







一、分区表
在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了。
一个分区相当于hdfs中的一级文件件
多个分区类似于hdfs中的多级文件夹,如下图:

数据源
01 01 80 01 02 90 01 03 99 02 01 70 02 02 60 02 03 80 03 01 80 03 02 80 03 03 80 04 01 50 04 02 30 04 03 20 05 01 76 05 02 87 06 01 31 06 03 34 07 02 89 07 03 98
1.1 创建分区表语法(一个分区)
create table score(s_id string,c_id string, s_score int) partitioned by (month string) row format delimited fields terminated by '\t';
1.2 加载数据到一个分区的分区表
load data local inpath '/export/server/hivedatas/score.csv' into table score partition (month='202006');
1.3 创建一个表带多个分区
create table score2 (s_id string,c_id string, s_score int) partitioned by (year string,month string,day string) row format delimited fields terminated by '\t';
1.4 加载数据到多个分区的分区表
load data local inpath '/export/server/hivedatas/score.csv' into table score2 partition(year='2020',month='06',day='01');
1.5 查看分区的命令
show partitions score;
1.6 添加一个分区命令
alter table score add partition(month='202007');
1.7 添加多个分区命令
alter table score add partition(month='202008') partition(month = '202009');
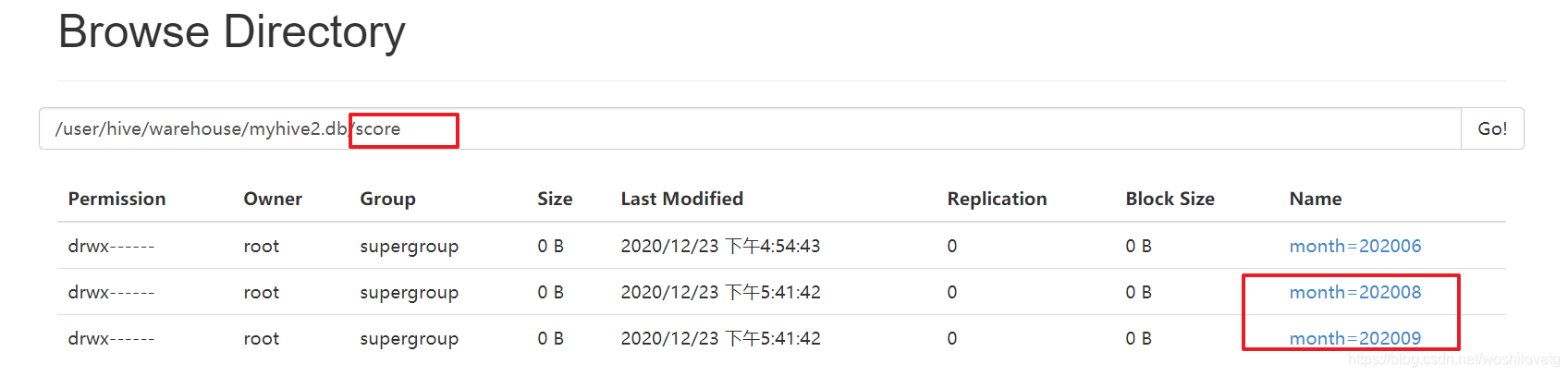
alter table score2 add partition(year='2020',month = '06',day='02');
一次创建多级

1.8 删除分区
alter table score drop partition(month = '202009');
二、分桶表
将数据按照指定的字段进行分成多个桶中去,说白了就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去
开启hive的桶表功能(此版本自动开启分桶,不需要执行)
set hive.enforce.bucketing=true;
# 开启分桶个数
set mapreduce.job.reduces=3;
# 创建分桶表
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
# 桶表的数据加载,由于桶表的数据加载通过hdfs dfs -put文件或者通过load data均不好使,只能通过insert overwrite 创建普通表,并通过insert overwrite的方式将普通表的数据通过查询的方式加载到桶表当中去
# 创建普通表
create table course_common (c_id string,c_name string,t_id string) row format delimited fields terminated by '\t';
# 导入数据到普通表
load data local inpath '/export/server/hivedatas/course.csv' into table course_common;
# 将普通表的数据insert overwrite 到course 分桶表 ,会启动一个 MR 程序
insert overwrite table course select * from course_common cluster by(c_id);
三、修改表
修改表名
# 创建一个表 create table course2 like course; # 修改表名 alter table course2 rename to course1;
添加表的字段
# 为score5 添加两个字段 分别是 mycol mysco alter table score5 add columns (mycol string, mysco string);
修改表字段
# 修改表的字段和类型 alter table score5 change column mysco mysconew string;
清空表数据
# 只能清空管理表(内部表)的数据,不能情况外部表的数据 truncate table score6


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









