







目录
1 HiAI Foundation Kit 概述
- 使用HiAI Foundation Kit将人工智能能力集成到鸿蒙应用中。HiAI Foundation Kit是面向麒麟硬件平台为各种人工智能模型和算法提供统一的接入和运行环境。应用程序使用HiAI Foundation Kit的API和用户数据,在设备端实现智能推理、模型训练以及模型优化等操作,充分发挥设备的本地智能处理能力。
- 模型是将人工智能算法应用于大量训练数据后得到的结果。使用模型依据新的输入数据进行智能推理和预测。模型能够完成许多用常规代码实现起来难度较大或效率较低的复杂任务。
- 使用华为昇腾提供的CANN开发平台进行模型的构建和训练。将CANN上训练好的模型转换为适合HiAI Foundation Kit的模型格式,以便集成到应用中。此外,也可以基于其他开源或自研的机器学习框架进行模型开发,然后借助HiAI Foundation Kit提供的工具链将模型适配到鸿蒙生态中。
- HiAI Foundation Kit通过协同调度设备的NPU(神经网络处理单元)、 CPU等硬件资源,实现高效的设备端智能计算性能优化。在提升计算效率的同时,尽可能降低对内存和电量的消耗。在设备端直接运行模型,减少了对网络的依赖,不仅保障了用户数据的隐私安全,还使应用程序在各种网络环境下都能保持快速响应,为用户提供流畅的智能交互体验。
- HiAI Foundation Kit构建在底层的硬件驱动和优化的计算库之上,面向华为自研的达芬奇架构NPU的计算核心,与云侧昇腾芯片统一支持Ascend C自定义算子编程语言和相关工具链,确保开发者面向NPU的开发优化可以一次开发、多端运行。
- HiAI Foundation Kit是鸿蒙智能生态的重要基石,为众多领域的智能应用提供核心支撑。例如:支持图像视觉相关的Core Vision Kit、用于自然语言处理的Natural Language Kit等AI计算加速能力,同时支持鸿蒙的MindSpore Lite Kit、Neural Network Runtime Kit,三方的MNN、PaddleLite等推理框架能力,共同打造丰富的智能应用场景。
1.1 场景
1.1.1 模型优化
- Model Zoo:模型库和工具包,为用户提供海量模型结构及算子,助力开发者选择硬件能效更优的模型结构。
- 模型轻量化:优化模型大小,降低计算量,降低空间占用与算力需求。
1.1.2 模型转换
- 离线模型转换:HiAI Foundation通过OMG工具可以把神经网络各种算子,比如卷积、池化、激活、全连接等离线编译成硬件专用的AI指令序列,同时将数据和权重重新排布,指令与数据融合在一起生成离线模型。
- AIPP(AI Pre-Process):AI预处理,支持输入数据硬件预处理,包括图像裁剪、通道交换、色域转换、图片缩放、数据类型转换、旋转和图片补边。由于AIPP硬件专用,可以获得更好的推理性能收益。通过模型转化配置文件生成动静态AIPP模型,及完成AIPP功能参数设置。
- 可变data_type:用于模型输入输出数据类型多样性的场景,无需修改训练好的模型,在使用OMG工具进行模型转换时,通过指定输入、输出数据类型使得同一个模型适用于不同输入输出的场景。
1.1.3 端侧部署
- 模型推理:主要包含模型编译和推理,是其它端侧部署的基础场景。
- AIPP部署:端侧AIPP部署主要为动态AIPP功能提供支持,即同一动态AIPP模型可以支持不同输入且使能不同AIPP功能的推理场景。
- 异构:HiAI Foundation能够自动识别运行环境上的计算能力,对神经网络进行自适应的子图拆分和设备协同调度能力。能够支持NPU、CPU的计算加速,在没有NPU的情况下,也能通过CPU提供更广泛的硬件适应能力。
- 内存零拷贝:将存放数据的ION内存封装为输入输出张量,直接进行推理,不需要进行输入张量和输出张量的数据拷贝,以便节省内存以及推理时间。
- 深度融合:模型推理时结合硬件深度融合,减少对DDR的访问,提升能效比。
1.1.4 单算子
在三方应用框架加载其原始模型阶段,根据算子的输入、输出、权重信息等参数创建相应的单算子执行器对象并完成加载。三方应用框架执行模型推理时,在其中算子计算过程中调用单算子推理接口,完成算子计算。
1.2 基本概念
在进行HiAI Foundation开发前,开发者应了解以下基本概念:
- NPU
NPU(Neural-network Processing Unit,神经网络处理器)是一种专门用于进行深度学习计算的芯片。
- 算子
深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。
- 异构计算
异构计算(Heterogeneous Computing),又译异质运算,主要是指使用不同类型指令集或体系架构的计算单元组成系统的计算方式。HiAI Foundation使用到的计算单元类别包括CPU、NPU等。
- AIPP
AIPP是针对AI推理的输入数据进行预处理的模块。HiAI模型推理一般需要标准化输入数据格式,而一般模型推理场景数据是一张图片,在格式上存在多样性,AIPP可实现不同格式图片数据到NPU标准输入数据格式的转换。对已训练好的模型,不用重新训练匹配推理计算平台需要的数据格式,而只通过AIPP参数配置或者在软件上调用AIPP接口即可完成适配。由于AIPP硬件专用,可以获得较好的推理性能收益,又可以称为“硬件图像预处理”。
2 环境准备
- 使用Ubuntu 64位运行Tools下载中tools_omg模型转换工具。
- 推荐使用Ubuntu 16.04及以上版本、MacOS 10.14及以上版本、Window 10及以上版本安装应用开发环境DevEco Studio。
- 准备训练好的tools_omg模型转换工具生成的离线模型或者从Model Zoo中选择合适的模型。
2.1 下载Tools
| Tools名称 | Tools说明 | Tools下载 | SHA256校验码 |
|---|---|---|---|
| 轻量化工具 包名:tools_dopt | 对原始模型进行轻量化,以减少模型体积及加快模型推理速度。 | DDK_tools_5.0.1.0 next | 3a7190aa56cff27f1135c4892ee57cfac955a820d150924a8a3fa9333dc85a18 |
| OMG工具 包名:tools_omg | 模型转换工具。 |
3 模型优化
3.1 Model Zoo
3.1.1 概述
Model Zoo提供了可直接调用的硬件最优模型库,集成图片分类、物体检测、语义分割、超分等典型场景的网络模型,包含HiAI性能调优使用指导、性能友好模型结构和推荐指数。帮助开发者快速了解算子的参数取值如何在硬件上获得更好的性能和能效收益,以及如何优化模型结构可以实现高性能与低功耗。
3.1.2 Model Zoo模型下载
Model Zoo中模型的名称、性能、模型下载信息如下表所示。模型下载中的.caffemodel、.pb、.onnx是原始浮点模型文件,通过参考对应论文来实现。.om是标准IR算子构建的OM模型文件,其中quant8_8.om是量化生成的OM模型文件,所有模型可通过Netron工具可视化。
| 场景 | 网络模型(单batch) | 浮点性能[1](耗时ms) | 量化性能[1](耗时ms) | 模型下载 | SHA256校验码 | 参考[2] |
|---|---|---|---|---|---|---|
| 图片分类 | Alexnet | 9.92 | 4.49 | CAFFE&OM | 7b01980acf0d16dadc6c9c326cdf757d2166928ae49cfd4091df154a5c512640 | |
| Resnet18 | 2.63 | 1.24 | CAFFE&OM | 4aa7caaa112f5280cb5c0ab5eed6edf84a16fe9a0b92b9ee333a808c9f07e886 | ||
| Vgg16 | 16.56 | 8.55 | TF&OM | f9193765889077e5997ddc8c1e75a563c8a1205e613da9634d3d83277962dd42 | ||
| Vgg19 | 18.34 | 8.73 | TF&OM | d19f363602740ff5859380c40ca6f0bed0cb3744f469873cdf862c71c7007a94 | ||
| Resnet50 | 5.15 | 3.54 | TF&OM | 6dedf4b5c3bfdaf70410236f1f73d942a5231f217e18c51918ba39b3b740b2df | ||
