




题目
表: Person
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | email | varchar | +-------------+---------+ id 是该表的主键列(具有唯一值的列)。 该表的每一行包含一封电子邮件。电子邮件将不包含大写字母。
编写解决方案 删除 所有重复的电子邮件,只保留一个具有最小 id 的唯一电子邮件。
(对于 SQL 用户,请注意你应该编写一个 DELETE 语句而不是 SELECT 语句。)
(对于 Pandas 用户,请注意你应该直接修改 Person 表。)
运行脚本后,显示的答案是 Person 表。驱动程序将首先编译并运行您的代码片段,然后再显示 Person 表。Person 表的最终顺序 无关紧要 。
返回结果格式如下示例所示。
示例 1:
输入: Person 表: +----+------------------+ | id | email | +----+------------------+ | 1 | john@example.com | | 2 | bob@example.com | | 3 | john@example.com | +----+------------------+ 输出: +----+------------------+ | id | email | +----+------------------+ | 1 | john@example.com | | 2 | bob@example.com | +----+------------------+ 解释: john@example.com重复两次。我们保留最小的Id = 1。
解析
将Person表连接起来,有:
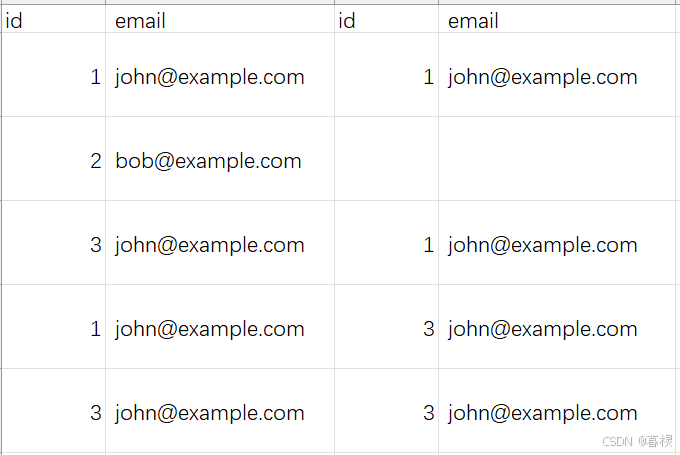
比较表1和表2的id,如果表2的id大于表1,则删除表二的行,最后返回表2
解答
delete p2
from Person as p1
join Person as p2
on p1.email = p2.email and p2.id >p1.id


















 1326
1326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











