



 本文介绍了K最近邻(KNN)算法,它是一种监督学习算法,用于分类和回归任务,通过计算样本距离进行分类。还阐述了利用KNN算法实现电影分类,以及ROC曲线评估分类模型性能,最后总结了KNN算法优缺点和适用场景。
本文介绍了K最近邻(KNN)算法,它是一种监督学习算法,用于分类和回归任务,通过计算样本距离进行分类。还阐述了利用KNN算法实现电影分类,以及ROC曲线评估分类模型性能,最后总结了KNN算法优缺点和适用场景。
目录
一、knn算法
K最近邻(K-Nearest Neighbors,KNN)算法是一种简单而有效的监督学习算法,用于分类和回归任务。它的基本原理是基于实例的学习,通过计算新样本与训练集中的样本之间的距离来进行分类或回归。
1.1、knn算法工作原理:
- 距离度量:KNN算法首先需要定义一个距离度量方法,通常使用欧式距离或曼哈顿距离来度量样本之间的相似度。
- 选择K值:确定K值,即要考虑的最近邻居的数量。K值的选择会影响算法的性能,通常通过交叉验证来确定。
- 找到最近邻居:对于新的测试样本,计算它与训练集中所有样本的距离,并选择距离最近的K个样本作为它的最近邻居。
- 分类或回归:对于分类任务,通过投票机制(多数表决)来确定测试样本所属的类别,即选择K个最近邻居中最常见的类别作为预测结果。对于回归任务,通常取K个最近邻居的平均值作为预测结果。
1.2、距离度量
我是使用欧式距离来度量样本之间的距离,公式如下:
二维空间的公式


1.3、例子
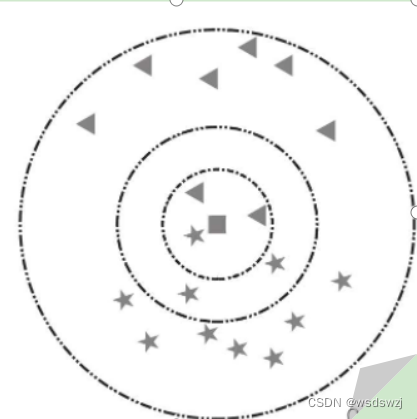
knn算法就是根据最近的几个东西的类别来判断这个未知东西的类别,遵从少数服从多数的原则。比如图中的正方形是未知的东西,然后把k值设为3,那么他就会去寻找距离正方形最近的3个东西,你可以从图中看到距离正方形最近的有两个三角形与一个五角星,那么他就会被判定为与三角星是一个类型的东西,若将k值设为5,那么就会出现三个五角星与两个三角形那么他就会被判定为与五角星一个类型的东西。
二、实现电影分类
2.1、该代码所需导入的库
import numpy as np # 导入NumPy库,用于处理数组和矩阵等数值计算
import operator # 导入operator模块,用于进行一些操作符相关的函数
import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
from sklearn.metrics import roc_curve, auc # 从sklearn.metrics模块中导入ROC曲线相关的函数2.2、该函数是导入数据集,我是使用手动输入数据集,也可以使用文件导入
def createDateSet():
group = np.array([[20, 101], [2, 102], [100, 1], [5, 110], [110, 10],
[30, 102], [100, 20], [50, 110], [110, 50], [20, 105],
[90, 30], [70, 105], [120, 40], [80, 100], [10, 90],
[40, 5], [60, 90], [100, 60], [20, 50], [10, 100],
[105, 25], [55, 95], [115, 45], [5, 85], [15, 95],
[35, 15], [30, 65], [125, 55], [55, 80], [5, 95],
[106, 15], [58, 85], [112, 48], [58, 88], [18, 88],
[38, 18], [35, 68], [128, 60], [78, 85], [8, 98],
[107, 22], [60, 80], [114, 52], [72, 82], [82, 12],
[12, 42], [72, 40], [65, 122], [95, 72], [1, 108]])
labels = ['爱情片', '爱情片', '动作片', '爱情片', '动作片',
'爱情片', '动作片', '爱情片', '动作片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '动作片',
'爱情片', '动作片', '爱情片', '动作片', '爱情片']