| Inception_v3 | 6.56 | 3.76 | TF&OM | d06c88a79acd19b10d5f7eddaae6aba3c02372cfdb036296b845aa3a9ccf46be | ||
| Inception_v4 | 11.90 | 7.29 | TF&OM | e042f489e6915eb6de5daa4b3200462e76f1bedca7147e2a19e8311a4b05afde | ||
| Inception_Resnet_v2 | 15.91 | 5.59 | TF&OM | 229164e49753126357f4a587694ca925afa60d1bfec184dba00085d69b5fc47b | ||
| Mobilenet_v1 | 2.16 | 0.52 | TF&OM | 864ef1d651e7f2cb9de69ce34d81e40783bdac47069b6db22aefb6f4ae17f24b | ||
| Mobilenet_v2 | 2.49 | 1.18 | TF&OM | 362c0169917122e45f4c5aed69ad3b9c8509b51a0531e6912360eff6c8b81cbc | ||
| Mobilenet_v2_1.4 | 3.16 | 1.67 | TF&OM | 8f1a05a83e813fac16e958ad5436569fe83f75f88137819d52ce2e268ad04126 | ||
| Mobilenet_v3_Large | 3.29 | 2.33 | TF&OM | 086640ff192629b6dba33d905ddb0925d612e395703948c6c7221f2e4126b85d | ||
| Googlenet | 34.69 | 1.64 | ONNX&OM | 97ef0325be2c3b8824a903abaeea943260d2f349da63d193168c96eff735ad0e | ||
| Squeezenet_v1 | 2.13 | 1.24 | ONNX&OM | e20be44bdaa30b9fa4a22ef876c1e7bd88db49b5d063992ef1595b34d3544997 | ||
| 物体检测 | SSD_mobilenetv2_voc | 5.02 | 2.84 | CAFFE&OM | 1d273130a07a6f888f6df1088b478049da9a961a3dbeaca7bfa92e616f0f01e9 | |
| Yolo_v5 | 4.74 | 4.33 | ONNX&OM | 83a205d70fcd9b31c13530da0b8752a6976b125b02ac07091fd088f58cd5a80f | ||
| 语义分割 | FCN | 131.23 | 62.76 | CAFFE&OM | 0cd87a51c1ea978a68e9cd4790106e99d910f78d5e68ec06e2bdd637aae5a73c | |
| DeepLab_v3 | 17.40 | 13.87 | TF&OM | 381f830f6b0154bf086dbc5b15575465a34c1b3d233a6d27bc417077832697c7 | ||
| 超分 | VDSR | 17.71 | 10.67 | CAFFE&OM | bf5a699ea55b2d2e42ac40884f2697d807b5b3f37e655ecb342e873c6ba6b844 | |
| FSRCNN | 17.24 | 17.02 | TF&OM | 03775c806d8d166fd29753ea8eaa3db377246fa469487b7e161a9e405a6ffa1c |
说明
- [1] 此性能数据测试基于kirin 9000芯片的华为手机。
- [2] 原始模型文件是参考论文和实现中的模型训练而来。
除Model Zoo中推荐的网络模型,还可以构建自定义的网络模型。性能优势的算子和计算结构如下。
3.1.3 HiAI算子性能指导
从易用性角度上来说,提供的算子功能不存在限制,但是从性能的使用角度上来说,是基于算子实现方式给出对应的性能使用指导。
1、NN算子
| IR算子 | 性能使用指导 | 推荐使用指数 |
|---|---|---|
| Activation | 当前性能硬件最优。 | ☆☆☆☆☆ |
| HardSwish | 当前性能硬件最优。 | ☆☆☆☆☆ |
| PRelu | 当前性能硬件最优。 | ☆☆☆☆☆ |
| BNInference | 当前性能硬件最优。 Conv(depthwise)+Bn组合使用时,会进行图融合优化抵消。 | ☆☆☆☆☆ |
| Convolution | 当Cin和Cout都是16的倍数时性能最优。 | ☆☆☆☆☆ |
| QuantizedConvolution | 当Cin和Cout都是32的倍数时性能最优。 | ☆☆☆☆☆ |
| ConvTranspose |
| ☆☆☆☆☆ |
| BiasAdd | 当前性能硬件最优。 Conv(depthwise)+BiasAdd组合使用时,会进行图融合优化抵消。 | ☆☆☆☆☆ |
| Eltwise | 当前性能硬件最优。 | ☆☆☆☆☆ |
| LRN | 当前性能硬件较优。
| ☆☆☆ |
| ConvolutionDepthwise | 当前性能硬件最优。 | ☆☆☆☆☆ |
| QuantizedConvolutionDepthwise | 当前性能硬件最优。 | ☆☆☆☆☆ |
| FullyConnection | 性能受DDR带宽限制,非算力受限算子,算法设计时合理配置权重大小。 | ☆☆☆☆☆ |
| QuantizedFullyConnection | 性能受DDR带宽限制,非算力受限算子,算法设计时合理配置权重大小。 | ☆☆☆☆☆ |
| PoolingD | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Scale | 当前性能硬件最优。 Conv(depthwise)+Scale组合使用时,会进行图融合优化抵消。 | ☆☆☆☆☆ |
| ShuffleChannel | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| ShuffleChannelV2 | 为了适配支持ANN场景算子,性能较差,仅支持功能。 | ☆ |
| Softmax | 当前性能硬件最优。 4维输入,axis=1,基于C通道做softmax时性能最优。 | ☆☆☆☆☆ |
| TopK | 为了适配支持ANN场景算子,性能较差,仅支持功能。 | ☆ |
| LogSoftmax | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Rank | shape推导类算子,模型构建时即可抵消。 | ☆☆☆☆☆ |
| ScatterNd | 非规则数据搬移,性能较差,不建议模型过多使用。 | ☆☆☆ |
| LogicalXor | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Threshold | 当前性能硬件最优。 | ☆☆☆☆☆ |
| AxisAlignedBboxTransform | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Normalize | 当前性能硬件最优。 | ☆☆☆☆☆ |
| SVDF | 当前性能硬件最优。 | ☆☆☆☆☆ |
| ReduceMean | 当前性能硬件最优。 | ☆☆☆☆☆ |
| LayerNorm | 当前性能硬件最优。
| ☆☆☆ |
| InstanceNorm | 当前性能硬件较优。
| ☆☆☆ |
| PriorBox | 当前性能硬件最优。 | ☆☆☆☆☆ |
| LSTM | 当前性能硬件较优,功能支持较窄。 | ☆☆☆☆ |
2、Math算子
| IR算子 | 性能使用指导 | 推荐使用指数 |
|---|---|---|
| Add | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Mul | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Expm1 | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Ceil | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Sin | 性能较差。 | ☆ |
