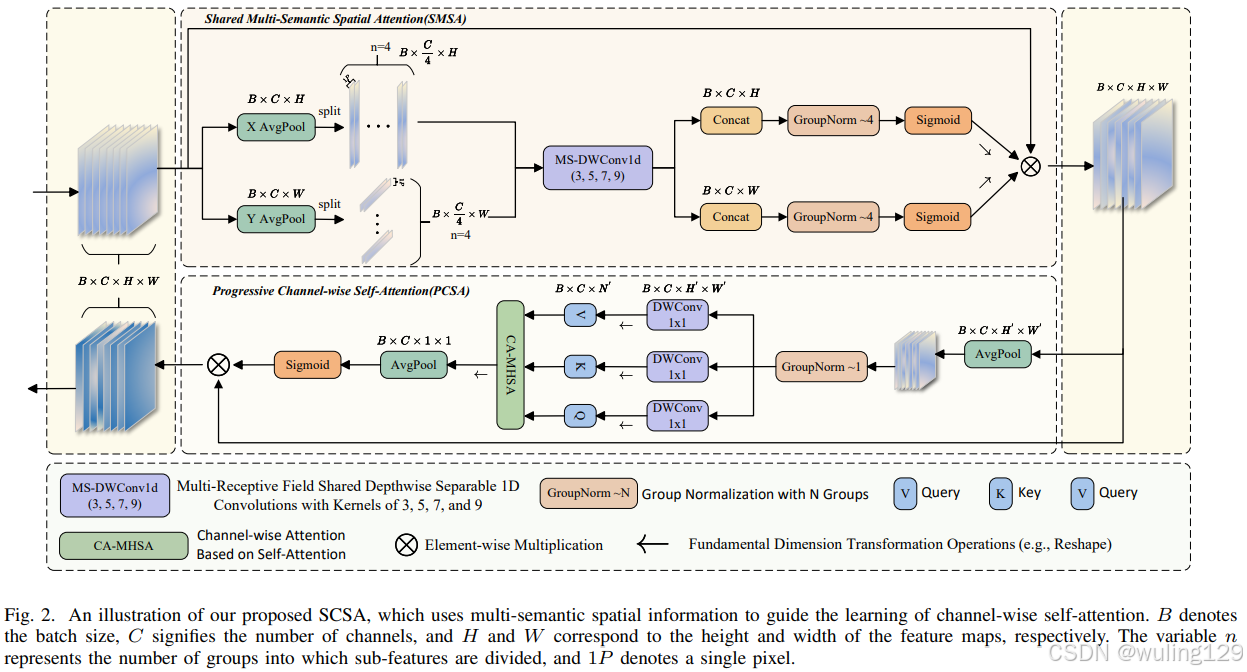
图2. SCSA(空间和通道协同注意力)的示意图,它使用多语义空间信息来指导通道级自注意力的学习。B表示批量大小,C表示通道数量,H和W分别对应特征图的高度和宽度。变量n代表子特征被划分成的组数,1P表示单个像素。
SCSA 空间和通道协同注意力由两部分组成:即Shareable Multi-Semantic Spatial Attention(SMSA,可共享的多语义空间注意力)和Progressive Channel-wise Self-Attention(PCSA,渐进式通道自注意力)。
SCSA的实现原理非常清晰,很容易理解,分为两步:1. 输入特征图经过SMSA进行空间特征增强,2. 再经过PCSA进行通道增强,从而得到输出。
1. SMSA 空间注意力实现原理
平均池化:
- 对输入特征图进行平均池化,计算出在高度和宽度方向的均值,从而获得两个新的特征图x_h和x_w 。
特征拆分:
- 将x_h拆分为四个部分:局部特征 l_x_h 和三个不同尺度的全局特征 g_x_h_s、g_x_h_m、g_x_h_l,每个部分包含的通道数为group_chans(C/4)。
- 同样地,对x_w进行拆分,得到相应的特征。
特征提取:
- 使用四个深度共享1D卷积(卷积核大小分别为3,5,7,9)对各部分特征进行处理,以提取不同尺度的信息。
空间注意力计算:
- 将提取的特征通过拼接(Concat)进行合并,并使用归一化层(GroupNorm)进行归一化处理。
- 通过门控机制(代码中可选Softmax或Sigmoid)计算出空间注意力权重 x_h_{attn} 和 x_w_{attn},这两个权重表示特征在空间上的重要性。
2. PCSA 通道自注意力实现原理
下采样:
- 使用指定的下采样方法(代码中可选平均池化、最大池化或重组合),对特征图x(B,C,H,W)进行下采样,得到更小的特征图(B,C,H',W')。
特征归一化与变换:
- 对下采样后的特征图进行归一化处理,然后利用1×1深度卷积生成查询(q)、键(k)和值(v),用于计算通道间的关系。
注意力矩阵计算:
- 将查询和键进行点积操作,计算注意力矩阵,并应用缩放因子来防止数值溢出。
- 通过门控机制(代码中可选Softmax或Sigmoid)操作计算得到最终的注意力权重,其中使用Dropout进行正则化处理。
加权求值:
- 将注意力权重与值(v)进行矩阵乘法,得到加权后的特征,作为通道增强特征图输出。
四、实验分析
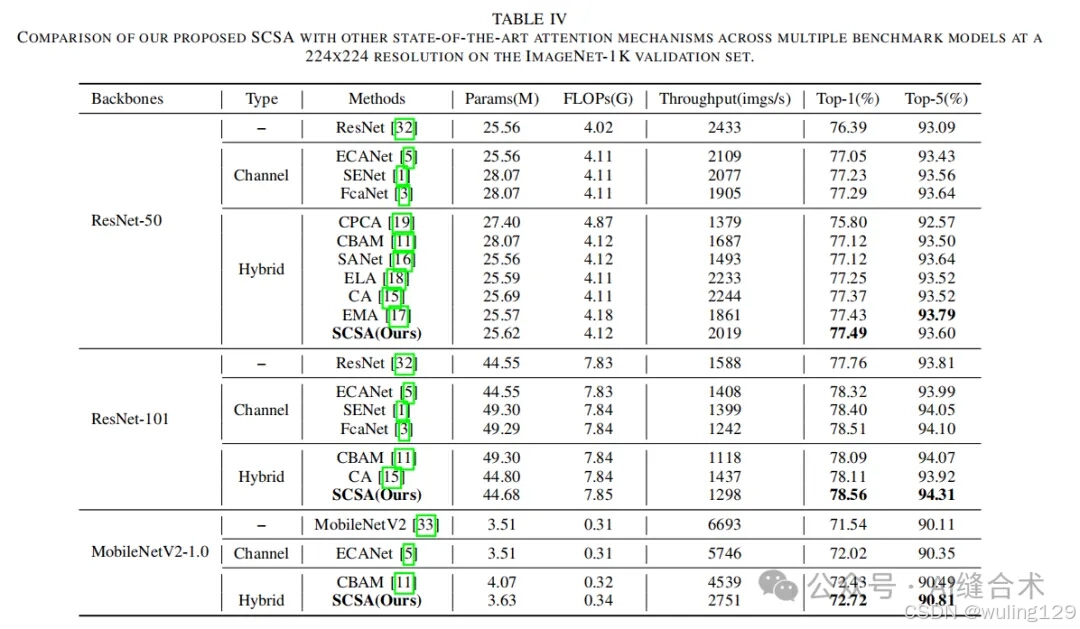
