







 本文是正则表达式的简明教程,介绍了正则表达式的基本概念、图形化工具、语法,包括原义字符、转义字符、字符集合、量词、贪婪与非贪婪模式等,并提供了一些实例和图形化工具帮助理解。
本文是正则表达式的简明教程,介绍了正则表达式的基本概念、图形化工具、语法,包括原义字符、转义字符、字符集合、量词、贪婪与非贪婪模式等,并提供了一些实例和图形化工具帮助理解。
正则表达式(Regular Expression) 简明教程
1. 什么是正则表达式?
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
通俗的讲就是按照某种规则去匹配符合条件的字符串
正则表达式的语法一般如下(js),两条斜线中间是正则主体,这部分可以有很多字符组成;i部分是修饰符,i的意思表示忽略大小写
/^abc/i
正则定义了很多特殊意义的字符,有名词,量词,谓词等,后面逐一介绍
2. 图形化工具理解正则表达式
辅助理解正则表达式的在线工具: regexper
URL分组替换
/http:(\/\/.+\.jpg)/

正则表达式中括号用来分组,这个时候我们可以通过用$1来获取 group#1的内容

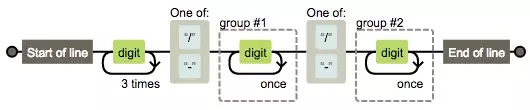
日期匹配与分组替换
/^\d{4}[/-]\d{2}[/-]\d{2}$/

正则分析如下:
- Start of line 是由
^生效的表示以此开头 - 对应结尾End of line 由
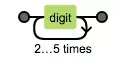
$生效表示以此结尾 - 接着看digit 由
\d生效表示数字 - 3times 由
{4}生效表示重复4次,digit 传过一次,3times表示再来三次循环,共4次,后面的once同理。 - 接下来,是 one of 在手机正则里面已经出现了。表示什么都行。只要符合这两个都让通过。
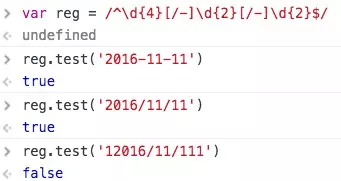
利用此正则,我们可以验证日期的合法性
结合URL分组替换所用到的分组特性,我们可以轻松写出日期格式化的方法
改造下这个正则
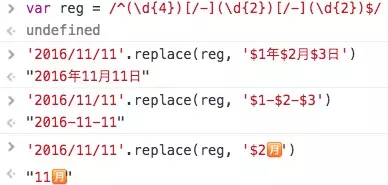
/^(\d{4})[/-](\d{2})[/-](\d{2})$/

