




文章目录
1. 堆排序
堆排序可以帮助选数,本质是选择排序。
1)建堆的思考(时间复杂度计算)
利用向下调整算法和向上调整算法完成建堆,第一个数作为一个堆,后面的数依次进行插入,本质是模拟堆插入的过程
升序:建大堆;降序:建小堆
为什么是这样子的呢?拿升序建大堆为例进行讲解:
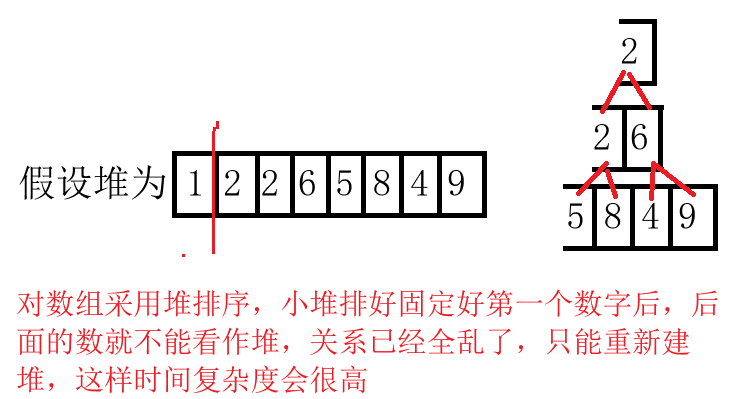
假设给出一个数组,要使用堆排序实现升序,如果这时建小堆,那么数组第一个数是最小的,那后面的数就需要重新建堆,而一次建堆的时间复杂度本身就是
O(NlogN),还需要重复n次这样的操作,即使看上去高大上,但实际效率十分低。
而采用大堆进行升序时,能够确定最大的数,这样就可以对数组首尾交换,从而实现固定最大的数字。这样原本的堆再利用堆删除的思想,就可以保证堆的关系不会乱,时间复杂度此时变成了:建堆
O(NlogN),选数O(N-1)logN,总的时间复杂度就是相加,就变成了O(NlogN),这个算法的量级也就下降了(时间复杂度是判定算法的量级,即使相同时间复杂度的算法,他们的量级也会有区别)
那还有更高效的建堆方法吗?答案就是直接利用向下调整算法!
从倒数第一个非叶子,即最后一个节点的父亲开始调整,这样可以减少一般的时间复杂度,而且调整的方式也会改变,从而使其更快
建堆的两个时间复杂度将在最后进行分析。

2)利用堆删除思想来进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序,下面将根据上述的思路进行升序
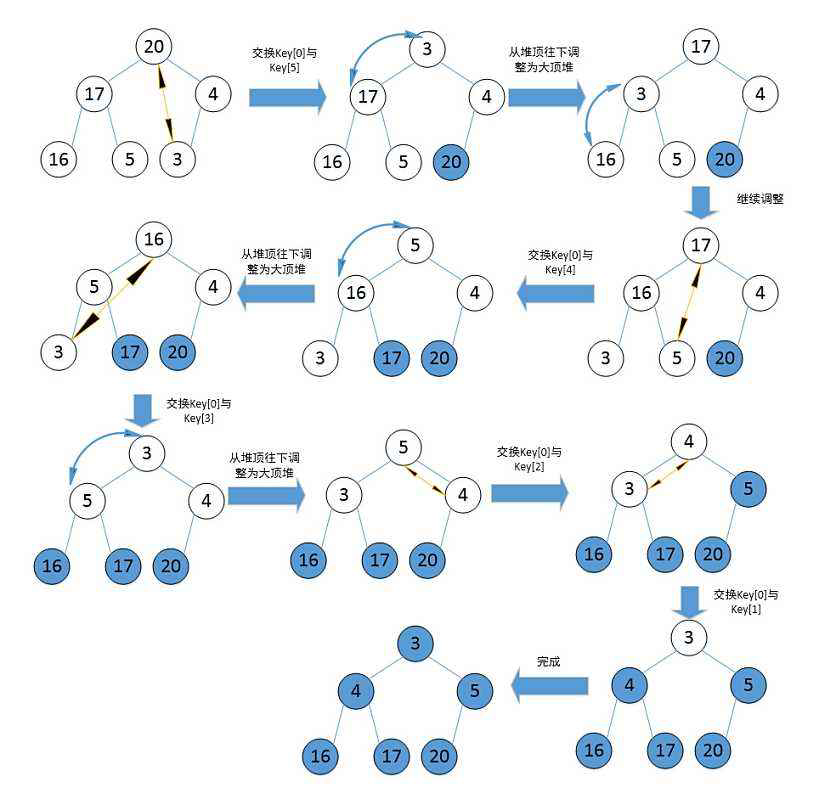
3)实现堆排序(升序-大堆)
依托上面堆实现的代码,但要修改向上调整算法和向下调整算法的判定条件为大堆。
#include "Heap.h"
void HeapSort(int* a, int n)
{
// 建大堆
//// 把a[0]当作一个大堆,其他数据插入
//// O(NlogN)
//for (int i = 1; i < n; i++)
//{
// // 修改判定条件为大堆,调整符号
// AdjustUp(a, i);
//}
// 只利用向下调整算法,效果更高,时间复杂度是 O(N)
// 从倒数第一个非叶子,即最后一个节点的父亲
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
// 升序使用向下调整算法,用堆删除的思路调整堆
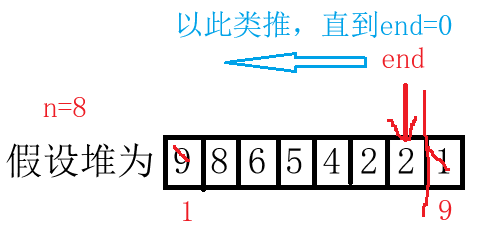
// O(NlogN)
int end = n - 1;
while (end > 0)
{
// 先排序大的数据,大的往后面先排好序
Swap(&a[0], &a[end]) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3198
3198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