- ImageNet-1K分类:在ImageNet-1K数据集上进行了分类实验,SCSA在多个模型上取得了最高的Top-1准确率,例如在ResNet-50上达到了77.49%的准确率,而在ResNet-101上达到了78.51%。
-
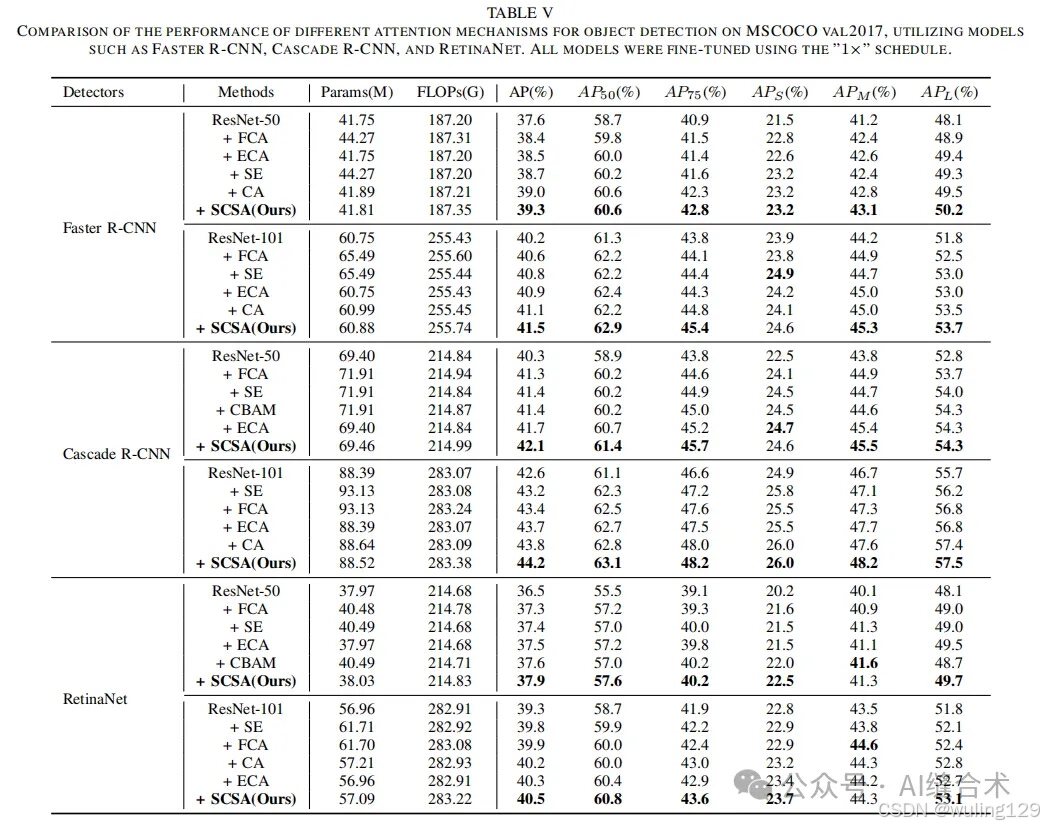
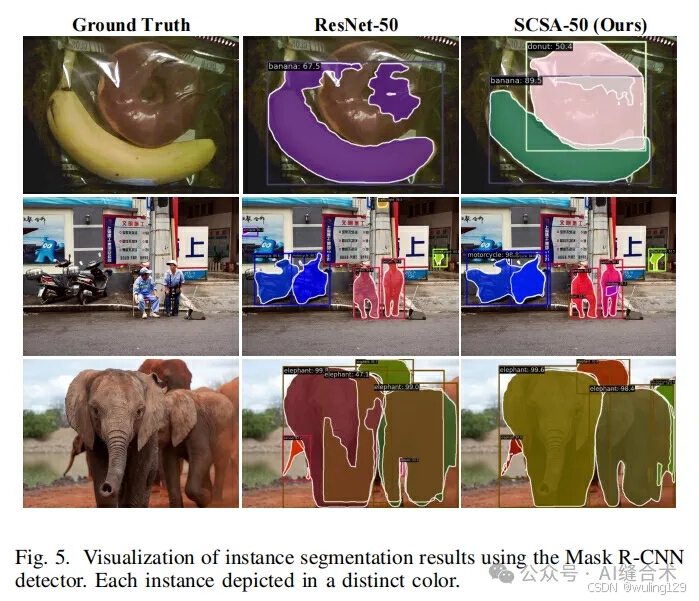
MSCOCO 2017:在MSCOCO 2017数据集上进行了目标检测、实例分割实验,使用了Faster R-CNN、Mask R-CNN、Cascade R-CNN和RetinaNet等检测器。实验结果显示,SCSA在不同检测器和模型大小上均优于其他最先进的注意力机制,例如在Faster R-CNN上,使用ResNet-50时,SCSA的平均精度(AP)提高了1.7%,使用ResNet-101时提高了1.3%。
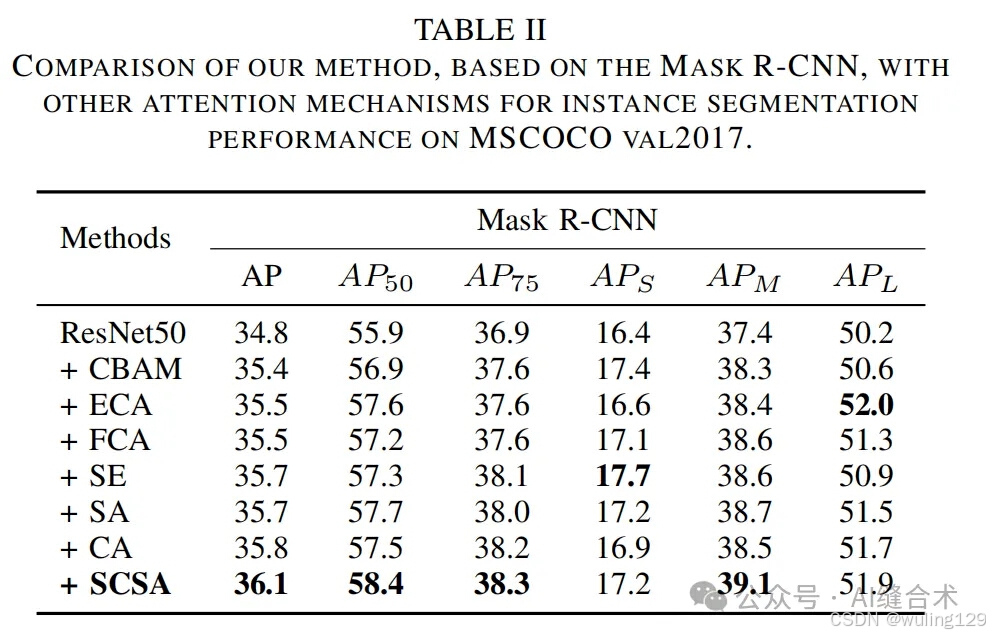

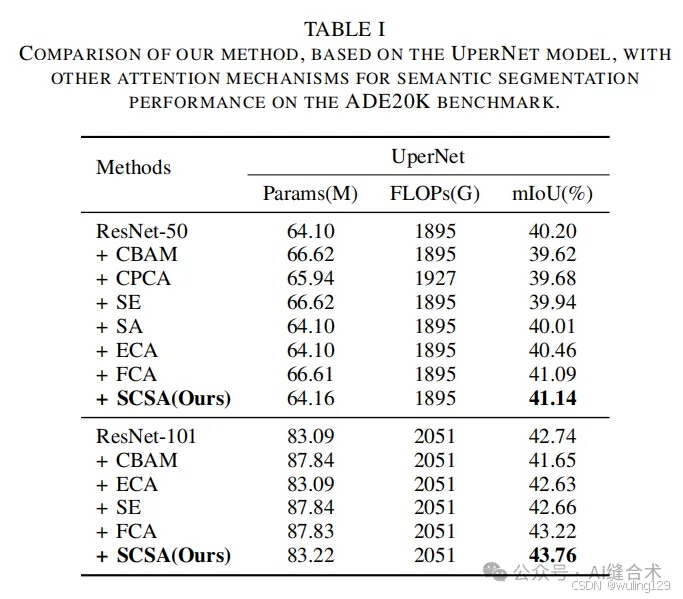
- ADE 20K:在ADE 20K数据集上进行了语义分割实验,使用了UperNet网络。实验结果表明,SCSA在ResNet-50和ResNet-101上分别提高了0.94%和1.02%的性能,显著优于其他注意力机制。

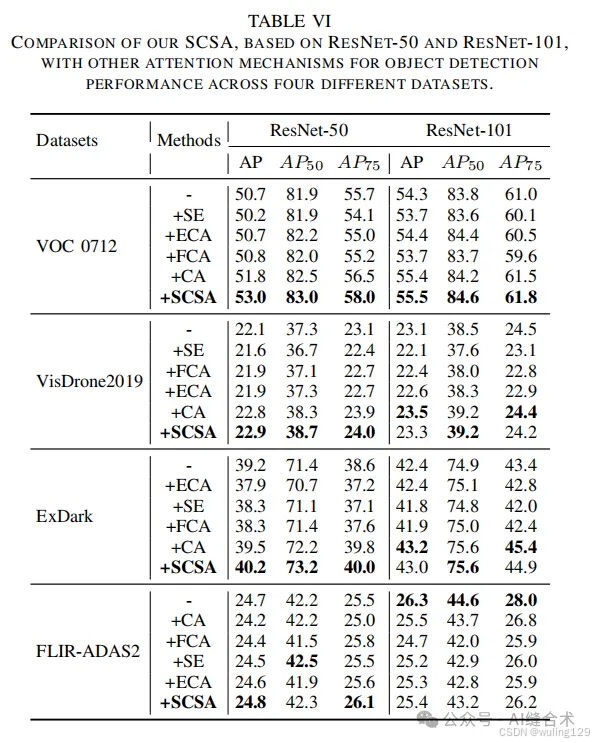
- 其他四个目标检测数据集:SCSA基于ResNet-50和ResNet-101与其他注意力机制在四个不同数据集上的物体检测性能比较。SCSA同样展示了在处理小对象、低光环境和复杂场景中的有效性。性能超越了SE、ECA、FCA、CA等注意力。
五、代码
import typing as t
import torch
import torch.nn as nn
from einops import rearrange
# 论文题目:SCSA: Exploring the Synergistic Effects Between Spatial and Channel Attention
# 中文题目: SCSA: 探索空间注意力和通道注意力之间的协同效应
# 论文链接:https://arxiv.org/pdf/2407.05128
# 代码来源:https://github.com/HZAI-ZJNU/SCSA
# 代码整理与注释:公众号:AI缝合术
# AI缝合术github:https://github.com/AIFengheshu/Plug-play-modules
class SCSA(nn.Module):
def __init__(
self,
dim: int,
