






mybatis基础复习
1.mybatis基础知识
mybatis执行流程
-
我们知道,每个sqlsessionfactory中有能有一种环境,但是配置文件可以配置多个环境,怎么在java中实现多个环境以供选择?
-
通过创建不同的sqlsessionfactoryBuidler实现
-
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment); SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment, properties);
-
-
sqlsession和sqlsessionfactory
-
- 为什么sqlsessionfactory要一致存在?
- sqlsession有哪些资源?
-
-
mybatis执行流程
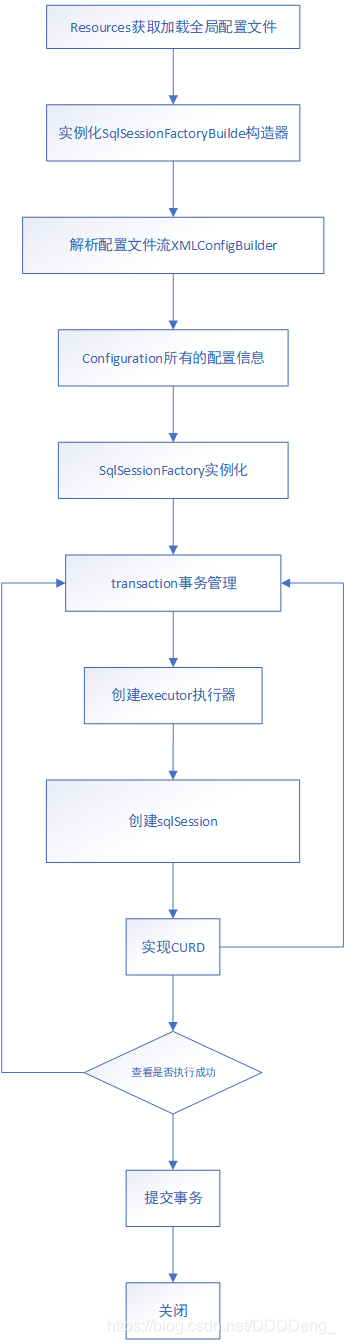
核心类对象和方法:
Resources:
resource方式加载配置文件;
SqlSessionFactoryBuilder:(设计者模式)构造SqlSessionFactory,很显然这个builder只需要构造出SqlSessionFactory就可以销毁了
1.读取reources的文件流;
2.加载配置文件;
3.构造SqlSessionFactory;
**SqlSessionFactory:**一般而言,在整个应用程序生命周期中没有任何理由销毁和替换SqlSessionFactory
1.创建和管理数据库会话;
SqlSession:显然其只在需要执行事务时有效,执行完应该关闭(以归还数据库连接资源)
1.SqlSession:数据库会话;
实现类是:DefaultSqlSession;
DefaultSqlSession:1.创建执行器Executor;
Executor mybatis执行真正的数据库操作的对象;(JDBC的获取连接connnect、创建事务prepareStatement(statement)、执行executeXXX、保存缓存(如果开启二级还有保存二级缓存))
复杂数据类型的结果映射
<!-- 非常复杂的结果映射 -->
<resultMap id="detailedBlogResultMap" type="Blog">
<constructor>
<idArg column="blog_id" javaType="int"/>
</constructor>
<result property="title" column="blog_title"/>
<association property="author" javaType="Author">
<id property="id" column="author_id"/>
<result property="username" column="author_username"/>
<result property="password" column="author_password"/>
<result property="email" column="author_email"/>
<result property="bio" column="author_bio"/>
<result property="favouriteSection" column="author_favourite_section"/>
</association>
<collection property="posts" ofType="Post">
<id property="id" column="post_id"/>
<result property="subject" column="post_subject"/>
<association property="author" javaType="Author"/>
<collection property="comments" ofType="Comment">
<id property="id" column="comment_id"/>
</collection>
<collection property="tags" ofType="Tag" >
<id property="id" column="tag_id"/>
</collection>
<discriminator javaType="int" column="draft">
<case value="1" resultType="DraftPost"/>
</discriminator>
</collection>
</resultMap>
constructor: association: collection: discriminator:
- 在日常使用中,我们常常会使用到一对一,一对多、多对一,多对多;
-
constructor

(下面下个都可以通过子查询、分治【即类型为resultMap来简化本resultMap】,因此常用于联级查询;可以参数如下)
association(对象)常用于1-1关联【详细看离线网页:Mybatis中使用association进行关联的几种方式 - 博客园】
作用和collection的相关属性类型

collection(复杂类型)

2.文档阅读
动态sql
