




 本文提出了一种利用汉字构形图(ChineseCharacterFormationGraph,CCFG)和GraphAttentionNetwork(FGAT)的方法,有效地区分部首的重要性,减少无关部首噪声。实验表明FGAT在汉字检测与识别中表现优秀,能更好地处理汉字编码和模型化问题。
本文提出了一种利用汉字构形图(ChineseCharacterFormationGraph,CCFG)和GraphAttentionNetwork(FGAT)的方法,有效地区分部首的重要性,减少无关部首噪声。实验表明FGAT在汉字检测与识别中表现优秀,能更好地处理汉字编码和模型化问题。
0、摘要
中文汉字通常是由偏旁部首组成的[1],这些偏旁部首本身包含了语义信息、字形信息、部首间关系,转换成特征描述是包含了空间特征、语义特征和部件特征非常有益于汉字的检测与识别。已有的利用汉字偏旁部首的方法包括基于部首的[2]、字形和部首间关系的[3]等。
但是现有的模型和编码对汉字不是最佳的,例如在引入部首信息和部首间信息的同时也把无关联的部首信息引入模型,这就增加了模型噪声。现有的方法无法分辨部首的重要程度,原因就在于无法过滤无关部首噪声带来的影响。
本文首先依据汉字的方位结构把汉字解耦成部首,即汉字构形图(Chinese character formation graph, CCFG)。CCFG保留了部首的空间方位关系,这有利于对汉字的部首内部语义特征进行显式建模。进一步,我们提出了Graph Attention Network (FGAT),FGAT可以有效的区分各部首的重要程序,有效提取部首层面的语义信息。实验也证明了这一点。
[1]Chinese Characters and Radicals Chinese Characters and Radicals
[2]Rare Chinese Character Recognition by Radical Extraction Network 笔记 - 简书
Rare Chinese Character Recognition by Radical Extraction Network
[3]https://www.cnblogs.com/bamtercelboo/p/9473202.html Improve Chinese Word Embeddings by Exploiting Internal Structure
百度:中文词向量论文综述 有惊喜
1、INTRODUCTION

不同于英文单词,超过80%的汉字通常由一个提供meaning的部首和一个提供发音的部首组成,如图2所示的妈(女提供性别信息即语义信息,马提供发音信息)。radical默认为汉字语义部首(甚至可以忽视汉字上下文),如泪字中的氵部首。所以有Sun et al. [39], Li et al. [21] and Yin et al. [46]三篇论文中利用汉字radical信息进行编码操作。有的汉字单个radical无法提供全部的语义信息,如抓字,扌(手)虽然是radical,但是需要和爪(动作)共同提供抓字的语义信息。因此,汉字的fine-grained components [47], stroke n-gram [6, 48] and structure [48]在语义上也是有意义的。