return group, labels# 返回数据集的特征和标签2.3、该函数是通过欧式距离公式来计算测试点与训练样本点之间的距离,然后记录距离较近的k个点,通过哪种类型的点多,就判断该测试点为什么类型的影片。k值对于knn算法的正确率有着很大的影响,需要进行思考并多次尝试选出正确率最高的看值。
def classify0(inX, dataSet, labels, k): # k近邻分类函数
dataSetSize = dataSet.shape[0] # 获取数据集的行数
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 计算测试样本与每个训练样本的差值
sqDiffMat = diffMat ** 2 # 计算差值的平方
sqDistance = sqDiffMat.sum(axis=1) # 计算每行平方的和
distance = sqDistance ** 0.5 # 计算欧氏距离
sortedDistIndices = distance.argsort() # 对距离进行排序并返回排序后的索引
classCount = {} # 创建一个字典,用于存储每个类别的出现次数
for i in range(k): # 遍历前k个最近邻样本
voteIlabel = labels[sortedDistIndices[i]] # 获取第i个最近邻样本的类别
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 统计每个类别出现的次数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 对类别出现次数进行排序
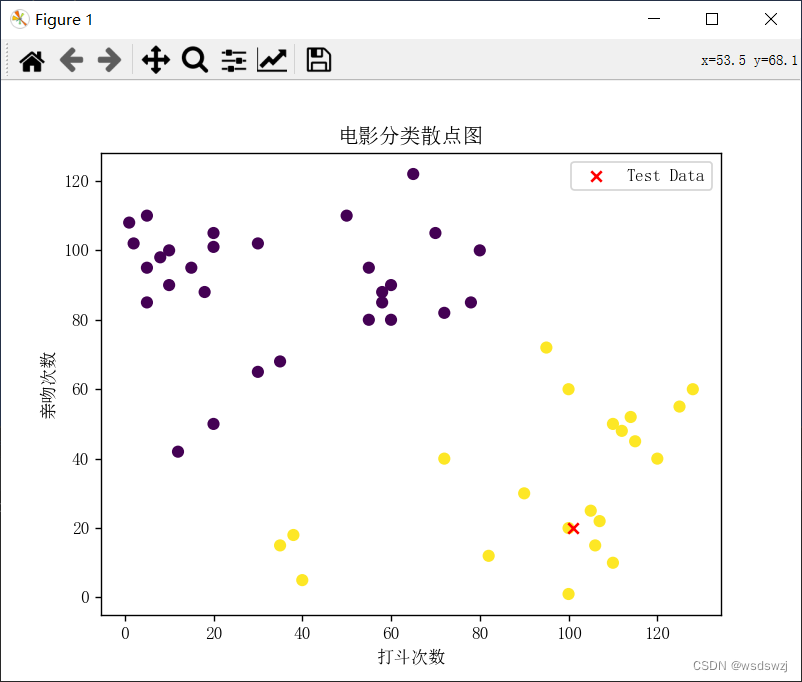
return sortedClassCount[0][0] # 返回出现次数最多的类别2.4、该函数是利用库来进行散点图的绘制
def plotScatter(group, labels, test): # 绘制散点图函数
fig = plt.figure() # 创建一个新的图形
ax = fig.add_subplot(111) # 添加一个子图
plt.rcParams['font.sans-serif'] = ['SimSun'] # 设置中文字体为宋体
ax.scatter(group[:, 0], group[:, 1], c=[0 if label == '爱情片' else 1 for label in labels], marker='o') # 绘制训练样本散点图
ax.scatter(test[0], test[1], c='r', marker='x', label='Test Data') # 绘制测试样本的散点图
ax.legend() # 显示图例
plt.xlabel('打斗次数') # 设置x轴标签
plt.ylabel('亲吻次数') # 设置y轴标签
plt.title('电影分类散点图') # 设置标题
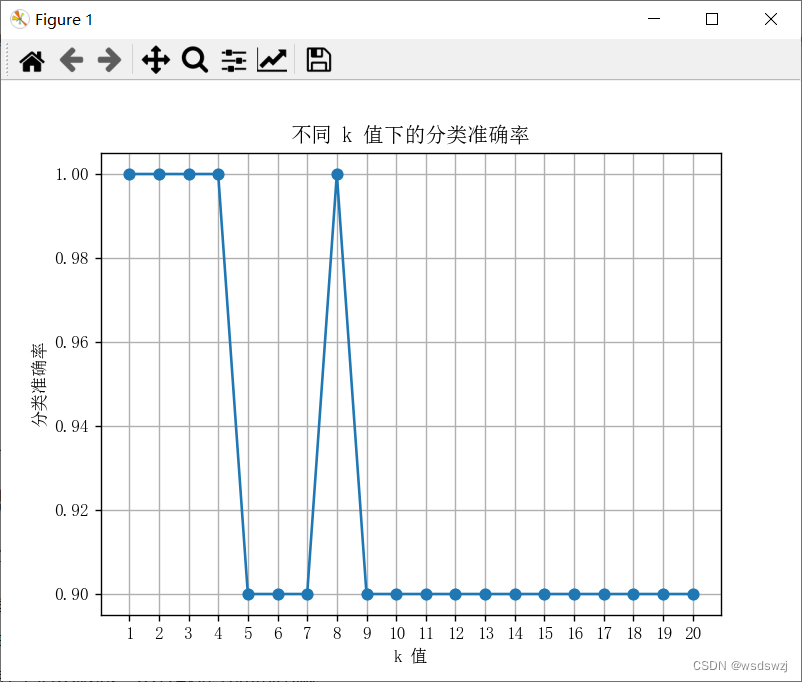
plt.show() # 显示图形2.5、这是用来测试测试集在不同k值的情况下正确率的情况,我这是是显示了k值为1-20的准确率图像
def getAccuracy(test_labels, pred_labels): # 计算分类准确率函数
correct_count = 0 # 初始化正确分类的样本数量为0
for i in range(len(test_labels)): # 遍历测试样本的标签
if test_labels[i] == pred_labels[i]: # 如果预测标签与真实标签相同
correct_count += 1 # 正确分类的样本数量加1
accuracy = correct_count / len(test_labels) # 计算准确率
return accuracy # 返回准确率 # 初始化准确率列表
accuracies = []
# 测试不同的 k 值
ks = range(1, 21)
for k in ks:
# 构造测试数据集
test_data = np.array([[20, 101], [2, 102], [40, 40], [5, 110], [110, 10],
[30, 102], [100, 20], [50, 110], [110, 50], [20, 105]])
