



读csv

主要函数:








大文件处理
读部分行
file = pd.read_csv('demo.csv', nrows=1000, usecols=['column1', 'column2', 'column3'])
读部分列
file = pd.read_csv('demo.csv', usecols=['column1', 'column2', 'column3'])
分块读取
reader = pd.read_csv('demo.csv', nrows=1000, usecols=['column1', 'column2', 'column3'], chunksize=1000, iterator=True)
for df in reader:
print(df)
reader = pd.read_csv('kuaishou.csv', chunksize=1000)
for df in reader:
print(df)上面两种方式是相同的。
reader = pd.read_csv('tmp.csv', iterator=True)
df = reader.get_chunk(1000)
写csv




可逆操作
对Series
方法一
写的时候:
ss.to_csv(‘somename.csv’, header=True,index=True) # 有header也有index
读的时候:
somename = pd.read_csv(“somename.csv”,header=0, index_col=0, squeeze=True)
# somename此时是Series,此时index保存下来
# 默认情况下
Series.to_csv(path=None, index=True, sep=’, ’, na_rep=”, float_format=None, header=False, index_label=None, mode=’w’, encoding=None, date_format=None, decimal=’.’)
pandas.read_csv(filepath_or_buffer, sep=’, ’, delimiter=None, header=’infer’, names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression=’infer’, thousands=None, decimal=b’.’, lineterminator=None, quotechar=’”’, quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=False, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False, as_recarray=False, compact_ints=False, use_unsigned=False, low_memory=True, buffer_lines=None, memory_map=False, float_precision=None)
方法二
将Series转化为DataFrame
pd.DataFrame(ss)然后按DataFrame保存
对DataFrame
写的时候:
df.to_csv(‘somename.csv’ , header=True,index=True) # 既有header又有index
读的时候:
somename = pd.read_csv(“somename.csv”, header=0,index_col=0)
如果不需要index和column名,直接转化为ndarray,再使用ndarray的保存和加载
a = ss.values
# 或a = df.values
numpy.save("filename.npy",a)
a = numpy.load("filename")写dict的顺序
pd.DataFrame([sorted(chunksize_df.columns.tolist()+["orb_match_ratio"])]).to_csv(success_save_ppath.as_posix(),header=False,index=False,mode="a", sep="\t")pd.DataFrame([pd.Series(match_dict).sort_index()]).to_csv(error_save_ppath.as_posix(), header=False, index=False, mode="a", sep="\t")finish_pd = finish_pd.reindex(columns=finish_pd.columns.sort_value())MultiIndex数据的保存与恢复
保存时一样
读取时不同
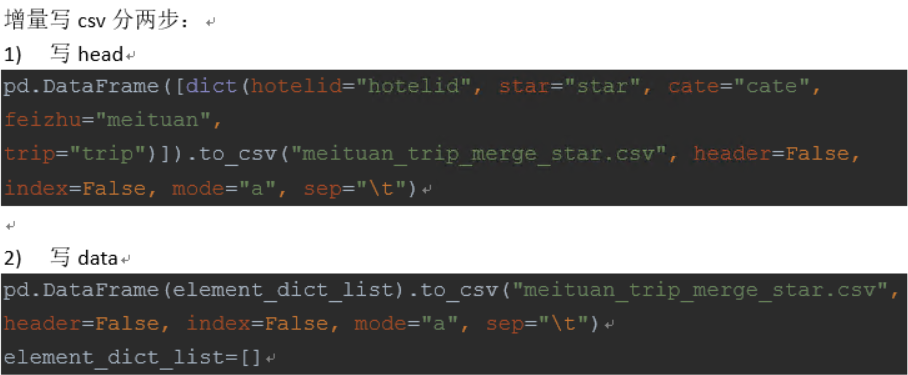
somename = pd.read_csv(“somename.csv”,header=[0,1], index_col=0)DataFrame增量写csv



















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











