








合作单位:清华深圳,上海AI实验室,南洋理工大学
开源地址:mmpose/tree/main/projects/rtmo
《Pose估计》系列文章目录
第一章 Python 机器学习入门之pandas的使用

摘要
实时多人姿态估计在平衡速度和精度方面提出了重大挑战。 虽然两阶段自上而下的方法会随着图像中人数的增加而减慢,但现有的一阶段方法往往不能同时提供高精度和实时性能。
本文介绍了RTMO,一个单阶段姿态估计框架,通过在YOLO架构中使用双一维热图表示关键点,无缝集成了坐标分类,在保持高速的同时,实现了与自上而下的方法相当的精度。
我们提出了一个动态坐标分类器和一个定制的损失函数,专门设计来解决坐标分类和密集预测模型之间的不兼容性。RTMO的性能优于最先进的起始姿态估计器,在COCO上提高1.1%,而在相同的骨干下运行速度快9倍。我们最大的模型,RTMO-l,在COCO val2017上达到74.8%的AP,在单一的V100 GPU上达到141 FPS,证明了其效率和准确性。
一、Introduction
多人姿态估计(MPPE)在计算机视觉领域是必不可少的,其应用范围从增强现实到体育分析。实时处理对于需要即时反馈的应用程序尤其重要,比如对运动员定位的指导。虽然出现了许多实时姿态估计技术[3,16,17,31],但实现速度和精度之间的平衡仍然具有挑战性。
当前实时算法分为两类:自上而下的[3,16]和单级的[17,31]。自顶向下的方法使用预先训练过的检测器在受试者周围创建边界框,然后对每个个体进行姿态估计。一个关键的限制是,它们的推理时间随图像中的人数而变化(见图1)。另一方面,单阶段方法准确地预测了图像中所有个体的关键点的位置。然而,与自顶向下的方法相比,目前的实时单阶段方法[17,31,34]的精度滞后(见图1)。这些方法依赖于YOLO架构,直接回归关键点坐标,这阻碍了性能,因为该技术类似于对每个关键点使用Dirac delta分布,忽略了固有的模糊性和不确定性[21]。
(狄拉克增量分布)
另外,坐标分类方法采用双一维热图,通过将关键点位置的概率扩展到跨越整个图像的两组箱子上来提高空间分辨率。这提供了更准确的预测和最小的额外计算成本[16,23]。
然而,将坐标分类直接应用于密集的预测场景,如初始姿态估计,由于图像的全局箱子分布,每个人只占据一个小区域,导致箱子利用效率低下。 此外,传统的库贝克-莱布勒散度(KLD)损失平均对待所有样本,这对于实例难度变化显著的单阶段姿态估计是次优的。
在这项工作中,我们克服了上述挑战,并将坐标分类方法纳入了基于yolo的框架中,从而导致了实时多人一阶段(RTMO)姿态估计模型的发展。RTMO引入了一个动态坐标分类器(DCC),它包括本地化到边界箱的动态箱分配和可学习的箱表示。
RTMO introduces a Dynamic Coordinate Classifier (DCC) that includes dynamic bin allocation localized to bounding boxes and learnable bin representations. Furthermore, we propose a novel loss function based on Maximum Likelihood Estimation (MLE) to effectively train the coordinate heatmaps. This new loss allows learning of per-sample uncertainty, automatically adjusting task difficulty and balancing optimization between hard and easy samples for more effective and harmonized training.
此外,我们提出了一种新的基于最大似然估计(MLE)的损失函数来有效地训练坐标热图。这种新的损失允许学习每个样本的不确定性,自动调整任务难度,并在硬样本和容易样本之间进行平衡优化,以获得更有效和协调的训练。
