



<<<接上一节
查询分析(Query analysis)
到目前为止,我们一直是使用用户的原始输入查询来执行检索。然而,使用模型来生成查询语句具有下面的优势。例如:
-
除了语义搜索之外,我们还可以构建结构化的过滤条件(例如:“查找自 2020 年以来的文档”);
-
模型可以将用户的查询重新优化成更有效的搜索查询,就算是原始查询比较复杂或包含无关内容。
查询分析利用模型将用户的原始输入转换或构建为优化过的搜索查询。我们可以很容易地将查询分析步骤集成到我们的应用中。为了更直观地展示这一点,我们将为向量存储中的文档添加一些元数据。我们会添加一些(人为设定的)文档字段,以便后续可以基于这些字段进行过滤。
total_documents = len(all_splits)
third = total_documents // 3
for i, document in enumerate(all_splits):
if i < third:
document.metadata["section"] = "beginning"
elif i < 2 * third:
document.metadata["section"] = "middle"
else:
document.metadata["section"] = "end"
all_splits[0].metadata
{'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/',
'start_index': 8,
'section': 'beginning'}
我们需要更新向量存储中的文档。这里我们将使用一个简单的InMemoryVectorStore,因为我们将用到它的一些特定功能(例如:元数据过滤)。
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embeddings)
_ = vector_store.add_documents(all_splits)
下面,我们定义Search类为包含一个字符串类型的查询属性(query)和一个section属性
(值可以是"beginning"、"middle" 或 "end"),当然你也可以根据需要自行定义这个结构。
from typing import Literal
from typing_extensions import Annotated
class Search(TypedDict):
"""Search query."""
query: Annotated[str, ..., "Search query to run."]
section: Annotated[
Literal["beginning", "middle", "end"],
...,
"Section to query.",
]
最后,我们在 LangGraph 应用中添加一个步骤,用于根据用户的原始输入生成查询语句:
class State(TypedDict):
question: str
query: Search
context: List[Document]
answer: str
def analyze_query(state: State):
structured_llm = llm.with_structured_output(Search)
query = structured_llm.invoke(state["question"])
return {"query": query}
def retrieve(state: State):
query = state["query"]
retrieved_docs = vector_store.similarity_search(
query["query"],
filter=lambda doc: doc.metadata.get("section") == query["section"],
)
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
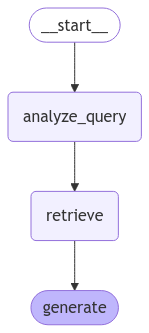
graph_builder = StateGraph(State).add_sequence([analyze_query, retrieve, generate])
graph_builder.add_edge(START, "analyze_query")
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
我们可以通过明确请求获取帖子结尾部分的内容来测试我们的例子。请注意,模型在回答中包含了不同的信息。
for step in graph.stream(
{"question": "What does the end of the post say about Task Decomposition?"},
stream_mode="updates",
):
print(f"{step}\n\n----------------\n")
{'analyze_query': {'query': {'query': 'Task Decomposition', 'section': 'end'}}}
----------------
{'retrieve': {'context': [Document(id='d6cef137-e1e8-4ddc-91dc-b62bd33c6020', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 39221, 'section': 'end'}, page_content='Finite context length: The restricted context capacity limits the inclusion of historical information, detailed instructions, API call context, and responses. The design of the system has to work with this limited communication bandwidth, while mechanisms like self-reflection to learn from past mistakes would benefit a lot from long or infinite context windows. Although vector stores and retrieval can provide access to a larger knowledge pool, their representation power is not as powerful as full attention.\n\n\nChallenges in long-term planning and task decomposition: Planning over a lengthy history and effectively exploring the solution space remain challenging. LLMs struggle to adjust plans when faced with unexpected errors, making them less robust compared to humans who learn from trial and error.'), Document(id='d1834ae1-eb6a-43d7-a023-08dfa5028799', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 39086, 'section': 'end'}, page_content='}\n]\nChallenges#\nAfter going through key ideas and demos of building LLM-centered agents, I start to see a couple common limitations:'), Document(id='ca7f06e4-2c2e-4788-9a81-2418d82213d9', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 32942, 'section': 'end'}, page_content='}\n]\nThen after these clarification, the agent moved into the code writing mode with a different system message.\nSystem message:'), Document(id='1fcc2736-30f4-4ef6-90f2-c64af92118cb', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'start_index': 35127, 'section': 'end'}, page_content='"content": "You will get instructions for code to write.\\nYou will write a very long answer. Make sure that every detail of the architecture is, in the end, implemented as code.\\nMake sure that every detail of the architecture is, in the end, implemented as code.\\n\\nThink step by step and reason yourself to the right decisions to make sure we get it right.\\nYou will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.\\n\\nThen you will output the content of each file including ALL code.\\nEach file must strictly follow a markdown code block format, where the following tokens must be replaced such that\\nFILENAME is the lowercase file name including the file extension,\\nLANG is the markup code block language for the code\'s language, and CODE is the code:\\n\\nFILENAME\\n\`\`\`LANG\\nCODE\\n\`\`\`\\n\\nYou will start with the \\"entrypoint\\" file, then go to the ones that are imported by that file, and so on.\\nPlease')]}}
----------------
{'generate': {'answer': 'The end of the post highlights that task decomposition faces challenges in long-term planning and adapting to unexpected errors. LLMs struggle with adjusting their plans, making them less robust compared to humans who learn from trial and error. This indicates a limitation in effectively exploring the solution space and handling complex tasks.'}}
----------------
在流式步骤(streamed steps)和 LangSmith 的追踪(trace)中,我们现在可以看到传递给检索步骤的结构化查询。
查询分析(Query Analysis)是一个很复杂问题,存在很多使用方法。更多案例请关注后续章节
接下来的步骤
我们已经介绍了构建一个基于数据的基础问答应用的各个步骤:
-
使用文档加载器(Document Loader)加载数据
-
使用文本分割器(Text Splitter)对数据进行分块,以便模型更易处理
-
对数据进行嵌入(embedding)并存储到向量数据库中
-
在接收到问题时,从向量库中检索出先前存储的相关数据块
-
使用检索到的数据块作为上下文生成回答
在本教程的第二部分中,我们将扩展此处的实现功能,以支持对话式交互和多步骤检索过程。
我是一名有十年以上经验的Java老码农,曾经沉迷于代码的世界,也曾在传统业务系统中摸爬滚打。但时代在变,AI 正在重塑技术格局。我不想被浪潮甩在身后,所以选择重新出发,走上 AI 学习与转型的旅程。
这个公众号,记录的不是鸡汤,也不是“割韭菜”的教程,而是我一个程序员真实的思考、学习、实战经验,以及从困惑到突破的全过程。
如果你也是在技术瓶颈中思考转型、想了解 AI 如何与传统开发结合、又或仅仅想看一个普通工程师的进化之路,欢迎关注,一起探索,一起成长。
关注我 和我一起,紧跟着AI的步伐,不被时代抛弃。✨


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