head_num: int,
window_size: int = 7,
group_kernel_sizes: t.List[int] = [3, 5, 7, 9],
qkv_bias: bool = False,
fuse_bn: bool = False,
down_sample_mode: str = 'avg_pool',
attn_drop_ratio: float = 0.,
gate_layer: str = 'sigmoid',
):
super(SCSA, self).__init__() # 调用 nn.Module 的构造函数
self.dim = dim # 特征维度
self.head_num = head_num # 注意力头数
self.head_dim = dim // head_num # 每个头的维度
self.scaler = self.head_dim ** -0.5 # 缩放因子
self.group_kernel_sizes = group_kernel_sizes # 分组卷积核大小
self.window_size = window_size # 窗口大小
self.qkv_bias = qkv_bias # 是否使用偏置
self.fuse_bn = fuse_bn # 是否融合批归一化
self.down_sample_mode = down_sample_mode # 下采样模式
assert self.dim % 4 == 0, 'The dimension of input feature should be divisible by 4.' # 确保维度可被4整除
self.group_chans = group_chans = self.dim // 4 # 分组通道数
# 定义局部和全局深度卷积层
self.local_dwc = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[0],
padding=group_kernel_sizes[0] // 2, groups=group_chans)
self.global_dwc_s = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[1],
padding=group_kernel_sizes[1] // 2, groups=group_chans)
self.global_dwc_m = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[2],
padding=group_kernel_sizes[2] // 2, groups=group_chans)