# 构造测试数据标签
test_labels = ['爱情片', '爱情片', '动作片', '爱情片', '动作片',
'爱情片', '动作片', '爱情片', '动作片', '爱情片']
# 使用 k 近邻算法对测试数据进行分类
pred_labels = [classify0(data, group, labels, k) for data in test_data]
# 计算分类准确率
accuracy = getAccuracy(test_labels, pred_labels)
# 将准确率添加到列表中
accuracies.append(accuracy)
# 绘制不同 k 值下的分类准确率曲线
plt.plot(ks, accuracies, marker='o')
plt.rcParams['font.sans-serif'] = ['SimSun']
plt.xlabel('k 值')
plt.ylabel('分类准确率')
plt.title('不同 k 值下的分类准确率')
plt.xticks(ks)
plt.grid(True)
plt.show()三、ROC曲线
3.1、ROC
ROC曲线(Receiver Operating Characteristic Curve)是一种用于评估分类模型性能的工具,特别是针对二分类问题。它以真阳性率(True Positive Rate,又称为灵敏度)为纵轴,以假阳性率(False Positive Rate)为横轴,将不同阈值下的分类器性能可视化呈现。
在ROC曲线中,横轴表示假阳性率(False Positive Rate,FPR),
计算方法为:
其中,FP代表实际为负样本但被错误地预测为正样本的数量,TN代表实际为负样本且被正确地预测为负样本的数量。
纵轴表示真阳性率(True Positive Rate,TPR),也称为灵敏度(Sensitivity),
计算方法为:
其中,TP代表实际为正样本且被正确地预测为正样本的数量,FN代表实际为正样本但被错误地预测为负样本的数量。
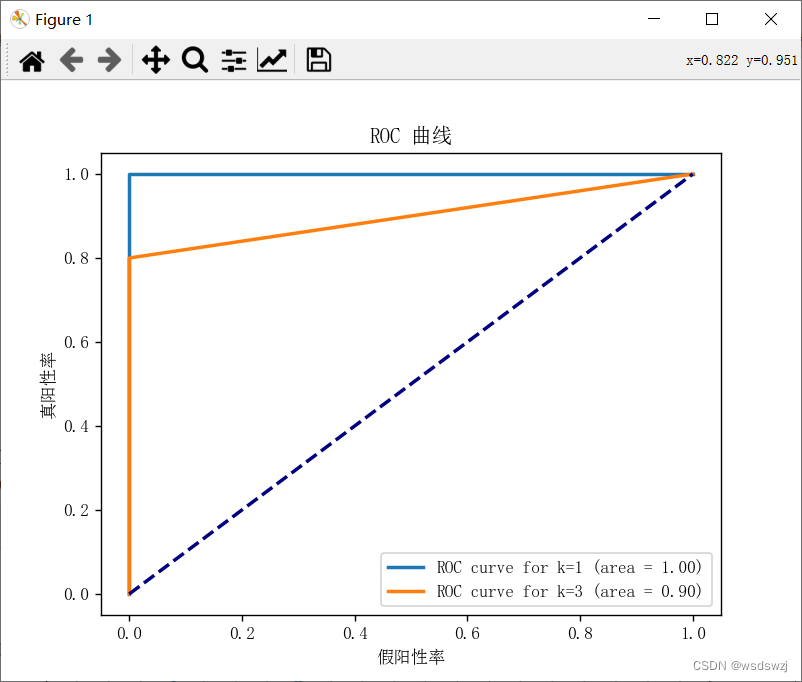
ROC曲线的绘制过程是,通过在不同的分类阈值下计算真阳性率和假阳性率,然后将这些点连接起来形成曲线。ROC曲线下方的面积(AUC,Area Under the Curve)是评估分类器性能的一个重要指标,AUC值越接近1,表示分类器性能越好;如果AUC为0.5,表示分类器的预测能力等同于随机猜测。
3.2、阈值
在二分类问题中,阈值是一个决策边界,用于将模型的输出分为两个类别。具体地说,当模型输出的概率或者得分大于等于阈值时,样本被划分为正类;反之,则划分为负类。阈值的选择对于模型的性能评估和应用非常重要。
通常情况下,阈值是根据具体应用的需求来确定的。在一些应用中,我们可能更注重准确率(Precision),希望尽量减少误报;而在另一些应用中,我们可能更关注召回率(Recall),希望尽量减少漏报。因此,根据具体应用场景,可以选择不同的阈值来平衡准确率和召回率,或者基于其他评价指标进行调整。
另外,阈值的选择也会影响到模型的 ROC 曲线和 AUC 值。通常情况下,我们会在 ROC 曲线上选择一个合适的操作点,该点对应的阈值通常是平衡真阳性率和假阳性率的一个点,以达到较好的分类性能。不同的阈值选择会导致 ROC 曲线上的不同点,进而影响到 AUC 值的大小。
3.3、绘制ROC曲线
由于我的数据太少显示出的roc曲线会不稳定或不可靠,建议增加一些数据进行评估
def plot_roc_curve_for_k(test_data, test_labels, k):
#计算测试数据集中每个样本的预测分数。使用 k 近邻算法 classify0() 对每个测试样本进行分类,
# 并将分类结果转换为 0 或 1,其中 1 表示类别为 '动作片',0 表示其他类别。
pred_scores = []
for data in test_data:
pred_score = classify0(data, group, labels, k)
pred_scores.append(1 if pred_score == '动作片' else 0) # 将标签转换为0和1
#调用 roc_curve 函数计算 ROC 曲线的假阳性率(FPR)、真阳性率(TPR)和阈值。