| Cos | 性能较差。 | ☆ |
| Floor | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Log1p | 当前性能硬件最优。 | ☆☆☆☆☆ |
| LogicalAnd | 当前性能硬件最优。 | ☆☆☆☆☆ |
| LogicalNot | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Maximum | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| Minimum | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| Equal | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Reciprocal | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Sqrt | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Square | 当前性能硬件最优。 | ☆☆☆☆☆ |
| CastT | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| Sign | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Exp | 当前性能硬件最优。 | ☆☆☆☆☆ |
| FloorMod | 当前性能硬件最优。 | ☆☆☆☆☆ |
| GreaterEqual | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Greater | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Less | 当前性能硬件最优。 | ☆☆☆☆☆ |
| MatMul | 当前性能硬件最优。 | ☆☆☆☆☆ |
| RealDiv | 性能较差,建议等效成mul或者Reciprocal+mul。 | ☆ |
| Rint | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| Round | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| Rsqrt | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| Sub | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Range | 模型构建时最优。 | ☆☆☆☆☆ |
| Acos | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Asin | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Log | 当前性能硬件最优。 | ☆☆☆☆☆ |
| LogicalOr | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Neg | 当前性能硬件最优。 | ☆☆☆☆☆ |
| ReduceProdD | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| ReduceSum | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Tan | 性能较差。 | ☆ |
| Power | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Pow | 性能较差。 | ☆ |
| ArgMaxExt2 | 当前性能硬件最优。 | ☆☆☆☆ |
| FloorDiv | 性能较差,不建议使用。 | ☆ |
| NotEqual | 当前性能硬件最优。 | ☆☆☆☆☆ |
| LessEqual | 当前性能硬件最优。 | ☆☆☆☆☆ |
| SquaredDifference | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Atan | 当前性能硬件最优。 | ☆☆☆☆☆ |
| BatchMatMul | 当前性能硬件最优。 | ☆☆☆☆☆ |
| ClipByValue | 当前性能硬件最优。 | ☆☆☆☆☆ |
| L2Normalize | 当前性能硬件最优。 | ☆☆☆☆☆ |
| ReduceMax | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
| ReduceMin | kirin 9000芯片的手机性能较优,其余芯片的手机无性能优化,仅支持功能。 | ☆ |
3、Array算子
| IR算子 | 性能使用指导 | 推荐使用指数 |
|---|---|---|
| ConcatD | 当前性能硬件最优。 当Cin是16的倍数且Cout是16的倍数时,做图融合抵消,性能最优。 | ☆☆☆☆☆ |
| FakeQuantWithMinMaxVars | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Reshape | 当前性能硬件最优。 有些场景算子会被融合抵消掉。 | ☆☆☆☆☆ |
| SplitD | 当前性能硬件最优。 当Cin是16的倍数且Cout是16的倍数时,做图融合抵消,性能最优。 | ☆☆☆☆☆ |
| SplitV | 由于是乱序的数据重排,性能较差。 | ☆ |
| Unpack | 由于是乱序的数据重排,性能较差。 | ☆ |
| Flatten | 由于是乱序的数据重排,性能较差。 | ☆ |
| Slice | 由于是乱序的数据重排,性能较差。 | ☆ |
| ExpandDims | shape推导类算子,模型构建时即可抵消。 | ☆☆☆☆☆ |
| GatherV2D | 由于是乱序的数据重排,性能较差。 | ☆ |
| GatherNd | 由于是乱序的数据重排,性能较差。 | ☆ |
| Pack | 由于是乱序的数据重排,性能较差。 | ☆ |
| SpaceToDepth | 由于是乱序的数据重排,性能较差。 | ☆ |
| DepthToSpace | 由于是乱序的数据重排,大部分场景性能较差。 针对4宫格场景(Cin=4,block=1)有特殊优化,性能较优。 | ☆☆ |
| StridedSlice | 由于是乱序的数据重排,性能较差。 | ☆ |
| SpaceToBatchND | 由于是乱序的数据重排,性能较差。 | ☆ |
| BatchToSpaceND | 由于是乱序的数据重排,性能较差。 | ☆ |
| Tile | 由于是乱序的数据重排,性能较差。 | ☆ |
| Size | shape推导类算子,模型构建时即可抵消。 | ☆☆☆☆☆ |
| Fill | 由于是乱序的数据重排,性能较差。 | ☆ |
| Select | 仅支持功能。 | ☆☆ |
| PadV2 | 针对HW方向补0的场景性能较优。 其他场景由于乱序的数据重排,性能较差。 | ☆☆☆ |
| Squeeze | shape推导类算子,模型构建时即可抵消。 | ☆☆☆☆☆ |
| Pad | 针对HW方向补0的场景性能较优。 其他场景由于乱序的数据重排,性能较差。 | ☆☆☆ |
| MirrorPad | 其他场景由于乱序的数据重排,性能较差。 | ☆ |
| OneHot | 其他场景由于乱序的数据重排,性能较差。 | ☆ |
| Shape | shape推导类算子,模型构建时即可抵消。 | ☆☆☆☆☆ |
| Dequantize | 当前性能硬件最优。 | ☆☆☆☆☆ |
| Quantize | 当前性能硬件最优。 | ☆☆☆☆☆ |
4、Detection算子
| IR算子 | 性能使用指导 | 推荐使用指数 |
|---|---|---|
| Permute | 由于乱序的数据重排,虽然做了相关优化,但是硬件不适合过多此类操作。 | ☆☆☆ |
| SSDDetectionOutput | 当前性能最优。 | ☆☆☆☆☆ |
5、Image算子
| IR算子 | 性能使用指导 | 推荐使用指数 |
|---|---|---|