self.global_dwc_l = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[3],
padding=group_kernel_sizes[3] // 2, groups=group_chans)
# 注意力门控层
self.sa_gate = nn.Softmax(dim=2) if gate_layer == 'softmax' else nn.Sigmoid()
self.norm_h = nn.GroupNorm(4, dim) # 水平方向的归一化
self.norm_w = nn.GroupNorm(4, dim) # 垂直方向的归一化
self.conv_d = nn.Identity() # 直接连接
self.norm = nn.GroupNorm(1, dim) # 通道归一化
# 定义查询、键和值的卷积层
self.q = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.k = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.v = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.attn_drop = nn.Dropout(attn_drop_ratio) # 注意力丢弃层
self.ca_gate = nn.Softmax(dim=1) if gate_layer == 'softmax' else nn.Sigmoid() # 通道注意力门控
# 根据窗口大小和下采样模式选择下采样函数
if window_size == -1:
self.down_func = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化
else:
if down_sample_mode == 'recombination':
self.down_func = self.space_to_chans # 重组合下采样
# 维度降低
self.conv_d = nn.Conv2d(in_channels=dim * window_size ** 2, out_channels=dim, kernel_size=1, bias=False)
elif down_sample_mode == 'avg_pool':
self.down_func = nn.AvgPool2d(kernel_size=(window_size, window_size), stride=window_size) # 平均池化
