




- 多线程:threading,利用CPU和IO可以通知执行的原理,让CPU不再干巴巴等待IO完成
- 多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务。
- 异步IO:asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
- 使用Lock对资源加锁,防止冲突访问
- 使用Queue实现不同线程/进程之间的数据通信,实现生产者,消费者模式
- 使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果
- 实现subprocess启动外部程序的进程,并进行输入输出交互
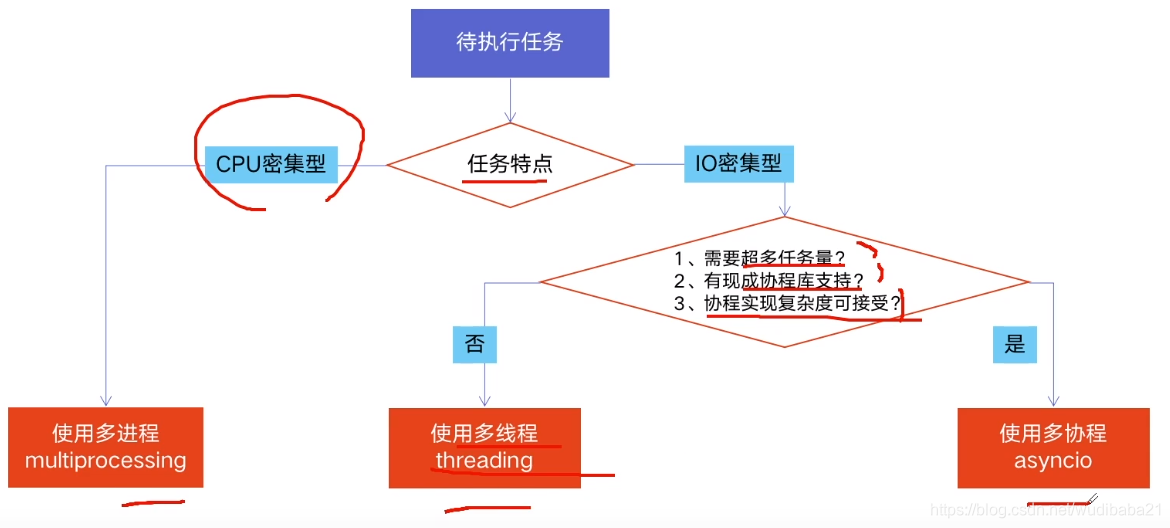
什么是CPU密集计算,什么是IO密集计算
cpu密集型:I/O在很短时间可以完成,需要大量的计算和处理,CPU占用率高,比如:压缩解压缩
I/O:大部分时间都在读内存操作,文件处理程序,读取数据库
多进程多线程多协程对比
一个进程中可以启动多个线程,一个线程中可以启动多个协程
进程是资源分配的最小单位
1、进程
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
2、线程
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
3、协程
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
多进程:
- 优点:可以利用多核CPU并行计算
- 缺点:占用资源最多、可启动数目比线程少
- 适用于:CPU密集型计算
多线程:
- 优点:相比进程,更轻量级、占用资源少
- 缺点:
- 相比进程:多线程只能并发执行,不能利用多CPU,只能使用单个CPU
- 相比协程:启动数目有限制,占用内存资源,有线程切换开销
多协程:
优点:内存开支最小、启动协程数量最多
缺点:支持 的库有限制,代码实现复杂
python速度慢的原因
- 动态类型语言,边解释边执行
- 无法利用多核CPU并发执行,GIL锁
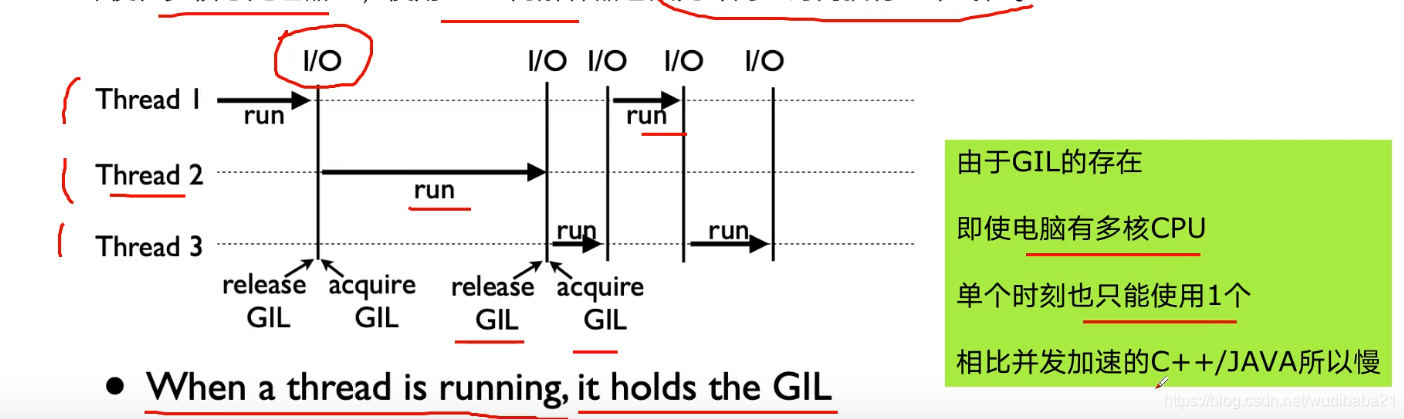
GIL
全局解释器锁:用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行
即使在多核心处理器上,使用GIL的解释器也只能允许同一时间执行一个线程


python创建多线程
 多线程及单线程实现及比较
多线程及单线程实现及比较
urls = [f'https://www.cnblogs.com/#p{page}' for page in range(2,50)]
def craw(url):
import requests
r = requests.get(url)
print(url,len(r.text))
def single_thread():
for url in urls:
craw(url)
def multi_thread():
threads = []
for url in urls:
threads.append(threading.Thread(target=craw,args=(url,)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == '__main__':
import time
start = time.time()
single_thread()
end = time.time()
duration= print(end-start)
print(duration)
start = time.time()
multi_thread()
end = time.time()
print(end-start)
多线程数据通信的queue.Queue
queue.Queue可以用于多线程之间的,线程安全的数据通信,而不用使用Lock的
from queue import Queue,LifoQueue
from threading import Thread
