









一、什么是归因分析
归因分析重在一个结果的产生可能是行为1也可能是行为2,那么行为1和行为2 对于达成这个结果的贡献度是多少呢?需要分析。
而漏斗:事件1和事件2之间肯定是有关系的,而归因分析中事件1和事件2是没什么必然的联系的。
按如所示:

在做一些运营活动,广告投放后,都需要去评估活动或者广告的效应;
我们的销量、拉新等业务目标,在广告投放或者运营活动组织后,有了明显的提升,但是这些提升是否是因为广告、运营活动导致的,需要有数据支撑!
这些数据分析,就属于事件归因分析的范畴!
二、归因分析的分类
而归因分析,又是一件非常复杂的运算:一个业务目标事件的达成,究竟是由哪些原因(待归因事件)引起的;待归因事件通常是事先会定好候选项!
比如,一个业务目标X,能够由A、C、F事件引起;
当一个用户完成了目标X,那么我们要分析他的X究竟是由A、C、F中哪一个事件所引起(贡献度);
有如下计算策略(模型):
首次触点归因:待归因事件中,最早发生的事件,被认为是导致业务结果的唯一因素。
末次触点归因:待归因事件中,最近发生的事,被认为是导致业务结果的唯一因素。
线性归因:待归因事件中,每一个事件都被认为对业务结果产生了影响,影响力平均分摊。

位置归因:定义一个规则,比如最早、最晚事件占40%影响力,中间事件平摊影响力
时间衰减归因:越近发生的待归因事件,对业务结果的影响力越大,需要自己定义规则。
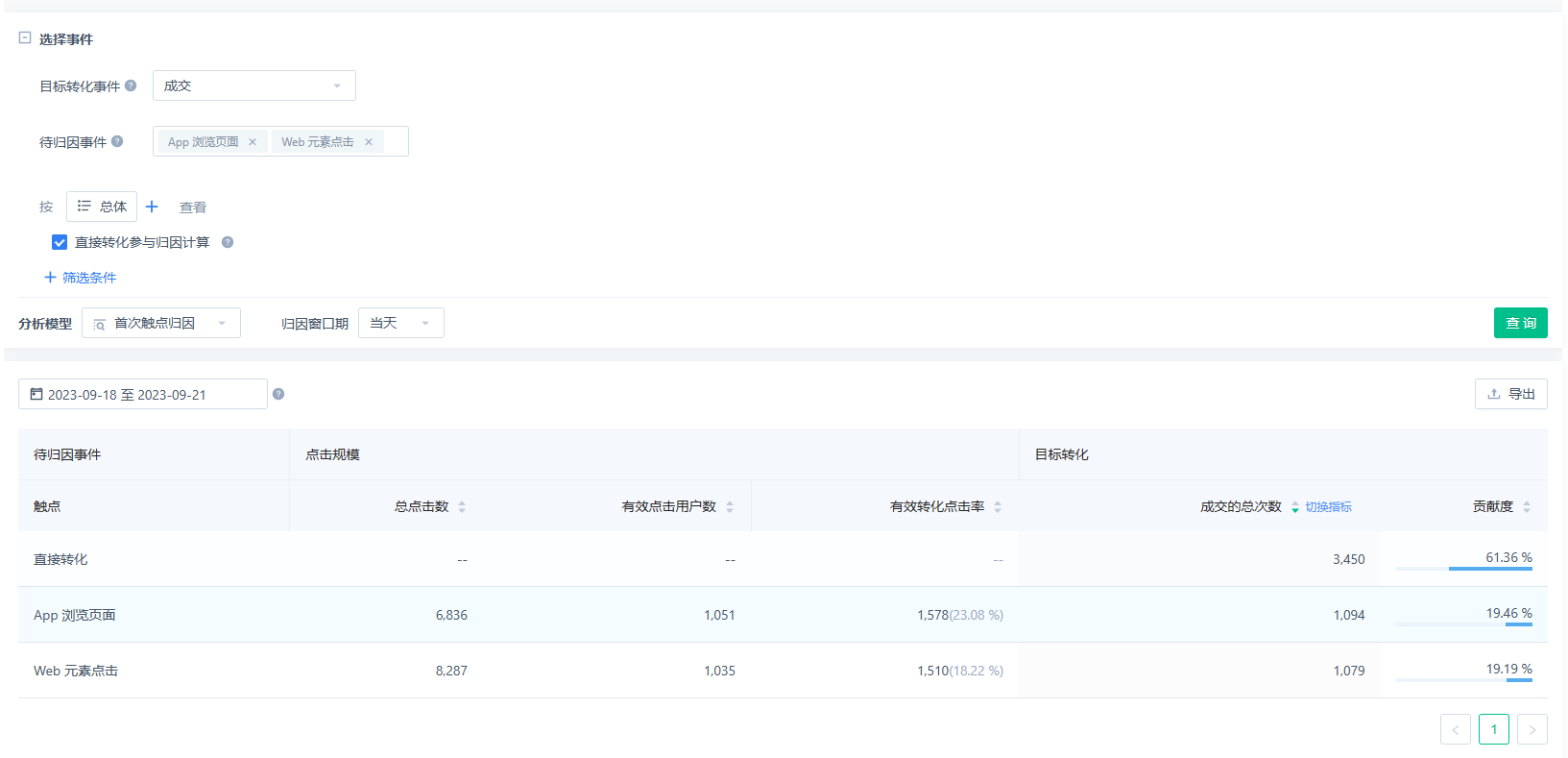
三、归因分析代码演示
1、导入测试数据
假如不使用模拟数据,应该使用 dwd 中的用户行为明细表
deviceid1,xx,k1:v1,1001
deviceid1,APP激活,k1:v1,1002
deviceid1,xx,k1:v1,1003
deviceid1,提交订单,k1:v1,1004
deviceid1,xx,k1:v1,1005
deviceid1,坑位曝光,k1:v1,1006
deviceid1,xx,k1:v1,1007
deviceid1,提交订单,k1:v1,1008
deviceid1,xx,k1:v1,1009
deviceid1,APP激活,k1:v1,1010
deviceid1,坑位曝光,k1:v1,1011