elif down_sample_mode == 'max_pool':
self.down_func = nn.MaxPool2d(kernel_size=(window_size, window_size), stride=window_size) # 最大池化
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
输入张量 x 的维度为 (B, C, H, W)
"""
# 计算空间注意力优先级
b, c, h_, w_ = x.size() # 获取输入的形状
# (B, C, H)
x_h = x.mean(dim=3) # 沿着宽度维度求平均
l_x_h, g_x_h_s, g_x_h_m, g_x_h_l = torch.split(x_h, self.group_chans, dim=1) # 拆分通道
# (B, C, W)
x_w = x.mean(dim=2) # 沿着高度维度求平均
l_x_w, g_x_w_s, g_x_w_m, g_x_w_l = torch.split(x_w, self.group_chans, dim=1) # 拆分通道
# 计算水平注意力
x_h_attn = self.sa_gate(self.norm_h(torch.cat((
self.local_dwc(l_x_h),
self.global_dwc_s(g_x_h_s),
self.global_dwc_m(g_x_h_m),
self.global_dwc_l(g_x_h_l),
), dim=1)))
x_h_attn = x_h_attn.view(b, c, h_, 1) # 调整形状
# 计算垂直注意力
x_w_attn = self.sa_gate(self.norm_w(torch.cat((
self.local_dwc(l_x_w),
self.global_dwc_s(g_x_w_s),
self.global_dwc_m(g_x_w_m),
self.global_dwc_l(g_x_w_l)
), dim=1)))
x_w_attn = x_w_attn.view(b, c, 1, w_) # 调整形状
# 计算最终的注意力加权
x = x * x_h_attn * x_w_attn
# 基于自注意力的通道注意力
# 减少计算量
y = self.down_func(x) # 下采样
y = self.conv_d(y) # 维度转换
_, _, h_, w_ = y.size() # 获取形状