1.动态sql关键字:if、choose、trim、foreach、
if:简单条件选择拼接,官方例子场景为:我们在提供多关键字搜索服务时,根据关键字是否输入拼接sql
<select id="" resultType="">
SELECT *
FROM POST P
WHERE
a = a
<if test="name!=null"> AND name like #{name}</if>
<if test="year!=null"> AND year > #{year}</if>
</select>
<!--
注意到where语句中出现了没用的 a=a;之所以如此是为了避免上面俩个if中任意一个匹配出现多余的AND关键字;类似的操作还有很多;因此后面有了trim帮助 我们自动去除多余关键字,避免类似烦恼;
除此之外,like关键字需要我们的name带有通配符:%、_;显然如果通过代码添加%、_非常不合适且麻烦,因此下面将介绍:<bind>绑定元素来添加字段的通配符 等;
-->
choose(when\otherwise):相当于java的switch语句;此时下面条件只能是when的一个,当所有when均不符合时将选择otherwise语句
<select id="" resultType="">
SELECT *
FROM POST P
WHERE
a = a
<choose>
<when test="name!=null">AND name like #{name}</when>
<when test="year>0">AND year> #{year}</when>
<otherwise>
</otherwise>
</choose>
</select>
trim:很多时候简单的if拼接并不能满足我们的需求,因此,可以通过trim进行高级拼接,通过配置可以去除拼接语句的一些错误;
在mybatis中已经封装了俩个trim:分别是<where></where>、<set></set>
trim的核心是:prefix:前缀拼接、subffix:后缀拼接、prefixOverrides:前缀去除、suffixOverrides:后缀去除;例如我们的where前缀需要拼接where、前缀需要去除 AND、OR等,set前缀需要拼接set、后缀需要去除,;因此,通过灵活配置,我们可以实现自定义set、where等
<select id="" resultType="">
SELECT *
FROM POST P
<trim prefix="where" prefixOverrides="AND|OR">
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</trim>
</select>
foreach:常用于对集合的遍历,特别是和IN配合使用,下面是官方例子
<select id="" resultType="">
SELECT *
FROM POST P
WHERE ID in
<foreach item="item" index="index" collection="list"
open="(" separator="," close=")">
#{item}
</foreach>
</select>
2.bind:绑定属性,对属性进行扩展
<select id="selectBlogsLike" resultType="Blog">
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
SELECT * FROM BLOG
WHERE title LIKE #{pattern}
</select>
3.script:注解的动态sql,一般不用
@Update({"<script>",
"update Author",
" <set>",
" <if test='username != null'>username=#{username},</if>",
" <if test='password != null'>password=#{password},</if>",
" <if test='email != null'>email=#{email},</if>",
" <if test='bio != null'>bio=#{bio}</if>",
" </set>",
"where id=#{id}",
"</script>"})
void updateAuthorValues(Author author);
mybatis配置
config配置

mapper配置
略
3.源码阅读(选读)
后文
补充知识
SqlSessionFactory:
-
再次强调SqlSessionFactory一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建一个实例。
-
因此SqlSessionFactory的最佳作用域是应用作用域(ApplocationContext)。
-
最简单的就是使用单例模式或静态单例模式。
SqlSession:
- 会话即连接到连接池的一个连接(封装了JDBC的connection)
- SqlSession 的实例不是线程安全的,因此是不能被共享的,所以应该在事务内部使用(所以它的最佳的作用域是请求或方法作用域。)
- 用完之后需要赶紧关闭,否则资源被占用!
