







 本文详细介绍了Java 8中的TreeMap数据结构,包括其与SortedMap和NavigableMap接口的关系,TreeMap的内部实现,如红黑树特性、排序方式以及导航功能。此外,文章还提到了TreeMap的子映射操作和插入删除后的树调整。最后,文中概述了Java 8中其他重要数据结构的简要介绍。
本文详细介绍了Java 8中的TreeMap数据结构,包括其与SortedMap和NavigableMap接口的关系,TreeMap的内部实现,如红黑树特性、排序方式以及导航功能。此外,文章还提到了TreeMap的子映射操作和插入删除后的树调整。最后,文中概述了Java 8中其他重要数据结构的简要介绍。
前言
书接上文,上一篇对 LinkedHashMap 进行了介绍与分析,本篇将对 TreeMap 进行介绍与分析。
首先还是先来看一下 Map 的继承关系图:
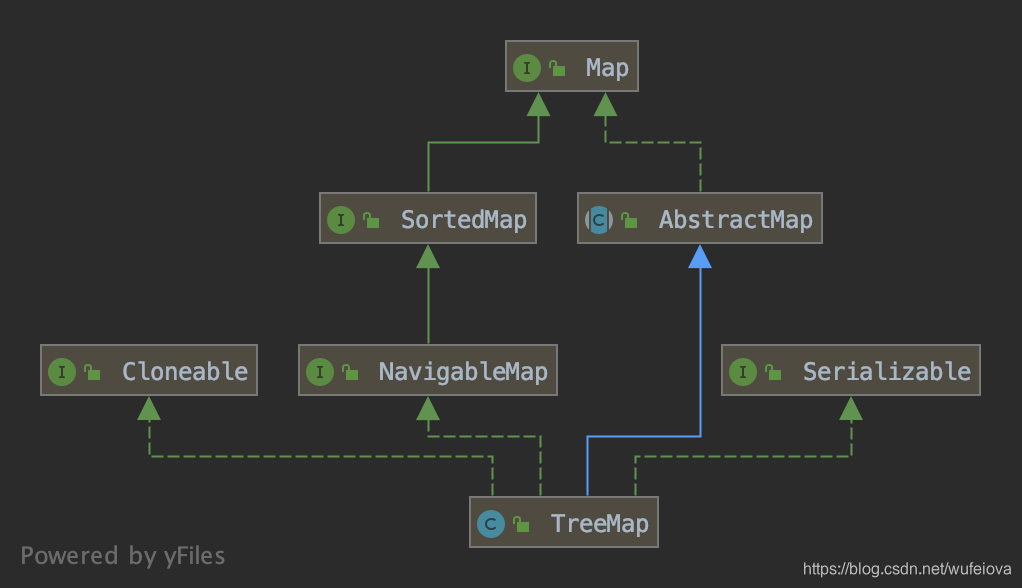
TreeMap 与其他 Map 最终实现类不同的部分是实现了 NavigableMap 接口,而 NavigableMap 继承于 SortedMap,所以在查看 TreeMap 之前还需要看一下这两个接口。
/**
* 为了防止与 LinkedHashMap 的自然顺序(插入顺序),访问顺序(修改顺序)的对于序的定义搞混,这里对于
* sorted 翻译成 <被排序>,sorted map 特指 <被排序 map> 。
*
* 一个还提供了一个它的键s是完整顺序的 {@link Map}。这个 map 是根据它的键s的 {@linkplain Comparable
* natural ordering},或者一个通常是在有序 map 建立时提供的 {@link Comparator} 来 <被排序> 的。这个顺
* 序在迭代涵盖这个 <被排序 map> 的 collection 视图s的时候会被影响(由 {@code entrySet}, {@code
* keySet} 和 {@code values} 方法返回的)。提供了几个额外的操作来利用顺序。(这个接口是 map 对于 {@link
* SortedSet} 的模拟。)
*
* 所有插入到一个 <被排序 map> 中的键s必须实现 {@code Comparable} 接口(或者被一个指定的 comparator 接
* 收)。还有,所有这样的键s必须是手动比较的:对于任何键 {@code k1} 和键 {@code k2},在 <被排序 map> 中
* {@code k1.compareTo(k2)}(或者 {@code comparator.compare(k1, k2)})必须不抛出一个 {@code
* ClassCastException}。企图违反这个约定将导致侵犯方法或者构造器调用而抛出一个 {@code
* ClassCastException}。
*
* 注意如果这个 <被排序 map> 要想正确地实现 {@code Map} 接口,被一个 <被排序 map> 维护的顺序(不管是不是
* 提供了一个明确的 comparator)必须是与 equals 一致的。(查看 {@code Comparable} 或者 {@code
* Comparator} 接口来了解与 equals 一致的明确定义。)必须这样因为 {@code Map} 接口是依据 {@code
* equals} 操作建立起来的,但是一个 <被排序 map> 完成所有 key 比较的方式是使用它的 {@code compareTo}
* (或者 {@code compare}) 方法,所以通过这个方法,两个键被视为 equal 的键是,从 <被排序 map> 的立场来
* 看,equal 的。就算一个 Tree Map 的排序与 equals 不一致,它的行为也是被良好定义的;它只是没有遵守
* {@code Map} 接口的一般规约。
*
* 所以一般目的的 <被排序 map> 实现类应该提供四个“基本”构造器。不可能从始至终强制这种建议,因为需要的构造器
* 不能被接口定义。对所有 <被排序 map> 的实现类期望的“标准”构造器是:
* <ol>
* <li>一个空的(没有参数的)构造器,它建立一个依照它的键的自然顺序 <被排序> 的空的 <被排序 map> </li>
* <li>一个带有 {@code Comparator} 类型的单参构造器,它建立一个依照指定 comparator 顺序 <被排序> 的
* 空的 <被排序 map>。</li>
* <li>一个带有 {@code Map} 类型的单参构造器,它建立一个与参数带有同样键值映射的新 map,依照它的键的自
* 然顺序 <被排序>。</li>
* <li>一个带有 {@code SortedMap} 类型的单参构造器,它建立一个与参数带有同样键值映射的新 <被排序
* map>,依照参数的顺序 <被排序>。</li>
* </ol>
*
* 注意:多个方法返回带有严格键范围的字映射。这种范围是<半开放>的,意味着,它们包含它们的低端点(闭区间)但是
* 不包含它们的高端点(开区间)。如果你需要一个<闭范围>(包含两个端点),而且它们的类型允许 计算一个给定键
* 的后继内容,仅仅需要从 {@code lowEndpoint} 到 {@code successor(highEndpoint)} 的字范围。比如,假
* 设 {@code m} 是一个键s为 String 的 map。以下惯用语包含一个包含 {@code m} 中所有键s在 {@code low}
* 到 {@code high} 之间的键值映射,(包含):<pre>
* SortedMap<String, V> sub = m.subMap(low, high+"\0");</pre>
*
* 一种相似的技术可以被用来生成一个<开范围>(没有一个端点是闭区间)。以下惯用语包含一个 {@code m} 中所有键s
* 在 {@code low} 到 {@code high} 之间的键值映射,(不包含):<pre>
* SortedMap<String, V> sub = m.subMap(low+"\0", high);</pre>
*/
public interface SortedMap<K,V> extends Map<K,V> {
/**
* 返回当前 map 用来为键排序的 comparator,如果当前 map 使用它的键的 {@linkplain Comparable
* natural ordering} 则返回 null。
*/
Comparator<? super K> comparator();
/**
* 返回当前 map 键s从{@code fromKey}, (包含),到 {@code toKey}, (不包含)的部分的一个视图。
* (如果 {@code fromKey} 和 {@code toKey} 是 equal),返回的 map 是空的。)返沪的 map 是由当前
* map 支持的,反之亦然。返回的 map 支持当前 map 支持的所有可选的操作。
*
* 视图向返回的 map 中插入一个超出它范围的键将抛出一个 {@code IllegalArgumentException}。
*/
SortedMap<K,V> subMap(K fromKey, K toKey);
/**
* 返回键s小于 {@code toKey} 的当前 map 的部分的一个视图。返回的 map 是被当前 map 支持的,所以对于
* 返回 map 的修改会影响到当前 map ,反之依然。返回的 map 支持当前 map 支持的所有可选的操作。
*
* 视图向返回的 map 中插入一个超出它范围的键将抛出一个 {@code IllegalArgumentException}。
*/
SortedMap<K,V> headMap(K toKey);
/**
* 返回键s大于等于 {@code fromKey} 的当前 map 的部分的一个视图。返回的 map 是被当前 map 支持的,所
* 以对于返回 map 的修改会影响到当前 map ,反之依然。返回的 map 支持当前 map 支持的所有可选的操作。
*
* 视图向返回的 map 中插入一个超出它范围的键将抛出一个 {@code IllegalArgumentException}。
*/
SortedMap<K,V> tailMap(K fromKey);
/**
* 返回当前 map 中第一个(最低的)键。
*/
K firstKey();
/**
* 返回当前 map 中最后一个(最高的)键。
*/
K lastKey();
/**
* 返回一个当前 map 中包含的键s的 {@link Set} 视图。
*
* 这个 set 的迭代器以升序返回键s。这个 set 是被这个 map 支持的,所以对于这个 map 的修改会影响到这个
* set,反之亦然。如果这个 map 在涵盖 set 的迭代操作过程中被修改了(除非通过迭代器自己的 {@code
* remove} 操作),迭代操作的结果是不可定义的。这个 set 支持元素移除,就是移除这个 map 中的对应映射,
* 通过 {@code Iterator.remove}, {@code Set.remove}, {@code removeAll}, {@code
* retainAll}, 和 {@code clear} 操作。它不支持 {@code add} 或者 {@code addAll} 操作。
*/
Set<K> keySet();
/**
* 返回一个当前 map 中包含的值s的 {@link Collection} 视图。
*
* 这个 collection 的迭代器以升序返回键s。这个 collection 是被这个 map 支持的,所以对于这个 map 的
* 修改会影响到这个 collection,反之亦然。如果这个 map 在涵盖 collection 的迭代操作过程中被修改了
* (除非通过迭代器自己的 {@code remove} 操作),迭代操作的结果是不可定义的。这个 collection 支持元
* 素移除,就是移除这个 map 中的对应映射,通过 {@code Iterator.remove}, {@code Set.remove},
* {@code removeAll}, {@code retainAll}, 和 {@code clear} 操作。它不支持 {@code add} 或者
* {@code addAll} 操作。
*/
Collection<V> values();
/**
* 返回一个当前 map 中包含的s的 {@link Set} 视图。
*
* 这个 set 的迭代器以升序返回键s。这个 set 是被这个 map 支持的,所以对于这个 map 的修改会影响到这个
* set,反之亦然。如果这个 map 在涵盖 set 的迭代操作过程中被修改了(除非通过迭代器自己的 {@code
* remove} 操作),迭代操作的结果是不可定义的。这个 set 支持元素移除,就是移除这个 map 中的对应映射,
* 通过 {@code Iterator.remove}, {@code Set.remove}, {@code removeAll}, {@code
* retainAll}, 和 {@code clear} 操作。它不支持 {@code add} 或者 {@code addAll} 操作。
*/
Set<Map.Entry<K, V>> entrySet();
}
通过 SortedMap 的源码可以看到,与之前 TreeSet 篇中 TreeSet 类的上层接口之一 SortedSet 接口如出一辙,只是这里头尾范围方法的返回对象从 SortedSet 变成了 SortedMap,首末方法的返回对象从范型对象变成了 map 键范型对象,同时 SortedMap 接口还新增了返回它三种键/值组合内部结构的视图方法。
同时由于 Map 不属于集合类型数据结构(Collection),所以没有定义 spliterator 方法(不过应该是在实现类中通过适配器模式实现了迭代操作,后续再看。)
下面再来看 NavigableMap 接口的源码
/**
* 一个由指定搜索目标返回最近匹配导航方法的扩展 {@link SortedMap}。方法 {@code lowerEntry}, {@code
* floorEntry}, {@code ceilingEntry}, 和 {@code higherEntry} 返回与键s分别小于,小于等于,大于等于
* 和大于一个指定键的 {@code Map.Entry} 对象,如果没有这种键,则返回 {@code null}。类似的,方法 {@code
* lowerKey}, {@code floorKey}, {@code ceilingKey}, 和 {@code higherKey} 只返回相关的键s。所有这
* 些方法餧设计用来定位,而不是横穿条目s。
*
* 一个 {@code NavigableMap} 可以以键的升序或者降序被访问和横穿。{@code descendingMap} 方法返回一个所
* 有相关与有向方法的相反的 map 视图。升序操作的性能和视图看上去要比降序的稍微快一些。方法 {@code subMap},
* {@code headMap},和 {@code tailMap} 与名称相似的 {@code SortedMap} 方法s的区别在于接受额外的描述
* 无论是更低还是更高的边界是否是包含的还是不包含的的参数。任何 {@code NavigableMap} 的子映射s必须实现
* {@code NavigableMap} 接口。
*
* 这个接口额外定义了返回 and/or 移除最近和最大的映射s 的方法 {@code firstEntry}, {@code
* pollFirstEntry}, {@code lastEntry}, 和 {@code pollLastEntry} ,如果有任何一个存在的话,否则返回
* {@code null}。
*
* 条目返回方法的实现s被期望返回代表了当时被生产的映射s快照s的 {@code Map.Entry} 对s,并且因此通常不支持
* 可选择的 {@code Entry.setValue} 方法。注意但是它可以使用方法 {@code put} 来修改关联 map 的映射。
*
* 方法
* {@link #subMap(Object, Object) subMap(K, K)},
* {@link #headMap(Object) headMap(K)}, 和
* {@link #tailMap(Object) tailMap(K)}
* 被特定用来返回 {@code SortedMap} 来允许 {@code SortedMap} 存在的实现类s可以改装来实现 {@code
* NavigableMap},但是这个接口的扩展s和实现s是鼓励重写这些方法来返回 {@code NavigableMap} 的。相似地,
* {@link #keySet()} 可以被重写来返回 {@code NavigableSet}。
*/
public interface NavigableMap<K,V> extends SortedMap<K,V> {
/**
* 返回一个严格小于指定键的最大键相关的键值映射,或者如果没有这样的键,则返回 {@code null}。
*/
Map.Entry<K,V> lowerEntry(K key);
/**
* 返回严格小于指定键的最大键,或者如果没有这样的键,则返回 {@code null}。
*/
K lowerKey(K key);
/**
* 返回一个小于等于指定键的最大键相关的键值映射,或者如果没有这样的键,则返回 {@code null}。
*/
Map.Entry<K,V> floorEntry(K key);
/**
* 返回严格小于等于指定键的最大键,或者如果没有这样的键,则返回 {@code null}。
*/
K floorKey(K key);
/**
* 返回一个大于等于指定键的最小键相关的键值映射,或者如果没有这样的键,则返回 {@code null}。
*/
Map.Entry<K,V> ceilingEntry(K key);
/**
* 返回严格大于等于指定键的最小键,或者如果没有这样的键,则返回 {@code null}。
*/
K ceilingKey(K key);
/**
* 返回一个严格大于指定键的最小键相关的键值映射,或者如果没有这样的键,则返回 {@code null}。
*/
Map.Entry<K,V> higherEntry(K key);
/**
* 返回严格大于等于指定键的最小键,或者如果没有这样的键,则返回 {@code null}。
*/
K higherKey(K key);
/**
* 返回一个与当前 map 中最小键相关的键值映射,或者如果没有这样的键,则返回 {@code null}。
*/
Map.Entry<K,V> firstEntry();
/**
* 返回一个与当前 map 中最大键相关的键值映射,或者如果没有这样的键,则返回 {@code null}。
*/
Map.Entry<K,V> lastEntry();
/**
* 移除并返回一个与当前 map 中最小键相关的键值映射,或者如果没有这样的键,则返回 {@code null}。
*/
Map.Entry<K,V> pollFirstEntry();
/**
* 移除并返回一个与当前 map 中最大键相关的键值映射,或者如果没有这样的键,则返回 {@code null}。
*/
Map.Entry<K,V> pollLastEntry();
/**
* 返回一个包含当前 map 中的映射s的反向视图。降序 map 被当前 map 支持,所以对于这个 map 的修改会影响
* 到降序 map,反之亦然。如果无论哪个 map 在涵盖一个无论哪个 map 的 collection 视图迭代操作过程中被
* 修改了(除了通过迭代器自己的 {@code remove} 操作),迭代操作的结果是不可定义的。
*
* 返回的 map 有一个的顺序等同于
* <tt>{@link Collections#reverseOrder(Comparator) Collections.reverseOrder}
* (comparator())</tt>
* 表达式 {@code m.descendingMap().descendingMap()} 返回一个与 {@code m} 本质上相同的 {@code
* m}。
*/
NavigableMap<K,V> descendingMap();
/**
* 返回一个当前 map 包含的键s的 {@link NavigableSet} 视图。这个 set 的迭代器以升序返回键s。这个
* set 被这个 map 支持,所以对这个 map 的修改会影响到这个 set,反之亦然。如果这个 map 在涵盖这个 set
* 的迭代操作过程中被修改了(除了通过迭代器自己的 {@code remove} 操作),迭代操作的结果是不可定义的。
* 这个 set 支持元素移除,就是从这个 map 中移除了对应的映射,通过 via the {@code
* Iterator.remove}, {@code Set.remove}, {@code removeAll}, {@code retainAll}, 和 {@code
* clear} 操作s。他不支持 {@code add} 或者 {@code addAll} 操作。
*/
NavigableSet<K> navigableKeySet();
/**
