




 本文深入探讨了并发系统的不同模型,包括并行工作者模型、流水线模型和函数式并行模型。并行工作者模型允许任务在多个线程间独立执行,而流水线模型则强调线程间的协作,每个线程负责任务的一部分。文章还分析了这些模型的优势和劣势。
本文深入探讨了并发系统的不同模型,包括并行工作者模型、流水线模型和函数式并行模型。并行工作者模型允许任务在多个线程间独立执行,而流水线模型则强调线程间的协作,每个线程负责任务的一部分。文章还分析了这些模型的优势和劣势。
并发系统可以使用不同的并发模型实现,不同的并发模型的线程通过不同的合作方式去处理任务
共享状态和分离状态(shared state and separate state)
- 共享状态:所有的线程分享某个状态,这个状态可能是一个object,共享状态可能碰到的问题有死锁,竞态等。
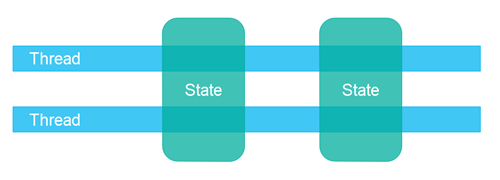
- 非共享状态:不同的线程之间不会有共享的数据,当不同的线程需要交流时,他们通过分享不可变的对象,或copy出一份数据给其他线程使用的方式,来避免并发问题。
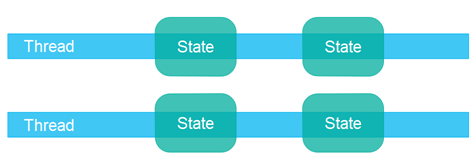
并行工作者模型
简单来说,不同的任务分配给不同的线程,这就是并行工作者模型。Java多线程大多数使用的是这个模型。
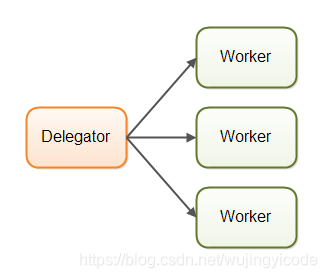
Delegator便是任务的分配者,Worker便是工作线程。Delegator将任务分配给Worker。
如果拿汽车厂作比喻,那么每一个Worker都在生产不同的汽车。
并行工作者模型的优势
简单易懂,当你想要增加并发量时,增加Worker即可。
并行工作者模型的劣势
- 共享状态下较为复杂:当不同的线程之间有共享数据时,比如:数据库,或是某些连接池,线程之间必须保证他们的写操作对其他线程可见,以免发生类似:死锁,竞态的情况。
- 无状态工作者:每次操作共享数据时,都必须再次读取,这样才能保证数据时最新的,这可能会降低程序的效率。工作者不保存状态,而是当需要的时候再去读取它,这就叫做无状态工作者。
- 任务被执行的先后顺序无法被保证:我们并不能保证,到底哪个任务先被执行。
流水线模型
与并行工作者模型相反,流水线模型由多个Worker共同协作,完成一个任务。
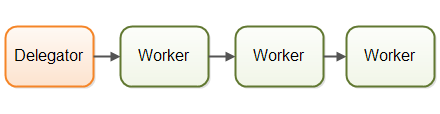
最常见的流水线模型是非阻塞IO。
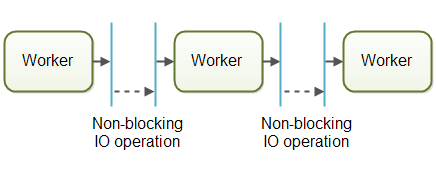
某个Worker进行任务时,需要进行IO操作,这时候CUP并不会等待IO完成再继续执行下去,而是让这个Worker放弃这个任务的执行权,等IO完成时,IO的结果会交给另一个Worker,让任务继续进行。
流水线模型的优势
- 无共享状态:各个Worker之间没有共享状态,这让我们实现起来较为简单。
- 满状态Worker:因为与其他Worker没有共享状态,各个Worker可以存有自己线程的当前状态,当状态发生修改时再写入外部存储。这样可以提高运行效率。
- 更好的硬件支持。
- 任务顺序可控。
流水线模型的劣势
- 代码很难看:流水线模型执行一个任务的代码通常遍布在各个位置,我们难以分辨出到底哪些代码执行了某个任务。而且,有时Worker是通过CallBack(回调)来实现的,当回调多起来时,我们难以确定执行顺序。
函数式并行模型
这个模型目前不够成熟,我们不做讨论。
参考:http://tutorials.jenkov.com/java-concurrency/same-threading.html

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