问答
-
问:怎么在mysql中查询 %_%;即怎么让%_符号不在表示通配符:
答:通过escape表明去除转义后面的通配符含义,使之成为普通的字符;例如下面,注意此时仍然使用like
SELECT * FROM user WHERE username like /%/_/% escape ‘/’;
Mybatis实现
架构设置
JDBC基础
-
首先我们过去通过JDBC(基于JDBC讨论)操作MySQL首先需要的是对于连接管理,然后就是本线程使用该连接的管理;
- 因为连接是TCP连接,建立(3次握手)和释放(4次挥手)都需要大量的时间,建立的tcp连接还要进行MySQL安全校验(3次握手)。所以很明显可以使用数据传输层的复用的思想,但是由于MySQL的连接的特殊性(和事务挂钩),所以复用的连接只能是在同一个事务中复用;
-
然后就通过连接(就是会话)获取到PrepareStatement,由Statement进行sql语句的封装、提交执行和结果集的映射ResultSet(如果是SELECT);显然Statement在一个事务可以复用,相应的结果集也可以复用
-
然后就是对于结果集进行操作获取想要的数据,一般不通过结果集修改MySQL的数据(尽管可以这么做)
- 最后需要进行结果集和Statement的关闭,然后归还connection给连接池管理器以进行相应处理
前面的所有过程除了对于JDBC三个对象的管理外,最复杂的就是对于参数的sql拼接和结果集的映射都是使用编程完成的,这极其不合理且导致DAO层代码严重耦合(毕竟一个表的各种条件查询、结果集获取和封装操作实在重复有点多)
-
我们知道一次statement对应一个resultset、俩者具有相同的生命,所以statement显然是可以重用(在保证上一个resultset不在使用的情况下)
-
JDBC为了更好的利用网络资源(毕竟TCP数据首部也不短),所以(prepare)statement支持对于update的批处理(Batch)、批处理是在commit的时候一次提交;
-
JDBC允许设置最大的获取以保证不会因为大量获取记录条数(Fetch Size)挤爆内存,另外就是分页,分页对于数据库而言非常重要,毕竟一次获取大量数据意味着性能消耗,这里又有物理分页和逻辑分页(逻辑分页相当于没分页,仅仅就是查出来后简单的获取一部分),limit是物理分页,另外对于mysql语句性能分析参考mysql复习笔记,略
基于这种就到了怎么解耦;(DriverMassager就省略了相应的数据库连接池自然是对应相应的管理器)
- 首先就是连接的三个对象管理独立出来,通过相应的数据库连接池和工具进行管理;为了实现线程安全且不需要显示传入参数进入DAO,通过隐私创建局部变量+ThreadLocal进行传入,事务使用完成自动回收,不再由以后进行管理;
- 然后就是将sql语句的复用,允许进行sql拼接、动态修改,以减少sql语句的耦合(特别是非常复杂的sql语句)
- 对于sql语句中的参数设置独立出来,以实现扩展性,以后可以传入各种参数,处理器自动拼接
- 对于执行后的resultset由解析处理器对结果集进行映射;
架构图
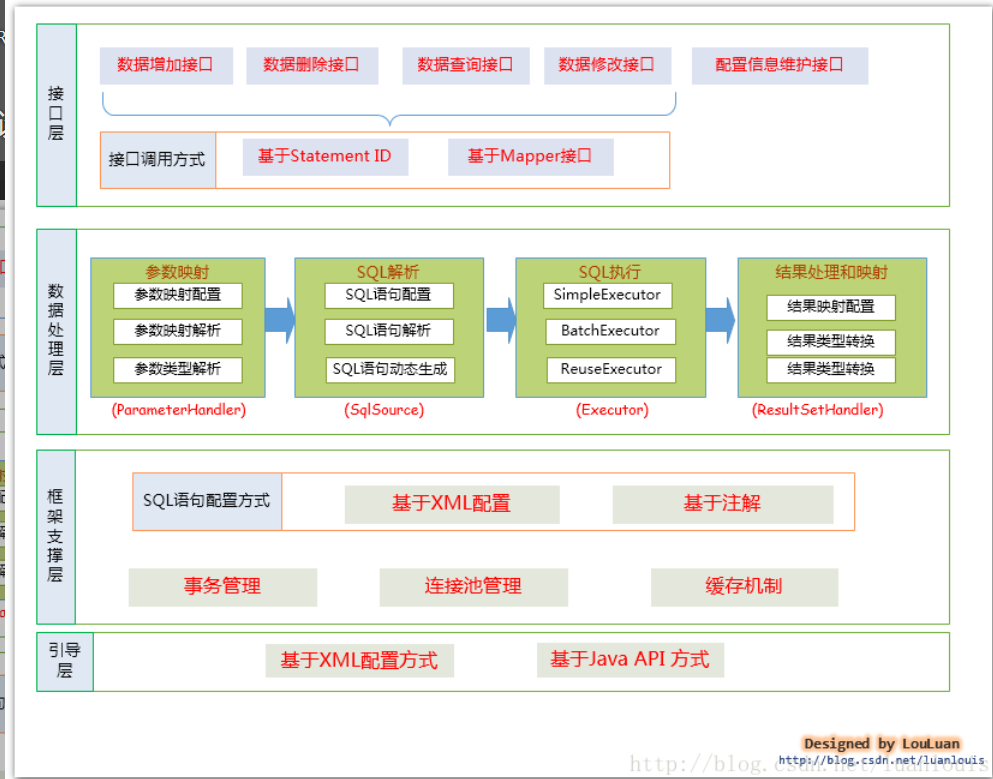

数据处理层显然是mybatis的核心,不过在这之前,我们先基于java实现mybatis的架构设置:纯java实现也非常简单,就是使用Configuration类(如果我们需要扩展Configuration可以实现自己的Configuration类)、Environment(Environment标签,以及其中的TransactionFactory、DataSource(就是对应的相应标签))、mapper标签就是addMapper、其他标签就是setXXX
@Component
@org.springframework.context.annotation.Configuration
@MapperScans(
@MapperScan("com.tianmao.dao")
)
public class MybatisFactoryBeanTestDao {
//通过java方式注入SqlSessionFactory
@Bean
public SqlSessionFactory getBean() {
return f;
}
//Configuration
static class MyMybatisConfig extends Configuration {