* 返回一个当前 map 中包含的键s相反顺序的 {@link NavigableSet} 视图。这个 set 的迭代器以降序返回键
* s。这个 set 被这个 map 支持,所以对这个 map 的修改会影响到这个 set,反之亦然。如果这个 map 在涵盖
* 这个 set 的迭代操作过程中被修改了(除了通过迭代器自己的 {@code remove} 操作),迭代操作的结果是不
* 可定义的。这个 set 支持元素移除,就是从这个 map 中移除了对应的映射,通过 via the {@code
* Iterator.remove}, {@code Set.remove}, {@code removeAll}, {@code retainAll}, 和 {@code
* clear} 操作s。他不支持 {@code add} 或者 {@code addAll} 操作。
*/
NavigableSet<K> descendingKeySet();
/**
* 返回一个当前 map 的键s范围从 {@code fromKey} 到 {@code toKey} 的部分的视图。如果 {@code
* fromKey} 和 {@code toKey} 是 equal 的,返回的 map 是空除非 {@code fromInclusive} 和
* {@code toInclusive} 都为 true。返回的 map 是被当前 map 支持的,所以对返回的 map 的修改会影响到
* 当前 map,反之亦然。返回的 map 支持所有当前 map 支持的可选 map 操作。
*
* 一个试图插入超出它的范围的一个键的操作将使返回的 map 抛出一个 {@code
* IllegalArgumentException},或者构建一个端点s在它的范围之外的子映射。
*/
NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive);
/**
* 返回一个当前 map 的键s小于(或等于,如果 {@code inclusive} 是 true 的化){@code toKey} 的部分
* 的视图。返回的 map 被当前 map 支持,所以对于返回的 map 的修改会影响到当前 map,反之亦然。返回的
* map 支持所有当前 map 支持的可选的 map 操作。
*
* 一个试图插入超出它的范围的一个键的操作将使返回的 map 抛出一个 {@code
* IllegalArgumentException}。
*/
NavigableMap<K,V> headMap(K toKey, boolean inclusive);
/**
* 返回一个当前 map 的键s小于(或等于,如果 {@code inclusive} 是 true 的化){@code fromKey} 的部
* 分的视图。返回的 map 被当前 map 支持,所以对于返回的 map 的修改会影响到当前 map,反之亦然。返回的
* map 支持所有当前 map 支持的可选的 map 操作。
*
* 一个试图插入超出它的范围的一个键的操作将使返回的 map 抛出一个 {@code
* IllegalArgumentException}。
*/
NavigableMap<K,V> tailMap(K fromKey, boolean inclusive);
/**
* 文档继承
*
* 等同于 {@code subMap(fromKey, true, toKey, false)}。
*/
SortedMap<K,V> subMap(K fromKey, K toKey);
/**
* 文档继承
*
* 等同于 {@code headMap(toKey, false)}。
*/
SortedMap<K,V> headMap(K toKey);
/**
* 文档继承
*
* 等同于 {@code tailMap(fromKey, true)}。
*/
SortedMap<K,V> tailMap(K fromKey);
}
通过 NavigableMap 的源码可以看到,与之前 TreeSet 篇中 TreeSet 类的上层接口之一 NavigableSet 接口如出一辙,只是针对键与映射(条目)定义了两套范围操作方法。
同时由于 Map 不属于集合类型数据结构(Collection),所以没有定义 iterator 方法(不过应该是在实现类中通过适配器模式实现了迭代操作,后续再看。)
了解了这两个接口之后就可以开始查看 TreeMap 的源码了
/**
* 一个基于 {@link NavigableMap} 的红黑树实现类。这个 map 是根据它的键s的 {@linkplain Comparable
* natural ordering},或者一个通常是在有序 map 建立时提供的 {@link Comparator} 来 <被排序> 的,主
* 要看哪个构造器被使用了。
*
* 这个实现类保证了对于 {@code containsKey}, {@code get}, {@code put} 和 {@code remove}
* 操作s的 log(n) 时间成本。算法适用于那些在 Cormen,Leiserson 和 Rivest 的 算法介绍。
*
* 注意被一个 tree map 维护的顺序,就像任何 <被排序 map>,并且不管有没有提供明确地 comparator,如果当
* 前 <被排序 map> 必须和 {@code equals} 等价。必须这样因为 {@code Map} 接口是依据 {@code
* equals} 操作建立起来的,但是一个 <被排序 map> 完成所有 key 比较的方式是使用它的 {@code
* compareTo} (或者 {@code compare}) 方法,所以通过这个方法,两个键被视为 equal 的键是,从 <被排序
* map> 的立场来看,equal 的。就算一个它的顺序与 equals 不一致,它的行为也是被良好定义的;它只是没有遵
* 守 {@code Map} 接口的一般规约。
*
* 注意这个实现类不是线程安全的。如果多个线程并行访问一个 map,并且至少其中一个线程结构性地改变了这个
* map,它必须从外部实现线程安全。(一个结构性改变是任何添加或者删除一个或多个映射s的操作,仅仅改变一个已
* 经存在的键的关联值不是一个结构性改变。)这通常是通过在一些实现了线程安全的对象中自然封装这个 map 来实现
* 的。
*
* 如果没有这样的对象存在,这个 map 应该使用
* {@link Collections#synchronizedSortedMap Collections.synchronizedSortedMap} 方法封装。这
* 最好在创建的时候被完成,来防止任何对这个 map 的非线程安全的访问:<pre>
* SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));</pre>
*
* 所有这个类的 “collection 视图方法s” 返回的 collections 的 {@code iterator} 方法返回的迭代器都
* 是 fail-fast 的,如果这个 map 在迭代器创建出来后的任何时间点被结构性更改,以任何除了通过迭代器自己的
* {@code remove} 方法之外的方式,这个迭代器将会抛出一个 {@link ConcurrentModificationException}
* 异常。因此,对于并发修改,迭代器失败的快速与干净,而不是在未来某个不确定的时间点冒险做任何不确定的行为。
*
* 注意一个迭代器的 fail-fast 行为不能提供像它所描述的那样的保证,一般来说,不可能对于不同步的并发操作做
* 任何硬性的保证。基于最好性能的基础,fail-fast 迭代器抛出一个 {@code
* ConcurrentModificationException}。因此,编
* 写一个依赖于这个异常来保证其正确性的程序是错误的:迭代器的 fail-fast 行为应该只被用于检查 bugs。
*
* 所有当前类的方法s返回的 {@code Map.Entry} 对s并且它的视图代表这个时间点创建的映射s的快照。他们不支
* 持 {@code Entry.setValue} 方法。(注意但是它可以使用方法 {@code put} 来修改关联 map 的映射。)
*/
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
/**
* 用来维护当前 tree map 的 comparator,或者如果它使用它的键s的自然排序则为 null。
*
* @serial
*/
private final Comparator<? super K> comparator;
/**根部节点**/
private transient Entry<K,V> root;
/**
* 这个 tree 中的条目的数量。
*/
private transient int size = 0;
/**
* 对这个 tree 进行结构性更改的次数。
*/
private transient int modCount = 0;
/**
* 构建一个新的,空的 tree map,使用它的自然顺序。所有加入到这个 map 的键s必须实现 {@link
* Comparable} 接口。并且,所有这样的键s必须手动的可比较:对于这个 map 中的任何键 {@code k1} 和
* {@code k2},{@code k1.compareTo(k2)} 必须不会抛出一个 {@code ClassCastException} 。如
* 果用户试图插入一个违反这个退阅的键(比如,用户试图向键s是 intergers 的 map 中 put 一个 string
* 键),{@code put(Object key, Object value)} 调用会抛出一个 {@code
* ClassCastException}。
*/
public TreeMap() {
comparator = null; //当前 comparator 赋值为 null
}
/**
* 构建一个新的,空的 tree map,根据给定 compaartor <被排序>。所有插入到 map 的键s必须手动的可比
* 较:对于这个 map 中的任何键 {@code k1} 和 {@code k2},{@code k1.compareTo(k2)} 必须不会
* 抛出一个 {@code ClassCastException} 。
*/
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator; //当前 comparator 赋值为 comparator
}
/**
* 构建一个新的包含与给定 map 包含相同映射s 的 tree map,根据它的键s的自然顺序 <被排序>。所有插入
* 到 map 的键s必须手动的可比较:对于这个 map 中的任何键 {@code k1} 和 {@code k2},{@code
* k1.compareTo(k2)} 必须不会抛出一个 {@code ClassCastException}。这个方法在 n*log(n) 时间
* 内运行。
*/
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null; //当前 comparator 赋值为 null
putAll(m); //调用 #putAll
}
/**
* 构建一个新的包含与给定 <被排序 map> 包含相同映射s 的 tree map 。这个方法在线性时间内运行。
*/
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator(); //当前 comparator 赋值为参数 m 的 comparator
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null); //调用 #buildFromSroted
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
// 查找操作
/**
* 返回当前 map 中的键值映射数量。
*/
public int size() {
return size; //返回长度
}
/**
* 如果当前 map 包含一个指定键对应的映射则返回 {@code true}。
*/
public boolean containsKey(Object key) {
return getEntry(key) != null; //调用 getEntry 方法
}
/**
* 如果当前 map 包含一个指定值对应的多个键s则返回 {@code true}。更正式地说,当且仅当当前 map 包含
* 至少一个对于一个值 {@code v} 存在 @code (value==null ? v==null : value.equals(v))} 时返
* 回 {@code true}。这个操作对于大多数实现类将大致需要与 map 长度成线性的时间。
*/
public boolean containsValue(Object value) {
for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e)) //循环,首元素为 #getFirstEntry,步移方式为 #successor
if (valEquals(value, e.value)) //调用 #valEquals 判断
return true;
return false;
}
/**
* 返回指定键映射到的值,或者如果 map 不包含这样的键,则返回 {@code null}。
*
* 更正式地说,如果当前 map 包含一个从键 {@code k} 到值 {@code v} 的依据 map 的顺序比较 {@code
* key} 与 {@code k} 的相等性, 那么方法返回 {@code v},不然的话返回 {@code null}。(至多只有
* 一个这样的映射。)
*
* 一个 {@code null} 返回值并不明确地表示 map 不包含这样的键,也有可能是 map 显式地将键映射到了
* {@code null}。{@link #containsKey containsKey} 操作可以被用来区分这两种情况。
*/
public V get(Object key) {
Entry<K,V> p = getEntry(key); //调用 getEntry 方法
return (p==null ? null : p.value); //如果 p 为 null 返回 null,否则返回 p 的值
}
/**获取比较器方法**/
public Comparator<? super K> comparator() {
return comparator; //返回 comparator
}
/**
* 继承文档
*/
public K firstKey() {
return key(getFirstEntry()); //调用 getFirstEntry 方法后调用静态方法 key
}
/**
* 继承文档
*/
public K lastKey() {
return key(getLastEntry()); //调用 getLastEntry 方法后调用静态方法 key
}
/**
* 拷贝所有指定 map 中的映射到当前 map。这些映射为指定 map 当前存在的人以键替换了当前映射有的任意映
* 射s。
*/
public void putAll(Map<? extends K, ? extends V> map) {
int mapSize = map.size();
if (size==0 && mapSize!=0 && map instanceof SortedMap) { //如果当前长度为 0,并且参数 map 长度不为 0 ,并且参数 map 是 SortedMap 的实例
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
if (c == comparator || (c != null && c.equals(comparator))) { //比较当前 comparator 与参数 map 的 comparator
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null); //调用 #buildFromSorted
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return;
}
}
super.putAll(map); //调用 AbstractMap#putAll,也就是循环参数 map 的 #entrySet,塞入当前 map
}
/**
* 返回指定值对应的当前 map 的条目,或者如果这个 map 不包含这个键对应的一个条目,在返回 {@code
* null}。
*/
final Entry<K,V> getEntry(Object key) {
// 为了提高性能而写在基于比较器的版本
if (comparator != null) //如果当前 comparator 不为 null
return getEntryUsingComparator(key); //调用 #getEntryUsingComparator 方法
if (key == null) //如果键为 null
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root; //root 赋值给 p
while (p != null) { //当 p 不为 null
int cmp = k.compareTo(p.key); //调用键的 #compareTo 方法比较参数与当前条目的键
if (cmp < 0) //如果参数键小于当前条目的键
p = p.left; //p 赋值为左子树
else if (cmp > 0) //如果参数键大于当前条目的键
p = p.right; //p 赋值为右子树
else //如果等于
return p; //返回 p
}
return null; //没有找到等于的情况,返回 null
}
/**
* getEntry 使用 comparator 的版本。从 getEntry 中分离以得到性能。(对于大多数方法这是不值得的,
* 它们更能少地依赖于 comparator 的性能,但是在这里是值得的。),逻辑跟上面的 getEntry 方法差不
* 多,这不过这个方法是在 comparator 不为 null 的时候的处理逻辑。
*/
final Entry<K,V> getEntryUsingComparator(Object key) {
@SuppressWarnings("unchecked")
K k = (K) key;
Comparator<? super K> cpr = comparator;
if (cpr != null) {
Entry<K,V> p = root;
while (p != null) {
int cmp = cpr.compare(k, p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
}
return null;
}
/**
* 根据指定键获得对应条目,如果不存在这样的条目,返回大于指定键的最小键对应的条目,如果不存在这样的条
* 目(比如,这个 Tree 中最大的键都比指定键要小),返回 {@code null}。
*/
final Entry<K,V> getCeilingEntry(K key) {