# test_labels 是测试数据的真实标签,pred_scores 是模型对测试数据的预测分数。
fpr, tpr, thresholds = roc_curve(test_labels, pred_scores)
#调用 auc 函数计算 ROC 曲线下的面积(AUC),用于评估分类器的性能。
roc_auc = auc(fpr, tpr)
#使用 plt.plot 函数绘制 ROC 曲线,并设置线宽(lw)、标签(label)以及 k 值和对应的 AUC 值。
plt.plot(fpr, tpr, lw=2, label='ROC curve for k=%d (area = %0.2f)' % (k, roc_auc))# 计算ROC曲线并绘制
test_data = np.array(
[[30, 102], [30, 20], [50, 110], [60, 50], [60, 105], [108, 30], [115, 15], [117, 20], [30, 95], [20, 112]])
test_labels = np.array([0, 1, 0, 1, 0, 1, 1, 1, 0, 0]) # 根据分类标签修改成0和1
# 定义不同的k值列表
k_values = [1, 3]
# 绘制不同k值下的ROC曲线
plt.figure()
for k in k_values:
plot_roc_curve_for_k(test_data, test_labels, k)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('假阳性率')
plt.ylabel('真阳性率')
plt.title('ROC 曲线')
plt.legend(loc="lower right")
plt.show()运行代码:
import numpy as np # 导入NumPy库,用于处理数组和矩阵等数值计算
import operator # 导入operator模块,用于进行一些操作符相关的函数
import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
from sklearn.metrics import roc_curve, auc # 从sklearn.metrics模块中导入ROC曲线相关的函数
def createDateSet():
group = np.array([[20, 101], [2, 102], [100, 1], [5, 110], [110, 10],
[30, 102], [100, 20], [50, 110], [110, 50], [20, 105],
[90, 30], [70, 105], [120, 40], [80, 100], [10, 90],
[40, 5], [60, 90], [100, 60], [20, 50], [10, 100],
[105, 25], [55, 95], [115, 45], [5, 85], [15, 95],
[35, 15], [30, 65], [125, 55], [55, 80], [5, 95],
[106, 15], [58, 85], [112, 48], [58, 88], [18, 88],
[38, 18], [35, 68], [128, 60], [78, 85], [8, 98],
[107, 22], [60, 80], [114, 52], [72, 82], [82, 12],
[12, 42], [72, 40], [65, 122], [95, 72], [1, 108]])
labels = ['爱情片', '爱情片', '动作片', '爱情片', '动作片',
'爱情片', '动作片', '爱情片', '动作片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '爱情片',
'动作片', '爱情片', '动作片', '爱情片', '动作片',
'爱情片', '动作片', '爱情片', '动作片', '爱情片']
return group, labels# 返回数据集的特征和标签
def classify0(inX, dataSet, labels, k): # k近邻分类函数
dataSetSize = dataSet.shape[0] # 获取数据集的行数