private static final String driver="";
private static final String url="";
private static final String username="";
private static final String password = "";
public MyMybatisConfig() {
super(new Environment("LocalEnvironment",new JdbcTransactionFactory(),new PooledDataSource(driver,url,username,password)));
}
//假装扩展了addMapper
@Override
public void addMapper(Class mapper) {
System.out.println("注册mapper:{}"+mapper.getSimpleName());
super.addMapper(mapper);
}
}
//SqlSessionFactory
private static final SqlSessionFactory f;
static {
f = new SqlSessionFactoryBuilder().build(new MyMybatisConfig());
Configuration configuration = f.getConfiguration();
configuration.setCacheEnabled(false);
configuration.setDefaultStatementTimeout(1000);
//……
}
//添加mapper空间(就是dao接口)
public static void addMapper(Class m) {
f.getConfiguration().addMapper(m);
}
//通过Configuration设置mybatis功能
public static Configuration getSession() {
return f.getConfiguration();
}
//获取会话,我们知道mybatis实现CRUD,可以通过mapper也可以通过sqlSession
public static SqlSession getSession(boolean autoCommit) {
return f.openSession(autoCommit);
}
public static void releaseSession(SqlSession sqlSession) {
sqlSession.close();
}
}
到这里基本mybatis架构就是实现了,我们使用了默认的jdbc的事务管理器和默认的mybatis数据库连接次POOLED,换句话说我们可以实现自己的事务处理器(Spring显然就是利用这一特性)、自己的数据库连接池(例如c3p0);所以这些都不是我们的重点,重点是数据处理层就是sql语句、然后就是将mapper接口转为Spring的bean,当然还有就是mybatis的一些一些性能的配置(前面已经说了);
经过上面我们知道,我们完全可以不配置mybatis.xml就能构造SqlSessionFactory,当然传入资源和解析也是可以;然后就是mapper,我们所有mapper接口都是没实现的,尽管我们使用xml配置了sql语句;换句话说显然需要mybatis通过JDK动态代理实现实现一个代理帮助我们实现相关的接口生成动态代理类,然后我们通过动态代理类实现JDBC操作;
mapper代理类的生成过程
前面我们已经实现了无配置生成SqlSessionFactory,所以mapper接口也不会通过xml配置(在Spring中通过MapperScan扫描指定包下的注解),所以跳过解析标签的阶段,直接到Configuration#addMapper
-
所有注册的mapper都通过Configuration#addMapper添加;
-
然后Configuration#addMapper调用MapperRegistry的addMapper,通过MapperRegistry保存MapperProxyFactory(即mapper的代理类),MapperRegistry保存了所有的MapperProxyFactory在HashMap中;这里需要注意俩点:
-