Entry<K,V> p = root;
while (p != null) { //从根部开始查找
int cmp = compare(key, p.key);
if (cmp < 0) { //如果指定键大于 p 键
if (p.left != null)
p = p.left; //说明还有比 p 小的
else
return p; //没有比 p 小的了,p 大于指定键,p 是最小键条目,返回
} else if (cmp > 0) { //如果指定键小于 p 键
if (p.right != null) {
p = p.right; //说明还有比 p 大的
} else { //没有比 p 大的了
Entry<K,V> parent = p.parent; //p 的父树缓存给 parent,从这里可以看到虽然第一行将 root 赋值给 p,从字面意思理解为将根赋值给 p,但其实 p 并不一定是根,它可能有父树,所以这里的 root 相当于一个游标开始位置,游标移动到了哪里,哪里就是 root
Entry<K,V> ch = p; //p 缓存个 ch
while (parent != null && ch == parent.right) { //当 parent 不为 null 并且 ch == parent.right 时,即 ch 是 parent 的右子树,即 ch 大于 parent,或者找到了树根
ch = parent; //arent 赋值给 ch
parent = parent.parent; //parent 的父树赋值给 parent
}
return parent; //返回 parent
}
} else //如果指定键等于 p 键
return p; //返回 p
}
return null; //返回 null
}
/**
* 获取与指定键对应的条目,如果不存在这样的条目,返回小于指定键的最大键对应的条目,如果不存在这样的条
* 目,则返回 {@code null}。
*/
final Entry<K,V> getFloorEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key);
if (cmp > 0) {// 如果指定键大于 p 键
if (p.right != null) //说明还有比 p 大的
p = p.right;
else
return p; //p 就是最大的了,返回 p
} else if (cmp < 0) { //指定键小于 p 键
if (p.left != null) {
p = p.left;
} else {
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.left) { //如果 ch 是 parent 的左子树,即 ch 小于 parent,或者找到了树根
ch = parent;
parent = parent.parent;
}
return parent;
}
} else // 之间键等于 p 键
return p; //返回 p
}
return null;
}
/**
* 获取大于指定键的最小键对应的条目,如果不存在这样的条目,则返回 {@code null}。
*/
final Entry<K,V> getHigherEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key); //比较参数键与 p 的键
if (cmp < 0) { //参数键小于 p 的键
if (p.left != null) //如果还有小于 p 的条目
p = p.left;
else
return p; //p 已经是最小条目了,返回 p
} else { //参数键大于 p 的键
if (p.right != null) { //如果还有大于 p 的条目
p = p.right;
} else { //没有右子树了
Entry<K,V> parent = p.parent; //p 已经是最大条目了,获取 p 的父树
Entry<K,V> ch = p;
while (parent != null && ch == parent.right) { //如果 ch 是 parent 的右子树
ch = parent;
parent = parent.parent; //步移父树
}
return parent; //直到为左子树或者已经为树根时,返回
}
}
}
return null;
}
/**
* 返回小于指定键的最大键对应的条目,如果不存在这样的条目(例子,Tree 中最小的键都比指定键大),返回
* {@code null}。
*/
final Entry<K,V> getLowerEntry(K key) {
Entry<K,V> p = root;
while (p != null) {
int cmp = compare(key, p.key); //比较指定键与 p 的键
if (cmp > 0) { //如果指定键大于 p 的键
if (p.right != null)
p = p.right; //还有更大的
else
return p; //已为最大
} else { //如果指定键小于 p 的键
if (p.left != null) {
p = p.left; //还有更小的
} else { //没有左子树了
Entry<K,V> parent = p.parent;
Entry<K,V> ch = p;
while (parent != null && ch == parent.left) {
ch = parent;
parent = parent.parent;
}
return parent; //直到为右子树或者已经为树根时,返回
}
}
}
return null;
}
/**
* 键当前 map 中的指定键与指定值关联。如果这个 map 之前包含这个键的映射,旧的值将被替换。
*/
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) { //如果当前 root 为 null
compare(key, key); // 类型(且可能为 null)检查
root = new Entry<>(key, value, null); //构建 root
size = 1; //第一次加入,长度为 1
modCount++; //第一次加入,结构性变更,自增 modCount
return null; //返回 null
}
//存在 root
int cmp;
Entry<K,V> parent;
// 分割 comparator 和 comparable 路径s
Comparator<? super K> cpr = comparator;
if (cpr != null) { //如果 comparator 不为 null
do {
parent = t;
cmp = cpr.compare(key, t.key); //comparator 存在,调用 compare 方法,比较指定键与 t 的键
if (cmp < 0) //如果指定键小于 t 的键
t = t.left; //树查找更小的条目
else if (cmp > 0) //如果指定键大于 t 的键
t = t.right; //树查找更大的条目
else //如果指定键等于 t 的键
return t.setValue(value); //调用 t.setValue 返回
} while (t != null); //循环条件 t 不为 null 时
}
else { //如果 comparator 为 null
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key); //comparator 不存在,调用 compareTo 方法
//比较与返回与 comparator 存在时一样
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//通过 compare 和 compareTo 都没有找到相等的
Entry<K,V> e = new Entry<>(key, value, parent); //构建新的条目
if (cmp < 0) //如果当前键比结果的键都要小
parent.left = e; //将 e 作为结果的左子树
else //不等于,那么必然是大于
parent.right = e; //将 e 作为结果的右子树
fixAfterInsertion(e); //调用 #fixAfterInsertion
size++; //插入后,自增 size
modCount++; //自增 modCount
return null; //不存在旧值,返回 null
}
/**
* 如果当前 TreMap 中存在当前键,则移除对应的映射。
*/
public V remove(Object key) {
Entry<K,V> p = getEntry(key); //调用 #getEntry
if (p == null) //如果不存在
return null; //返回 null
V oldValue = p.value; //缓存 p 的值
deleteEntry(p); //调用 #deleteEntry
return oldValue; //返回 oldValue
}
/**
* 移除当前 map 中的所有映射s。
* 调用返回后这个 map 就会为空。
*/
public void clear() {
modCount++; //自增 modCount
size = 0; //size赋值为 0
root = null; //root 赋值为 null
}
/**
* 返回当前 {@code TreeMap} 实例的一个浅拷贝。(键s和值s没有被克隆。)
*/
public Object clone() {
TreeMap<?,?> clone;
try {
clone = (TreeMap<?,?>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
// 将克隆对象只为“处女”状态(除了 comparator)
clone.root = null;
clone.size = 0;
clone.modCount = 0;
clone.entrySet = null;
clone.navigableKeySet = null;
clone.descendingMap = null;
// 用我们的映射s初始化克隆
try {
clone.buildFromSorted(size, entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
return clone;
}
// NavigableMap API 方法
/**
* @since 1.6
*/
//获取第一个条目
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry()); //调用 #getFirstEntry,然后调用 #exportEntry
}
/**
* @since 1.6
*/
//获取最后一个条目
public Map.Entry<K,V> lastEntry() {
return exportEntry(getLastEntry()); //调用 #getLastEntry,然后调用 #exportEntry
}
/**
* @since 1.6
*/
//弹出第一个条目
public Map.Entry<K,V> pollFirstEntry() {
Entry<K,V> p = getFirstEntry(); //调用 #getFirstEntry
Map.Entry<K,V> result = exportEntry(p); //调用 #exportEntry
if (p != null) //如果 p 不为 null
deleteEntry(p); //调用 #deleteEntry
return result; //返回 result
}
/**
* @since 1.6
*/
//弹出最后一个条目
public Map.Entry<K,V> pollLastEntry() {
Entry<K,V> p = getLastEntry(); //调用 #getLastEntry
Map.Entry<K,V> result = exportEntry(p); //调用 #exportEntry
if (p != null) //如果 p 不为 null
deleteEntry(p); //调用 #deleteEntry
return result; //返回 result
}
/**
* 返回严格小于(开区间)指定键的最大键对应的映射
*/
public Map.Entry<K,V> lowerEntry(K key) {
return exportEntry(getLowerEntry(key)); //调用 #getLowerEntry,然后调用 #exportEntry 方法
}
/**
* 返回严格小于(开区间)指定键的最大键
*/
public K lowerKey(K key) {
return keyOrNull(getLowerEntry(key)); //调用 #getLowerEntry,然后调用 #keyOrNull,这里可以看到 #keyOrNull 这个方法设计的巧妙
}
/**
* 返回小于等于(闭区间)指定键的最大键对应的映射
*/
public Map.Entry<K,V> floorEntry(K key) {
return exportEntry(getFloorEntry(key)); //调用 #getFloorEntry,然后调用 #exportEntry
}
/**
* 返回小于等于(闭区间)指定键的最大键
*/
public K floorKey(K key) {
return keyOrNull(getFloorEntry(key)); //调用 #getFloorEntry,然后调用 #keyOrNull
}
/**
* 返回大于等于(闭区间)指定键的最小键对应的映射
*/
public Map.Entry<K,V> ceilingEntry(K key) {
return exportEntry(getCeilingEntry(key)); //调用 #getCeilingEntry,然后调用 #exportEntry
}
/**
* 返回大于等于(闭区间)指定键的最小键
*/
public K ceilingKey(K key) {
return keyOrNull(getCeilingEntry(key)); //调用 #getCeilingEntry,然后调用 #keyOrNull
}
/**
* 返回严格大于(开区间)指定键的最小键对应的映射
*/
public Map.Entry<K,V> higherEntry(K key) {
return exportEntry(getHigherEntry(key)); //调用 #getHigherEntry,然后调用 #exportEntry
}
/**
* 返回严格大于(开区间)指定键的最小键
*/
public K higherKey(K key) {
return keyOrNull(getHigherEntry(key)); //调用 #getHigherEntry,然后调用 #keyOrNull
}
// 视图s
/**
* 在第一次这个视图被请求时初始化的类属性来包含一个条目 set 视图的实例。视图s是状态无关的,所以没有理
* 由创建多个。
*/
private transient EntrySet entrySet; //entrySet
private transient KeySet<K> navigableKeySet; //navigableKeySet,类比 HashMap 中的 keySet
private transient NavigableMap<K,V> descendingMap; //desendingMap,注意这个是 HashMap 中没有的
/**
* 返回一个当前 map 包含的键s的 {@link Set} 视图。
*
* 这个 set 的迭代器以升序返回键s。这个 set 的并行迭代器是延迟绑定,fail-fast 的,并且额外使用一个
* 升序的键顺序合并顺序记录 {@link Spliterator#SORTED} 和 {@link Spliterator#ORDERED} 特征
* 值。如果这个 tree map 的 comparator (查看 {@link #comparator()}) 是 {@code null},这
* 个并行迭代器的 comparator (查看 {@link java.util.Spliterator#getComparator()})是
* {@code null}。不然的话,这个并行迭代器的 comparator 就会与整个 tree map 的 comparator 顺序
* 相同或者强制相同。
*
* 这个 set 被这个 map 支持,所以对于这个 map 的修改会影响到 这个 set,反之亦然。如果这个 map 在
* 涵盖这个 set 的迭代操作过程中被修改了(除了通过这个迭代器自己的 {@code remove} 操作),这个迭代
* 操作的结果是不可定义的。这个 set 支持元素移除,也就是从这个 map 中移除对应的映射,通过 {@code
* Iterator.remove}, {@code Set.remove}, {@code removeAll}, {@code retainAll}, 和
* {@code clear} 操作。它不支持 {@code add} 或者 {@code addAll} 操作。
*/
public Set<K> keySet() {
return navigableKeySet(); //调用 #navigableKeySet
}
/**
* 返回可导航的 keySet
*
* @since 1.6
*/
public NavigableSet<K> navigableKeySet() {
KeySet<K> nks = navigableKeySet;
return (nks != null) ? nks : (navigableKeySet = new KeySet<>(this)); //调用 KeySet 构造器,传入当前 map
}
/**
* 返回降序的 keySet
*
* @since 1.6
*/
public NavigableSet<K> descendingKeySet() {
return descendingMap().navigableKeySet(); //调用 #descendingMap,然后调用 #navigableKeySet
}
/**
* 返回一个包含当前 map 中所有值的 {@link Collection} 视图。
*
* 这个 collection 的迭代器以升序返回对应键s对应的值s。这个 collectino 的并行迭代器是延迟绑定和
* fail-fast 的,并且额外使用一个对应键s的升序的合并的顺序记录 {@link Spliterator#ORDERED}。
*
* 这个 collection 被这个 map 支持,所以所有对这个 map 的修改都会影响这个 collection,反之亦
* 然。如果这个 map 在涵盖这个 collectin 的迭代操作过程中被修改了(除了通过这个迭代器自己的
