




RegExp 构造函数:
在 ES5 中,RegExp 构造函数的参数有两种情况:第一种情况是,参数是字符串,这时第二个参数表示正则表达式的修饰符;第二种情况是,参数是一个正则表达式,此时不允许使用第二个参数添加修饰符,否则会报错。
var regex = new RegExp('xyz', 'i');
// 等价于
var regex = /xyz/i;
var regex = new RegExp(/xyz/i);
// 等价于
var regex = /xyz/i;
var regex = new RegExp(/xyz/, 'i'); // Uncaught TypeError: Cannot supply flags when constructing one RegExp from another
ES6 改变了这种行为,如果 RegExp 构造函数第一个参数是一个正则对象,那么可以使用第二个参数指定修饰符,而且返回的正则表达式会忽略原有正则表达式的修饰符,只使用新指定的修饰符。
new RegExp(/abc/ig, 'i').flags // "i"
flags 属性:
ES6 为正则表达式新增了 flags 属性,返回正则表达式的修饰符。
// ES5 的 source 属性返回正则表达式的正文
/abc/ig.source // "abc"
// ES6 的 flags 属性返回正则表达式的修饰符
/abc/ig.flags // 'gi'
u 修饰符:
ES6 为正则表达式添加了 u 修饰符,含义为 “Unicode” 模式,用来正确处理大于\uFFFF的 Unicode 字符,也就是说,会正确处理四个字节的 UTF-16 编码。
/^\uD83D/u.test('\uD83D\uDC2A') // false
/^\uD83D/.test('\uD83D\uDC2A') // true
上面代码中,\uD83D\uDC2A是一个四个字节的 UTF-16 编码,代表一个字符。但是 ES5 不支持四个字节的 UTF-16 编码,会将其识别为两个字符,导致第二行代码结果为 true。加了 u 修饰符以后,ES6 就会识别其为一个字符,所以第一行代码结果为 false。
正则实例对象新增 unicode 属性,表示是否设置了 u 修饰符。
const r1 = /hello/;】
const r2 = /hello/u
r1.unicode // false
r2.unicode // true
y 修饰符:
ES6 为正则表达式添加了 y 修饰符,叫做"粘连修饰符"。y 修饰符的作用与 g 修饰符类似,也是全局匹配,后一次匹配都从上一次匹配成功的下一个位置开始。不同之处在于,g 修饰符只要剩余位置中存在匹配即可,而 y 修饰符必须确保匹配从剩余的第一个位置开始,这也就是"粘连"的含义。
var s = 'aaa_aa_a'
var r1 = /a+/g
var r2 = /a+/y
r1.exec(s) // ["aaa"]
r2.exec(s) // ["aaa"]
r1.exec(s) // ["aa"]
r2.exec(s) // null
var s = 'aaa_aa_a'
var r = /a+_/y
r.exec(s) // ["aaa_"]
r.exec(s) // ["aa_"]
ES6 的正则实例对象多了 sticky 属性,表示是否设置了 y 修饰符。
var r = /hello\d/y
r.sticky // true
s 修饰符:
正则表达式中,.是一个特殊字符,代表任意的单个字符。但是有两个例外,一个是四个字节的 UTF-16 字符,这个可以用 u 修饰符解决;另一个是行终止符。
所谓行终止符,就是该字符表示一行的终结。
以下四个字符属于行终止符:换行符 \n、回车符 \r、行分隔符,段分隔符。
/foo.bar/.test('foo\nbar') // false
ES2018 引入 s 修饰符,使得.可以匹配任意单个字符。这被称为 “dotAll” 模式,即点代表一切字符。
/foo.bar/s.test('foo\nbar') // true
正则表达式还引入了一个 dotAll 属性,返回一个布尔值,表示该正则表达式是否设置了 s 修饰符。
const re = /foo.bar/s
re.dotAll // true
命名捕获分组:
以前只能通过下标访问捕获到的分组。
const str = '<a href="http://baidu.com">百度</a>'
const reg = /<a href="(.*)">(.*)<\/a>/
const result = reg.exec(str)
console.log(result)
// 提取 url 与文本
console.log(result[1])
console.log(result[2])

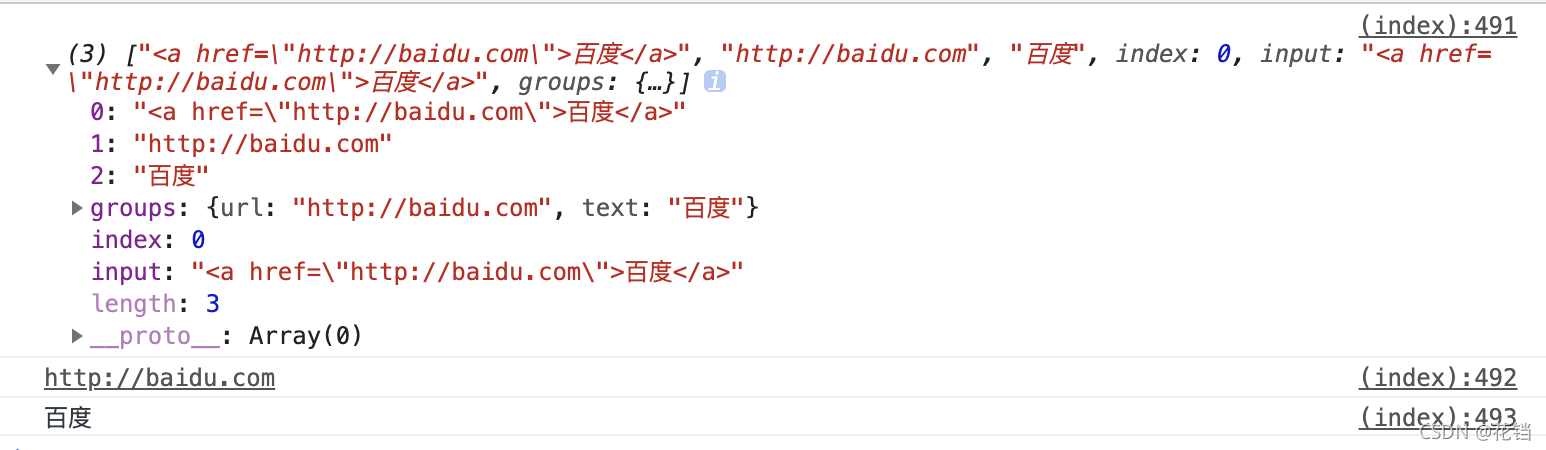
现在可以通过 ?<名称> 命名捕获到的分组,通过groups.名称 访问捕获到的分组。
const str = '<a href="http://baidu.com">百度</a>'
const reg = /<a href="(?<url>.*)">(?<text>.*)<\/a>/
const result = reg.exec(str)
console.log(result)
// 提取 url 与文本
console.log(result.groups.url)
console.log(result.groups.text)

















 89
89



 到【灌水乐园】发言
到【灌水乐园】发言