首先就是使用hashmap,说明不是线程安全的;但是MapperProxyFactory是线程安全的,里面俩个实例对象:class是final、保存方法的缓存的map是ConcurrentHashMap
-
生成的是MapperProxyFactory,不是真正代理类
-
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>(); public <T> void addMapper(Class<T> type) { //首先检查mapper是否为接口,如果不是显然不需要生成代理,也不会保存在MapperProxyFactory中 //这也是为什么spring-mybatis只能使用接口方式的原因 if (type.isInterface()) { //已存在? if (hasMapper(type)) { throw new BindingException("Type " + type + " is already known to the MapperRegistry."); } boolean loadCompleted = false; try { //前面说的HashMap<>(); knownMappers.put(type, new MapperProxyFactory<>(type)); //mapper注解构建器。 //解析指定的mapper接口对应的Class对象中,包含的所有mybatis框架中定义的注解,并生成Cache、ResultMap、MappedStatement三种类型对象 MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type); //解析 parser.parse(); loadCompleted = true; } finally { if (!loadCompleted) { knownMappers.remove(type); } } } }
-
-
当我们使用getMapper的时候就会调用通过MapperProxyFactory生成代理类MapperProxy,显然该handler实现了InvocationHandler接口,这样MapperProxyFactory就变成了真正的执行SqlSession的类;这里我们会传入SqlSession已确定该mapper的SqlSession类型(mybatis使用DefaultSqlSession,Spring使用SqlSessionTemplate)
-
这样mapper由接口到MapperProxyFactory再到MapperProxy就是完成了;
- 总结
- dao层或者说mapper的功能是单一的,就是实现和数据库交互,所以完全不用真正实现我们定义的mapper接口,mybatis只需要知道这个接口传入的的方法参数是什么、需要得到的参数是什么即可;
- 所以利用jdk动态代理:Proxy.newProxyInstance(classLoader, new Class[] { mapperInterface }, handler);仅仅只需要利用mapperInterface接口(完成方法绑定),并不需要handler记录被代理对象即可,真正实现调用SqlSession执行是在handler的invoke中
- 总结
-
在和spring整合的时候上面,就需要将上面的代理类注册到spring中;(以注解注入为例子)
- 首先需要利用Spring的扩展功能,实现支持接口的注册
- BeanDefinitionRegistryPostProcessor重写postProcessBeanDefinitionRegistry
- 除了设置基本信息外,增加了scanner.registerFilters();以实现对于接口的扫描和注册;
- 开始扫描,继承了ClassPathBeanDefinitionScanner,对于扫描进行了处理
- 利用ClassPathBeanDefinitionScanner的doScan方法进行扫描注册(BeanDefinition)
- 重写processBeanDefinitions方法,对注册的BeanDefinition属性进行修改,特别是修definition.setBeanClass修改了BeanDefinition的class由接口变为MapperFactoryBean.Class;很明显这是一个FactoryBean,同时其由实现了SqlSessionDaoSupport通过addMapper;
