






 本文深入探讨了谷歌ObjectDetectionAPI的五个核心模型,重点介绍了ssd_mobilenet_v1_coco模型及其在移动设备上的应用。文章涵盖了模型训练、迁移学习、及在不同数据集上的应用案例,并分享了在人脸检测领域的实际部署经验。
本文深入探讨了谷歌ObjectDetectionAPI的五个核心模型,重点介绍了ssd_mobilenet_v1_coco模型及其在移动设备上的应用。文章涵盖了模型训练、迁移学习、及在不同数据集上的应用案例,并分享了在人脸检测领域的实际部署经验。
谷歌的objet detectoin api 主要公布了5个在COCO上训练的网络。网络结构分别是SSD+MobileNet、SSD+Inception、R-FCN+ResNet101、Faster RCNN+ResNet101、Faster RCNN+Inception_ResNet。
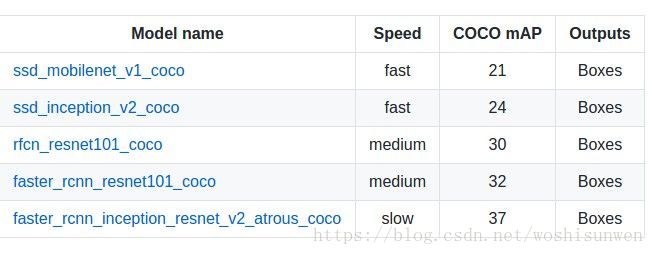
其安装过程见官网。特别之处,本项目是选择谷歌研究人员提出的ssd_mobilenet_v1_coco模型训练,该模型高效快速,可用于移动和嵌入式设备的视觉应用。 MobileNet 基于一个流线型的架构,该架构使用 depthwise separable convolution 来构建轻量级的深度神经网络。我们引入了两个简单的全局超参数,有效权衡延迟和准确度。这些超参数能让模型搭建者根据问题的限制为其应用选择适当规模的模型。我们在资源和准确率的不同权衡条件下进行了广泛的实验,与 ImageNet 分类任务的其他流行模型相比,我们的模型显示出很好的性能。 然后,我们证明了 MobileNet 在一系列应用和使用情况中的有效性,包括对象检测,细粒度识别,人脸属性提取,以及大规模地理定位。
某知乎用户这么评价该框架:
“模型本身并没有太多新意,因为大家基本上都有了,但是我觉得最重要的是提供了工程实践的样例,这个对于训练新的模型,包括训练工程师们用正确的方法设计模型,都是有帮助的。
比如说TF-Slim:虽然Keras那么响亮,但是做computer vision的话就是Slim的抽象最合适也最容易重构。Sergio从Caffe的年代就开始在科研一线考虑模型设计和抽象的问题,经过那么多框架的迭代,在CV上比拍脑袋的Keras还是好太多。