queue = LifoQueue()
for i in range(20000):
queue.put(i,False)
def consumer(q:Queue,name:str):
with open(name,'w') as f:
while not q.empty():
a=q.get(False)
f.write("%d\n" % a)
f.close()
tasks = []
l = 2
for i in range(l):
t=Thread(target=consumer,args=[queue,str(i)])
tasks.append(t)
for i in range(l):
tasks[i].start()
使用Lock来保证线程安全
import threading
import time
lock = threading.Lock()
class Account:
def __init__(self,balance):
self.balance=balance
def draw(account,amount):
with lock:
if account.balance>=amount:
time.sleep(1)
print(threading.current_thread().name,"取钱成功")
account.balance-=amount
print(threading.current_thread().name,"余额:",account.balance)
else:
print(threading.current_thread().name,"余额不足")
if __name__ == '__main__':
account=Account(1000)
ta = threading.Thread(name="ta",target=draw,args=(account,800))
tb = threading.Thread(name="tb",target=draw,args=(account,100))
ta.start()
tb.start()
ta.join()
tb.join()线程池
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统的交互。在这种情形下,使用线程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
此外,使用线程池可以有效地控制系统中并发线程的数量。当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致 Python 解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量不超过此数。
线程池的使用
线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor,其中 ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池。
如果使用线程池/进程池来管理并发编程,那么只要将相应的 task 函数提交给线程池/进程池,剩下的事情就由线程池/进程池来搞定。
Exectuor 提供了如下常用方法:
- submit(fn, *args, **kwargs):将 fn 函数提交给线程池。*args 代表传给 fn 函数的参数,*kwargs 代表以关键字参数的形式为 fn 函数传入参数。
- map(func, *iterables, timeout=None, chunksize=1):该函数类似于全局函数 map(func, *iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。
- shutdown(wait=True):关闭线程池。
from concurrent.futures import ThreadPoolExecutor
import threading
import time
# 定义一个准备作为线程任务的函数
def action(max):
my_sum = 0
for i in range(max):