deviceid1,xx,k1:v1,1012
deviceid1,提交订单,k1:v1,1013
deviceid1,xx,k1:v1,1014
deviceid1,坑位曝光,k1:v1,1015
deviceid1,APP激活,k1:v1,1016
deviceid1,xx,k1:v1,1017
deviceid1,提交订单,k1:v1,1018
deviceid2,xx,k1:v1,1001
deviceid2,APP激活,k1:v1,1002
deviceid2,xx,k1:v1,1003
deviceid2,提交订单,k1:v1,1004
deviceid2,xx,k1:v1,1005
deviceid2,坑位曝光,k1:v1,1006
deviceid2,xx,k1:v1,1007
deviceid2,提交订单,k1:v1,1008
deviceid2,xx,k1:v1,1009
deviceid2,坑位曝光,k1:v1,1010
deviceid2,坑位曝光,k1:v1,1011
deviceid2,xx,k1:v1,1012
deviceid2,提交订单,k1:v1,1013
deviceid2,xx,k1:v1,1014
deviceid2,坑位曝光,k1:v1,1015
deviceid2,APP激活,k1:v1,1016
deviceid2,APP激活,k1:v1,1016
deviceid2,xx,k1:v1,1017
deviceid2,提交订单,k1:v1,1018
load data local inpath '/home/hivedata/guiyin.txt' into table tmp_event_log_detail partition(dt='2022-11-26')
alter table tmp_event_log_detail drop partition(dt='2022-11-26')首次/末次触点归因、线性归因
首次触点归因的定义:待归因事件中,最早发生的事件,被认为是导致业务结果的唯一因素
需求描述:对某个目标事件的待归因事件的【首次触点归因】进行统计 统计指标包含目标转化总次数,贡献度
指标口径【规则】
目标转化总次数 = 待归因事件出现次数 * 权重