* {@code remove} 操作),迭代操作的结果是不可定义的。这个 collection 支持元素移除,也就是从这个
* map 中移除对应的映射,通过 {@code Iterator.remove}, {@code Set.remove}, {@code
* removeAll}, {@code retainAll}, 和 {@code clear} 操作。它不支持 {@code add} 或者 {@code
* addAll} 操作。
*/
public Collection<V> values() {
Collection<V> vs = values;
if (vs == null) {
vs = new Values(); //调用 Values 空构造器
values = vs;
}
return vs;
}
/**
* 返回一个包含当前 map 中所有映射s的 {@link Set} 视图。
*
* 这个 set 的迭代器以键的升序顺序返回条目s。这个 set 的并行迭代器是延迟绑定,fail-fast 的,并且额
* 外使用一个升序的键顺序合并顺序记录 {@link Spliterator#SORTED} 和 {@link
* Spliterator#ORDERED} 特征值。
*
* 这个 set 被这个 map 支持,所以对于这个 map 的修改会影响到 这个 set,反之亦然。如果这个 map 在
* 涵盖这个 set 的迭代操作过程中被修改了(除了通过这个迭代器自己的 {@code remove} 操作),这个迭代
* 操作的结果是不可定义的。这个 set 支持元素移除,也就是从这个 map 中移除对应的映射,通过 {@code
* Iterator.remove}, {@code Set.remove}, {@code removeAll}, {@code retainAll}, 和
* {@code clear} 操作。它不支持 {@code add} 或者 {@code addAll} 操作。
*/
public Set<Map.Entry<K,V>> entrySet() {
EntrySet es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet()); //调用 EntrySet 空构造器
}
/**
* @since 1.6
*/
public NavigableMap<K, V> descendingMap() {
NavigableMap<K, V> km = descendingMap;
return (km != null) ? km :
(descendingMap = new DescendingSubMap<>(this,
true, null, true,
true, null, true));
}
/**
* 返回子映射s方法(Navigable 对象)
*/
public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive) {
return new AscendingSubMap<>(this,
false, fromKey, fromInclusive,
false, toKey, toInclusive); //调用 AscendingSubMap 构造器
}
/**
* 返回头映射s方法
*/
public NavigableMap<K,V> headMap(K toKey, boolean inclusive) {
return new AscendingSubMap<>(this,
true, null, true,
false, toKey, inclusive); //调用 AscendingSubMap 构造器
}
/**
* 返回尾映射s方法
*/
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive) {
return new AscendingSubMap<>(this,
false, fromKey, inclusive,
true, null, true); //调用 AscendingSubMap 构造器
}
/**
* 返回子映射s方法(SortedMap 对象,适配更广泛)
*/
public SortedMap<K,V> subMap(K fromKey, K toKey) {
return subMap(fromKey, true, toKey, false); //调用 #subMap
}
/**
* 返回头映射s方法(SortedMap 对象,适配更广泛)
*/
public SortedMap<K,V> headMap(K toKey) {
return headMap(toKey, false); //调用 #headMap
}
/**
* 返回尾映射s方法(SortedMap 对象,适配更广泛)
*/
public SortedMap<K,V> tailMap(K fromKey) {
return tailMap(fromKey, true); //调用 #tailMap
}
//替换方法
@Override
public boolean replace(K key, V oldValue, V newValue) {
Entry<K,V> p = getEntry(key); //调用 #getEntry
if (p!=null && Objects.equals(oldValue, p.value)) { //如果 p 不为 null 并且 p 值与指定值相同
p.value = newValue; //p 值置为指定值
return true; //返回 true
}
return false; //返回 false
}
//替换方法
@Override
public V replace(K key, V value) {
Entry<K,V> p = getEntry(key); //调用 #getEntry
if (p!=null) { //如果 p 不为 null 直接替换并返回旧值
V oldValue = p.value;
p.value = value;
return oldValue;
}
return null;
}
//循环消费方法
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
int expectedModCount = modCount; //缓存 modCount
for (Entry<K, V> e = getFirstEntry(); e != null; e = successor(e)) { //初始值为 #getFirstEntry,步移方式是 #successor
action.accept(e.key, e.value); //消费
if (expectedModCount != modCount) { //如果当前 modCount 与 expectedModCount 不想等
throw new ConcurrentModificationException(); //抛出 ConcurrentModificationException
}
}
}
//替换所有方法
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Objects.requireNonNull(function);
int expectedModCount = modCount; //缓存 modCount
for (Entry<K, V> e = getFirstEntry(); e != null; e = successor(e)) { //初始值为 #getFirstEntry,步移方式是 #successor
e.value = function.apply(e.key, e.value); //作用函数调用
if (expectedModCount != modCount) {
throw new ConcurrentModificationException();
}
}
}
// 视图类支持
//值类,继承自 AbstractCollection
class Values extends AbstractCollection<V> {
//获取迭代器方法
public Iterator<V> iterator() {
return new ValueIterator(getFirstEntry()); //调用 #getFirstEntry,然后调用 ValueIterator 构造器
}
//获取长度方法
public int size() {
return TreeMap.this.size(); //调用 TreeMap#size
}
//判断是否包含方法
public boolean contains(Object o) {
return TreeMap.this.containsValue(o); //调用 TreeMap#containsValue
}
//移除方法
public boolean remove(Object o) {
for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e)) { //#getFirstEntry 开始,#successor 步移
if (valEquals(e.getValue(), o)) { //调用 #valEquals 比较
deleteEntry(e); //调用 #deleteEntry
return true; //返回 true
}
}
return false; //返回 false
}
//清空方法
public void clear() {
TreeMap.this.clear(); //调用 TreeMap#clear
}
//获得键并行迭代器方法
public Spliterator<V> spliterator() {
return new ValueSpliterator<K,V>(TreeMap.this, null, null, 0, -1, 0); //调用 ValueSpliterator 构造器
}
}
//EntrySet 类,继承自 AbstractSet
class EntrySet extends AbstractSet<Map.Entry<K,V>> {
//获得串行迭代器
public Iterator<Map.Entry<K,V>> iterator() {
return new EntryIterator(getFirstEntry()); //调用 #getFirstEntry,调用 EntryIterator 构造器
}
//判存方法,注意这里的实现与 Values 不同
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> entry = (Map.Entry<?,?>) o;
Object value = entry.getValue(); //缓存参数的值
Entry<K,V> p = getEntry(entry.getKey()); //根据参数键调用 #getEntry
return p != null && valEquals(p.getValue(), value); //比较 p 的值与指定存书的值
}
//移除方法,注意这里与 Values 实现不同
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> entry = (Map.Entry<?,?>) o;
Object value = entry.getValue();
Entry<K,V> p = getEntry(entry.getKey());
if (p != null && valEquals(p.getValue(), value)) { //如果存在于指定值相同的值
deleteEntry(p); //调用 #deleteEntry
return true; //返回 true
}
return false; //返回 false
}
//获得长度方法
public int size() {
return TreeMap.this.size(); //TreeMap#size
}
//清空方法
public void clear() {
TreeMap.this.clear(); //TreeMap#clear
}
//获得条目并行迭代器
public Spliterator<Map.Entry<K,V>> spliterator() {
return new EntrySpliterator<K,V>(TreeMap.this, null, null, 0, -1, 0); //调用 EntrySpliterator 构造器
}
}
/*
* 不像 Values 与 EntrySet,这个 keySet 类是静态的,委托给一个 NavigableMap 来允许被 SubMaps
* 使用,这比需要对以下迭代器方法进行类型测试更糟糕,这些方法在主类和子类中都被适当地定义了。
*/
//返沪键迭代器
Iterator<K> keyIterator() {
return new KeyIterator(getFirstEntry()); //#getFirstEntry,调用 KeyIterator 构造器
}
//返回降序键迭代器
Iterator<K> descendingKeyIterator() {
return new DescendingKeyIterator(getLastEntry()); //#getLastEntry,调用 DescendingKeyIterator 构造器
}
//KeySet 类,继承自 AbstractSet 类,实现了 NavigableSet 接口
static final class KeySet<E> extends AbstractSet<E> implements NavigableSet<E> {
private final NavigableMap<E, ?> m; //持有一个 NavigableMap 变量
KeySet(NavigableMap<E,?> map) { m = map; } //通过构造器传入一个 NavigableMap 缓存
//获取串行迭代器
public Iterator<E> iterator() {
if (m instanceof TreeMap) //如果 m 是 TreeMap 实例
return ((TreeMap<E,?>)m).keyIterator(); //调用 Tree#keyIterator
else //否则
return ((TreeMap.NavigableSubMap<E,?>)m).keyIterator(); //调用 NavigableSubMap#keyIterator
}
//获取降序迭代器
public Iterator<E> descendingIterator() {
if (m instanceof TreeMap) //如果 m 是 TreeMap 的实例
return ((TreeMap<E,?>)m).descendingKeyIterator(); //调用 TreeMap#descendingKeyIterator
else
return ((TreeMap.NavigableSubMap<E,?>)m).descendingKeyIterator(); //调用 TreeMap.NavigableSubMap#descendingKeyIterator
}
public int size() { return m.size(); //调用 m.size
public boolean isEmpty() { return m.isEmpty(); } //调用 m.isEmpty
public boolean contains(Object o) { return m.containsKey(o); } //调用 m.continasKey
public void clear() { m.clear(); } //调用 m.clear
public E lower(E e) { return m.lowerKey(e); } //调用 m.lowerKey
public E floor(E e) { return m.floorKey(e); } //调用 m.floorKey
public E ceiling(E e) { return m.ceilingKey(e); } //调用 m.ceilingKey
public E higher(E e) { return m.higherKey(e); } //调用 m.higerKey
public E first() { return m.firstKey(); } //调用 m.firstKey
public E last() { return m.lastKey(); } //调用 m.lastKey
public Comparator<? super E> comparator() { return m.comparator(); } //返回 m.comparator
public E pollFirst() {
Map.Entry<E,?> e = m.pollFirstEntry(); //调用 m.pollFirstEntry
return (e == null) ? null : e.getKey(); //返回 e 的键
}
public E pollLast() {
Map.Entry<E,?> e = m.pollLastEntry(); //调用 m.pollLastEntry
return (e == null) ? null : e.getKey(); //返回 e 的键
}
public boolean remove(Object o) {
int oldSize = size(); //调用 #size,获取 m 的长度
m.remove(o); //调用 m.remove
return size() != oldSize; //判断现在的长度是否为原有长度
}
//子 sets
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new KeySet<>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive)); //调用 m 的 subMap 方法,然后调用 KeySet 的构造器
}
//头 sets
public NavigableSet<E> headSet(E toElement, boolean inclusive) {
return new KeySet<>(m.headMap(toElement, inclusive)); //调用 m 的 headeMap 方法,然后调用 KeySet 的构造器
}
// 尾 sets
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new KeySet<>(m.tailMap(fromElement, inclusive)); //调用 m 的 tailMap 方法,然后调用 KeySet 的构造器
}
//以下方法同样是为了简化调用,提供了默认参数
//子 sets
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false); //调用 #subSet
}
//头 sets
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false); //调用 #headSet