print(threading.current_thread().name + ' ' + str(i))
my_sum += i
return my_sum
# 创建一个包含2条线程的线程池
pool = ThreadPoolExecutor(max_workers=2)
# 向线程池提交一个task, 50会作为action()函数的参数
future1 = pool.submit(action, 50)
# 向线程池再提交一个task, 100会作为action()函数的参数
future2 = pool.submit(action, 100)
# 判断future1代表的任务是否结束
print(future1.done())
time.sleep(3)
# 判断future2代表的任务是否结束
print(future2.done())
# 查看future1代表的任务返回的结果
print(future1.result())
# 查看future2代表的任务返回的结果
print(future2.result())
# 关闭线程池
pool.shutdown()多进程(multiprocess.process)
多进程multiprocessing知识梳理(对比多线程threading)
| 语法条目 | 多线程 | 多进程 |
| 引入模块 | from threading import Thread | from multiprocessing import Process |
| 新建 启动 结束 | | |
| 数据通信 | | |
| 线程安全加锁 | | |
| 池化技术 | | |
代码比较
import time
import math
PRIMES=[112272535095293]*100
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
def is_prime(n):
if n<2:
return False
if n==2:
return True
if n%2==0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3,sqrt_n+1,2):
if n%i==0:
return False
return True
def signal_thread():
for number in PRIMES:
is_prime(number)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime,PRIMES)
def mutli_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime,PRIMES)
if __name__ == '__main__':
start = time.time()
signal_thread()
end = time.time()
print("signal_thread consume:",end-start,"sencods")
start = time.time()
multi_thread()
end = time.time()
print("mult_thread consume:", end - start, "sencods")
start = time.time()
mutli_process()
end = time.time()
print("multi_process consume:", end - start, "sencods")
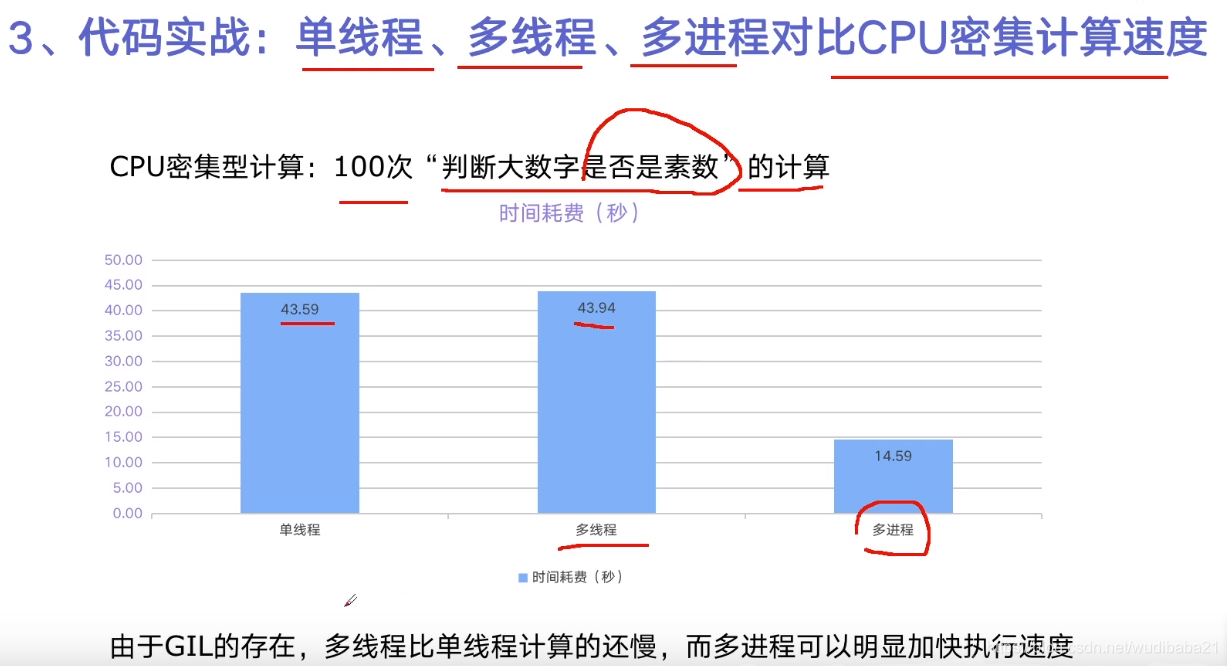
signal_thread consume: 70.89206147193909 sencods
mult_thread consume: 76.76559948921204 sencods
multi_process consume: 32.349082231521606 sencods
异步IO


















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