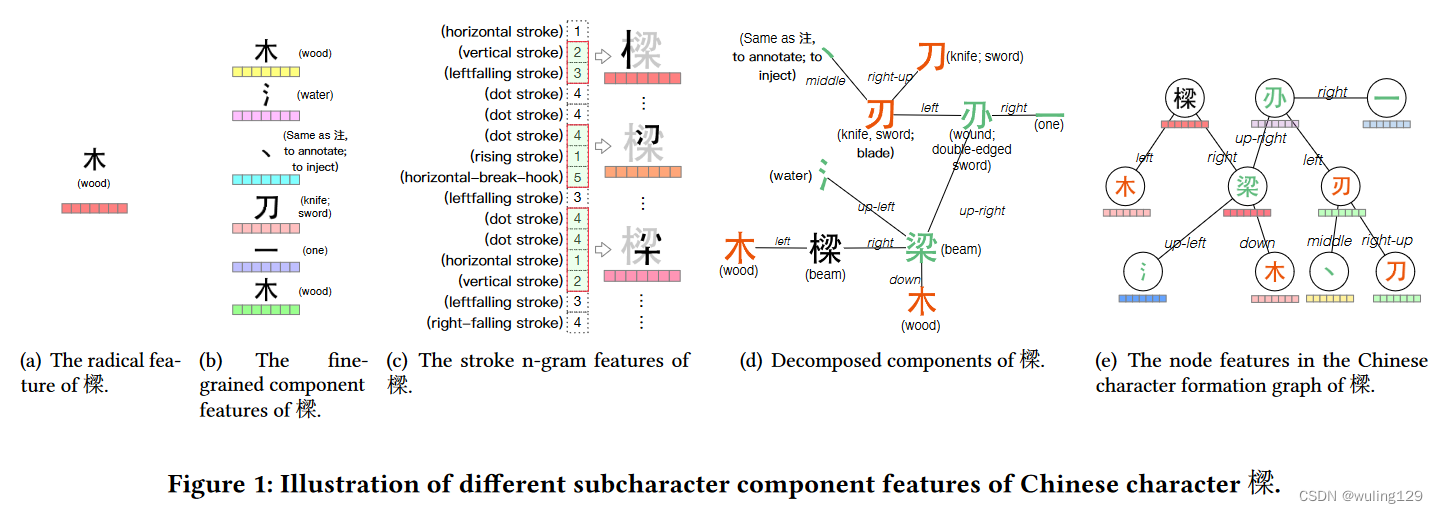 但是现有的方法并未完美解决汉字编码和模型化问题。如图1中的汉字“樑”,木 是radical,并提供了原材料信息,部件“梁”却定义了“樑”的意义。如果如图1(b)中采用fine-grained components拆解,虽然能提供详细的部首信息(木, 氵 丶,刀、木)但也带来语义无关的部首(such as 氵 and 丶);如采用stroke n-gram 分解“樑”也会带来无意义的笔画信息。这些语义无关和意思无关的部首是识别汉字的噪音。现有方法的部首均等(未正确分配部首权重,哪一个方法要确认),或把部首权重设置为超参数来计算权重,都不能很好的解决部首权重分配问题。
但是现有的方法并未完美解决汉字编码和模型化问题。如图1中的汉字“樑”,木 是radical,并提供了原材料信息,部件“梁”却定义了“樑”的意义。如果如图1(b)中采用fine-grained components拆解,虽然能提供详细的部首信息(木, 氵 丶,刀、木)但也带来语义无关的部首(such as 氵 and 丶);如采用stroke n-gram 分解“樑”也会带来无意义的笔画信息。这些语义无关和意思无关的部首是识别汉字的噪音。现有方法的部首均等(未正确分配部首权重,哪一个方法要确认),或把部首权重设置为超参数来计算权重,都不能很好的解决部首权重分配问题。
通过观察发现“樑”字可以按照字形结构进行递归分级拆解(如图1(d))。graph neural network可以很好的解决结构逐级编码的问题【19,42】,因此本文把汉字部首采用图网络结构进行表示,边表示节点间方位关系,这样得到汉字部首图网络(如图1e)。并基于字形图网络构建了Chinese Character Formation Graph Attention Network (FGAT)汉字部首图注意力网络。
2 RELATED WORK
3、METHODOLOGY
3.1 Chinese Character Formation
汉字结构[1,48],表示部首之间的方位关系。考虑到数据的准确性和完整性,论文从QXK中收集了BERT[11]词汇中汉字的构成和组成成分(https://qxk.bnu.edu.cn/)。

3.2 Chinese Character Formation Graph
我们根据汉字结构将其分解为部首,并将直接从汉字中分解出来的部首称之为one-hop 部首,将从one-hop 部首分解的部首称为two-hop部首,依此类推。最终得到汉字结构图,包含部首节点和部首间方位关系的边。如图1(e)所示“樑”字的结构图。