# 先归一化,然后重塑 -> (B, H, W, C) -> (B, C, H * W),并生成 q, k 和 v
y = self.norm(y) # 归一化
q = self.q(y) # 计算查询
k = self.k(y) # 计算键
v = self.v(y) # 计算值
# (B, C, H, W) -> (B, head_num, head_dim, N)
q = rearrange(q, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
k = rearrange(k, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
v = rearrange(v, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
# 计算注意力
attn = q @ k.transpose(-2, -1) * self.scaler # 点积注意力计算
attn = self.attn_drop(attn.softmax(dim=-1)) # 应用注意力丢弃
# (B, head_num, head_dim, N)
attn = attn @ v # 加权值
# (B, C, H_, W_)
attn = rearrange(attn, 'b head_num head_dim (h w) -> b (head_num head_dim) h w', h=int(h_), w=int(w_))
# (B, C, 1, 1)
attn = attn.mean((2, 3), keepdim=True) # 求平均
attn = self.ca_gate(attn) # 应用通道注意力门控
return attn * x # 返回加权后的输入
if __name__ == "__main__":
#参数: dim特征维度; head_num注意力头数; window_size = 7 窗口大小
scsa = SCSA(dim=32, head_num=8, window_size=7)
# 随机生成输入张量 (B, C, H, W)
input_tensor = torch.rand(1, 32, 256, 256)
# 打印输入张量的形状
print(f"输入张量的形状: {input_tensor.shape}")
# 前向传播
output_tensor = scsa(input_tensor)
# 打印输出张量的形状
print(f"输出张量的形状: {output_tensor.shape}")
















 243
243





 到【灌水乐园】发言
到【灌水乐园】发言