}
// 尾 sets
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true); //调用 #tailset
}
// 降序 set
public NavigableSet<E> descendingSet() {
return new KeySet<>(m.descendingMap()); //调用 m 的 descendingMap 方法,然后调用 KeySet 构造器
}
//返回并行迭代器
public Spliterator<E> spliterator() {
return keySpliteratorFor(m); //调用 #keySpliteratorFor
}
}
/**
* PrivateEntryIterator 类,TreeMap 迭代器基类,实现了 Iterator 接口
*/
abstract class PrivateEntryIterator<T> implements Iterator<T> {
//这里的类属性有点像 LinkedList 的迭代器,不同的是没有 nextIndex(也是因为它不是连续的,而是散列的原因)
Entry<K,V> next;
Entry<K,V> lastReturned;
int expectedModCount;
//构造器,参数赋值给 next,当前 modCount 赋值给 expectedModCount
PrivateEntryIterator(Entry<K,V> first) {
expectedModCount = modCount;
lastReturned = null;
next = first;
}
//判断游标后是否还有条目
public final boolean hasNext() {
return next != null; //判断 next 是否不为 null
}
//返回游标后的下一个条目
final Entry<K,V> nextEntry() {
Entry<K,V> e = next; //next 缓存给 e
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = successor(e); // #successor
lastReturned = e; //e 赋值给 lastReturned
return e; //返回 e
}
//返回游标前一个条目,扩展方法
final Entry<K,V> prevEntry() {
Entry<K,V> e = next; //next 缓存给 e
if (e == null)
throw new NoSuchElementException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
next = predecessor(e); //#predecessor
lastReturned = e; //e 赋值给 lastReturned
return e; //返回 e
}
//移除方法
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
// deleted entries are replaced by their successors
if (lastReturned.left != null && lastReturned.right != null) //如果 lastReturned 的左子树不为 null 并且 lastReturned 的右子树不为 null
next = lastReturned; //建立 next 与 lastReturned 的引用链接
deleteEntry(lastReturned); //#deleteEntry
expectedModCount = modCount;
lastReturned = null; //lastReturned 赋值为 null,如果建立了引用链接,那么同时 next 也变成了 null,也就没有下一个元素了,如果 lastReturned 做子树为 null 或者 lastReturned 的右子树为 null,则不会建立链接,next 不变
}
}
//EntryIterator 迭代器,继承自 PrivateEntryIterator
final class EntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> {
EntryIterator(Entry<K,V> first) {
super(first); //调用 PrivateEntryIterator 构造器
}
public Map.Entry<K,V> next() {
return nextEntry(); //调用 PrivateEntryIterator#nextEntry 返回条目
}
}
//ValueIterator 迭代器,继承自 PrivateEntryIterator
final class ValueIterator extends PrivateEntryIterator<V> {
ValueIterator(Entry<K,V> first) {
super(first); //与 EntryIterator 相同
}
public V next() {
return nextEntry().value; //调用 PrivateEntryIterator#nextEntry 返回值
}
}
//KeyIterator 迭代器,继承自 PrivateEntryIterator
final class KeyIterator extends PrivateEntryIterator<K> {
KeyIterator(Entry<K,V> first) {
super(first); //与 EntryIterator 相同
}
public K next() {
return nextEntry().key; //调用 PrivateEntryIterator#nextEntry 返回键
}
}
//DecendingKeyIterator 迭代器,继承自 PrivateEntryIterator
final class DescendingKeyIterator extends PrivateEntryIterator<K> {
DescendingKeyIterator(Entry<K,V> first) {
super(first); //与 EntryIterator 相同
}
public K next() {
return prevEntry().key; //调用 PrivateEntryIterator#prevEntry 返回键
}
//移除方法
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
deleteEntry(lastReturned); //调用 #deleteEntry
lastReturned = null; //注意这里和 next 没有关系,将 lastReturned 赋值为 null
expectedModCount = modCount; //将 expectedModCount 赋值为 modCount
}
}
// 小工具
/**
* 使用当前 TreeMap 正确的比较方式比较两个键s。
*/
@SuppressWarnings("unchecked")
final int compare(Object k1, Object k2) {
return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2) //如果 k1 和 k2 是 Comparable 实现类,调用 compareTo 方法比较
: comparator.compare((K)k1, (K)k2); //否则调用 comparator.compare 进行比较
}
/**
* 测试两个值s的相等性。它与 o1.equals(o2) 的区别仅仅在于它正确地拷贝 {@code null} o1。
*/
static final boolean valEquals(Object o1, Object o2) {
return (o1==null ? o2==null : o1.equals(o2));
}
/**
* 为条目返回 SimpleImmutableEntry,如果(条目)是 null 则返回 null
*/
static <K,V> Map.Entry<K,V> exportEntry(TreeMap.Entry<K,V> e) {
return (e == null) ? null :
new AbstractMap.SimpleImmutableEntry<>(e); //调用 AbstractMap#SimpleImmutableEntry 构造器,如果还记得这个类,它不支持 setValue 方法,只是返回一个线程安全的键值映射s快照
}
/**
* 返回条目的键,如果(条目是)null 则返回 null
*/
static <K,V> K keyOrNull(TreeMap.Entry<K,V> e) {
return (e == null) ? null : e.key;
}
/**
* 返回指定条目对应的键
*/
static <K> K key(Entry<K,?> e) {
if (e==null)
throw new NoSuchElementException();
return e.key;
}
// 子 maps
/**
* 为不匹配的栅栏键服务的虚拟之作为无边界的 SubMapIterators
*/
private static final Object UNBOUNDED = new Object();
/**
* @serial 包含
*
* NavigableSubMap 类,继承自 AbstractMap,实现了 NavigableMap 接口和 Serializable 接口
*/
abstract static class NavigableSubMap<K,V> extends AbstractMap<K,V>
implements NavigableMap<K,V>, java.io.Serializable {
private static final long serialVersionUID = -2102997345730753016L;
/**
* 支持的 map
*/
final TreeMap<K,V> m;
/**
* 断点被使用三点来代表(fromStart, lo, loInclusive) 和 (toEnd, hi, hiInclusive)。如果
* fromStart 是 true,那么 low(当然的) 边界是支持的 map 的起始(点),而其他的值s被忽略。
* 否则的话,如果 loInclusive 是 true,lo 是包含的边界,或者(loInclusive 是 false 的话)
* lo 是不包含的边界。对于 upper 边界也类似。
*/
final K lo, hi;
final boolean fromStart, toEnd;
final boolean loInclusive, hiInclusive;
//NavigableSubMap 构造器
NavigableSubMap(TreeMap<K,V> m,
boolean fromStart, K lo, boolean loInclusive,
boolean toEnd, K hi, boolean hiInclusive) {
if (!fromStart && !toEnd) { //fromStart 为 false 并且 toEnd 为 false,意味着不从起始开始,不到末尾结束
if (m.compare(lo, hi) > 0)
throw new IllegalArgumentException("fromKey > toKey");
} else { //fromStart 为 true 或者 toEnd 为 true,意味着从其实开始或者到末尾结束
if (!fromStart) //如果到末尾结束,类型检查
m.compare(lo, lo);
if (!toEnd) //如果从起始开始
m.compare(hi, hi);
}
this.m = m;
this.fromStart = fromStart;
this.lo = lo;
this.loInclusive = loInclusive;
this.toEnd = toEnd;
this.hi = hi;
this.hiInclusive = hiInclusive;
}
// 内部工具
//判断太低方法
final boolean tooLow(Object key) {
if (!fromStart) { //如果 fromStart 为 false
int c = m.compare(key, lo); //比较键参数 与 lo
if (c < 0 || (c == 0 && !loInclusive)) //如果键参数小于 lo,或者键参数等于 lo 并且 loInclusive 为 false,说明不包含 lo
return true; //返回 true
}
return false; //返回 false
}
//判断太高方法
final boolean tooHigh(Object key) {
if (!toEnd) { //如果 toEnd 为 false
int c = m.compare(key, hi); //比较键参数与 hi
if (c > 0 || (c == 0 && !hiInclusive)) //如果键参数大于 hi,或者键参数等于 hi 并且 hiInclusive 为 false,说明不包含 hi
return true; //返回 true
}
return false; //返回 false
}
//判断是否在范围中方法
final boolean inRange(Object key) {
return !tooLow(key) && !tooHigh(key); //调用 #tooLow 与 #tooHigh 进行判断
}
//判断在闭区间中
final boolean inClosedRange(Object key) {
return (fromStart || m.compare(key, lo) >= 0) //如果 fromStart 为 true 并且键参数大于等于 lo
&& (toEnd || m.compare(hi, key) >= 0); //并且如果 toEnd 为 true 并且键参数小于等于 hi
}
//判断是否在范围中方法
final boolean inRange(Object key, boolean inclusive) {
return inclusive ? inRange(key) : inClosedRange(key); //如果 inclusive 参数为 true,#inRange,否则 #inclosedRange
}
/*
* 关系运算s的绝对定位版本s。
* map 子类使用这些名称类似 “sub” 版本s来为降序 maps 倒置。
*/
//最小绝对定位条目
final TreeMap.Entry<K,V> absLowest() {
TreeMap.Entry<K,V> e =
(fromStart ? m.getFirstEntry() : //fromStart 为 true,调用 m.getFirstEntry
(loInclusive ? m.getCeilingEntry(lo) : //否则判断 loInclusive 是否为 true,如果为 true 调用 m.getCeilingEntry
m.getHigherEntry(lo))); //否则调用 m.getHigherEntry
return (e == null || tooHigh(e.key)) ? null : e; //如果 e 为 null 或者 #tooHigh 为 true 则返回 null,否则返回 e
}
//最大绝对定位条目
final TreeMap.Entry<K,V> absHighest() {
TreeMap.Entry<K,V> e =
(toEnd ? m.getLastEntry() : //toEnd 为 true,调用 m.getLatEntry
(hiInclusive ? m.getFloorEntry(hi) : //否则判断 hiInclusive 是否为 true,如果为 true 调用 m.getFloorEntry
m.getLowerEntry(hi))); //否则调用 m.getLowerEntry
return (e == null || tooLow(e.key)) ? null : e; //如果 e 为 null 或者 #tooLow 为 true 则返回 null,否则返回 e
}
//返回大于等于指定键的最小绝对定位键条目
final TreeMap.Entry<K,V> absCeiling(K key) {
if (tooLow(key)) //#tooLow
return absLowest(); //# absLoest
TreeMap.Entry<K,V> e = m.getCeilingEntry(key); //调用 m.getCeilingEntry
return (e == null || tooHigh(e.key)) ? null : e; //如果 e 为 null 或者 #tooHigh 为 true 则返回 null,否则返回 e
}
//返回大于指定键的最小绝对定位键条目
final TreeMap.Entry<K,V> absHigher(K key) {
if (tooLow(key))
return absLowest();
TreeMap.Entry<K,V> e = m.getHigherEntry(key);
return (e == null || tooHigh(e.key)) ? null : e;
}
//返回小于等于指定键的最大绝对定位键条目
final TreeMap.Entry<K,V> absFloor(K key) {
if (tooHigh(key))
return absHighest();
TreeMap.Entry<K,V> e = m.getFloorEntry(key);
return (e == null || tooLow(e.key)) ? null : e;
}
//返回小于指定键的最大绝对定位键条目
final TreeMap.Entry<K,V> absLower(K key) {
if (tooHigh(key))
return absHighest();
TreeMap.Entry<K,V> e = m.getLowerEntry(key);
return (e == null || tooLow(e.key)) ? null : e;
}
//返回以升序穿越的高绝对定位栅栏
final TreeMap.Entry<K,V> absHighFence() {
return (toEnd ? null : (hiInclusive ?
m.getHigherEntry(hi) :
m.getCeilingEntry(hi)));
}
//返回以降序穿越的低绝对定位栅栏
final TreeMap.Entry<K,V> absLowFence() {
return (fromStart ? null : (loInclusive ?