对于大多数具有相同结构的汉字,字符中具有相同方位的分解部首在分解部首表中具有相同的序列位置索引。我们用部首的序列位置索引来标识它的方位信息。形式上,我们首先对表1中列出的结构进行编号。如果汉字字符具有相同的结构(编号为m),它的one-hop分解部首列表的长度的最大值表示为;它的结构编号下标记为
反映了它自身的结构信息特征。并讲它的one-hop分解部首列表中的第i个部首的方位记为为
,
(1)
这个编号不太懂。
3.3 FGAT
Formation Graph Attention Network (FGAT) 构造了汉字结构图注意层,用以区分部首分层语义特征的重要性,并过滤汉字结构中的噪声子部首信息。不同于GAT [42],为了直接评估两个节点之间的语义相似性,将它们嵌入之间的点积作为注意力得分。本文将提出一个单一的汉字结构图注意层,它被部署在所有的FGAT架构中。
3.3.1 Notation
汉字,其自身结构编号为m,部件集为
,n是汉字部首的数量(应该是全部)。对
来说其汉字结构图记为
。
记为汉字结构图结点的特征编码,
记为方位编码,
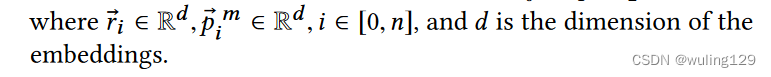
3.3.2 Embedding Layer
对结构图中的
来说,它的输入包含:特征+方位
(2)
所以结构图对应的FGAT输入可以表示为
不同于Transformer[41],我们引入方位编码来表示汉字结构图的方位信息特征。
3.3.3 Chinese Character Formation Graph Attentional Layer
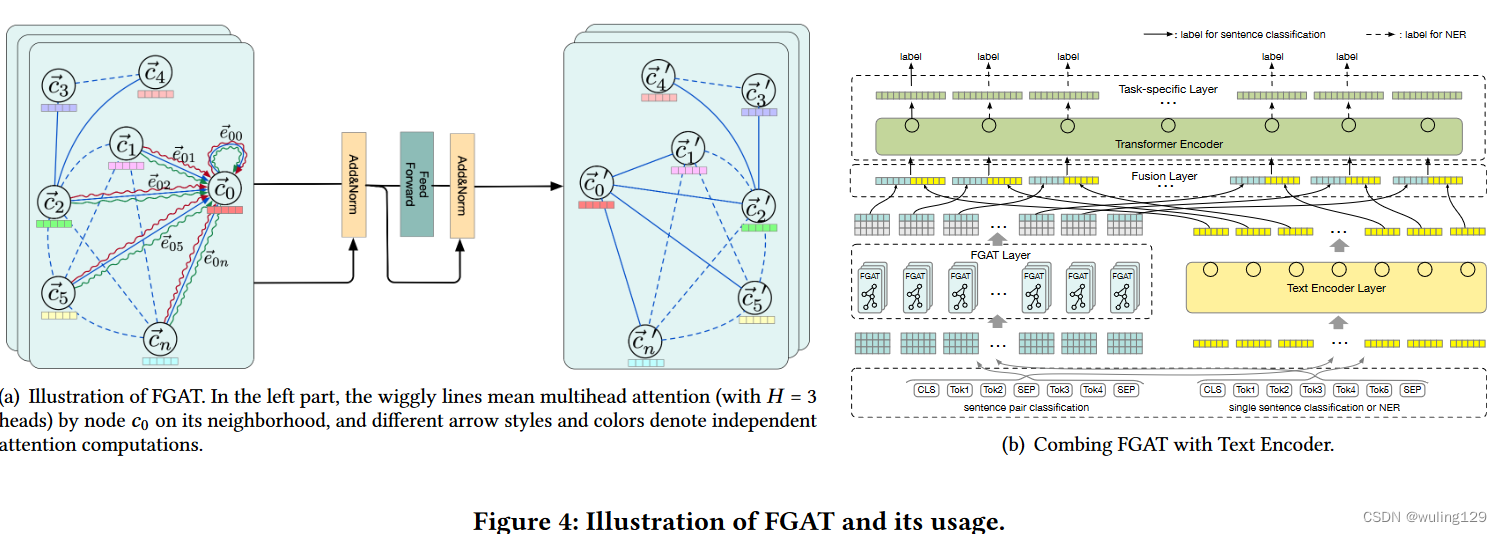
在汉字结构图注意层基础上,将根据相邻结点的表示来更新结点的表示信息。利用GAT思路和自注意力机制,汉字结构图注意层可通过边连接 递归传播结点语义特征。如图4(a)所示,字结构图注意层生成新的结点特征表示图。
邻接矩阵:为了直接获取同一结点one-hop的部首之间信息,我们定义了Component-Character-Component (3C) metapath [12](什么意思?). 如结点和其元路径3C(
为起点),其可见邻接点定义为
沿着给定元路径3C所能访问到结点的集合;并且one-hop部首之间可见关系表示为虚线(见Fig. 4(a));注意,我们抑制(消除)了 3C 中不同结点分解出部首节点的连接关系(只有同一接点的one-hop之间才有虚线,其他没有),如Fig. 4(a)中的
和
,由于他们不是同一个结点分解出来的所以没有关系。邻接矩阵A定义:
(3)
indicates that there is an edge between
and
, including solid and dashed line; while ci ↮ cj is not.i, j ∈ [0, n].矩阵A包含了字结构图中的结构信息。
信息聚合:参考Transformer [41]中的编码可以很容易的接收邻接矩阵A中的信息,聚合和它的邻接关系如下式:

3.4 Combining FGAT with Text Encoders