贡献度 = 当前待归因事件转化总次数/所有待归因事件转化总次数
例如:
坑位曝光 --> 待归因事件
商品曝光 --> 待归因事件
提交订单 --> 目标事件
dws层建模
create table dws.attribution_analysis(
model_name string, -- 模型名称
attribution_strategy string, -- 归因策略
deviceid string, -- 用户
target_event string, -- 目标事件
wait_attribution string, -- 待归因事件
weight double -- 权重
)期望的结果如下图所示:
| 业务模型 | 策略名称 | 用户 | 目标事件 | 待归因事件 | 归因权重 |
| 跳楼购归因 | 线性归因 | g001 | 购买商品(p01) | 运营位(1) 点击 | 50 |
| 跳楼购归因 | 线性归因 | g001 | 购买商品(p01) | 广告(ad8) 曝光 | 50 |
| 跳楼购归因 | 线性归因 | g002 | 购买商品(p01) | 运营位(1) 点击 | 50 |
| 跳楼购归因 | 线性归因 | g002 | 购买商品(p01) | 搜索(kw2)点击 | 50 |
| 小米新品促销归因 | 末次触点归因 | g004 | 购买小米至尊11 | 轮播广告2点击 | 100 |
| 小米新品促销归因 | 末次触点归因 | g005 | 购买小米至尊11 | 搜索“小米新品” | 100 |
开发逻辑
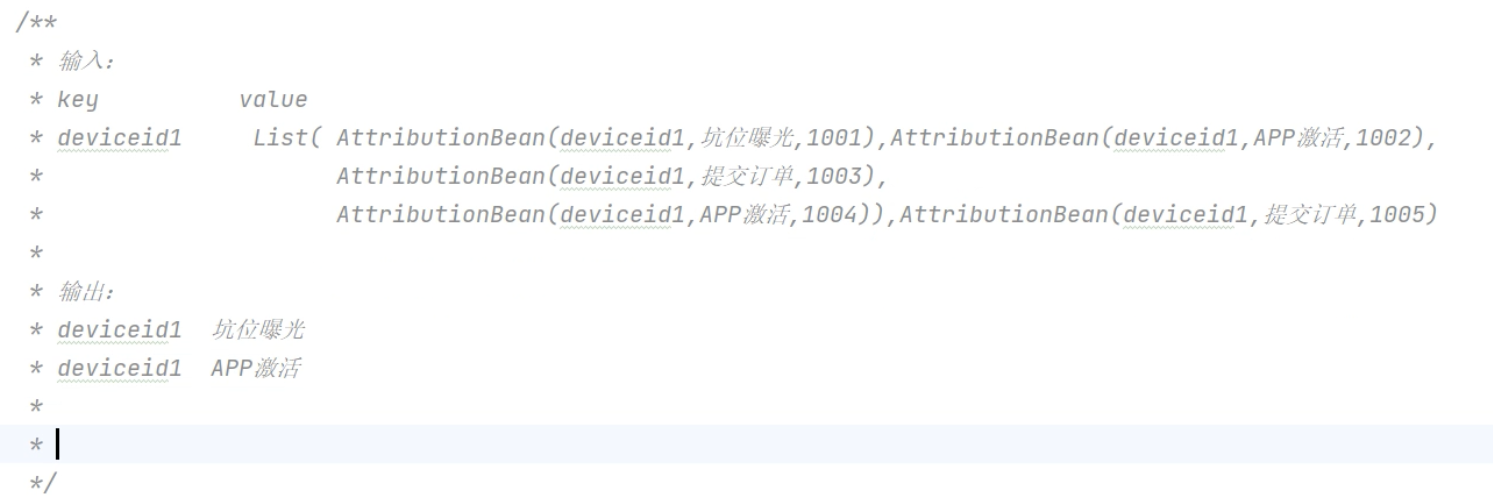
class AttributionBean:
def __init__(self, deviceid, eventid, ts):
self.deviceid = deviceid
self.eventid = eventid
self.ts = ts
def __repr__(self):
return f"{self.deviceid},{self.eventid},{self.ts}"from typing import List
from SparkUtils import *