m.getLowerEntry(lo) :
m.getFloorEntry(lo)));
}
// 抽象方法定义在升序或者降序类s中
// 这些依赖于正确的绝对定位版本s
abstract TreeMap.Entry<K,V> subLowest();
abstract TreeMap.Entry<K,V> subHighest();
abstract TreeMap.Entry<K,V> subCeiling(K key);
abstract TreeMap.Entry<K,V> subHigher(K key);
abstract TreeMap.Entry<K,V> subFloor(K key);
abstract TreeMap.Entry<K,V> subLower(K key);
//从当前子映射的角度返回键升序迭代器
abstract Iterator<K> keyIterator();
//返回键并行迭代器
abstract Spliterator<K> keySpliterator();
//从当前子映射的角度返回键降序迭代器
abstract Iterator<K> descendingKeyIterator();
// 公共方法
public boolean isEmpty() {
//如果 fromStart 与 toEnd 都为 true,调用 m.isEmpty,否则调用 entrySet().isEmpty
return (fromStart && toEnd) ? m.isEmpty() : entrySet().isEmpty();
}
public int size() {
//如果 fromStart 与 toEnd 都为 true,调用 m.size,否则调用 entrySet().size
return (fromStart && toEnd) ? m.size() : entrySet().size();
}
public final boolean containsKey(Object key) {
//如果 #inRange,调用 m.containsKey
return inRange(key) && m.containsKey(key);
}
public final V put(K key, V value) {
//如果 #inRange,调用 m.put
if (!inRange(key)) //这里就实现了确保在范围内的功能
throw new IllegalArgumentException("key out of range");
return m.put(key, value);
}
public final V get(Object key) {
return !inRange(key) ? null : m.get(key);
}
public final V remove(Object key) {
return !inRange(key) ? null : m.remove(key);
}
public final Map.Entry<K,V> ceilingEntry(K key) {
return exportEntry(subCeiling(key)); //#subCeiling,#exportEntry
}
public final K ceilingKey(K key) {
return keyOrNull(subCeiling(key)); //#subCeiling,#keyOrNull
}
public final Map.Entry<K,V> higherEntry(K key) {
return exportEntry(subHigher(key)); //#subHigher,#exportEntry
}
public final K higherKey(K key) {
return keyOrNull(subHigher(key)); //#subHigher,#keyOrNull
}
public final Map.Entry<K,V> floorEntry(K key) {
return exportEntry(subFloor(key)); //#subFloor,#exportEntry
}
public final K floorKey(K key) {
return keyOrNull(subFloor(key)); //#subFloor,#keyOrNull
}
public final Map.Entry<K,V> lowerEntry(K key) {
return exportEntry(subLower(key)); //#subLower,#exportEntry
}
public final K lowerKey(K key) {
return keyOrNull(subLower(key)); //#subLower,#keyOrNull
}
public final K firstKey() {
return key(subLowest()); //#subLowest,#key
}
public final K lastKey() {
return key(subHighest()); //#subHigheste,#key
}
public final Map.Entry<K,V> firstEntry() {
return exportEntry(subLowest());
}
public final Map.Entry<K,V> lastEntry() {
return exportEntry(subHighest());
}
public final Map.Entry<K,V> pollFirstEntry() {
TreeMap.Entry<K,V> e = subLowest();
Map.Entry<K,V> result = exportEntry(e);
if (e != null)
m.deleteEntry(e);
return result;
}
public final Map.Entry<K,V> pollLastEntry() {
TreeMap.Entry<K,V> e = subHighest();
Map.Entry<K,V> result = exportEntry(e);
if (e != null)
m.deleteEntry(e);
return result;
}
// 视图s
transient NavigableMap<K,V> descendingMapView;
transient EntrySetView entrySetView;
transient KeySet<K> navigableKeySetView;
public final NavigableSet<K> navigableKeySet() {
KeySet<K> nksv = navigableKeySetView;
return (nksv != null) ? nksv :
(navigableKeySetView = new TreeMap.KeySet<>(this));
}
public final Set<K> keySet() {
return navigableKeySet();
}
public NavigableSet<K> descendingKeySet() {
return descendingMap().navigableKeySet();
}
public final SortedMap<K,V> subMap(K fromKey, K toKey) {
return subMap(fromKey, true, toKey, false);
}
public final SortedMap<K,V> headMap(K toKey) {
return headMap(toKey, false);
}
public final SortedMap<K,V> tailMap(K fromKey) {
return tailMap(fromKey, true);
}
// 视图类s
// NavigableSubMap EntrySetView
abstract class EntrySetView extends AbstractSet<Map.Entry<K,V>> {
private transient int size = -1, sizeModCount;
//加上了对于范围的判断
public int size() {
if (fromStart && toEnd)
return m.size();
if (size == -1 || sizeModCount != m.modCount) {
sizeModCount = m.modCount;
size = 0;
Iterator<?> i = iterator();
while (i.hasNext()) {
size++;
i.next();
}
}
return size;
}
public boolean isEmpty() {
TreeMap.Entry<K,V> n = absLowest();
return n == null || tooHigh(n.key);
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> entry = (Map.Entry<?,?>) o;
Object key = entry.getKey();
if (!inRange(key))
return false;
TreeMap.Entry<?,?> node = m.getEntry(key);
return node != null &&
valEquals(node.getValue(), entry.getValue());
}
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> entry = (Map.Entry<?,?>) o;
Object key = entry.getKey();
if (!inRange(key))
return false;
TreeMap.Entry<K,V> node = m.getEntry(key);
if (node!=null && valEquals(node.getValue(),
entry.getValue())) {
m.deleteEntry(node);
return true;
}
return false;
}
}
/**
* 子映射s迭代器
*/
abstract class SubMapIterator<T> implements Iterator<T> {
TreeMap.Entry<K,V> lastReturned;
TreeMap.Entry<K,V> next;
final Object fenceKey; //多了个一个栅栏键
int expectedModCount;
SubMapIterator(TreeMap.Entry<K,V> first,
TreeMap.Entry<K,V> fence) {
expectedModCount = m.modCount;
lastReturned = null;
next = first;
fenceKey = fence == null ? UNBOUNDED : fence.key;
}
public final boolean hasNext() {
return next != null && next.key != fenceKey; //多了判断 next 的键不是栅栏键
}
final TreeMap.Entry<K,V> nextEntry() {
TreeMap.Entry<K,V> e = next;
if (e == null || e.key == fenceKey) //多了判断 next 的键不是栅栏键
throw new NoSuchElementException();
if (m.modCount != expectedModCount)
throw new ConcurrentModificationException();
next = successor(e);
lastReturned = e;
return e;
}
final TreeMap.Entry<K,V> prevEntry() {
TreeMap.Entry<K,V> e = next;
if (e == null || e.key == fenceKey) //多了判断 next 的键不是栅栏键
throw new NoSuchElementException();
if (m.modCount != expectedModCount)
throw new ConcurrentModificationException();
next = predecessor(e);
lastReturned = e;
return e;
}
final void removeAscending() {
if (lastReturned == null)
throw new IllegalStateException();
if (m.modCount != expectedModCount)
throw new ConcurrentModificationException();
// 被删除的条目s被它们的 successors 替换了
if (lastReturned.left != null && lastReturned.right != null)
next = lastReturned;
m.deleteEntry(lastReturned);
lastReturned = null;
expectedModCount = m.modCount;
}
final void removeDescending() {
if (lastReturned == null)
throw new IllegalStateException();
if (m.modCount != expectedModCount)
throw new ConcurrentModificationException();
m.deleteEntry(lastReturned);
lastReturned = null;
expectedModCount = m.modCount;
}
}
//子映射条目迭代器
final class SubMapEntryIterator extends SubMapIterator<Map.Entry<K,V>> {
SubMapEntryIterator(TreeMap.Entry<K,V> first,
TreeMap.Entry<K,V> fence) {
super(first, fence);
}
public Map.Entry<K,V> next() {
return nextEntry();
}
public void remove() {
removeAscending();
}
}
//降序子映射条目迭代器
final class DescendingSubMapEntryIterator extends SubMapIterator<Map.Entry<K,V>> {
DescendingSubMapEntryIterator(TreeMap.Entry<K,V> last,
TreeMap.Entry<K,V> fence) {
super(last, fence);
}
public Map.Entry<K,V> next() {
return prevEntry();
}
public void remove() {
removeDescending();
}
}
//子映射键迭代器,实现了作为 KeySpliterator 支持的最小并行迭代器
final class SubMapKeyIterator extends SubMapIterator<K>
implements Spliterator<K> {
SubMapKeyIterator(TreeMap.Entry<K,V> first,
TreeMap.Entry<K,V> fence) {
super(first, fence);
}
public K next() {
return nextEntry().key;
}
public void remove() {
removeAscending();
}
public Spliterator<K> trySplit() {
return null;
}
public void forEachRemaining(Consumer<? super K> action) {
while (hasNext())
action.accept(next());
}
public boolean tryAdvance(Consumer<? super K> action) {
if (hasNext()) {
action.accept(next());
return true;
}
return false;
}
public long estimateSize() {
return Long.MAX_VALUE;
}
public int characteristics() {
return Spliterator.DISTINCT | Spliterator.ORDERED |
Spliterator.SORTED;
}
public final Comparator<? super K> getComparator() {
return NavigableSubMap.this.comparator();
}
}
//降序子映射键迭代器
final class DescendingSubMapKeyIterator extends SubMapIterator<K>
implements Spliterator<K> {
DescendingSubMapKeyIterator(TreeMap.Entry<K,V> last,
TreeMap.Entry<K,V> fence) {
super(last, fence);
}
public K next() {
return prevEntry().key;
}
public void remove() {
removeDescending();
}
public Spliterator<K> trySplit() {
return null;
}
public void forEachRemaining(Consumer<? super K> action) {
while (hasNext())
action.accept(next());
}
public boolean tryAdvance(Consumer<? super K> action) {
if (hasNext()) {
action.accept(next());
return true;
}
return false;
}
public long estimateSize() {
return Long.MAX_VALUE;
}
public int characteristics() {
return Spliterator.DISTINCT | Spliterator.ORDERED;
}
}
}
/**
* @serial include
*/
//升序子映射类继承自 NavigableSubMap
static final class AscendingSubMap<K,V> extends NavigableSubMap<K,V> {
private static final long serialVersionUID = 912986545866124060L;
AscendingSubMap(TreeMap<K,V> m,
boolean fromStart, K lo, boolean loInclusive,
boolean toEnd, K hi, boolean hiInclusive) {
super(m, fromStart, lo, loInclusive, toEnd, hi, hiInclusive);
}
public Comparator<? super K> comparator() {
return m.comparator();
}
public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive) {
if (!inRange(fromKey, fromInclusive))
throw new IllegalArgumentException("fromKey out of range");
if (!inRange(toKey, toInclusive))
throw new IllegalArgumentException("toKey out of range");
return new AscendingSubMap<>(m,
false, fromKey, fromInclusive,
false, toKey, toInclusive);
}
public NavigableMap<K,V> headMap(K toKey, boolean inclusive) {
if (!inRange(toKey, inclusive))
throw new IllegalArgumentException("toKey out of range");
return new AscendingSubMap<>(m,
fromStart, lo, loInclusive,
false, toKey, inclusive);
}
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive) {
if (!inRange(fromKey, inclusive))
throw new IllegalArgumentException("fromKey out of range");
return new AscendingSubMap<>(m,
false, fromKey, inclusive,
toEnd, hi, hiInclusive);
}
public NavigableMap<K,V> descendingMap() {
NavigableMap<K,V> mv = descendingMapView;
return (mv != null) ? mv :
(descendingMapView =
new DescendingSubMap<>(m,
fromStart, lo, loInclusive,
toEnd, hi, hiInclusive));
}
Iterator<K> keyIterator() {
return new SubMapKeyIterator(absLowest(), absHighFence());
}
Spliterator<K> keySpliterator() {
return new SubMapKeyIterator(absLowest(), absHighFence());
}
Iterator<K> descendingKeyIterator() {
return new DescendingSubMapKeyIterator(absHighest(), absLowFence());
}
final class AscendingEntrySetView extends EntrySetView {
public Iterator<Map.Entry<K,V>> iterator() {
return new SubMapEntryIterator(absLowest(), absHighFence());
}
}
public Set<Map.Entry<K,V>> entrySet() {
EntrySetView es = entrySetView;
return (es != null) ? es : (entrySetView = new AscendingEntrySetView());
}
TreeMap.Entry<K,V> subLowest() { return absLowest(); }
TreeMap.Entry<K,V> subHighest() { return absHighest(); }
TreeMap.Entry<K,V> subCeiling(K key) { return absCeiling(key); }
TreeMap.Entry<K,V> subHigher(K key) { return absHigher(key); }
TreeMap.Entry<K,V> subFloor(K key) { return absFloor(key); }
TreeMap.Entry<K,V> subLower(K key) { return absLower(key); }
}
/**
* @serial include
*/
//降序子映射类继承自 NavigableSubMap
static final class DescendingSubMap<K,V> extends NavigableSubMap<K,V> {
private static final long serialVersionUID = 912986545866120460L;