我在TF的一位朋友这么说:框架特别是像TF这样的框架就像C++,学习曲线陡,牛人可以用得炉火纯青,不熟的人可以造成很强的反效果 - 这也是我对TF有保留意见的一个地方,设计是按照Google资深工程师的技术功底来搞的,然后平时就像是让小朋友开车那样恐怖。现在这些模型和代码,就是教小朋友开车啦。设计训练自己的模型更加高效。”
在Google的api基础上训练自己的模型的时候,可以使用不同的模型进行训练,确定了模型既可以用自己的数据集从头开始训练,也在使用pre-trained模型在新数据集上进行学习,叫迁移学习。在detection_model_zoo中包括了很多预训练模型可以使用。
在github上找了个工程,某大神自己在object_detection api上训练了从 WIDERFACE dataset.上下载的人脸数据,并提供了.pb文件,能够进行视频人脸检测,使用者只需按步骤配置安装tf环境+protobuf+object_detection api环境运行即可。不过看不出使用者的工作量,还需自己搞个库训练一下。由于主要想做一个人脸的视频流检测,没有在别的公开数据集做训练。
下一步准备在其他的公开数据集训练一次,教程网址:
https://blog.youkuaiyun.com/zlase/article/details/78734138
https://blog.youkuaiyun.com/wc781708249/article/details/78110205
https://www.cnblogs.com/yutonghu/p/8393993.html
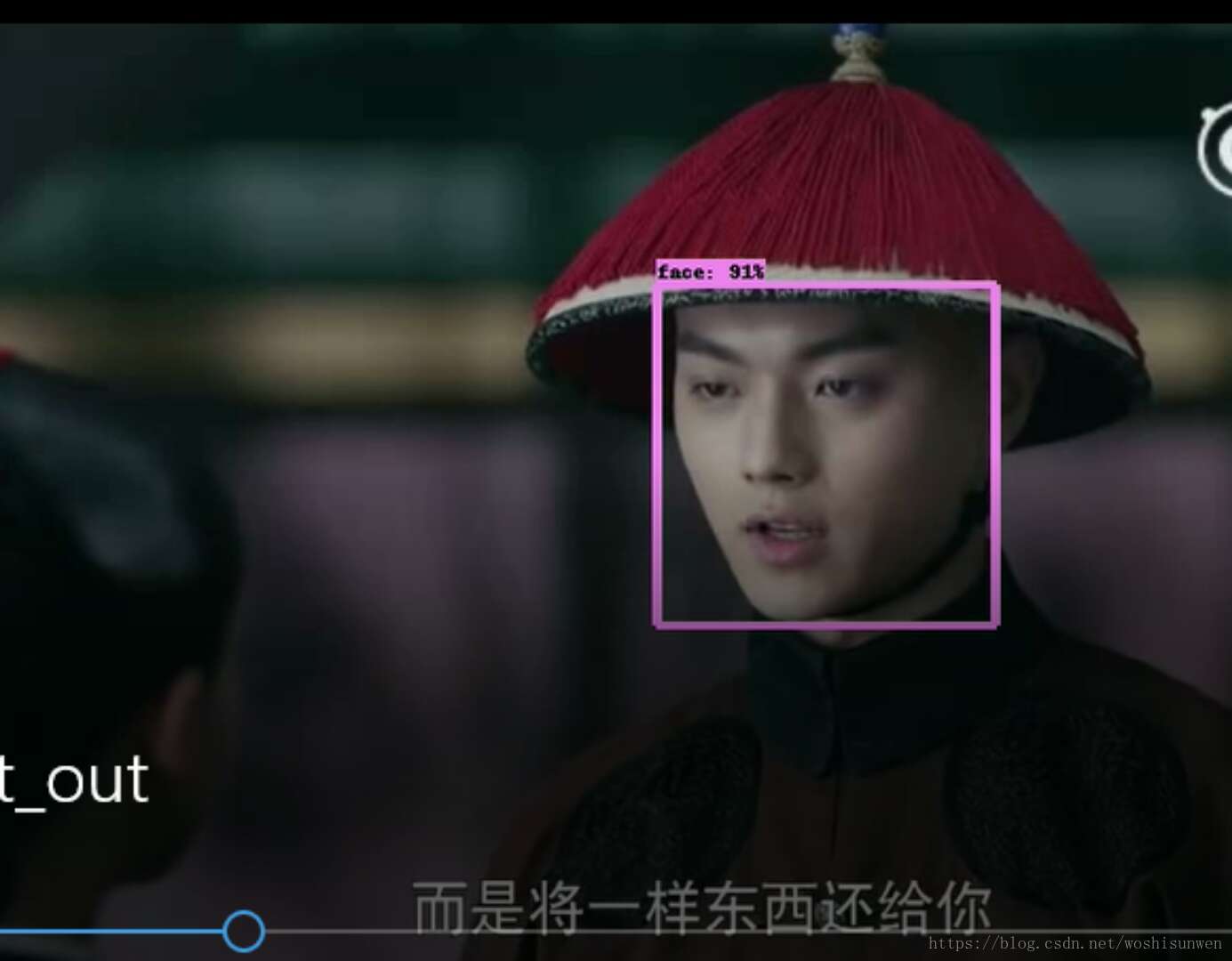
检测效果:

总结:
一种算法,一个开源项目,一个学习总结。环境配置,linux入门,github网站使用,遇到问题寻找解决方案,发现兴趣点。
能找到一个自己的兴趣点是一件不容易的事。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









