







一、hive介绍和架构
1.1 什么是hive
-
hive 是基于 Hadoop的数据仓库的工具,依赖于hadoop
-
hive 本质上来说就是SQL翻译成MR的工具
-
hive 的数据保存在 HDFS 上
-
hive 可以使用类 SQL 查询功能
1.2 为什么要使用hive
-
直接使用 hadoop mr 成本高,操作复杂,优化难度高,hive 提供了 类SQL功能,用户只要写SQL就能查询出来相关的数据,成本就低;
-
会SQL的人,比大数据的开发的人要多
-
进行数据分析的阶段,最好的工具是SQL
1.3 hive的架构
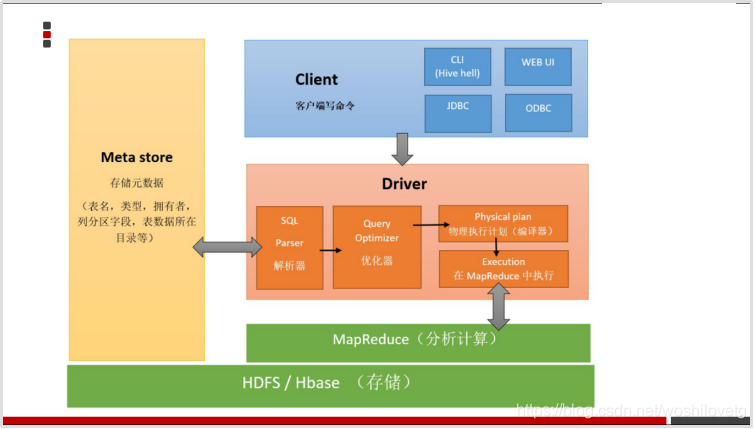
-
客户端:提供写SQL,提交SQL
-
Driver: hive 的 服务器
-
解析器:将SQL转换成AST 抽象语法数据,解析SQL,同时在元数据中判断当前表的数据信息,比如说是否存在某个表,如果不存在就报错
-
编译器:将AST 转换成 逻辑执行计划,生成执行树
-
优化器:将逻辑执行计划进行优化
-
执行器:将执行计划树生成MR,然后提交给yarn平台执行
-
-
存储和执行:Hive使用HDFS进行存储,使用MapReduce进行计算
1.4 hive 的元数据和元数据服务
-
元数据内容包括: 数据库的名称,默认数据default,有哪些表,表中有哪些字段,字段类型是什么,数据的分隔符号都有哪些,数据的存储路径
-
元数据存储到哪里: 默认是存储在derby数据库,企业开发一般不用,会使用 mysql数据库进行元数据的存储。
-
元数据服务(metastore)在整个hive服务中,提供元数据的服务:metastore服务,主要负责hive中元数据的管理工作,所以在启动hive的时候,要启动metastore服务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