拿到 group#1 #2 #3 的内容,对应 $1 $2 $3
3. 正则表达式语法
3.1 原义字符
没有特殊意义的字符都是简单字符,简单字符就代表自身,绝大部分字符都是简单字符,举个例子
/abc/ // 匹配 abc
/123/ // 匹配 123
/-_-/ // 匹配 -_-
/海镜/ // 匹配 海镜
3.2 转义字符
\是转义字符,其后面的字符会代表不同的意思。它将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,n”匹配字符“n”。“\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。
转义字符主要有三个作用:
- 为了匹配不方便显示的特殊字符,比如换行
\n,tab符号\t等- 正则中预先定义了一些代表特殊意义的字符,比如
\w等- 在正则中某些字符有特殊含义(比如下面说到的),转义字符可以让其显示自身的含义
常用转义字符列表:
| 转义字符 | 描述 |
|---|---|
| \n | 匹配换行符。等价于 \x0a 和 \cJ。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \r | 匹配回车符。等价于 \x0d 和 \cM。 |
| \r\n | 匹配一个“回车+换行”的组合 |
| 在Windows里面,\r\n是文本行结束标签,\r\n\r\n匹配的是两行之间的空白行 | |
| 在Unix\Linux里面,\n是文本行结束标签,\n\n匹配的就是两行之间的空白行 | |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配制表符,也就是tab键。等价于 \x09 和 \cI。 |
| \v | 匹配垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配任何一个字母或者数字或者下划线 |
| \W | 匹配任何一个字母或者数字或者下划线以外的字符 |
| \d | 匹配数字字符,0~9 |
| \D | 匹配非数字字符 |
| \b | 匹配单词的边界 |
| \B | 匹配非单词边界 |
| \ | 匹配\本身 |
| \0 | 前缀\0匹配八进制,例如\011匹配ASCII字符9(制表符) |
| \x | 前缀\x匹配十六进制,例如\x0A对应ASCII字符10(换行符) |
| \u002B | 002B是4位16进制数字,代表对应的字符 |
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
举个栗子:
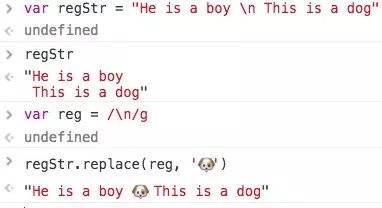
3.3 字符集合[]
有时我们需要匹配一类字符,字符集可以实现这个功能,字符集的语法用[]分隔。
这个符号用来表示逻辑关系或,比如[abc]表示a或者b或c.[-.]表示符号-或者.号(注意这里,在[]中的.号代表的就是这个符号,但是如果在其外面,表示个匹配所有。 所以如果不在[]之中,想要匹配’.’,就要通过转意符号.)
这里还是要说明,在[]中,特殊字符不需要转义,可以直接使用,比如[.()],但是在外面,是需要转义的( .等
例如:匹配a或b或c
[abc]
如果要表示字符很多,可以使用-表示一个范围内的字符。如果只是想匹配-在范围类最后加-即可。
下面两种表示效果一致
[0123456789]
[0-9]
在前面添加^,可表示非的意思。
下面的代码能够匹配a``b``c之外的任意字符,包括空格
[^abc]
3.4 内置字符集
常用为了方便书写
| 字符 | 等价类 | 含义 |
|---|---|---|
. | [^\n\r] | 除了回车符和换行符之外的所有字符 |
\d | [0-9] | 数字字符 |
\D | [^0-9] | 非数字字符 |
\s | [\f\n\r\t\v] | 空白符 |
\S | [^\f\n\r\t\v] | 非空白符 |
\w | [a-zA-Z0-9_] | 单词字符(字母、数字、下划线) |
\W | [^a-zA-Z0-9_] | 非单词字符 |
有了这些内置字符集,写一些正则就很方便了,比如我们希望匹配一个 ab+数字+任意字符 的字符串,就可以这样写了 /ab\d./
3.5 量词
如果需要匹配多次某个字符,正则也提供了量词的功能,正则中的量词有多个,如?、+、*、{n}、{m,n}、{m,}
| 字符 | 含义 |
|---|---|
| {n} | 出现n次,比如a{2},匹配aa |
| {m,n} | 至少出现m次但不超过n次,优先匹配n次。比如a{1,3},可以匹配aaa、aa、a |
| {n,} | 至少出现n次(+的升级版)。匹配n-∞次,优先匹配∞次,比如a{1,},可以匹配aaaa... |
| {0,n} | 至多出现n次(其实就是{m,n} 方便记忆而已) |
| ? | 出现0次或1次,优先匹配1次,相当于{0,1} |
| + | 出现至少1次及以上。匹配1-n次,优先匹配n次,相当于{1,} |
| * | 出现任意次。匹配0-n次,优先匹配n次,相当于{0,} |
3.6 贪婪与非贪婪
贪婪模式
正则表达式 默认匹配 贪婪模式,也就是说匹配尽可能多的情况。
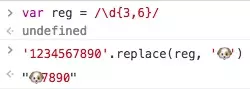
例1:
/\d{3,6}/
例2:
a{1, 3} // 匹配字符串'aaa'的话,会匹配aaa而不是a
贪婪模式下,匹配的了最多的情况。
非贪婪模式
与贪婪模式相对应的就是非贪婪模式,也就是说匹配尽可能少的情况。
在量词后面加?,就可开启非贪婪模式
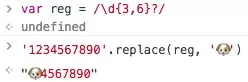
例1:
/\d{3,6}/
例2:
a{1, 3}? // 匹配字符串'aaa'的话,会匹配a而不是aaa
如果想知道,正则表达式是如何匹配量词的,请看 进阶正则表达式 文中有介绍,正则是如何回溯的。