因此,RTMO实现了与实时自顶向下方法相当的精度,并超过了其他轻量级的单阶段方法。此外,RTMO在处理一个图像中的多个实例时显示出了优越的速度,以相似的精度超过了自上而下的方法。
这项工作的关键贡献包括:
- 提出一种为密集预测量身定制的创新的坐标分类技术,利用坐标箱进行精确的关键点定位,同时解决不同的实例大小和复杂性。
- 提出一种新的实时单阶段的MPPE方法,它将协调分类与YOLO架构无缝集成,在现有的MPPE方法之间实现了性能和速度的最佳平衡。
二、相关工作
2.1单阶段的姿态估计器
受单阶段目标检测算法[8,10,25,41,52]发展的启发,一系列单阶段姿态估计方法出现了[11,31,35,40,52]。这些方法在单个转发传递中执行MPPE,并直接从预定的根位置回归特定于实例的关键点。其他方法如PETR [38]和ED-Pose [47]将姿态估计视为端到端关键点回归的集合预测问题。除了基于回归的解决方案外,FCPose [32]、InsPose [36]和CID [43]等技术还利用动态卷积或注意机制来生成用于关键点定位的实例特定热图。
与两阶段姿态估计方法相比,预测方法消除了预处理(如自上而下方法的人工检测)和后处理(如自下而上方法的关键点分组)的需要。这将带来两个好处: 1)一致的推理时间,而不管映像中的实例数量如何;2)简化部署和实际使用的简化管道。尽管有这些优点,现有的预测方法仍然难以平衡高精度和实时推理。高精度模型[43,47]通常依赖于资源密集型的骨干,如HRNet [39]或Swin [26],这使得实时估计具有挑战性。相反,实时模型[31,34]在性能上的妥协。我们的模型解决了这种权衡,提供了高精度和快速的实时推断。
2.2 2.2.坐标分类
SimCC [23]和RTMPose [16]采用坐标分类方法进行姿态估计,沿水平轴和垂直轴将关键点划分为亚像素箱,实现没有高分辨率特征、平衡精度和速度的空间识别。然而,对于密集的预测方法,在整个图像上跨越箱子是不切实际的,因为需要大量的箱子来减少量化误差,这导致了许多箱子的效率低下,而对于个别实例来说是多余的。DFL [21]在每个锚点附近的预定义范围内设置箱子,这可能不覆盖大实例的关键点,并可能对小实例导致显著的量化错误。
作者提出的方法在局部区域内分配箱子,并按比例调整到每个实例的大小,从而优化了箱子的利用率,确保关键点的覆盖率,并最小化量化误差。
2.3 变压器增强的姿态估计
基于变压器的架构已经在姿态估计中普遍存在,利用最先进的变压器骨干来提高精度,如ViTPose [46],或将变压器编码器与cnn结合来捕获空间
关系[48]。标记的[22]和Poseur [33]证明了基于标记的关键点嵌入在热图和基于回归的方法中的有效性,利用了视觉线索和解剖约束。PETR [38]和ED-Pose [47]等框架在端端多人姿态估计中引入了变压器,RTMPose [16]将自我关注与基于simcc的[23]框架用于关键点依赖分析,RTMO也采用了这种方法。
虽然位置编码是通知查询和关键位置的标准方法,但我们创新地使用它为每个空间箱子形成表示向量,使箱子-关键点相似度的计算,便于准确的定位预测。
方法
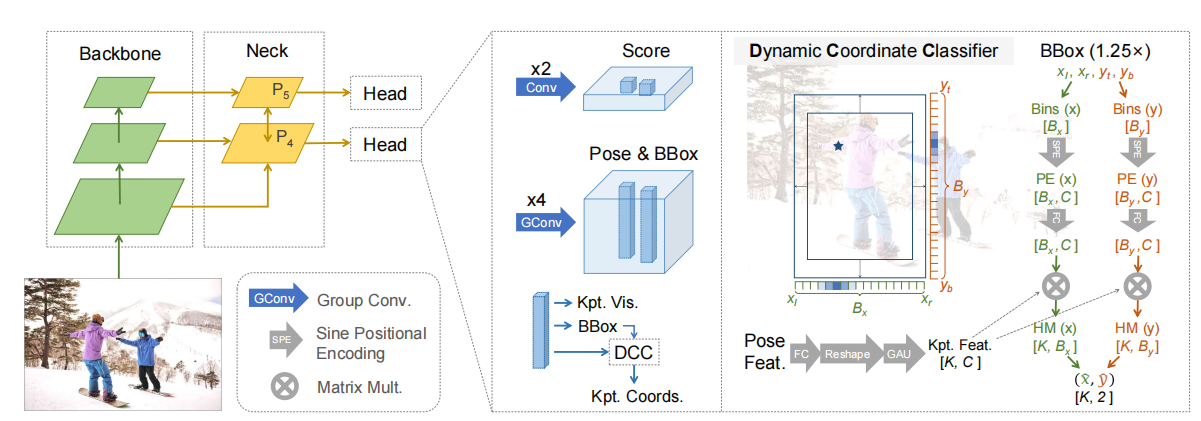 图2.RTMO网络架构的概述。它的头部输出对分数、边界框、关键点坐标和每个网格单元格的可见性的预测。动态坐标分类器将姿态特征转换为水平轴、水平轴和垂直轴的K对一维热图,包含一个是预测边界框大小的1.25倍的扩展区域。从这些热图中,可以精确地提取出关键点坐标。K为keypoint的总数。
图2.RTMO网络架构的概述。它的头部输出对分数、边界框、关键点坐标和每个网格单元格的可见性的预测。动态坐标分类器将姿态特征转换为水平轴、水平轴和垂直轴的K对一维热图,包含一个是预测边界框大小的1.25倍的扩展区域。从这些热图中,可以精确地提取出关键点坐标。K为keypoint的总数。
总结
我们对RTMO这种面向实时的多人姿态估计检测器进行了解读,它的亮点主要有:1、改进了回归算法,用于高精度的人体关键点回归;2、改进了误差损失函数,考虑了不同部位关键点的误差不一样的属性。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