| ImageData DynamicImageData ImageCrop ImageChannelSwap ImageColorSpaceConvertion ImageResize ImageDataTypeConversion ImagePadding | AIPP相关图形处理算子,性能硬件最优。 | ☆☆☆☆☆ |
| CropAndResize | 仅功能支持,性能较差。 | ☆ |
| ResizeBilinear ResizeBilinearV2 Interp | 大部分场景性能硬件最优,个别场景待优化。 | ☆☆☆☆☆ |
| ResizeNearestNeighbor Upsample | 大部分场景性能硬件最优,个别场景待优化。 | ☆☆☆☆☆ |
| Crop | 仅功能支持,性能较差。 | ☆ |
| NonMaxSuppressionV3D | 仅功能支持,性能较差。 | ☆ |
3.1.4 性能友好计算结构
| 应用场景 | 网络类型 | 推荐指数 | 推荐说明 |
|---|---|---|---|
| 分类网络 | AlexNet | ☆☆☆☆ | 全连接层权重较大,推理过程带宽受限,可从Model Zoo中下载。 |
| VGG16 | ☆☆☆☆ | 全连接层权重较大,推理过程带宽受限,可从Model Zoo中下载。 | |
| VGG19 | ☆☆☆ | 全连接层权重较大,推理过程带宽受限,可从Model Zoo中下载。 | |
| ResNet18/34/50/101/152 | ☆☆☆☆☆ | 模型权重大小适中,硬件算力利用率接近100%,ResNet50可从Model Zoo下载。 | |
| GoogleNet | ☆☆☆☆ | 硬件算力利用率接近75%,可从Model Zoo中下载。 | |
| InceptionV3 | ☆☆☆☆ | 硬件算力利用率接近85%,可从Model Zoo中下载。 | |
| InceptionV4 | ☆☆☆☆ | 硬件算力利用率接近85%,可从Model Zoo中下载。 | |
| Inception_Resnet_v2 | ☆☆☆☆ | 硬件算力利用率接近90%,可从Model Zoo中下载。 | |
| Xception | ☆☆☆☆ | 硬件算力利用率接近85%,可从Model Zoo中下载。 | |
| MobileNet_v1 | ☆☆☆☆☆ | 模型权重大小适中,硬件算力利用率接近95%,可从Model Zoo中下载。 | |
| MobileNet_v2 | ☆☆☆☆☆ | 模型权重大小适中,硬件算力利用率接近95%,可从Model Zoo中下载。 | |
| MobileNet_v3 | ☆☆☆☆☆ | 模型权重大小适中,硬件算力利用率接近95%,可从Model Zoo中下载。 | |
| SqueezeNet | ☆☆☆☆☆ | 模型权重大小适中,硬件算力利用率接近95%,可从Model Zoo中下载。 | |
| DenseNet | ☆☆☆☆☆ | 模型权重大小适中,硬件算力利用率接近95%。 | |
| ShuffleNet_v1 ShuffleNet_v2 | ☆ | 存在大量shuffleChannel操作,本身是内存搬移操作,非计算受限。 此网络为带宽受限网络,shuffleChannel仅支持功能,性能不保证较优。 | |
| Resnext | ☆☆☆☆ | 硬件算力利用率接近85%。 | |
| EfficientNet | ☆☆☆☆☆ | 模型权重大小适中,硬件算力利用率接近95%。 | |
| SENet | ☆☆☆☆ | 硬件算力利用率接近75%。 | |
| 物体检测 | Faster_RCNN | ☆☆☆☆☆ | 硬件算力利用率接近85%。 |
| SSD | ☆☆☆☆ | 硬件算力利用率接近85%,当前仅支持通过omg流程生成。 | |
| FPN | ☆☆☆☆☆ | 硬件算力利用率接近90%,后处理不在模型中,由算法单独完成。 | |
| 语义分割 | FCN | ☆☆☆☆☆ | 硬件算力利用率接近85%,由于模型计算量较大,实际部署时要做参数裁剪,可从Model Zoo中下载 。 |
| DeeplabV3 | ☆☆☆ | 硬件算力利用率接近60%,可从Model Zoo中下载。 | |
| Unet | ☆☆☆ | 硬件算力利用率接近60%。 | |
| MaskRcnn | ☆☆ | 硬件算力利用率接近80%(仅限tf->om版本,IR对接方式不支持)。 | |
| PSPNet | ☆☆☆ | 不支持pyramid pooling算子,可以通过多个pool等效,性能一般。 | |
| 超分 | VDSR | ☆☆☆☆☆ | 硬件算力利用率接近85%,可以达到实时超分要求,可从Model Zoo中下载。 |
| FSRCNN | ☆☆☆☆ | 硬件算力利用率接近70%,可以达到部分实时超分要求,可从Model Zoo中下载。 | |
| SRCNN | ☆☆☆☆ | 硬件算力利用率接近70%,可以达到部分实时超分要求。 | |
| DnCNN | ☆☆☆☆ | 硬件算力利用率接近65%,计算量较大,可以达到部分实时超分要求。 | |
| DRCN | ☆☆☆☆ | 硬件算力利用率接近65%,计算量较大,可以达到部分实时超分要求。 | |
| DRRN | ☆☆☆ | 硬件算力利用率接近60%,计算量较大,可以达到部分实时超分要求。 | |
| EnhanceNet | ☆☆☆ | 硬件算力利用率接近60%,计算量较大,可以达到部分实时超分要求。 | |
| 语音语义 | RNN | ☆☆ | 功能支持较为单一。 |
| LSTM | ☆☆ | 功能支持较为单一。 | |
| Transformer | ☆☆☆☆ | 硬件算力利用率接近70%。 | |
| Bert | ☆☆☆☆ | 硬件算力利用率接近70%。 |
3.2 模型轻量化
3.2.1 简介
轻量化工具是一款集模型压缩算法和网络结构搜索算法于一体的自动模型轻量化工具,针对NPU架构对深度神经网络模型进行深度的模型优化,可以帮助用户自动地完成模型轻量化以及网络结构的生成任务。目前支持无训练模式、插件式量化模式和网络结构搜索。
- 无训练量化:用户可以直接输入模型,无需重训练,快速的完成模型轻量化。适用于快捷方便量化的用户使用。
- 插件式量化:为用户提供模型量化API,在用户训练工程中对浮点模型进行量化模型校准或量化模型重训练,易用性高,插件式重训练量化适用于较高精度要求的用户。
- 网络结构搜索:支持分类网络、检测网络、分割网络三种网络类型。用户配置相应的搜索参数和接口函数后,使用网络结构搜索工具进行搜索,在设定的算力约束下,得到优秀的网络模型。适用于需要自动生成网络结构的用户。
| 模式 | 支持的框架 | 支持的策略 | 支持的设备 |
|---|---|---|---|
| 无训练量化 | TensorFlow、PyTorch、ONNX | Quant_INT8-8 | 同时支持CPU和GPU模式,GPU支持单机单卡。 |
| 插件式量化 | TensorFlow、PyTorch | Quant_INT8-8 | 支持GPU,支持单机单卡。 |
| 网络结构搜索 | TensorFlow、PyTorch | NASEA | 支持GPU,支持单机单卡和单机多卡。 |
通过模型轻量化以及网络结构搜索获得模型在NPU上的收益可以参见模型收益。
说明
Quant_INT8-8:权重8bit量化,数据8bit量化。
经过轻量化工具小型化后的模型,可以使用OMG转换工具转为OM离线模型,使用方式可参见量化模型转换。
该轻量化工具位于“tools_dopt”目录下。
| 目录文件 | 描述说明 |
|---|---|
| tools_dopt/dopt_tf_py3 | TensorFlow框架无训练,插件式量化,网络结构搜索的工具入口以及demo。 |
| tools_dopt/dopt_pytorch_py3 | PyTorch框架无训练,插件式量化,网络结构搜索的工具入口以及demo。 |
| tools_dopt/dopt_onnx_py3 | ONNX框架无训练工具入口。 |
3.2.2 支持范围
- 支持Linux环境,Ubuntu 22.04。
- 插件式支持GPU训练,单机单卡训练。
- 无训练支持CPU和GPU量化。
- 网络结构搜索工具支持单机单卡和单机多卡,进行分类、检测、分割场景的骨架搜索,依赖运行环境参见环境准备。
3.2.3 系统要求
- TensorFlow用户使用本工具需同时满足下列环境要求:
- Python 3.10
- Ubuntu 22.04
- Tensorflow 2.8.0
- GPU需要使用支持CUDA的显卡(无训练量化可不配置)
- PyTorch用户使用本工具需同时满足下列环境要求:
- Python 3.10
- Ubuntu 22.04