DescendingSubMap(TreeMap<K,V> m,
boolean fromStart, K lo, boolean loInclusive,
boolean toEnd, K hi, boolean hiInclusive) {
super(m, fromStart, lo, loInclusive, toEnd, hi, hiInclusive);
}
private final Comparator<? super K> reverseComparator =
Collections.reverseOrder(m.comparator);
public Comparator<? super K> comparator() {
return reverseComparator;
}
public NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive) {
if (!inRange(fromKey, fromInclusive))
throw new IllegalArgumentException("fromKey out of range");
if (!inRange(toKey, toInclusive))
throw new IllegalArgumentException("toKey out of range");
return new DescendingSubMap<>(m,
false, toKey, toInclusive,
false, fromKey, fromInclusive);
}
public NavigableMap<K,V> headMap(K toKey, boolean inclusive) {
if (!inRange(toKey, inclusive))
throw new IllegalArgumentException("toKey out of range");
return new DescendingSubMap<>(m,
false, toKey, inclusive,
toEnd, hi, hiInclusive);
}
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive) {
if (!inRange(fromKey, inclusive))
throw new IllegalArgumentException("fromKey out of range");
return new DescendingSubMap<>(m,
fromStart, lo, loInclusive,
false, fromKey, inclusive);
}
public NavigableMap<K,V> descendingMap() {
NavigableMap<K,V> mv = descendingMapView;
return (mv != null) ? mv :
(descendingMapView =
new AscendingSubMap<>(m,
fromStart, lo, loInclusive,
toEnd, hi, hiInclusive));
}
Iterator<K> keyIterator() {
return new DescendingSubMapKeyIterator(absHighest(), absLowFence());
}
Spliterator<K> keySpliterator() {
return new DescendingSubMapKeyIterator(absHighest(), absLowFence());
}
Iterator<K> descendingKeyIterator() {
return new SubMapKeyIterator(absLowest(), absHighFence());
}
final class DescendingEntrySetView extends EntrySetView {
public Iterator<Map.Entry<K,V>> iterator() {
return new DescendingSubMapEntryIterator(absHighest(), absLowFence());
}
}
public Set<Map.Entry<K,V>> entrySet() {
EntrySetView es = entrySetView;
return (es != null) ? es : (entrySetView = new DescendingEntrySetView());
}
TreeMap.Entry<K,V> subLowest() { return absHighest(); }
TreeMap.Entry<K,V> subHighest() { return absLowest(); }
TreeMap.Entry<K,V> subCeiling(K key) { return absFloor(key); }
TreeMap.Entry<K,V> subHigher(K key) { return absLower(key); }
TreeMap.Entry<K,V> subFloor(K key) { return absCeiling(key); }
TreeMap.Entry<K,V> subLower(K key) { return absHigher(key); }
}
/**
* 此类的存在只是为了与不支持 NavigableMap 的早期版本的 TreeMap 序列化兼容。也就是一个适配器。它
* 将一个旧版本的 SubMap 转化成一个新版本的 AscendingSubMap。这个类永远不被用作他用。
*
* @serial include
*/
private class SubMap extends AbstractMap<K,V>
implements SortedMap<K,V>, java.io.Serializable {
private static final long serialVersionUID = -6520786458950516097L;
private boolean fromStart = false, toEnd = false;
private K fromKey, toKey;
private Object readResolve() {
return new AscendingSubMap<>(TreeMap.this,
fromStart, fromKey, true,
toEnd, toKey, false);
}
public Set<Map.Entry<K,V>> entrySet() { throw new InternalError(); }
public K lastKey() { throw new InternalError(); }
public K firstKey() { throw new InternalError(); }
public SortedMap<K,V> subMap(K fromKey, K toKey) { throw new InternalError(); }
public SortedMap<K,V> headMap(K toKey) { throw new InternalError(); }
public SortedMap<K,V> tailMap(K fromKey) { throw new InternalError(); }
public Comparator<? super K> comparator() { throw new InternalError(); }
}
// 红黑算法
private static final boolean RED = false;
private static final boolean BLACK = true;
/**
* Tree 中的 Node。作为一种手段翻倍来将键值对传回给用户(查看 Map.Entry)。
*/
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
/**
* 使用指定键,值和父树,和 {@code null} 子树链接,和 BLACK 色建立一个新的细胞。
*/
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
/**
* 返回键。
*/
public K getKey() {
return key;
}
/**
* 返回与键关联的值。
*/
public V getValue() {
return value;
}
/**
* 使用指定值替换键关联的当前值。
*/
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return valEquals(key,e.getKey()) && valEquals(value,e.getValue());
}
public int hashCode() {
int keyHash = (key==null ? 0 : key.hashCode());
int valueHash = (value==null ? 0 : value.hashCode());
return keyHash ^ valueHash;
}
public String toString() {
return key + "=" + value;
}
}
/**
* 返回 TreeMpa 中的第一个条目(根据 TreeMap 的键排序功能)。如果这个 TreeMap 是空的,返回
* null。
*/
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p; //找到最左子树
}
/**
* 返回 TreeMpa 中的最后一个条目(根据 TreeMap 的键排序功能)。如果这个 TreeMap 是空的,返回
* null。
*/
final Entry<K,V> getLastEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.right != null)
p = p.right;
return p; //找到最右子树
}
/**
* 返回指定条目的 successor,或者如果没有(这样的 successor)则返回 null。
*/
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.right != null) {
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
/**
* 返回指定条目的 predecessor,或者如果没有(这样的 predecessor)则返回 null。
*/
static <K,V> Entry<K,V> predecessor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.left != null) {
Entry<K,V> p = t.left;
while (p.right != null)
p = p.right;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.left) {
ch = p;
p = p.parent;
}
return p;
}
}
/**
* 平衡算法
*
* 在插入和删除过程中的重新平衡实现s与 CLR 版本有些许不同。我们使用一个 accessors 的 set 来正确地
* 处理 null 而不是使用虚拟的 nilnodes。它们被用来避免在主要算法中混乱的 nulless 检查。
* (Nullable 设计模式)
*/
private static <K,V> boolean colorOf(Entry<K,V> p) {
return (p == null ? BLACK : p.color);
}
private static <K,V> Entry<K,V> parentOf(Entry<K,V> p) {
return (p == null ? null: p.parent);
}
private static <K,V> void setColor(Entry<K,V> p, boolean c) {
if (p != null)
p.color = c;
}
private static <K,V> Entry<K,V> leftOf(Entry<K,V> p) {
return (p == null) ? null: p.left;
}
private static <K,V> Entry<K,V> rightOf(Entry<K,V> p) {
return (p == null) ? null: p.right;
}
/** 来自 CLR,左旋 */
private void rotateLeft(Entry<K,V> p) {
if (p != null) {
Entry<K,V> r = p.right;
p.right = r.left;
if (r.left != null)
r.left.parent = p;
r.parent = p.parent;
if (p.parent == null)
root = r;
else if (p.parent.left == p)
p.parent.left = r;
else
p.parent.right = r;
r.left = p;
p.parent = r;
}
}
/** 来自 CLR,右旋 */
private void rotateRight(Entry<K,V> p) {
if (p != null) {
Entry<K,V> l = p.left;
p.left = l.right;
if (l.right != null) l.right.parent = p;
l.parent = p.parent;
if (p.parent == null)
root = l;
else if (p.parent.right == p)
p.parent.right = l;
else p.parent.left = l;
l.right = p;
p.parent = l;
}
}
/** 来自 CLR */
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
/**
* 删除 node p,然后重新平衡 tree。
*/
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// 如果是严格内部的,拷贝 successor 的元素给 p 并且使 p 指向 successor。
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p 有两颗子树
// 如果替换 node 存在,开始修正。
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// 将替换链接到 parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// 将链接s设为 null 这样它们就可以通过 fixAfterDeletion 使用。
p.left = p.right = p.parent = null;
// 修正 replacement
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // 如果是仅有的 node 就返回。
root = null;
} else { // 没有子树。使用自身作为虚替换并且断开链接。
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
/** 来自 CLR */
private void fixAfterDeletion(Entry<K,V> x) {
while (x != root && colorOf(x) == BLACK) {
if (x == leftOf(parentOf(x))) {
Entry<K,V> sib = rightOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateLeft(parentOf(x));
sib = rightOf(parentOf(x));
}
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK);
setColor(sib, RED);
rotateRight(sib);
sib = rightOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(rightOf(sib), BLACK);
rotateLeft(parentOf(x));
x = root;
}
} else { // 对称的
Entry<K,V> sib = leftOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateRight(parentOf(x));
sib = leftOf(parentOf(x));
}
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(leftOf(sib)) == BLACK) {
setColor(rightOf(sib), BLACK);
setColor(sib, RED);
rotateLeft(sib);
sib = leftOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(leftOf(sib), BLACK);
rotateRight(parentOf(x));
x = root;
}
}
}
setColor(x, BLACK);
}
private static final long serialVersionUID = 919286545866124006L;
/**
* 序列化写
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// 写出 Comparator 和其他
s.defaultWriteObject();
// 写出长度
s.writeInt(size);
// 写出键和值
for (Iterator<Map.Entry<K,V>> i = entrySet().iterator(); i.hasNext(); ) {
Map.Entry<K,V> e = i.next();
s.writeObject(e.getKey());
s.writeObject(e.getValue());
}
}
/**
* 序列化读
*/
private void readObject(final java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// 写入 Comparator 和其他
s.defaultReadObject();
// 写如 size
int size = s.readInt();
buildFromSorted(size, null, s, null);
}
/** 只在 TreeSet.readObject 被调用*/
void readTreeSet(int size, java.io.ObjectInputStream s, V defaultVal)
throws java.io.IOException, ClassNotFoundException {
buildFromSorted(size, null, s, defaultVal);
}
/** 只在 TreeSet.addAll 被调用*/
void addAllForTreeSet(SortedSet<? extends K> set, V defaultVal) {
try {
buildFromSorted(set.size(), set.iterator(), null, defaultVal);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
/**
* 被排序的数据的线性时间 tree 建立算法。可以从迭代器或者流中接受键和/或值。这导致太多参数,但是看上
* 去比可选择的更好。这个方法接受的四种格式是:
*
* 1) 一个 Map.Entries 的迭代器 (it != null, defaultVal == null).
* 2) 一个 keys 的迭代器 (it != null, defaultVal != null).
* 3) 一个轮流序列化了 keys and values 的流。
* (it == null, defaultVal == null).
* 4) 一个序列化了键s的流。 (it == null, defaultVal != null).
*
* 它假设这个 TreeMap 的 comparator 已经在调用这个方法前被设置好了。
*/
private void buildFromSorted(int size, Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
this.size = size;
root = buildFromSorted(0, 0, size-1, computeRedLevel(size),
it, str, defaultVal);
}
/**
* 真正完成之前那个方法的工作的递归的"帮助方法"。相同名称的参数具有相同的定义。额外的参数s在下方文档
* 中。它假设这个 TreeMap 的 comparator 和长度类属性在调用这个方法之前都被设置好了。(它忽略这两个
* 类属性。)
*/
@SuppressWarnings("unchecked")
private final Entry<K,V> buildFromSorted(int level, int lo, int hi,
int redLevel,
Iterator<?> it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
/*
* 策略:根是最中间的元素。为了到达它,我们不得不先递归构造整个左子树,以此来抓去它的全部元素。我
* 们然后可以接着做右子树。
*
* lo 和 hi 元素s是当前 subtree 从迭代器或者流中离开的最小和最大的位置s。它们不是真正被标记为
* 值了,我们只是按顺序操作,保证内容s以相应的顺序被提取。
*/
if (hi < lo) return null;
int mid = (lo + hi) >>> 1;
Entry<K,V> left = null;
if (lo < mid)
left = buildFromSorted(level+1, lo, mid - 1, redLevel,
it, str, defaultVal);
// 从迭代器或者流中提取键和/或值
K key;
V value;
if (it != null) {
if (defaultVal==null) {
Map.Entry<?,?> entry = (Map.Entry<?,?>)it.next();
key = (K)entry.getKey();
value = (V)entry.getValue();
} else {
key = (K)it.next();
value = defaultVal;
}
} else { // 使用流
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
}
Entry<K,V> middle = new Entry<>(key, value, null);
// 在未满的最底部的 RED nodes
if (level == redLevel)
middle.color = RED;
if (left != null) {
middle.left = left;
left.parent = middle;
}
if (mid < hi) {
Entry<K,V> right = buildFromSorted(level+1, mid+1, hi, redLevel,
it, str, defaultVal);
middle.right = right;
right.parent = middle;
}
return middle;
}
/**
* 知道找到所有 nodes 都是 BLACK 的 level。这是由 buildTree 生产出的最后一个 '满' 级别的完整二
* 叉树。剩下的 nodes 被染成 RED。(这使得一个 '棒的' 颜色分派工作s set wrt 未来的插入s。这一段不
* 清楚该如何翻译。。)这个级别数是通过找到到达零节点所需的拆分数来计算的。)(答案是 ~lg(N),但是在
* 任何情况下必须被相同的快速 O(lg(N)) 循环计算。)
*/
private static int computeRedLevel(int sz) {
int level = 0;
for (int m = sz - 1; m >= 0; m = m / 2 - 1)
level++;
