




背景
在分布式系统生成唯一ID,面临的问题:
- 全局唯一性:需要确保不同节点生成的 ID 不会重复,保证全局唯一
- 高可用性和高性能:ID 生成服务不能成为系统的瓶颈,需支持高并发请求,高可用和高性能保证
- 趋势递增性:为了优化数据库索引和查询性能(结合DB场景下),ID 最好是趋势递增的。
- 存储效率:ID 的长度应尽可能短,以减少存储空间和传输成本。
一些其他方案:
• 数据库自增 ID:很自然的实现,但容易会成为性能瓶颈和单点故障,不适用于过高并发的分布式系统。
• UUID:虽然能保证全局唯一性,但长度较长(128 位),且为随机分布,不利于数据库索引优化。
Snowflake 是 Twitter 开源的一种生成全局唯一 ID 的算法,旨在解决分布式系统中唯一标识符生成的问题。能够在高并发情况下,快速生成不重复、有序的 64 位整数 ID。Snowflake算法,利用了时间戳、机器标识、序列号等方式,巧妙的完成的ID生成。
Snowflake设计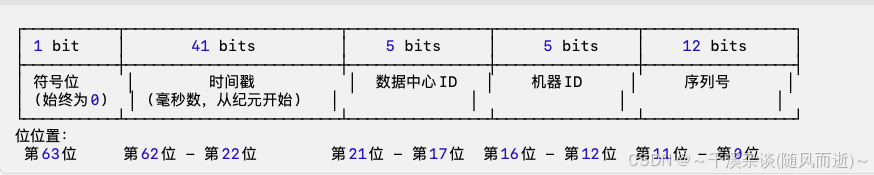
如上图,位置从左到右依次为高位到低位,即从第63位(最高位)到第0位(最低位);总共64位,组成一个唯一的 Snowflake ID。
各参数定义如下:
- 符号位(1位,第63位):
• 占用最高位(第63位),始终为0,不使用。为了确保生成的 ID 是非负整数,Snowflake 将最高位的符号位设为 0,也可用于拓展 - 时间戳部分(41位,第62位 - 第22位):
• 表示从自定义纪元(如 2020-01-01 00:00:00)开始经过的毫秒数。
• 占用位:第62位到第22位,共41位。 - 数据中心ID(5位,第21位 - 第17位):
• 标识数据中心或机房。
• 可表示 0 到 31 之间的整数(共32个数据中心)。
• 占用位:第21位到第17位,共5位。 - 机器ID(5位,第16位 - 第12位):
• 标识同一数据中心内的机器或节点。
• 可表示 0 到 31 之间的整数(共32台机器)。
• 占用位:第16位到第12位,共5位。 - 序列号(12位,第11位 - 第0位):
• 在同一毫秒内生成的序列号,防止 ID 冲突。
• 可表示 0 到 4095 之间的整数(每毫秒可生成 4096 个不同的 ID)。
• 占用位:第11位到第0位,共12位。
应用实例
自定义纪元:2020-01-01 00:00:00
获取当前时间:2024-10-11 12:00:00
数据中心 ID:3
机器 ID:12
序列号:0
计算过程如下:
- 计算时间戳差值:时间戳差值 = 当前时间毫秒数 - 自定义纪元毫秒数
- ID = (时间戳差值 << 22) | (数据中心 ID << 17) | (机器 ID << 12) | 序列号 (按照上述位置分布移动位),如果序号超过4096,那么ID生成器等待1ms继续生成
总结
优点
- 全局唯一性
• 唯一 ID:结合时间戳、数据中心 ID、机器 ID 和序列号,确保在分布式系统中生成的 ID 全局唯一。 - 高并发和高性能
• 本地生成:ID 在本地生成,无需网络通信,延迟极低。
• 高并发:每毫秒可生成 4096 个 ID,支持高并发需求。 - 趋势递增性
• 按时间排序:ID 包含时间戳,整体上是趋势递增的,有利于数据库索引和日志排序。 - 可扩展性
• 分布式部署:支持多数据中心和多机器部署,方便系统水平扩展。 - 简单易用,开源常见实现
缺点
- 依赖系统时间
• 时钟回拨问题:如果服务器时间出现回拨,可能导致 ID 冲突或重复。以及需要服务器有可靠的时间同步机制,依赖于 NTP 服务等。
• 解决方案:需要在代码中检测时钟回拨,采取等待或抛出异常等措施。 - 时间戳溢出
• 使用期限有限:41 位时间戳约可使用 69 年(从自定义纪元开始),需要合理设置纪元时间。大部分系统够用 - 单点故障风险
• 机器故障:如果某台机器的机器 ID 或数据中心 ID 配置错误,可能导致 ID 冲突。
• 解决方案:需要对机器 ID 和数据中心 ID 进行统一管理,防止重复。同时部分场景,可能存在不多的数据中心或者机器,可以适当调整上述位置分布 - 序列号耗尽
• 高并发限制:在极高并发的情况下(单机每毫秒超过 4096 个请求),序列号可能耗尽,导致生成 ID 失败。
• 解决方案:可以适当调整位数分配,增加序列号位数,或者在应用层进行限流。或者等待 - 跨语言的实现风险
• 不同编码:由于各语言对整数的处理方式可能不同,跨语言传递时需要注意大整数的序列化和反序列化。

















 1978
1978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