汉字的内部语义特征(提取自FGAT)可以直接用在下游文本编码中,such as convolutional neural networks [14, 18], recurrent neural networks [23, 40] and transformers [11, 41].由于大模型在NLP领域的巨大进展,我们优先考虑FGAT和transformer-based pretraining models结合,以同时获取部首层面的语义特征和大模型预训练的优点。
如Fig 4(b)所示,模型包含4层,依次是:the text encoder layer, the FGAT layer, the fusion layer and the task-specific output layer.(偷个懒,不翻了)

来自transformer编码器的输出表示被馈送到预测层中。在句子分类任务中,使用来自transformer编码器的特殊CLS标记的表示来表示句子序列的状态;transformer编码器的汉字标记表示用于表示命名实体识别(named entity recognition,NER)任务中的字符状态。如token和它的transformer输出表示
,
的输出label为
,得到目标函数:
(9)
4 EXPERIMENTS
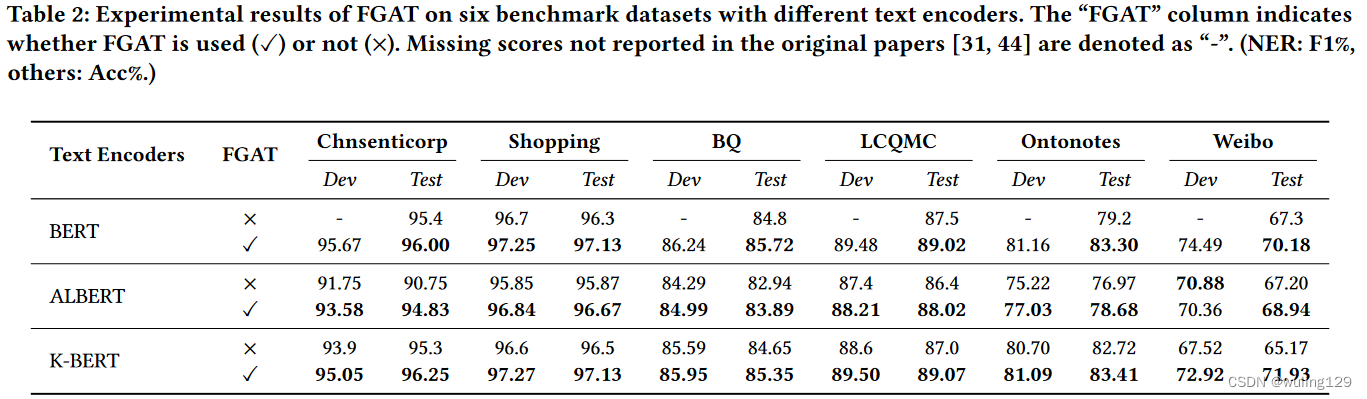
4.1 Text Encoders
文中用三种文本编码分别是:
BERT [11]:基于BERT(中文)在WikiZh上进行了预训练, GitHub地址:https://github.com/google-research/bert
ALBERT [20]:基于ALBERT(中文)的GitHub发布地址:https://github.com/google-research/albert
K-BERT [44].通过知识图实现语言表示,实现常识或领域知识的表达能力。5.https://github.com/autoliuweijie/K-BERT
4.2 Datasets
six popular Chinese NLP datasets in our experiments:
- Chnsenticorp. Chnsenticorp is a hotel review dataset; and it is a single sentence classification task. https://github.com/pengming617/bert_classification
- Shopping. Shopping is a online shopping review dataset; and it is a single sentence classification task. https://share.weiyun.com/5xxYiig
- BQ. BQ [4] is a large-scale Chinese natural language inference corpus.