- PyTorch 1.11
- opencv-python
- GPU需要使用支持CUDA的显卡(无训练量化可不配置)
- ONNX用户使用本工具需同时满足下列环境要求:
- Python 3.10
- Ubuntu 22.04
- ONNX Runtime 1.15
- ONNX 1.14
3.2.4 用户指引
下面列举了不同用户场景对应的步骤和工具链功能。用户可以根据下表中列举的不同场景选择适宜的优化方式。
1、TensorFlow用户
| 用户场景 | 使用依赖 | 工具链提供功能 | 使用限制 | 建议使用工具 | 优势 |
|---|---|---|---|---|---|
|
| Quant_INT8-8 | 无 | 无需TensorFlow编写代码,新手用户友好 | |
|
| Quant_INT8-8 | 无 | 模型精度可保障 | |
|
| 搜索生成网络结构 | 无 | 可根据用户提供的配置信息自动搜索到在特定场景上表现优秀的网络结构 |
2、PyTorch用户
| 用户场景 | 使用依赖 | 工具链提供功能 | 使用限制 | 建议使用工具 | 优势 |
|---|---|---|---|---|---|
|
| Quant_INT8-8 | 无 | 无需PyTorch编写代码,新手用户友好 | |
|
| Quant_INT8-8 | 无 | 模型精度可保障 | |
|
| 搜索生成网络结构 | 无 | 可根据用户提供的配置信息自动搜索到在特定场景上表现优秀的网络结构 |
3、ONNX用户
| 用户场景 | 用户需要准备 | 工具链提供功能 | 使用限制 | 建议使用工具 | 优势 |
|---|---|---|---|---|---|
|
| Quant_INT8-8 | 无 | 无需编写代码,新手用户友好 |
3.3 端侧部署
3.3.1 部署全流程
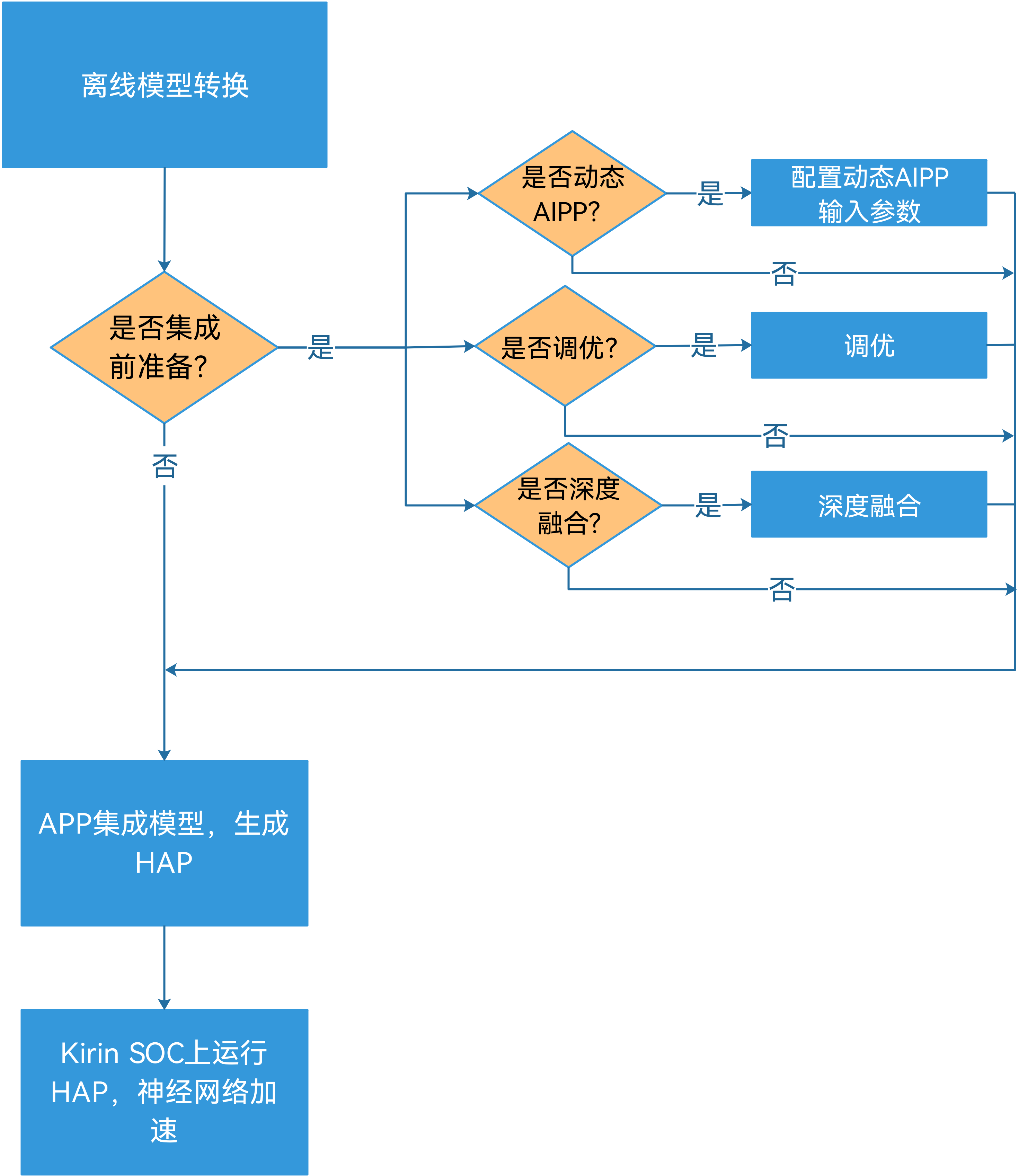
1、离线模型转换
离线模型转换需要将Caffe、TensorFlow、ONNX、MindSpore模型转换为HiAI Foundation平台支持的模型格式,并可以按需进行AIPP操作、量化操作,使用场景及方法如下:
2、App集成
App集成流程包含创建项目、配置项目里的NAPI、集成模型,集成模型又包含加载模型、编译模型、模型输入数据预处理、运行模型、模型输出数据后处理流程。
3.3.2 模型推理
1、基本概念
该场景是基本模型的使用场景,主要包含模型的编译和推理,其他场景是基础场景的一个扩展和功能增强。
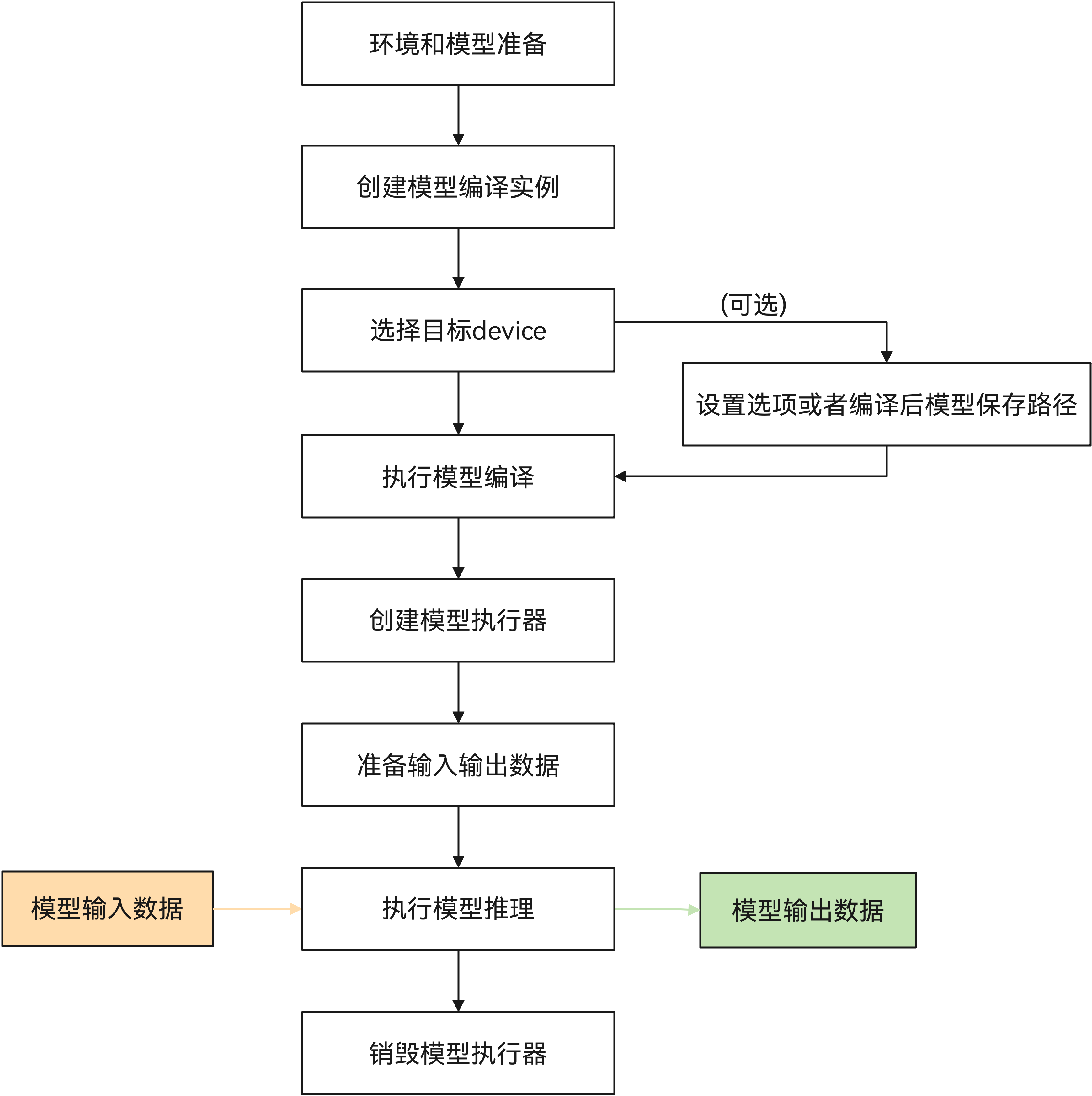
2、业务流程
模型推理的主要开发流程如下图所示:
3、接口说明
以下接口为主要流程接口,如要使用更丰富的编译、加载和执行时的配置,请参见API参考。
| 接口名 | 描述 |
|---|---|
| OH_NNCompilation* OH_NNCompilation_ConstructWithOfflineModelBuffer(const void *modelBuffer, size_t modelSize); | 根据模型buffer创建模型编译实例。 |
| OH_NN_ReturnCode OH_NNCompilation_SetDevice(OH_NNCompilation *compilation, size_t deviceID); | 设置模型编译和执行的目标设备。 |
| OH_NN_ReturnCode OH_NNCompilation_Build(OH_NNCompilation *compilation); | 执行模型编译,生成编译后的模型保存在compilation中。 |
| OH_NNExecutor* OH_NNExecutor_Construct(OH_NNCompilation *compilation); | 根据编译后的模型,创建模型推理的执行器。 |
| NN_Tensor* OH_NNTensor_Create(size_t deviceID, NN_TensorDesc* tensorDesc); | 构造输入输出Tensor。 |
| OH_NN_ReturnCode OH_NNExecutor_RunSync(OH_NNExecutor *executor, NN_Tensor *inputTensor[], size_t inputCount, NN_Tensor *outputTensor[], size_t outputCount); | 执行模型的同步推理。 |
| void OH_NNCompilation_Destroy(OH_NNCompilation **compilation); | 销毁模型编译实例。 |
| OH_NN_ReturnCode OH_NNTensor_Destroy(NN_Tensor** tensor); | 销毁输入输出Tensor。 |
| void OH_NNExecutor_Destroy(OH_NNExecutor **executor); | 销毁模型推理的执行器。 |
4、开发步骤
以下为模型推理的主要开发步骤,具体实现请参见SampleCode。
1. 准备模型和开发环境。
- 准备om模型,可以通过tools_omg工具生成或从Model Zoo获取。
- 下载并配置DevEco Studio IDE环境,确保可以正常开发和调试HarmonyOS应用。
3. 创建模型编译实例。
- 调用OH_NNCompilation_ConstructWithOfflineModelBuffer读取模型buffer,创建模型编译实例。或者通过调用OH_NNCompilation_ConstructWithOfflineModelFile直接读取模型文件,创建模型编译实例。
4. 选择目标device:HiAIFoundation。
- 调用OH_NNDevice_GetAllDevicesID,获取所有的设备ID,查找name为"HIAI_F"字段的设备ID,记录并通过OH_NNCompilation_SetDevice设置到步骤3创建的编译实例中。
5. 执行模型编译。
- 调用OH_NNCompilation_Build,传入步骤3创建的模型编译实例,即可执行模型编译,编译后的模型数据仍然保存在模型编译实例中。
6. 创建模型执行器。
- 调用OH_NNExecutor_Construct,创建编译后模型对应的执行器实例。执行器创建完成后即可调用OH_NNCompilation_Destroy销毁模型编译实例。
7. 构造输入输出Tensor。
- 调用OH_NNExecutor_GetInputCount,查询输入的个数,通过OH_NNExecutor_CreateInputTensorDesc获取到对应索引的TensorDesc,根据该TensorDesc通过OH_NNTensor_Create创建Tensor,即可向Tensor中写入实际数据。输出Tensor的构造与输入Tensor的构造过程一致。
8. 执行模型推理。
- 调用OH_NNExecutor_RunSync,执行模型的同步推理功能,模型的输出数据保存在outputTensors中。开发者可根据需要对输出数据做相应的处理以得到期望的内容。
9. 销毁实例。
- 调用OH_NNExecutor_Destroy,销毁创建的模型执行器实例。
- 调用OH_NNTensor_Destroy,销毁创建的输入输出Tensor。
3.3.3 App集成
1、创建项目
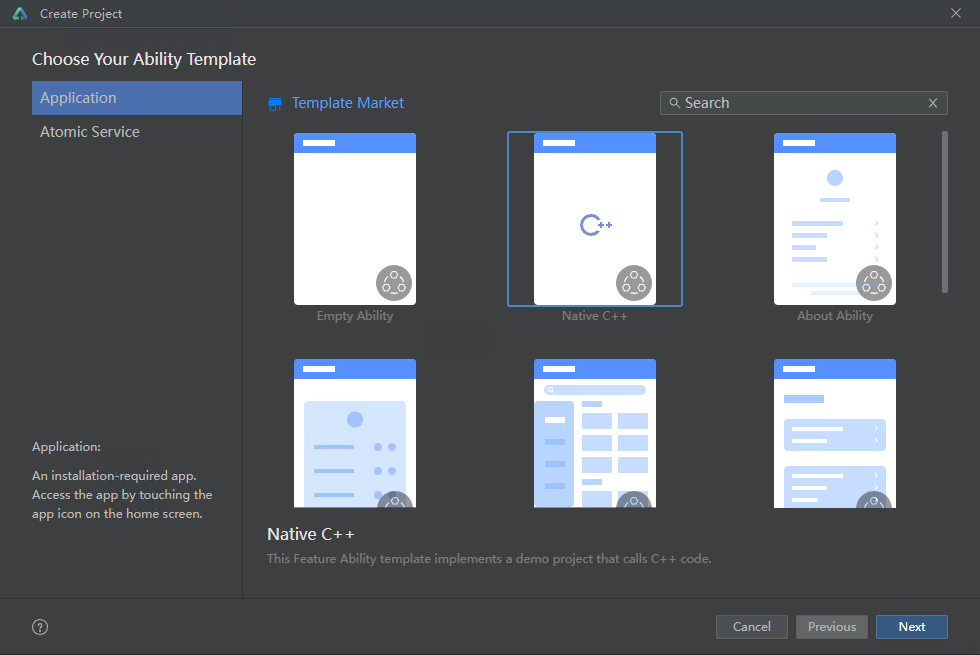
本章以Caffe SqueezeNet模型集成为例,说明App集成操作过程。
- 创建DevEco Studio项目,选择“Native C++”模板,点击“Next”。
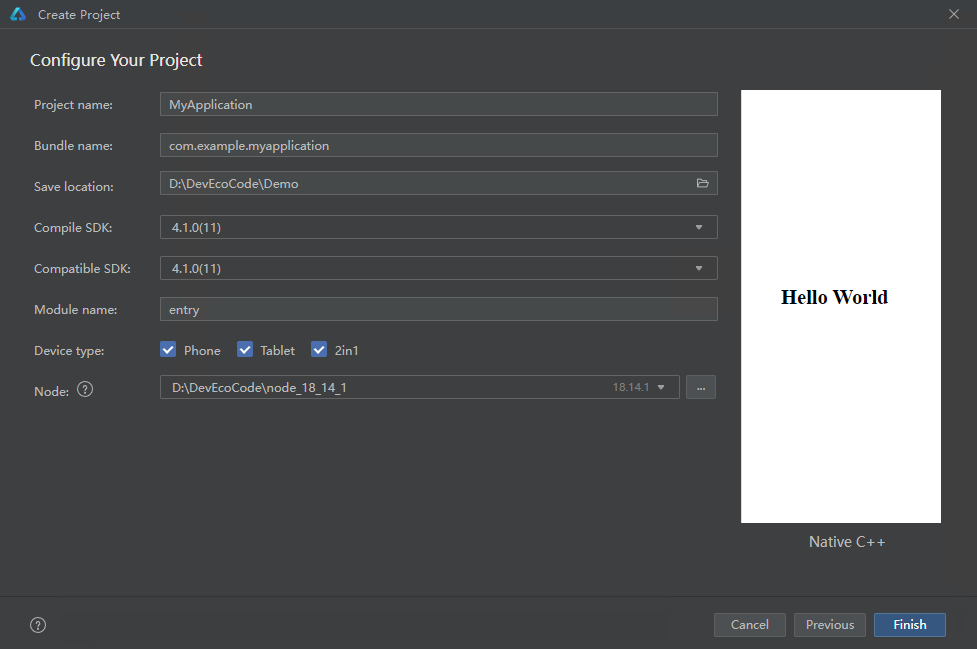
- 按需填写“Project name”、“Save location”和“Module name”,选择“Compile SDK”为“4.1.0(11)”及以上版本,点击“Finish”。
2、配置项目NAPI
编译HAP时,NAPI层的so需要编译依赖NDK中的libneural_network_core.so和libhiai_foundation.so。
头文件引用
按需引用NNCore和Hiai Foundation的头文件。
#include "neural_network_runtime/neural_network_core.h"
#include "hiai_foundation/hiai_options.h"编写CMakeLists.txt
CMakeLists.txt示例代码如下:
# the minimum version of CMake.
cmake_minimum_required(VERSION 3.4.1)
project(HiaiDemo)
set(NATIVERENDER_ROOT_PATH ${CMAKE_CURRENT_SOURCE_DIR})
include_directories(${NATIVERENDER_ROOT_PATH}
${NATIVERENDER_ROOT_PATH}/include)
include_directories(${HMOS_SDK_NATIVE}/sysroot/usr/lib)
FIND_LIBRARY(hiai_foundation-lib hiai_foundation)
add_library(entry SHARED Classification.cpp HIAIModelManager.cpp)
target_link_libraries(entry PUBLIC libace_napi.z.so
libhilog_ndk.z.so
librawfile.z.so
${hiai_foundation-lib}
libneural_network_core.so
)3、集成模型
模型的加载、编译和推理主要是在native层实现,应用层主要作为数据传递和展示作用。
模型推理之前需要对输入数据进行预处理以匹配模型的输入,同样对于模型的输出也需要做处理获取自己期望的结果。另外SDK中提供了设置模型编译和运行时的配置接口,开发者可根据实际需求选择使用接口。
本节阐述同步模式下单模型的使用,从流程上分别阐述每个步骤在应用层和native层的实现和调用。接口请参见API参考,示例请参见SampleCode,本示例支持加载离线模型对图片中的物体进行分类,App运行效果图如下所示。

预置模型
为了让App运行时能够读取到模型文件和处理推理结果,需要先把离线模型和模型对应的结果标签文件预置到工程的“entry/src/main/resources/rawfile”目录中。
本示例所使用的离线模型的转换和生成请参考Caffe模型转换。
加载离线模型
在App应用创建时加载模型和读取结果标签文件。
上述流程可参见SampleCode中“entry/src/main/cpp/Classification.cpp”文件中的LoadModel函数和“entry/src/main/cpp/HiAiModelManager.cpp”中的HIAIModelManager::LoadModelFromBuffer函数。
输入输出数据准备
- 调用NAPI层的LoadModel函数,读取模型的buffer。
- 把模型buffer传递给HIAIModelManager类的HIAIModelManager::LoadModelFromBuffer接口,该接口调用OH_NNCompilation_ConstructWithOfflineModelBuffer创建模型的编译实例。
- 设置模型的deviceID。
size_t deviceID = 0; const size_t *allDevicesID = nullptr; uint32_t deviceCount = 0; // 获取所有已连接设备的ID OH_NN_ReturnCode ret = OH_NNDevice_GetAllDevicesID(&allDevicesID, &deviceCount); if (ret != OH_NN_SUCCESS || allDevicesID == nullptr) { OH_LOG_ERROR(LOG_APP, "OH_NNDevice_GetAllDevicesID failed"); return OH_NN_FAILED; } // 获取设备名为HIAI_F的设备ID for (uint32_t i = 0; i < deviceCount; i++) { const char *name = nullptr; // 获取指定设备的名称 ret = OH_NNDevice_GetName(allDevicesID[i], &name); if (ret != OH_NN_SUCCESS || name == nullptr) { OH_LOG_ERROR(LOG_APP, "OH_NNDevice_GetName failed"); return OH_NN_FAILED; } if (std::string(name) == "HIAI_F") { deviceID = allDevicesID[i]; break; } } // modelData和modelSize为模型的内存地址和大小, compilation的创建可参考HiAI Foundation Codelab OH_NNCompilation *compilation = OH_NNCompilation_ConstructWithOfflineModelBuffer(modelData, modelSize); // 设置编译器的设备id为HIAI_F ret = OH_NNCompilation_SetDevice(compilation, deviceID); if (ret != OH_NN_SUCCESS) { OH_LOG_ERROR(LOG_APP, "OH_NNCompilation_SetDevice failed"); return OH_NN_FAILED; } - 调用OH_NNCompilation_Build,执行模型编译。
- 调用OH_NNExecutor_Construct,创建模型执行器。
- 调用OH_NNCompilation_Destroy,释放模型编译实例。
- 处理模型的输入,例如示例中模型的输入为1*3*227*227格式Float类型的数据,需要把输入的图片转成该格式后传递到NAPI层。
- 创建模型的输入和输出Tensor,并把应用层传递的数据填充到输入的Tensor中。
// 创建输入数据
size_t inputCount = 0;
std::vector<NN_Tensor*> inputTensors;
OH_NN_ReturnCode ret = OH_NNExecutor_GetInputCount(executor, &inputCount); // 创建executor可参考HiAI Foundation Codelab
if (ret != OH_NN_SUCCESS || inputCount != inputData.size()) { // inputData为开发者构造的输入数据
OH_LOG_ERROR(LOG_APP, "OH_NNExecutor_GetInputCount failed, size mismatch");
return OH_NN_FAILED;
}
for (size_t i = 0; i < inputCount; ++i) {
NN_TensorDesc *tensorDesc = OH_NNExecutor_CreateInputTensorDesc(executor, i); // 创建executor可参考HiAI Foundation Codelab
NN_Tensor *tensor = OH_NNTensor_Create(deviceID, tensorDesc); // deviceID的获取方式可参考加载离线模型的步骤3或者HiAI Foundation Codelab
if (tensor != nullptr) {
inputTensors.push_back(tensor);
}
OH_NNTensorDesc_Destroy(&tensorDesc);
}
if (inputTensors.size() != inputCount) {
OH_LOG_ERROR(LOG_APP, "input size mismatch");
DestroyTensors(inputTensors); // DestroyTensors为释放tensor内存操作函数,具体实现可参考HiAI Foundation Codelab
return OH_NN_FAILED;
}
// 初始化输入数据
for (size_t i = 0; i < inputTensors.size(); ++i) {
void *data = OH_NNTensor_GetDataBuffer(inputTensors[i]);
size_t dataSize = 0;
OH_NNTensor_GetSize(inputTensors[i], &dataSize);
if (data == nullptr || dataSize != inputData[i].size()) { // inputData为模型的输入数据,使用方式可参考HiAI Foundation Codelab
OH_LOG_ERROR(LOG_APP, "invalid data or dataSize");
return OH_NN_FAILED;
}
memcpy(data, inputData[i].data(), inputData[i].size()); // inputData为模型的输入数据,使用方式可参考HiAI Foundation Codelab
}
// 创建输出数据,与输入数据的创建方式类似
size_t outputCount = 0;
std::vector<NN_Tensor*> outputTensors;
ret = OH_NNExecutor_GetOutputCount(executor, &outputCount); // 创建executor可参考HiAI Foundation Codelab
if (ret != OH_NN_SUCCESS) {
OH_LOG_ERROR(LOG_APP, "OH_NNExecutor_GetOutputCount failed");
DestroyTensors(inputTensors); // DestroyTensors为释放tensor内存操作函数,具体实现可参考HiAI Foundation Codelab
return OH_NN_FAILED;
}
for (size_t i = 0; i < outputCount; i++) {
NN_TensorDesc *tensorDesc = OH_NNExecutor_CreateOutputTensorDesc(executor, i); // 创建executor可参考HiAI Foundation Codelab
NN_Tensor *tensor = OH_NNTensor_Create(deviceID, tensorDesc); // deviceID的获取方式可参考加载离线模型的步骤3或者HiAI Foundation Codelab
if (tensor != nullptr) {
outputTensors.push_back(tensor);
}
OH_NNTensorDesc_Destroy(&tensorDesc);
}
if (outputTensors.size() != outputCount) {
DestroyTensors(inputTensors); // DestroyTensors为释放tensor内存操作函数,具体实现可参考HiAI Foundation Codelab
DestroyTensors(outputTensors); // DestroyTensors为释放tensor内存操作函数,具体实现可参考HiAI Foundation Codelab
OH_LOG_ERROR(LOG_APP, "output size mismatch");
return OH_NN_FAILED;
}
上述流程可参见SampleCode中“entry/src/main/cpp/Classification.cpp”文件中的InitIOTensors函数和“entry/src/main/cpp/HiAiModelManager.cpp”中的HIAIModelManager::InitIOTensors函数。
同步推理离线模型
说明
如果不更换模型,则首次编译加载完成后可多次推理,即一次编译加载,多次推理。