3.7 字符边界
有时我们会有边界的匹配要求,比如以xxx开头,以xxx结尾
| 字符 | 含义 |
|---|---|
^ | 以xxx开头 |
$ | 以xxx结尾 |
\b | 单词边界,指[a-zA-Z_0-9]之外的字符 |
\B | 非单词边界 |
^在[]外表示匹配开头的意思
^abc // 可以匹配abc,但是不能匹配aabc
$表示匹配结尾的意思
abc$ // 可以匹配abc,但是不能匹配abcc
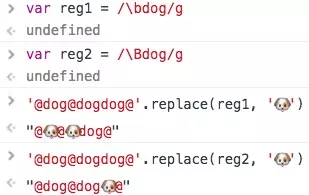
\b表示单词的边界
abc\b // 可以匹配 abc ,但是不能匹配 abcc
演示下\b与\B 的区别:
3.8 选择表达式
有时我们想匹配x或者y,如果x和y是单个字符,可以使用字符集,[abc]可以匹配a或b或c,如果x和y是多个字符,字符集就无能为力了,此时就要用到分组
正则中用|来表示分组,a|b表示匹配a或者b的意思
123|456|789 // 匹配 123 或 456 或 789
3.9 分组与引用
分组
分组,又称为子表达式,是正则中非常强大的一个功能,可以让上面提到的量词作用于一组字符,而非单个字符,分组的语法是圆括号包裹(xxx)
举个栗子:
不分组 /abc{2}/
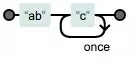
量词仅作用到最后的c
分组 /(abc){2}/
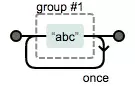
(abc){2} // 匹配abcabc
分组不能放在[]中,分组中还可以使用选择表达式
(123|456){2} // 匹配 123123、456456、123456、456123
回溯引用
当一个正则表达式被分组后,每个分组默认都是捕获的,会自动被赋予一个组号,从左到右分别是 $1 $2…
在分组的(后面添加?:可以让分组变为非捕获分组,非捕获分组可以提高性能和简化逻辑。
'123'.match(/(?:123)/) // 返回 ['123']
'123'.match(/(123)/) // 返回 ['123', '123']
举个栗子:
/^(\d{4})[/-](\d{2})[/-](\d{2})$/
轻松拿到 group#1 #2 #3 的内容,对应 $1 $2 $3
如果在反向引用中不想捕获应该如何操作? 加上 ?:即可
/^(?:\d{4})[/-](\d{2})[/-](\d{2})$/
和分组相关的另一个概念是引用,比如在匹配html标签时,通常希望<xxx></xxx>后面的xxx能够和前面保持一致
引用的语法是\数字,数字代表引用前面第几个捕获分组,注意非捕获分组不能被引用
<([a-z]+)><\/\1> // 可以匹配 `<span></span>` 或 `<div></div>`等
回溯引用允许正则表达式引用前面的匹配结果
\1表示第一个子表达式,\2表示第二个子表达式,如此类推
\0在很多实现里面,可以用来表示整个正则表达式
某些实现里面,回溯引用用$来代替\
3.10 预搜索
如果你想匹配xxx前不能是yyy,或者xxx后不能是yyy,那就要用到预搜索
js只支持正向预搜索,也就是xxx后面必须是yyy,或者xxx后面不能是yyy
1(?=2) // 可以匹配12,不能匹配22
1(?!2) // 可以匹配22,不能匹配12
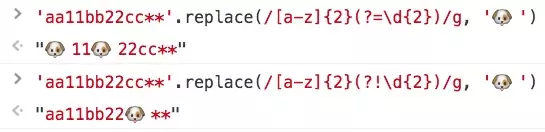
题目:如何将’123456’转成货币带逗号的。‘123,456’。这个是很常规格式化金额的需求。
如果在没有学习正则之前,我的思路是:
- 字符串转数组
- 反转数组
- 每隔三个添加个逗号
- 添加完了反转数组
- 数组转字符串
好累~~~
今天学习了正则,可以一步到位 '123456789'.replace(/(\d)(?=(?:\d{3})+$)/g, '$1,')
3.11 修饰符
修饰符与其他语法特殊,字面方法声名的时候放到/后,构造函数声明的时候,作为第二个参数传入。整个正则表达式可以理解为正则表达式规则字符串+修饰符。
/xxx/gi // 最后面的g和i就是两个修饰符
-
g:global 执行一个全局匹配(正则遇到第一个匹配的字符就会结束,加上全局修复符,可以让其匹配到结束) -
i:ignore case执行一个不区分大小写的匹配(正则默认是区分大小写的,i可以忽略大小写) -
m:multiple lines多行匹配(正则默认情况下,^和 只 能 匹 配 字 符 串 的 开 始 和 结 尾 , m 修 饰 符 可 以 让 和 只能匹配字符串的开始和结尾,m修饰符可以让^和 只能匹配字符串的开始和结尾,m修饰符可以让和匹配行首和行尾)
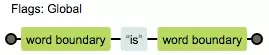
修饰符可以一起用 const reg =/\bis\b/gim
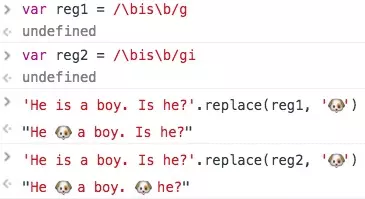
有g和没有g的区别
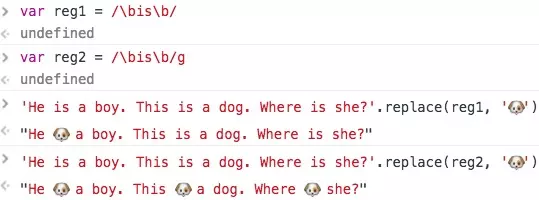
没有g只替换了第一个,有g 所有的都换了
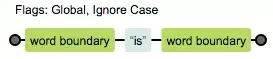
有i和没有i的区别
有i忽略大小写,没有i严格区分大小写
有m和没有m的区别
/jing$/ // 能够匹配 'yanhaijing,不能匹配 'yanhaijing\n'
/jing$/m // 能够匹配 'yanhaijing, 能够匹配 'yanhaijing\n'
/^jing/ // 能够匹配 'jing',不能匹配 '\njing'
/^jing/m // 能够匹配 'jing',能够匹配 '\njing'

















 130
130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









