







 本文介绍了XML的基本概念,包括其特点、基本语法、文本处理及约束方式,并详细讲解了DOM和SAX两种主要的XML解析方法。
本文介绍了XML的基本概念,包括其特点、基本语法、文本处理及约束方式,并详细讲解了DOM和SAX两种主要的XML解析方法。
一、xml概念
1、Extensible Markup Language 可扩展标记语言
可扩展:标签都是自定义的。 <user> <student>
2、xml与html的区别
1. xml标签都是自定义的,html标签是预定义。
2. xml的语法严格,html语法松散
3. xml是存储数据的,html是展示数据
3、基本语法
1. xml文档的后缀名 .xml
2. xml第一行必须定义为文档声明
3. xml文档中有且仅有一个根标签
4. 属性值必须使用引号(单双都可)引起来
5. 标签必须正确关闭
6. xml标签名称区分大小写
4、文本
CDATA区:在该区域中的数据会被原样展示
* 格式: <![CDATA[ 数据 ]]>
5、约束
能够在xml中引入约束文档
能够简单的读懂约束文档
分类:
1. DTD:一种简单的约束技术(用的很少了)
本地:<!DOCTYPE 根标签名 SYSTEM "dtd文件的位置">
网络:<!DOCTYPE 根标签名 PUBLIC "dtd文件名字" "dtd文件的位置URL">
2. Schema:一种复杂的约束技术(开发中最常用的)
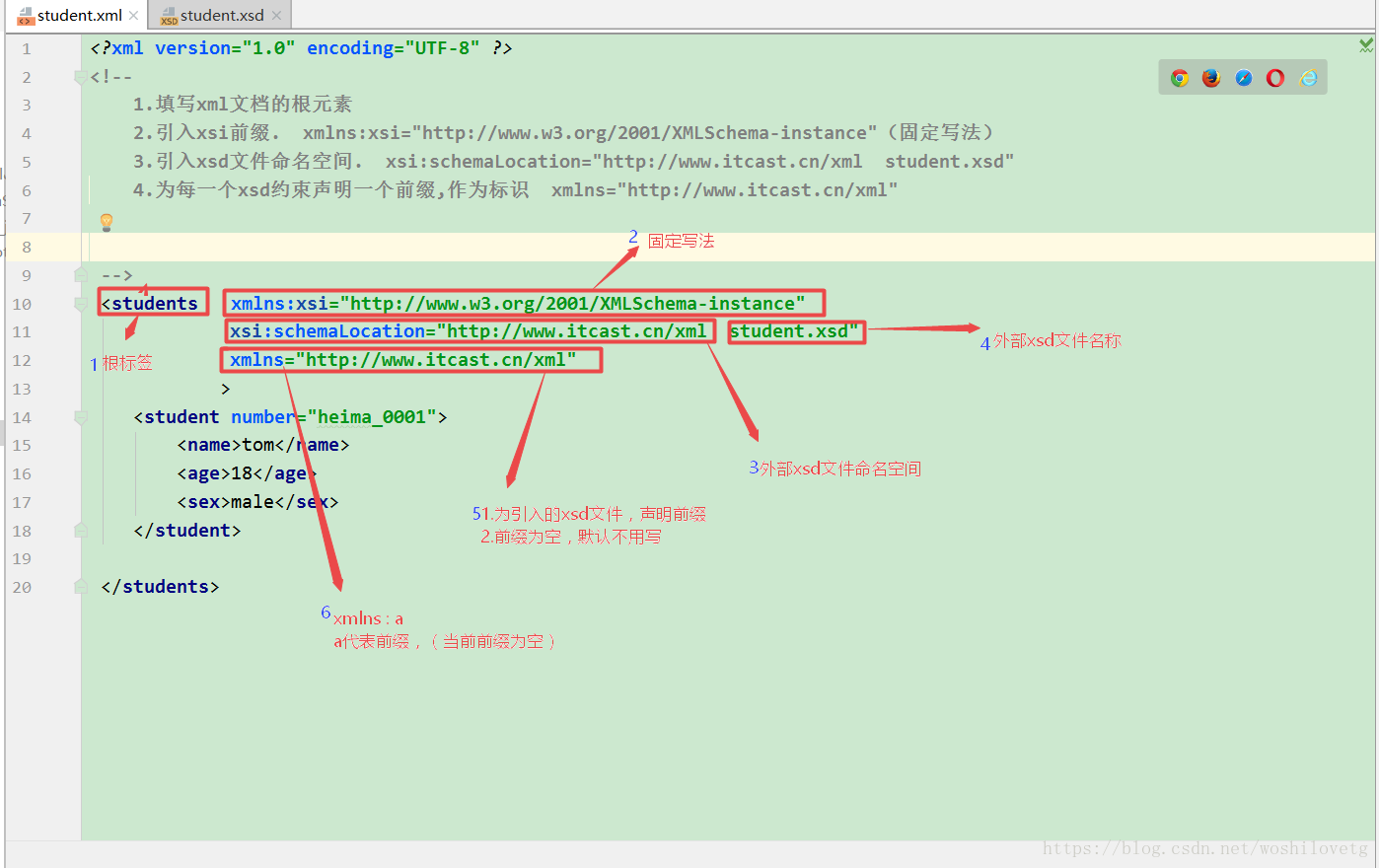
1.如下图在xml中引入约束文档
<?xml version="1.0" encoding="UTF-8" ?>
<!--
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"(固定写法)
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.itcast.cn/xml"
-->
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/xml student.xsd"
xmlns="http://www.itcast.cn/xml">
<student number="heima_0001">
<name>tom</name>
<age>18</age>
<sex>male</sex>
</student>
</students>
2..读懂约束文档
二、xml解析
1.解析xml
将xml文档中的数据,读取到内存中
2.解析xml的方式
1.DOM解析
将xml文档一次性加载进内存,在内存中形成DOM树
2.SAX解析
逐行解析,解析一行,释放一行
3.常见解析器
DOM4J、Jsoup
4.Jsoup解析
步骤:
1.导入Jsoup包
2.获取Document对象
3.获取元素对象
4.获取值
基础练习:xml解析_Jsoup_根据选择器进行获取练习
package cn.itcast.wtg;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
public class JsonpTest01 {
public static void main(String[] args) throws IOException {
//获取xml文件路径
String path = JsonpTest01.class.getClassLoader().getResource("student.xml").getPath();
//加载xml文件,得到ducument对象