调用OH_NNExecutor_RunSync,完成模型的同步推理。
可参见SampleCode中“entry/src/main/cpp/Classification.cpp”文件中的RunModel函数和“entry/src/main/cpp/HiAiModelManager.cpp”中的HIAIModelManager::RunModel函数。
模型输出后处理
- 调用OH_NNTensor_GetDataBuffer,获取输出的Tensor,在输出Tensor中会得到模型的输出数据。
- 对输出数据进行相应的处理可得到期望的结果。
例如本示例demo中模型的输出是1000个label的概率,期望得到这1000个结果中概率最大的三个标签。
- 销毁申请的Tensor资源和执行器实例。
上述流程可参见SampleCode中“entry/src/main/cpp/Classification.cpp”文件中的GetResult、UnloadModel函数和“entry/src/main/cpp/HiAiModelManager.cpp”中的HIAIModelManager::GetResult、HIAIModelManager::UnloadModel函数。
说明
用户可根据需要自行设置模型推理优先级。使用OH_NNCompilation_SetPriority接口,默认值为OH_NN_PRIORITY_NONE,本接口应在模型推理前调用。
4 单算子应用
4.1 概述
HiAI Foundation提供独立的算子创建和计算通路,三方框架可以在模型加载、推理过程中,将卷积、深度卷积等算子通过单算子对接的方式迁移至NPU,经过硬件平台的加速计算,与整网模式对比灵活度更高,相比于整网CPU计算性能更优。
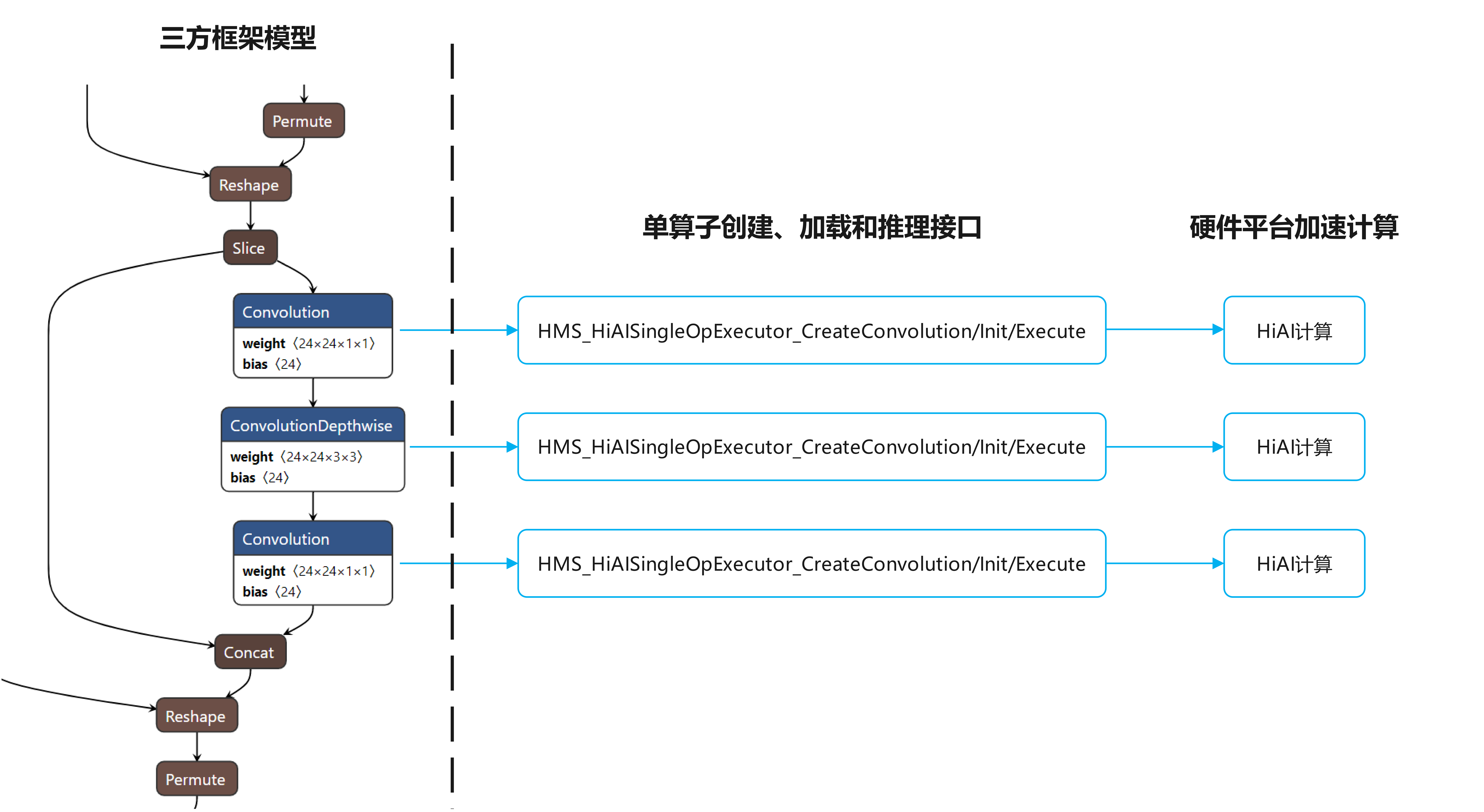
以下为单算子Tensor创建,单算子执行器创建、加载、执行接口,接口使用请参见开发步骤。如要使用更丰富的设置和查询接口,请参见API参考。
| 接口名 | 描述 |
|---|---|
| HiAI_SingleOpTensorDesc * HMS_HiAISingleOpTensorDesc_Create (const int64_t *dims, size_t dimNum, HiAI_SingleOpDataType dataType, HiAI_SingleOpFormat format, bool isVirtual); | 创建HiAI_SingleOpTensorDesc对象。 |
| void HMS_HiAISingleOpTensorDesc_Destroy (HiAI_SingleOpTensorDesc **tensorDesc); | 释放HiAI_SingleOpTensorDesc对象。 |
| HiAI_SingleOpBuffer * HMS_HiAISingleOpBuffer_Create (size_t dataSize); | 按照指定的内存大小创建HiAI_SingleOpBuffer对象。 |
| size_t HMS_HiAISingleOpBuffer_GetSize (const HiAI_SingleOpBuffer *buffer); | 查询HiAI_SingleOpBuffer的字节大小。 |
| void * HMS_HiAISingleOpBuffer_GetData (const HiAI_SingleOpBuffer *buffer); | 查询HiAI_SingleOpBuffer的内存地址。 |
| OH_NN_ReturnCode HMS_HiAISingleOpBuffer_Destroy (HiAI_SingleOpBuffer **buffer); | 释放HiAI_SingleOpBuffer对象。 |
| HiAI_SingleOpTensor * HMS_HiAISingleOpTensor_CreateFromTensorDesc (const HiAI_SingleOpTensorDesc *desc); | 根据HiAI_SingleOpTensorDesc创建HiAI_SingleOpTensor对象。 |
| HiAI_SingleOpTensor * HMS_HiAISingleOpTensor_CreateFromConst (const HiAI_SingleOpTensorDesc *desc, void *data, size_t dataSize); | 根据HiAI_SingleOpTensorDesc、常量数据(如卷积权重、偏置等)的内存地址和数据大小创建HiAI_SingleOpTensor对象。 |
| HiAI_SingleOpTensorDesc * HMS_HiAISingleOpTensor_GetTensorDesc (const HiAI_SingleOpTensor *tensor); | 获取HiAI_SingleOpTensor的Tensor描述。 |
| HiAI_SingleOpBuffer * HMS_HiAISingleOpTensor_GetBuffer (const HiAI_SingleOpTensor *tensor); | 获取HiAI_SingleOpTensor的Buffer。 |
| OH_NN_ReturnCode HMS_HiAISingleOpTensor_Destroy (HiAI_SingleOpTensor **tensor); | 释放HiAI_SingleOpTensor对象。 |
| HiAI_SingleOpOptions * HMS_HiAISingleOpOptions_Create (void); | 创建HiAI_SingleOpOptions对象。 |
| void HMS_HiAISingleOpOptions_Destroy (HiAI_SingleOpOptions **options); | 释放HiAI_SingleOpOptions对象。 |
| HiAI_SingleOpDescriptor* HMS_HiAISingleOpDescriptor_CreateConvolution(HiAISingleOpDescriptor_ConvolutionParamvolutionParam param); | 创建卷积类(普通卷积、转置卷积、深度卷积)的描述符对象。 |
| void HMS_HiAISingleOpDescriptor_Destroy (HiAI_SingleOpDescriptor **opDesc); | 释放HiAI_SingleOpDescriptor对象。 |
| HiAI_SingleOpExecutor* HMS_HiAISingleOpExecutor_CreateConvolution(HiAI_SingleOpExecutorConvolutionParam param); | 创建卷积类算子对应的HiAI_SingleOpExecutor对象。 |
| size_t HMS_HiAISingleOpExecutor_GetWorkspaceSize (const HiAI_SingleOpExecutor *executor); | 查询HiAI_SingleOpExecutor所需的ION内存工作空间的字节大小。 |
| OH_NN_ReturnCode HMS_HiAISingleOpExecutor_Init (HiAI_SingleOpExecutor *executor, void *workspace, size_t workspaceSize); | 加载HiAI_SingleOpExecutor。 |
| OH_NN_ReturnCode HMS_HiAISingleOpExecutor_Execute (HiAI_SingleOpExecutor *executor, HiAI_SingleOpTensor *input[], int32_t inputNum, HiAI_SingleOpTensor *output[], int32_t outputNum); | 执行同步运算推理。 |
| OH_NN_ReturnCode HMS_HiAISingleOpExecutor_Destroy (HiAI_SingleOpExecutor **executor); | 销毁HiAI_SingleOpExecutor对象,释放执行器占用的内存。 |
4.2 开发步骤
以下开发步骤以卷积单算子为例。
- 创建单算子执行器。
- 调用HMS_HiAISingleOpOptions_Create,创建单算子配置对象。
- 调用HMS_HiAISingleOpDescriptor_CreateConvolution,创建卷积类算子描述符对象。
- 调用HMS_HiAISingleOpTensor_CreateFromConst,分别创建卷积算子的权重、偏置单算子Tensor。
- 调用HMS_HiAISingleOpTensorDesc_Create,分别创建单算子输入Tensor、输出Tensor的描述对象。
- 调用HMS_HiAISingleOpExecutor_CreateConvolution,将上述创建好的卷积类算子描述符对象、卷积算子的权重Tensor、卷积算子的偏置Tensor、输入Tensor描述、输出Tensor描述作为输入,创建单算子执行器;
如果需要创建卷积算子与激活算子的融合算子执行器,还需要调用HMS_HiAISingleOpDescriptor_CreateActivation,创建激活类算子描述符对象,然后调用HMS_HiAISingleOpExecutor_CreateFusedConvolutionActivation创建融合算子执行器。
- 创建成功后,调用HMS_HiAISingleOpDescriptor_Destroy释放算子描述符对象,调用HMS_HiAISingleOpOptions_Destroy释放单算子创建配置对象。
- 创建输入/输出Tensor。
- 调用HMS_HiAISingleOpTensor_CreateFromTensorDesc,分别创建单算子输入Tensor、输出Tensor。
- 创建成功后,调用HMS_HiAISingleOpTensorDesc_Destroy释放Tensor描述符对象。
- 调用HMS_HiAISingleOpTensor_GetBuffer,获取输入/输出Tensor内部的Buffer对象。
- 调用HMS_HiAISingleOpBuffer_GetData,获取申请好的输入/输出ION内存地址,可用于该单算子在模型整网推理中的输入写入、输出读取。
- 加载单算子执行器。
- 调用HMS_HiAISingleOpExecutor_GetWorkspaceSize,获取已创建的单算子执行器在执行推理计算时需要的ION内存工作空间大小。
- 调用HMS_HiAISingleOpBuffer_Create,根据单算子执行器所需的ION内存工作空间大小创建足够的工作空间。
- 调用HMS_HiAISingleOpBuffer_GetData,获取申请好的ION内存工作空间的地址。
- 调用HMS_HiAISingleOpExecutor_Init,使用工作空间内存地址、工作空间大小,加载创建好的单算子执行器。
- 执行推理运算。
调用HMS_HiAISingleOpExecutor_Execute,执行同步运算推理。
- 卸载单算子执行器,释放资源。
- 调用HMS_HiAISingleOpTensor_Destroy,释放输入、输出Tensor对象
- 调用HMS_HiAISingleOpBuffer_Destroy,释放工作空间。
- 调用HMS_HiAISingleOpExecutor_Destroy,释放执行器对象。
4.3 示例说明
假定现在有一个深度卷积算子,输入维度为1x8x224x224,输入NCHW格式排布的float32类型数据,准备好NCHW排布的权重与偏置数据,调用单算子接口推理运算获得NCHW格式float32类型的输出可以参考如下示例代码:
// 示例算子参数
// 单算子卷积模式