- LCQMC. LCQMC [24] is a large-scale Chinese question matching corpus. The goal of this task is to determine if the two questions have a similar intent.
- OntoNotes. OntoNotes [37] comprises various genres of text (e.g., news, conversational telephone speech, weblogs...) with structural information and shallow semantics annotated. We employ OntoNotes as a NER benchmark dataset.
- Weibo. Weibo [34] is a widely-used NER benchmark dataset focused on Chinese social media from the popular Sina Weibo service. This dataset contains Weibo messages annotated for both name and nominal mentions.
4.5 Internal Semantic Information of Chinese Characters
哪种组件级的内部语义信息可以在改进汉字表示的挑战中获得更好的性能?为此和6种部件检测与识别算法进行了比较:
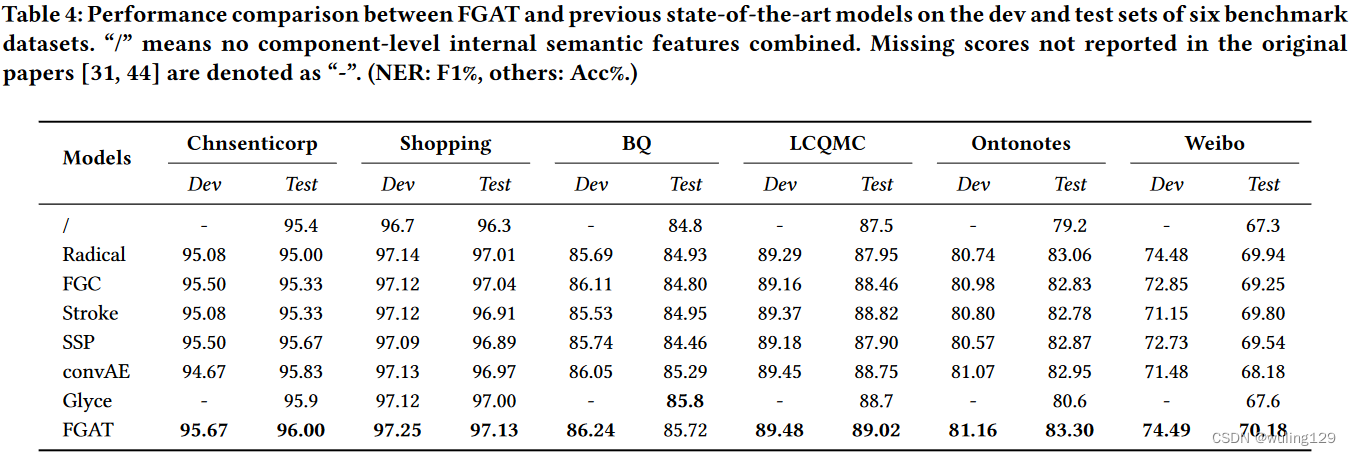
经过试验得出可能原因如下:(1)Radical, FGC, Stroke and SSP 将部首视为内部语义单元。这些模型通常只计算语义单元特征的未加权平均值,或者有时将权重设置为超参数并计算特征的加权平均值;因此,它们不能有效地区分部首的重要性并过滤有噪声的子特征信息。(2)convAE和Glyce从汉字字形图像中提取视觉特征。在详细分析Glyce提取的字形图像嵌入后,我们发现两个隐含语义相似的汉字在向量空间中没有更高的余弦相似度。原因可能是卷积运算保留了部首的方位信息,但破坏了部首为语义单元的语义独立性;部首的局部视觉特征不能很好地反映部首的语义特征。
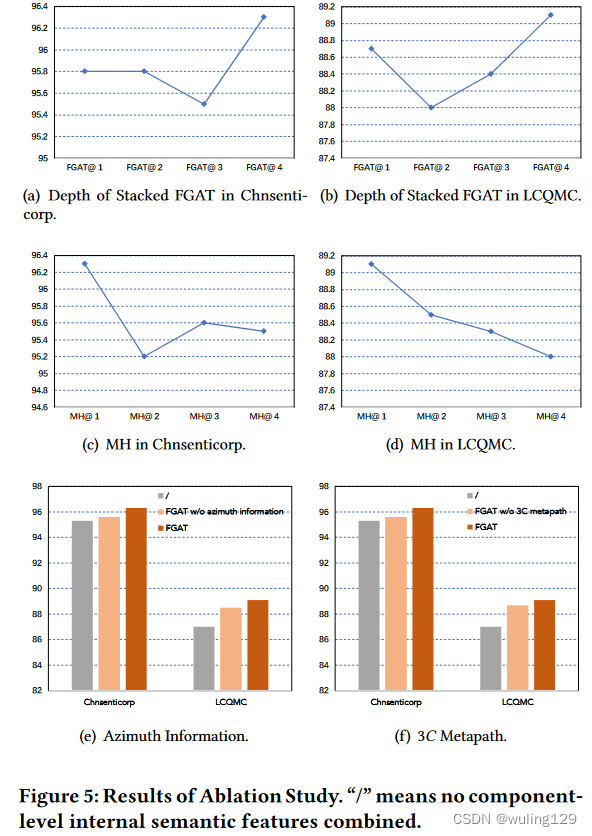
4.6 Ablation Study
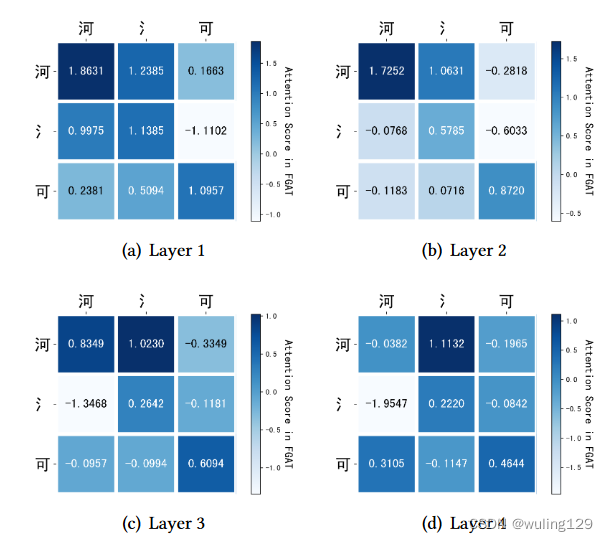
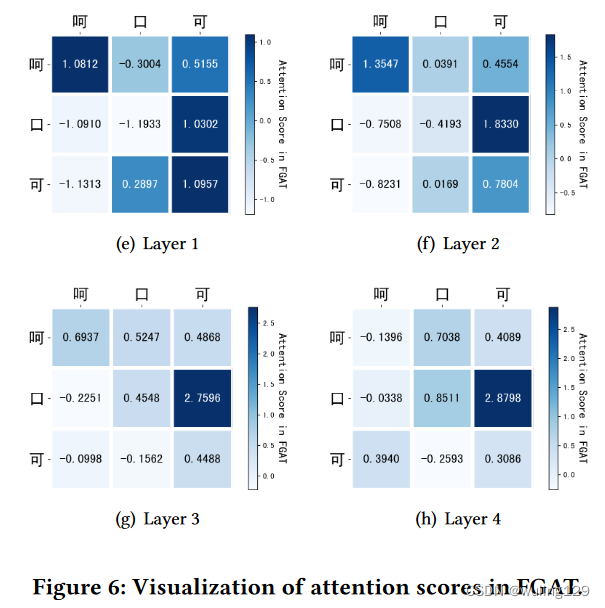
5 CASE STUDY

















 5005
5005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