return level;
}
/**
* 目前我们只对完整的 map 支持以并行迭代器为基础的版本,以降序的形式,不然的话依赖于默认s因为对于子映
* 射s的长度估算会控制(性能)消耗。为了键s视图s检查的类型测试s不是很棒但是可以避免扰乱存在的类构造器
* s。如果这个返回 null,调用者必须使用简单的默认并写迭代器。
*/
static <K> Spliterator<K> keySpliteratorFor(NavigableMap<K,?> m) {
if (m instanceof TreeMap) {
@SuppressWarnings("unchecked") TreeMap<K,Object> t =
(TreeMap<K,Object>) m;
return t.keySpliterator();
}
if (m instanceof DescendingSubMap) {
@SuppressWarnings("unchecked") DescendingSubMap<K,?> dm =
(DescendingSubMap<K,?>) m;
TreeMap<K,?> tm = dm.m;
if (dm == tm.descendingMap) {
@SuppressWarnings("unchecked") TreeMap<K,Object> t =
(TreeMap<K,Object>) tm;
return t.descendingKeySpliterator();
}
}
@SuppressWarnings("unchecked") NavigableSubMap<K,?> sm =
(NavigableSubMap<K,?>) m;
return sm.keySpliterator();
}
final Spliterator<K> keySpliterator() {
return new KeySpliterator<K,V>(this, null, null, 0, -1, 0);
}
final Spliterator<K> descendingKeySpliterator() {
return new DescendingKeySpliterator<K,V>(this, null, null, 0, -2, 0);
}
/**
* 并写迭代器s的基类。迭代操作开始与一个指定的起源并且继续指导但是不包含一个指定栅栏(或者 null 的话
* 就是到最后)。在最高级别,对于升序情况,第一个 split 使用根作为左栅栏/有起源。从那里开始,右手边s
* 的 splits 用它的左子树替换当前的栅栏,也作为 split-off 并行迭代器的起源。左手边s是对称的。降序
* 版本s用最后并且于升序相反的 split 规则s作为起源。这个基类不对方向性作出承诺,或者最高级别的并行得
* 带起是否涵盖了整棵树。这意味着真正的 split 机制其实在子类s中。一些子类 trySplit 方法s是相同的
* (除了对于运行时类型s),但是不是很好的因子化的。
*
* 目前,子类版本s只对完整的 map 存在(包括通过它的 descendingMap 降序的降序键s)。其他的是可以但
* 是目前不值得的因为子映射s需要 O(n) 计算量来决定长度,这本质上限制了使用自定义并行迭代器而不是默认
* 机制的潜在的加速s的可能性。
*
* 为了助推器初始化,外部构造器s使用否定的长度估算:对于升序使用 -1,对于降序使用 -2。
*/
static class TreeMapSpliterator<K,V> {
final TreeMap<K,V> tree;
TreeMap.Entry<K,V> current; // 横穿,对范围内的第一个 node 初始化
TreeMap.Entry<K,V> fence; // 一个超过最后的,或者 null
int side; // 0:最高, -1:是一个左 split, +1:右
int est; // 长度估算(只在最高级别准确)
int expectedModCount; // 用作 CME 检查
TreeMapSpliterator(TreeMap<K,V> tree,
TreeMap.Entry<K,V> origin, TreeMap.Entry<K,V> fence,
int side, int est, int expectedModCount) {
this.tree = tree;
this.current = origin;
this.fence = fence;
this.side = side;
this.est = est;
this.expectedModCount = expectedModCount;
}
final int getEstimate() { // 强制初始化
int s; TreeMap<K,V> t;
if ((s = est) < 0) {
if ((t = tree) != null) {
current = (s == -1) ? t.getFirstEntry() : t.getLastEntry();
s = est = t.size;
expectedModCount = t.modCount;
}
else
s = est = 0;
}
return s;
}
public final long estimateSize() {
return (long)getEstimate();
}
}
static final class KeySpliterator<K,V>
extends TreeMapSpliterator<K,V>
implements Spliterator<K> {
KeySpliterator(TreeMap<K,V> tree,
TreeMap.Entry<K,V> origin, TreeMap.Entry<K,V> fence,
int side, int est, int expectedModCount) {
super(tree, origin, fence, side, est, expectedModCount);
}
public KeySpliterator<K,V> trySplit() {
if (est < 0)
getEstimate(); // 强制初始化
int d = side;
TreeMap.Entry<K,V> e = current, f = fence,
s = ((e == null || e == f) ? null : // 空的
(d == 0) ? tree.root : // 曾经是最高
(d > 0) ? e.right : // 曾经是右
(d < 0 && f != null) ? f.left : // 曾经是左
null);
if (s != null && s != e && s != f &&
tree.compare(e.key, s.key) < 0) { // e 还没有超过 s
side = 1;
return new KeySpliterator<>
(tree, e, current = s, -1, est >>>= 1, expectedModCount);
}
return null;
}
public void forEachRemaining(Consumer<? super K> action) {
if (action == null)
throw new NullPointerException();
if (est < 0)
getEstimate(); // 强制初始化
TreeMap.Entry<K,V> f = fence, e, p, pl;
if ((e = current) != null && e != f) {
current = f; // 用完
do {
action.accept(e.key);
if ((p = e.right) != null) {
while ((pl = p.left) != null)
p = pl;
}
else {
while ((p = e.parent) != null && e == p.right)
e = p;
}
} while ((e = p) != null && e != f);
if (tree.modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super K> action) {
TreeMap.Entry<K,V> e;
if (action == null)
throw new NullPointerException();
if (est < 0)
getEstimate(); // 强制初始化
if ((e = current) == null || e == fence)
return false;
current = successor(e);
action.accept(e.key);
if (tree.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
public int characteristics() {
return (side == 0 ? Spliterator.SIZED : 0) |
Spliterator.DISTINCT | Spliterator.SORTED | Spliterator.ORDERED;
}
public final Comparator<? super K> getComparator() {
return tree.comparator;
}
}
static final class DescendingKeySpliterator<K,V>
extends TreeMapSpliterator<K,V>
implements Spliterator<K> {
DescendingKeySpliterator(TreeMap<K,V> tree,
TreeMap.Entry<K,V> origin, TreeMap.Entry<K,V> fence,
int side, int est, int expectedModCount) {
super(tree, origin, fence, side, est, expectedModCount);
}
public DescendingKeySpliterator<K,V> trySplit() {
if (est < 0)
getEstimate(); // 强制初始化
int d = side;
TreeMap.Entry<K,V> e = current, f = fence,
s = ((e == null || e == f) ? null : // 空
(d == 0) ? tree.root : // 曾最高
(d < 0) ? e.left : // 曾左
(d > 0 && f != null) ? f.right : // 曾右
null);
if (s != null && s != e && s != f &&
tree.compare(e.key, s.key) > 0) { // e 还没有超过 s
side = 1;
return new DescendingKeySpliterator<>
(tree, e, current = s, -1, est >>>= 1, expectedModCount);
}
return null;
}
public void forEachRemaining(Consumer<? super K> action) {
if (action == null)
throw new NullPointerException();
if (est < 0)
getEstimate(); // 强制初始化
TreeMap.Entry<K,V> f = fence, e, p, pr;
if ((e = current) != null && e != f) {
current = f; // 用完
do {
action.accept(e.key);
if ((p = e.left) != null) {
while ((pr = p.right) != null)
p = pr;
}
else {
while ((p = e.parent) != null && e == p.left)
e = p;
}
} while ((e = p) != null && e != f);
if (tree.modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super K> action) {
TreeMap.Entry<K,V> e;
if (action == null)
throw new NullPointerException();
if (est < 0)
getEstimate(); // 强制初始化
if ((e = current) == null || e == fence)
return false;
current = predecessor(e);
action.accept(e.key);
if (tree.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
public int characteristics() {
return (side == 0 ? Spliterator.SIZED : 0) |
Spliterator.DISTINCT | Spliterator.ORDERED;
}
}
static final class ValueSpliterator<K,V>
extends TreeMapSpliterator<K,V>
implements Spliterator<V> {
ValueSpliterator(TreeMap<K,V> tree,
TreeMap.Entry<K,V> origin, TreeMap.Entry<K,V> fence,
int side, int est, int expectedModCount) {
super(tree, origin, fence, side, est, expectedModCount);
}
public ValueSpliterator<K,V> trySplit() {
if (est < 0)
getEstimate(); // 强制初始化
int d = side;
TreeMap.Entry<K,V> e = current, f = fence,
s = ((e == null || e == f) ? null : // 空
(d == 0) ? tree.root : // 曾最高
(d > 0) ? e.right : // 曾右
(d < 0 && f != null) ? f.left : // 曾左
null);
if (s != null && s != e && s != f &&
tree.compare(e.key, s.key) < 0) { // e 还没有超过 s
side = 1;
return new ValueSpliterator<>
(tree, e, current = s, -1, est >>>= 1, expectedModCount);
}
return null;
}
public void forEachRemaining(Consumer<? super V> action) {
if (action == null)
throw new NullPointerException();
if (est < 0)
getEstimate(); // 强制初始化
TreeMap.Entry<K,V> f = fence, e, p, pl;
if ((e = current) != null && e != f) {
current = f; // 用完
do {
action.accept(e.value);
if ((p = e.right) != null) {
while ((pl = p.left) != null)
p = pl;
}
else {
while ((p = e.parent) != null && e == p.right)
e = p;
}
} while ((e = p) != null && e != f);
if (tree.modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super V> action) {
TreeMap.Entry<K,V> e;
if (action == null)
throw new NullPointerException();
if (est < 0)
getEstimate(); // 强制初始化
if ((e = current) == null || e == fence)
return false;
current = successor(e);
action.accept(e.value);
if (tree.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
public int characteristics() {
return (side == 0 ? Spliterator.SIZED : 0) | Spliterator.ORDERED;
}
}
static final class EntrySpliterator<K,V>
extends TreeMapSpliterator<K,V>
implements Spliterator<Map.Entry<K,V>> {
EntrySpliterator(TreeMap<K,V> tree,
TreeMap.Entry<K,V> origin, TreeMap.Entry<K,V> fence,
int side, int est, int expectedModCount) {
super(tree, origin, fence, side, est, expectedModCount);
}
public EntrySpliterator<K,V> trySplit() {
if (est < 0)
getEstimate(); // 强制初始化
int d = side;
TreeMap.Entry<K,V> e = current, f = fence,
s = ((e == null || e == f) ? null : // 空
(d == 0) ? tree.root : // 曾最高
(d > 0) ? e.right : // 曾右
(d < 0 && f != null) ? f.left : // 曾左
null);
if (s != null && s != e && s != f &&
tree.compare(e.key, s.key) < 0) { // e 还没有超过 s
side = 1;
return new EntrySpliterator<>
(tree, e, current = s, -1, est >>>= 1, expectedModCount);
}
return null;
}
public void forEachRemaining(Consumer<? super Map.Entry<K, V>> action) {
if (action == null)
throw new NullPointerException();
if (est < 0)
getEstimate(); // 强制初始化
TreeMap.Entry<K,V> f = fence, e, p, pl;
if ((e = current) != null && e != f) {
current = f; // 用完
do {
action.accept(e);
if ((p = e.right) != null) {
while ((pl = p.left) != null)
p = pl;
}
else {
while ((p = e.parent) != null && e == p.right)
e = p;
}
} while ((e = p) != null && e != f);
if (tree.modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
public boolean tryAdvance(Consumer<? super Map.Entry<K,V>> action) {
TreeMap.Entry<K,V> e;
if (action == null)
throw new NullPointerException();
if (est < 0)
getEstimate(); // 强制初始化
if ((e = current) == null || e == fence)
return false;
current = successor(e);
action.accept(e);
if (tree.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
public int characteristics() {
return (side == 0 ? Spliterator.SIZED : 0) |
Spliterator.DISTINCT | Spliterator.SORTED | Spliterator.ORDERED;
}
@Override
public Comparator<Map.Entry<K, V>> getComparator() {
// 改写或者创建一个基于键的 comparator
if (tree.comparator != null) {
return Map.Entry.comparingByKey(tree.comparator);
}
else {
return (Comparator<Map.Entry<K, V>> & Serializable) (e1, e2) -> {
@SuppressWarnings("unchecked")
Comparable<? super K> k1 = (Comparable<? super K>) e1.getKey();
return k1.compareTo(e2.getKey());
};
}
}
}
}
1、由 TreeMap 的源码可以看到,TreeMap 的源码相当复杂,不仅存在类似于 Map 中的 KeySet,Values 和 EntrySet,它们各自的串行和并行迭代器(KeySet 的迭代器还包括 DescendingKeyIterator)还有可导航的 NavigableSubMap,NavigableSubMap 中有自己的升序、降序迭代器。
2、排序的方式是通过 Comparable 的 compareTo 方法或者指定 Comparator 的 compare 方法。
3、导航主要是针对键而言的,KeySet 类是静态的(可能是因为它需要扩展许多导航相关的方法),依靠持有一个 NavigableMap 的实例来使 TreedMap 的 KeySet 也拥有导航功能。
4、由于是红黑树形结构,迭代的方式不再是向前/向后,而是找到比当前更大的最小条目(更大意味着右子树,最小意味着右子树的最左节点,没有右子树的话向上找父树节点比自己小的第一个)或者比当前更小的最大条目(更小意味着左子树,最大意味着左子树的最右节点,没有左子树的话向上找父树节点比自己大的第一个)。
5、一般获取的条目都是 SimpleImmutableEntry,也就是在 AbstractMap 中将 setValue 定义为抛出 UnsupportedOperationException 的异常的不可操作方法的条目对象(而 HashMap 的 Node 是可以 setValue 的)。
6、返回子映射(子健)集主要有子/头/尾集三种,对于开闭区间都有支持。
7、在可导航的子映射类中加入了对于范围的判断来确保在 TreeMap 中承诺的不超出范围检查。
8、通过 compare(a, a) 做类型检查。
9、树根在 put 方法和 remove 方法中确定,如果 root 不存在直接生成新的树根,否则调用 fixAfterInsertion/fixAfterDeletion 方法再元素插入/删除后进行树调整并对 root 赋值。
同样这里没有深究 TreeMap 中对于红黑树的实现。
本篇对 TreeMap 进行了介绍与分析,由于 ConcurrentHashMap 属于 JUC 中的一部分,在这里先不做介绍,在 并发编程篇 中再做介绍,而 HashTable 是一个不再建议被使用的类,所以这里也不再介绍。对于 Java 8 中另一种经典数据结构 Queue 在介绍 LinkedList 的时候稍有提到(LinkedList 实现了 Deque 双端队列接口,而 Deque 继承自 Queue 队列接口),其他 Queue 接口的实现类大都分布在 JUC 包中,这里先不做介绍,在 并发编程篇 中再做介绍。WeakHashMap 牵涉到引用类型知识,将在 Java 引用篇 中进行介绍。
接下来三篇将对剩余三个比较重要的类,EnumSet,EnumMap, ArrayDeque。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