- SqlSessionDaoSupport继承了DaoSupport,DaoSupport实现了InitializingBean。InitializingBean的作用是在Spring初始化bean对象时会首先调用InitializingBean的afterPropertiesSet()方法。
- 最后通过FactoryBean的getObject调用getMapper完成整个注入SpringIoc容器过程
- 首先需要利用Spring的扩展功能,实现支持接口的注册
所以重点就是搞懂SqlSession;
核心类
SqlSession

- DefaultSqlSession :只能在单线程使用的,其线程不安全,主要表现在connection不安全;
- SqlSessionManager :在多线程环境下使用,使用ThreadLocal,注意其还实现了SqlSessionFactory,不过现在更多使用DefaultSqlSessionFactory创建sqlSession;
- SqlSessionTemplate:显然是Spring使用的SqlSession的模板,该类同样是线程安全的;
SqlSession接口:sql会话的顶层设置(无论是一系列简单的CRUD、还是使用不过现在基本基于mapper.xml设置的sql语句都是通过SqlSession进行的)
SqlSessionFactory:获取和回收SqlSession,在Spring-Mybatis中通过FactoryBean注入SqlSessionFactory;
SqlSession有四大组件帮助其完成:参数解析(ParameterHandler)、执行(Executor)、结果解析(ResultHandler)、会话管理(StatementHandler)
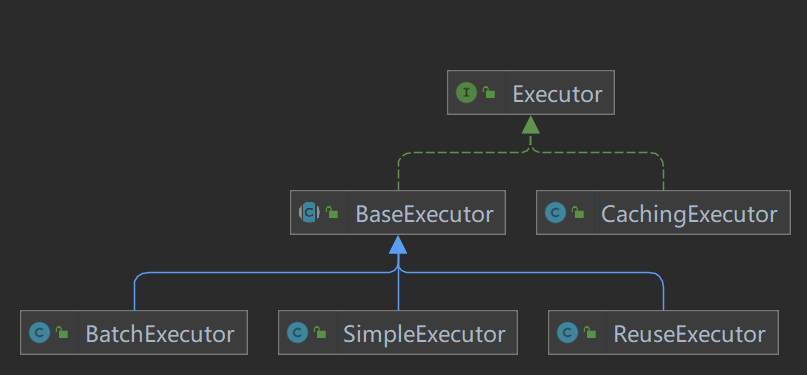
Executor
- 执行器分为俩大类:二级缓存执行器CachingExector和(一级缓存)基本执行器BaseExecutor
- CachingExector显然只有开启二级缓存时才有效,主要是在query(select操作)前检查缓存中数据是否存在,在update前检查是否需要清空缓存(如果未设置将默认清空)
- BaseExecutor只有一级缓存,换句话说就是在当前事务缓存才有效,也只检查一级缓存,sqlSession关闭这失效;
- BaseExecutor的三个子处理器(执行器)
- SimpleExecutor:默认简单执行器,既没有批处理功能、每次执行sql还都是新的Statement;
- 内部的实现是通过一个HashMap来维护Statement对象的。由于当前Map只在该session中有效,所以使用完成后记得调用
flushStatements来清除Map;
- 内部的实现是通过一个HashMap来维护Statement对象的。由于当前Map只在该session中有效,所以使用完成后记得调用
- BatchExector:批执行器(当然使用的是jdbc的批处理器模式,具有jdbc批处理特点;所以只有update有效)
- ReuseExecutor:可重用执行器,重用的是statement,不过这里重用仅仅是相同sql语句重用,换句话说不同的sql语句(mapper方法)不会重用statement,statement会在map保持;map只在该session中有效,所以使用完成后记得调用
flushStatements来清除Map
- SimpleExecutor:默认简单执行器,既没有批处理功能、每次执行sql还都是新的Statement;
StatementHandler
-
很明显,statementHandler就是连接前面的(connection、prepareStatement、resultset的)
-
前面我们说过Executor了,StatementHandler和这个有相似的设置思路分别有两个实现类 BaseStatementHandler 和 RoutingStatementHandler ,BaseStatementHandler 有三个实现类, 他们分别是 SimpleStatementHandler、PreparedStatementHandler 和 CallableStatementHandler。
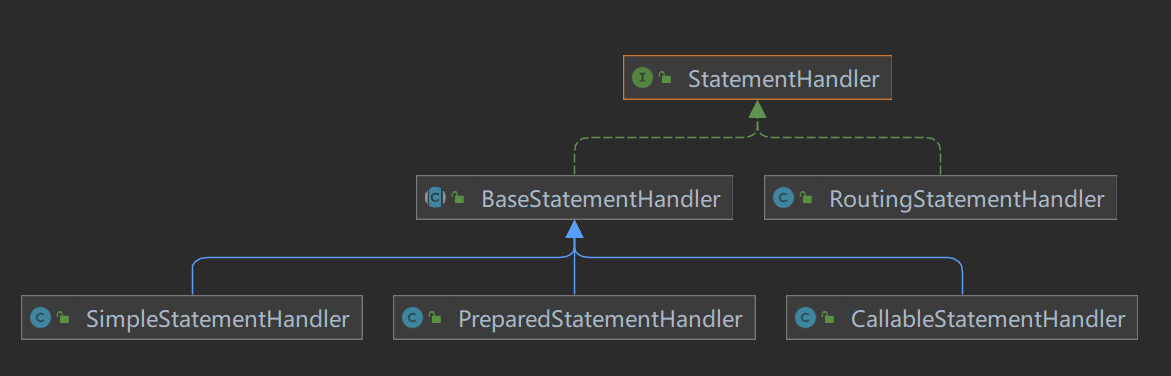