Document document = Jsoup.parse(new File(path), "utf-8");
/*
需求开始。。。。。。。。。。。。。。。
*/
//1.获取id为itcast的元素
Elements ele_itcast = document.select("#itcast");
System.out.println(ele_itcast);
System.out.println("===================================");
//2.获取name标签元素
Elements ele_name = document.select("name");
System.out.println(ele_name);
System.out.println("===================================");
//3.获取student标签并且number属性值为heima_0001的age子标签
Elements ele_age = document.select("student[number='heima_0001'] > age");
System.out.println(ele_age);
System.out.println("===================================");
//4.查询所有student标签
Elements student = document.select("student");
System.out.println(student);
System.out.println("===================================");
//5.查询所有student标签下的name标签
Elements name = document.select("student>name");
System.out.println(name);
System.out.println("===================================");
//6.查询student标签下带有id属性的name标签
Elements ele_idname = document.select("student>name[id]");
System.out.println(ele_idname);
System.out.println("===================================");
//7.查询student标签下带有id属性的name标签 并且id属性值为itcast
Elements select = document.select("student>name[id='itcast']");
System.out.println(select);
//8.获取xing标签中的内容
System.out.println("===================================");
Elements select1 = document.select("name[id='itcast']>xing");
System.out.println(select1.get(0).text());
//9.获取属性名为id的元素对象们
System.out.println("===================================");
Elements select2 = document.select("[id]");
System.out.println(select2);
}
}

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