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 计算测试样本与每个训练样本的差值
sqDiffMat = diffMat ** 2 # 计算差值的平方
sqDistance = sqDiffMat.sum(axis=1) # 计算每行平方的和
distance = sqDistance ** 0.5 # 计算欧氏距离
sortedDistIndices = distance.argsort() # 对距离进行排序并返回排序后的索引
classCount = {} # 创建一个字典,用于存储每个类别的出现次数
for i in range(k): # 遍历前k个最近邻样本
voteIlabel = labels[sortedDistIndices[i]] # 获取第i个最近邻样本的类别
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 统计每个类别出现的次数
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 对类别出现次数进行排序
return sortedClassCount[0][0] # 返回出现次数最多的类别
def plotScatter(group, labels, test): # 绘制散点图函数
fig = plt.figure() # 创建一个新的图形
ax = fig.add_subplot(111) # 添加一个子图
plt.rcParams['font.sans-serif'] = ['SimSun'] # 设置中文字体为宋体
ax.scatter(group[:, 0], group[:, 1], c=[0 if label == '爱情片' else 1 for label in labels], marker='o') # 绘制训练样本散点图
ax.scatter(test[0], test[1], c='r', marker='x', label='Test Data') # 绘制测试样本的散点图
ax.legend() # 显示图例
plt.xlabel('打斗次数') # 设置x轴标签
plt.ylabel('亲吻次数') # 设置y轴标签
plt.title('电影分类散点图') # 设置标题
plt.show() # 显示图形
def getAccuracy(test_labels, pred_labels): # 计算分类准确率函数
correct_count = 0 # 初始化正确分类的样本数量为0
for i in range(len(test_labels)): # 遍历测试样本的标签
if test_labels[i] == pred_labels[i]: # 如果预测标签与真实标签相同
correct_count += 1 # 正确分类的样本数量加1
accuracy = correct_count / len(test_labels) # 计算准确率
return accuracy # 返回准确率
#绘制针对不同 k 值的 k 近邻算法在测试数据上的 ROC 曲线。
def plot_roc_curve_for_k(test_data, test_labels, k):
#计算测试数据集中每个样本的预测分数。使用 k 近邻算法 classify0() 对每个测试样本进行分类,
# 并将分类结果转换为 0 或 1,其中 1 表示类别为 '动作片',0 表示其他类别。
pred_scores = []
for data in test_data:
pred_score = classify0(data, group, labels, k)
pred_scores.append(1 if pred_score == '动作片' else 0) # 将标签转换为0和1
#调用 roc_curve 函数计算 ROC 曲线的假阳性率(FPR)、真阳性率(TPR)和阈值。
# test_labels 是测试数据的真实标签,pred_scores 是模型对测试数据的预测分数。
fpr, tpr, thresholds = roc_curve(test_labels, pred_scores)
#调用 auc 函数计算 ROC 曲线下的面积(AUC),用于评估分类器的性能。
roc_auc = auc(fpr, tpr)