- RoutingStatementHandler:路由构造StatementHandler,就是我们配置mapper的方法的statementHandler时,其会保持在RoutingStatementHandler中,具体还是下面三个handler;简单来说就是一个封装类,它不提供具体的实现,只是根据Executor的类型,创建不同的类型StatementHandler
- SimpleStatementHandler:相当于statement
- PreparedStatementHandler :相当于prepareStatement
- CallableStatementHandler:调用数据库中的存储过程
-
BaseStatementHandler 实现了封装数据
-
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException { ErrorContext.instance().sql(boundSql.getSql()); Statement statement = null; try { statement = instantiateStatement(connection); setStatementTimeout(statement, transactionTimeout); setFetchSize(statement); return statement; } catch (SQLException e) { closeStatement(statement); throw e; } catch (Exception e) { closeStatement(statement); throw new ExecutorException("Error preparing statement. Cause: " + e, e); } }
ParameterHandler
很明显就是设置参数的,实现我们在JDBC的statement.setXXXX;
ResultHandler
结果解析器,显然这个会比较变态(我们各种ResultMap、1对一、1对多等等都是靠他解析
数据处理层
既然是通过SqlSession执行,就由此分析:以selectList为例子
//mapper全限定名+方法名(或者alias+方法名)、参数
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
//
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//MappedStatement显然就是封装的mapper的方法对应的statement
MappedStatement ms = configuration.getMappedStatement(statement);
//executor执行,那么executor哪来的呀,再回到
//wrapCollection显示是第二个重点就是封装参数为指定的名称的Collection类型,方便后面解析
//Executor.NO_RESULT_HANDLER:没有对应的处理器,那显然不是我们想要的,先不管,一路点击进入(跳过crash)
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
//最后来到BatchExecutor#doQuery
public <E> List<E> doQuery(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException {
Statement stmt = null;
try {
flushStatements();
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameterObject, rowBounds, resultHandler, boundSql);
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
SqlSession执行流程
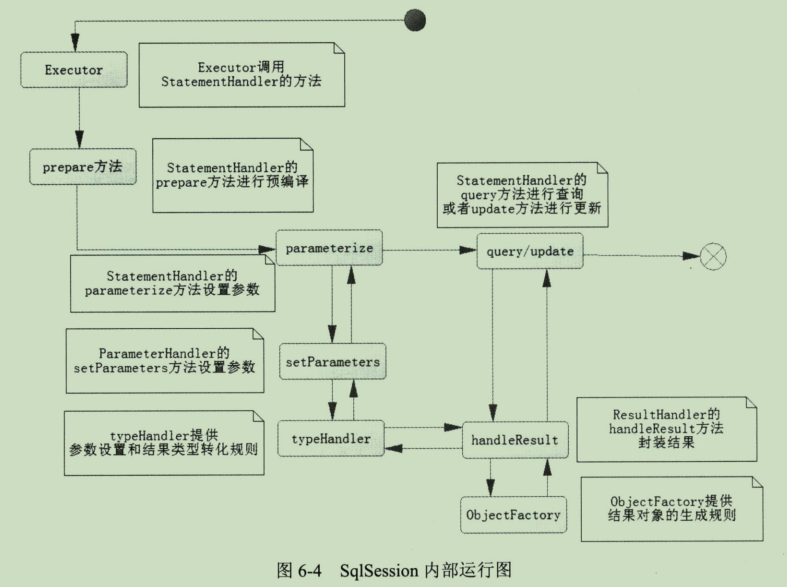



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











