






 本文探讨了如何将图像分类中的半监督学习方法Noisy Student Training (NST) 应用于语音识别,利用语音增强技术SpecAugment进行优化。实验表明,在LibriSpeech数据集上,仅用100小时有标签数据,结合大量无标签数据,NST显著降低了WER,展示了其在自动语音识别中的潜力。
本文探讨了如何将图像分类中的半监督学习方法Noisy Student Training (NST) 应用于语音识别,利用语音增强技术SpecAugment进行优化。实验表明,在LibriSpeech数据集上,仅用100小时有标签数据,结合大量无标签数据,NST显著降低了WER,展示了其在自动语音识别中的潜力。
论文:
Improved Noisy Student Training for Automatic Speech Recognition
摘要:
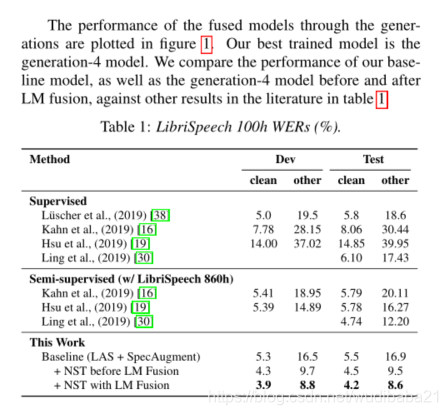
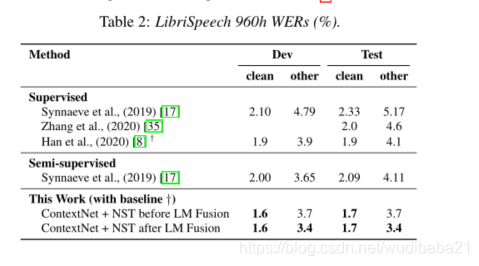
将“noisy student training”这种半监督学习方法应用到语音领域,采用语音增强SpecAugment 来适应和改进这种半监督方法。在LibriSpeech数据集上的效果非常明显,使用100h作为监督训练,其余剩下的作为无监督训练,就能在测试集上获得4.2%/8.6%的WER,加大无监督训练数据集,可以获得1.7%/3.4%的WER刷新了最低错误率。
引言:
将图像分类中了半监督学习方法NST[1]引入到语音识别中。先用未标记数据训练一系列模型,然后通过纯净语料,之前训练的模型作为教师模型,来指导训练学生模型。
引入了以下方法:
- 语音增强方法[2][3](时域频域掩盖)
- 语言模型shallow fusion
-
针对教师网络生成的文本的归一化过滤分数
-
子模块变体来权衡由教师模型生成的token
-
层次训练是有效的,引入层次过滤和分级增强
然后讲了通过这种半监督方法在数据集上所能达到的性能。
相关工作论文举例,讲了半监督学习的发展和好处,对自训练有积极作用。
训练步骤
假设一个标记集为S,未标记集为U,和一个在独立text上训练的语言模型,然后NST模型产生一系列的语音识别模型如下:
- 在有标签数据集上使用语音增强方法训练模型M0
- 将M0和LM模型进行shallow fusion并且评测性能
- 使用融合的模型和未标记数据集U打标签。
- 过滤置信度较低的数据,得到过滤后的标签数据F(M(U))
- 平衡F(M(U))得到数据b*F(M(U))
- 将5中得到的数据和有标签数据混合,使用语音增强训练新的模型
- 使
,跳到步骤二进行新的一轮训练
使用[2]中提出的语音增强方法用在每一步训练,我们采用自适应时间屏蔽[3],其中时间屏蔽的大小与输入话语的长度成线性比例,具体取决于任务。
引入一个过滤公式
平衡生成的标签:这是通过以贪婪的方式优化采样集的标记分布与目标分布之间的KL散度来实现的,其中,按大小为B的批收集句子。通过选择顶部B从句子池中选择每批以成本收益为依据的句子,即通过将句子添加到当前采样成绩单集除以其记号数量,从而减少KL差异。在收集了一批样本并将其添加到样本集之后,将计算组合句子的标记分布与目标分布之间的KL散度,然后对该过程进行迭代。
实验:
语音增强:对于第0代,我们使用两个具有掩码参数(F)27的频率掩码,两个具有掩码参数(T)40的时间掩码和具有扭曲参数(W)40的时间扭曲[2]。在第2代和第4代,我们重新调整了代理任务上的时间掩码参数T(使用LAS-4-1024模型,并根据[2]调度了LB)。用于第0代和第1代,第2代和第3代,第4代和第5代的时间掩蔽参数分别设置为40、80和100。
参考文献:
- Q. Xie, M.-T. Luong, E. Hovy, and Q. V . Le, “Self-training with noisy student improves imagenet classification,” in CVPR, 2020.
- D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk,and Q. V . Le, “Specaugment: A simple data augmentation method for automatic speech recognition,” in Interspeech, 2019.
- D. S. Park, Y. Zhang, C.-C. Chiu, Y. Chen, B. Li, W. Chan, Q. V.Le, and Y. Wu, “Specaugment on large scale datasets,”arXivpreprint arXiv:1912.05533, 2019


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