#使用 plt.plot 函数绘制 ROC 曲线,并设置线宽(lw)、标签(label)以及 k 值和对应的 AUC 值。
plt.plot(fpr, tpr, lw=2, label='ROC curve for k=%d (area = %0.2f)' % (k, roc_auc))
if __name__ == '__main__':
# 创建数据集
group, labels = createDateSet()
# 测试集
test = [101, 20]
# kNN分类,这里设定 k=3
test_class = classify0(test, group, labels, 3)
# 打印分类结果
print(test_class)
# 绘制散点图,展示训练数据集和测试数据点
plotScatter(group, labels, test) # 调用绘制散点图函数
# 初始化准确率列表
accuracies = []
# 测试不同的 k 值
ks = range(1, 21)
for k in ks:
# 构造测试数据集
test_data = np.array([[20, 101], [2, 102], [40, 40], [5, 110], [110, 10],
[30, 102], [100, 20], [50, 110], [110, 50], [20, 105]])
# 构造测试数据标签
test_labels = ['爱情片', '爱情片', '动作片', '爱情片', '动作片',
'爱情片', '动作片', '爱情片', '动作片', '爱情片']
# 使用 k 近邻算法对测试数据进行分类
pred_labels = [classify0(data, group, labels, k) for data in test_data]
# 计算分类准确率
accuracy = getAccuracy(test_labels, pred_labels)
# 将准确率添加到列表中
accuracies.append(accuracy)
# 绘制不同 k 值下的分类准确率曲线
plt.plot(ks, accuracies, marker='o')
plt.rcParams['font.sans-serif'] = ['SimSun']
plt.xlabel('k 值')
plt.ylabel('分类准确率')
plt.title('不同 k 值下的分类准确率')
plt.xticks(ks)
plt.grid(True)
plt.show()
# 计算ROC曲线并绘制
test_data = np.array(
[[30, 102], [30, 20], [50, 110], [60, 50], [60, 105], [108, 30], [115, 15], [117, 20], [30, 95], [20, 112]])
test_labels = np.array([0, 1, 0, 1, 0, 1, 1, 1, 0, 0]) # 根据分类标签修改成0和1
# 定义不同的k值列表
k_values = [1, 3]
# 绘制不同k值下的ROC曲线
plt.figure()
for k in k_values:
plot_roc_curve_for_k(test_data, test_labels, k)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('假阳性率')
plt.ylabel('真阳性率')
plt.title('ROC 曲线')
plt.legend(loc="lower right")
plt.show()
运行结果:

四、总结:
1、knn算法优点:
- 简单易理解,易于实现。
- 适用于多种类型的数据,包括离散型和连续型数据。
- 对异常值不敏感,不受数据分布的影响。
2、knn算法缺点:
- 计算复杂度高,对于大规模数据集计算开销大。
- 需要大量的存储空间来保存训练数据。
- 对K值的选择敏感,选择不当可能导致模型性能下降。
使用场景:
- 数据集较小,或者对计算效率要求不高的情况。
- 数据集没有明显的类别边界或决策边界不规则的情况。
- 数据集的属性不是很多,且属性之间的关联性较弱的情况。

















 5937
5937




 到【灌水乐园】发言
到【灌水乐园】发言