from AttributionBean import *
# 最难的是这个函数的编写
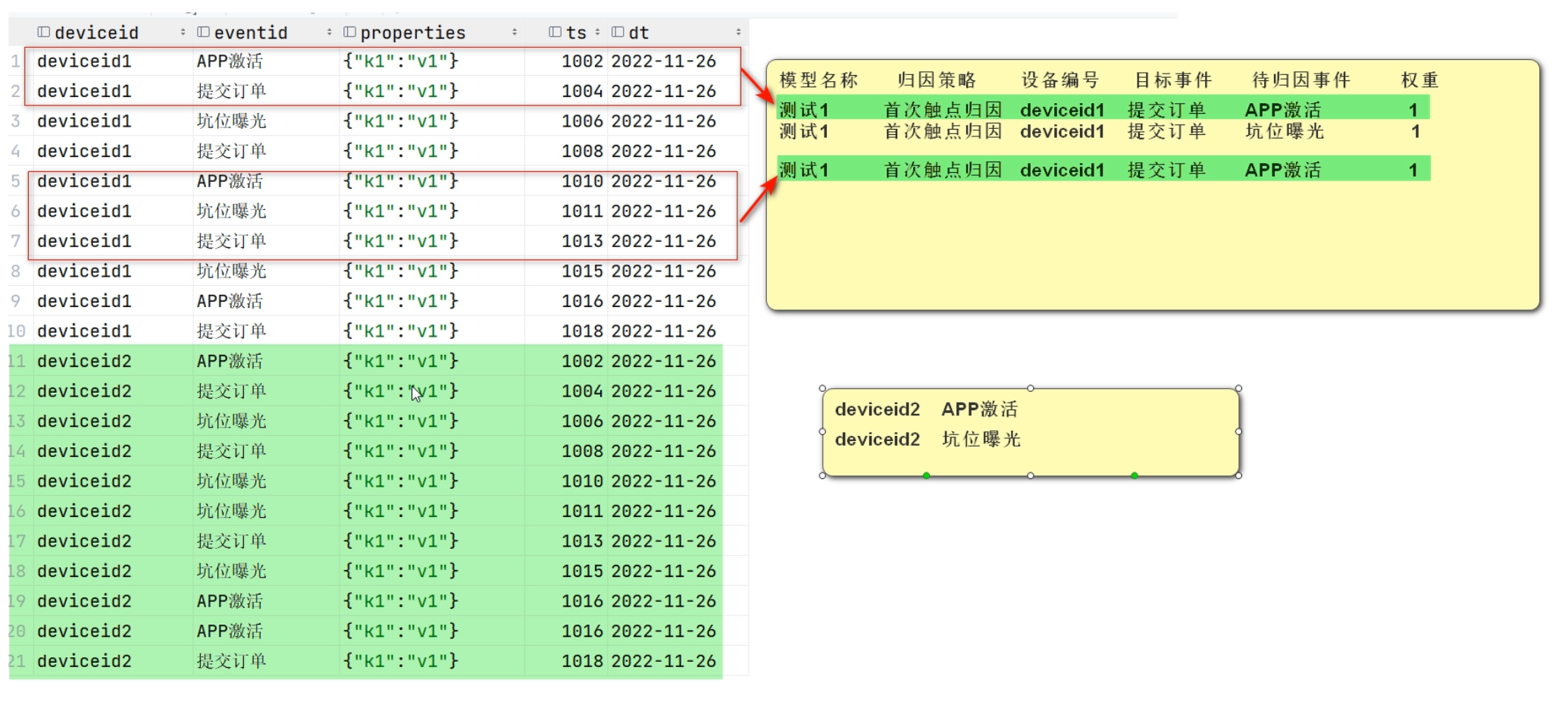
# (deviceid1, [AttributionBean1 AttributionBean2 AttributionBean3])
def flatMapDef(tuple2):
deviceid = tuple2[0]
# list(迭代器) 将一个迭代器转变为list
list01 = list(tuple2[1]) # AttributionBean
#print(list01)
# 排序
list01.sort(key=lambda x: x.ts)
# list02 中存放的是一次小的事件组合
list02:List[AttributionBean] = []
# list03 存放的是所有的满足条件的数据
list03: List[List[AttributionBean]] = []
for ele in list01:
if ele.eventid != '提交订单':
list02.append(ele)
else:
list03.append(list02)
list02:List[AttributionBean] = []
return list03
def flatMapDef2(list01):
list02: List= []
num = 0
for attribution in list01:
list02.append(('618大促','线性归因分析',attribution.deviceid,'提交订单',attribution.eventid,1/len(list01)))
return list02
if __name__ == '__main__':
spark: SparkSession = SparkUtils.getSparkSession("根据明细数据得到归因明细", "local")
# 更换思路,使用spark代码,将数据保存到hive
logDetailDf = spark.sql("""
select * from tmp.tmp_event_log_detail where dt='2024-06-03' and eventid in ('APP激活','坑位曝光','提交订单')