HiAI_SingleOpConvMode convMode = HIAI_SINGLEOP_CONV_MODE_DEPTHWISE;
int64_t strides[2] = {1, 1};
int64_t dilations[2] = {1, 1};
int64_t pads[4] = {0, 0, 0, 0};
int64_t groups = 1;
// 单算子填充模式
HiAI_SingleOpPadMode padMode = HIAI_SINGLEOP_PAD_MODE_SAME;
int64_t filterDims[4] = {8, 1, 3, 3};
size_t filterDataSize = 8 * 1 * 3 * 3 * sizeof(float);
void* filterData = malloc(filterDataSize);
int64_t biasDims[1] = {8};
size_t biasDataSize = 8 * sizeof(float);
void* biasData = malloc(biasDataSize);
int64_t inputDims[4] = {1, 8, 224, 224};
HiAI_SingleOpDataType inputDataType = HIAI_SINGLEOP_DT_FLOAT;
// 单算子张量排布格式
HiAI_SingleOpFormat inputFormat = HIAI_SINGLEOP_FORMAT_NCHW;
bool inputIsVirtual = false;
// 若不指定算子输出数据类型和排布格式,请设置数据类型为HIAI_SINGLEOP_DT_UNDEFINED,排布格式为HIAI_SINGLEOP_FORMAT_RESERVED
// 在单算子创建完成后,调用HMS_HiAISingleOpExecutor_UpdateOutputTensorDesc,将输出Tensor描述更新为硬件适配最优的数据类型和排布格式
int64_t outputDims[4] = {1, 8, 224, 224};
HiAI_SingleOpDataType outputDataType = HIAI_SINGLEOP_DT_FLOAT;
HiAI_SingleOpFormat outputFormat = HIAI_SINGLEOP_FORMAT_NCHW;
bool outputIsVirtual = false;
// 创建单算子执行器
HiAI_SingleOpOptions* options = HMS_HiAISingleOpOptions_Create();
HiAISingleOpDescriptor_ConvolutionParam convOpDescCreateParam = {convMode, {0}, {0}, {0}, groups, padMode};
memcpy(convOpDescCreateParam.strides, strides, 2 * sizeof(int64_t));
memcpy(convOpDescCreateParam.dilations, dilations, 2 * sizeof(int64_t));
memcpy(convOpDescCreateParam.pads, pads, 4 * sizeof(int64_t));
// 创建卷积类的描述符对象
HiAI_SingleOpDescriptor* convOpDesc = HMS_HiAISingleOpDescriptor_CreateConvolution(convOpDescCreateParam);
// 创建一个单算子tensor描述对象,根据维度、数据类型和格式
HiAI_SingleOpTensorDesc* filterDesc = HMS_HiAISingleOpTensorDesc_Create(filterDims, 4, HIAI_SINGLEOP_DT_FLOAT, HIAI_SINGLEOP_FORMAT_NCHW, false);
// 创建一个单算子tensor对象
HiAI_SingleOpTensor* filter = HMS_HiAISingleOpTensor_CreateFromConst(filterDesc, filterData, filterDataSize);
HiAI_SingleOpTensorDesc* biasDesc = HMS_HiAISingleOpTensorDesc_Create(biasDims, 1, HIAI_SINGLEOP_DT_FLOAT, HIAI_SINGLEOP_FORMAT_NCHW, false);
HiAI_SingleOpTensor* bias = HMS_HiAISingleOpTensor_CreateFromConst(biasDesc, biasData, biasDataSize);
HiAI_SingleOpTensorDesc* inputDesc = HMS_HiAISingleOpTensorDesc_Create(inputDims, 4, inputDataType, inputFormat, inputIsVirtual);
HiAI_SingleOpTensorDesc* outputDesc = HMS_HiAISingleOpTensorDesc_Create(outputDims, 4, outputDataType, outputFormat, outputIsVirtual);
// 构造单算子卷子executor参数
HiAI_SingleOpExecutorConvolutionParam executorCreateParam = {options, convOpDesc, inputDesc, outputDesc, filter, bias};
// 创建卷积单算子executor
HiAI_SingleOpExecutor* executor = HMS_HiAISingleOpExecutor_CreateConvolution(executorCreateParam);
if (executor == nullptr) {
printf("HMS_HiAISingleOp executor create failed. \n");
}
// 对不需要的资源建议即时销毁
HMS_HiAISingleOpTensorDesc_Destroy(&filterDesc);
HMS_HiAISingleOpTensorDesc_Destroy(&biasDesc);
HMS_HiAISingleOpOptions_Destroy(&options);
HMS_HiAISingleOpDescriptor_Destroy(&convOpDesc);
OH_NN_ReturnCode ret = HMS_HiAISingleOpTensor_Destroy(&filter);
if (ret != OH_NN_SUCCESS) {
printf("HMS_HiAISingleOp filter destroy failed.\n");
}
ret = HMS_HiAISingleOpTensor_Destroy(&bias);
if (ret != OH_NN_SUCCESS) {
printf("HMS_HiAISingleOp bias destroy failed.\n");
}
// 创建输入/输出Tensor
HiAI_SingleOpTensor* input = HMS_HiAISingleOpTensor_CreateFromTensorDesc(inputDesc);
HMS_HiAISingleOpTensorDesc_Destroy(&inputDesc);
HiAI_SingleOpTensor* output = HMS_HiAISingleOpTensor_CreateFromTensorDesc(outputDesc);
HMS_HiAISingleOpTensorDesc_Destroy(&outputDesc);
// 单算子输入Tensor和输出Tensor的内存必须为ION内存以节省拷贝开销
// 创建输入Tensor成功后,可以使用以下方式获取输入Tensor内的ION内存地址进行输入数据填装
// 输出Tensor内的ION内存地址也可以用以下方式获取,在推理计算成功后用于输出数据读取
HiAI_SingleOpBuffer* inputBuffer = HMS_HiAISingleOpTensor_GetBuffer(input);
void* inputData = HMS_HiAISingleOpBuffer_GetData(inputBuffer);
size_t inputDataSize = HMS_HiAISingleOpBuffer_GetSize(inputBuffer);
memset(inputData, 0, inputDataSize);
// 查询单算子执行器所需的ION内存工作空间的字节大小
size_t workspaceSize = HMS_HiAISingleOpExecutor_GetWorkspaceSize(executor);
// 若存在多个单算子执行器,各个执行器的工作空间内存可以复用,只需要申请所需的最大工作空间即可
HiAI_SingleOpBuffer* workspaceBuffer = HMS_HiAISingleOpBuffer_Create(workspaceSize);
void* workspace = HMS_HiAISingleOpBuffer_GetData(workspaceBuffer);
ret = HMS_HiAISingleOpExecutor_Init(executor, workspace, workspaceSize);
if (ret != OH_NN_SUCCESS) {
printf("HMS_HiAISingleOp executor init failed.\n");
}
// 执行推理运算
HiAI_SingleOpTensor* inputs[] = {input};
HiAI_SingleOpTensor* outputs[] = {output};
ret = HMS_HiAISingleOpExecutor_Execute(executor, inputs, 1, outputs, 1);
if (ret != OH_NN_SUCCESS) {
printf("HMS_HiAISingleOp executor execute failed.\n");
}
// 卸载单算子执行器,释放资源
ret = HMS_HiAISingleOpTensor_Destroy(&input);
if (ret != OH_NN_SUCCESS) {
printf("HMS_HiAISingleOp input destroy failed.\n");
}
ret = HMS_HiAISingleOpTensor_Destroy(&output);
if (ret != OH_NN_SUCCESS) {
printf("HMS_HiAISingleOp output destroy failed.\n");
}
ret = HMS_HiAISingleOpBuffer_Destroy(&workspaceBuffer);
if (ret != OH_NN_SUCCESS) {
printf("HMS_HiAISingleOp workspaceBuffer destroy failed.\n");
}
ret = HMS_HiAISingleOpExecutor_Destroy(&executor);
if (ret != OH_NN_SUCCESS) {
printf("HMS_HiAISingleOp executor destroy failed.\n");
}
free(filterData);
free(biasData);
















 9420
9420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