""")
logDetailDf.show()
mapRdd = logDetailDf.rdd.map(lambda row:(row.deviceid,AttributionBean(row.deviceid,row.eventid,row.ts)))
# ('deviceid1', deviceid1,APP激活,1002)
mapRdd.foreach(print)
# deviceid1 AttributionBean1 AttributionBean2 AttributionBean3
flatMapRdd = mapRdd.groupByKey().flatMap(lambda tuple:flatMapDef(tuple))
# [deviceid1,APP激活,1010, deviceid1,坑位曝光,1011]
flatMapRdd.foreach(print)
# 我要的是一个集合中的第一条元素
# 首次归因计算方式
#resultRdd = flatMapRdd.map(lambda list:('618大促','首次归因分析',list[0].deviceid,'提交订单',list[0].eventid,1))
# 末次归因计算方法
resultRdd = flatMapRdd.map(lambda list:('618大促','末次归因分析',list[len(list)-1].deviceid,'提交订单',list[len(list)-1].eventid,1))
# 线性归因怎么做? 一个目标事件的达成,是因为多个事件组成的,每个事件都各占1部分,平均分配
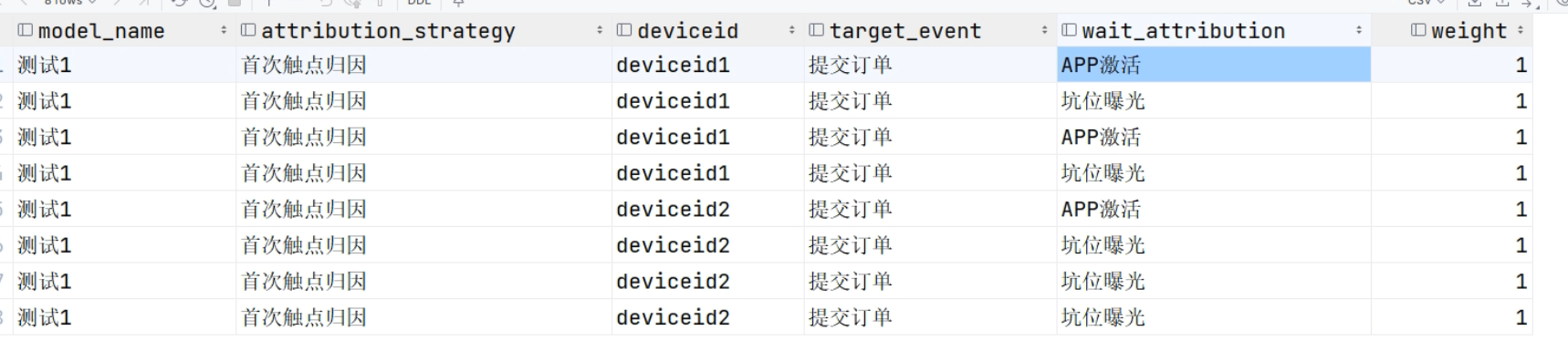
resultRdd.toDF().write.insertInto("dws.attribution_analysis")
flatMapRdd2 = flatMapRdd.flatMap(flatMapDef2)
flatMapRdd2.foreach(print)
#flatMapRdd2.toDF().write.insertInto("dws.attribution_analysis")当我们rdd.groupByKey() 之后想要达到的效果:
在python的函数中,假如一个函数需要返回值,return关键字必须写,否则,返回值是None。
然后我们attribution_analysis 表就有了数据,根据这个表中的数据进行统计,将统计的结果放入到attribution_analysis_result中。
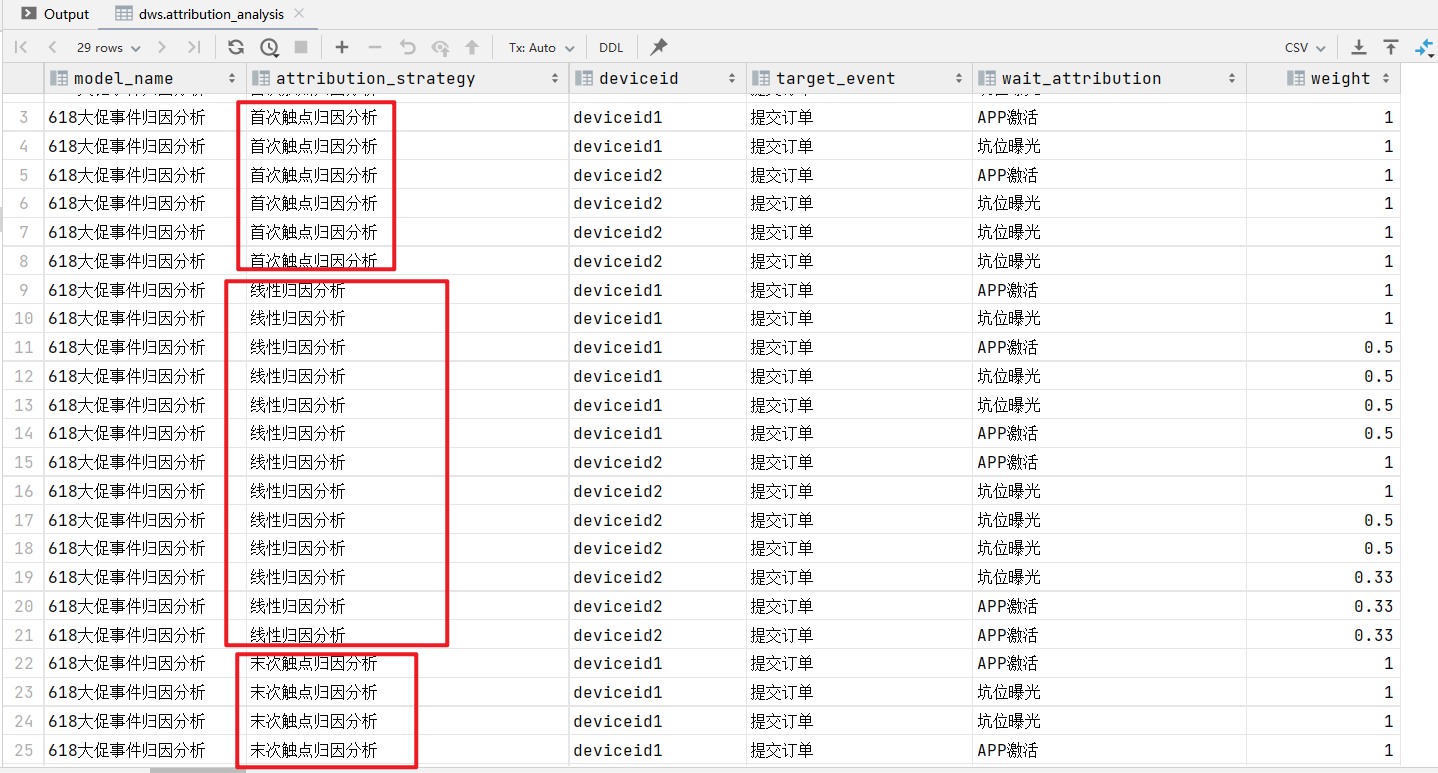
ads层建模
create table ads.attribution_analysis_result(
model_name string, -- 模型名称
attribution_strategy string, -- 归因策略
target_event string, -- 目标事件
wait_attribution string, -- 待归因事件
contribution double -- 贡献度·
)
with t as (
select
model_name,
attribution_strategy,
target_event,
wait_attribution,
sum(weight) sumWeight
from dws.attribution_analysis group by model_name,attribution_strategy,target_event,wait_attribution
)
insert into table ads.attribution_analysis_result
select
model_name,
attribution_strategy,
target_event,
wait_attribution,
round(sumWeight/ sum(sumWeight) over(partition by model_name,
attribution_strategy,
target_event ),2) zhanBi
from t ;


















 2502
2502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











