







 本文介绍了如何结合 TensorFlow、Keras-OCR 和 OpenCV 从钢结构技术图纸中提取尺寸信息。通过对象检测、文本识别和图像处理技术,实现了对不同形状和注释的识别,从而计算相关属性。
本文介绍了如何结合 TensorFlow、Keras-OCR 和 OpenCV 从钢结构技术图纸中提取尺寸信息。通过对象检测、文本识别和图像处理技术,实现了对不同形状和注释的识别,从而计算相关属性。

简单介绍
输入是技术绘图图像。对象检测模型获取图像后对其进行分类,找到边界框,分配维度,计算属性。
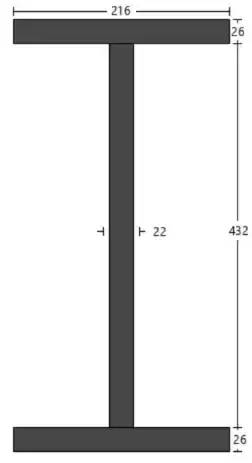
示例图像(输入)
分类后,找到“IPN”部分。之后,它计算属性,例如惯性矩。它适用于不同类型的部分(IPN、UPN、相等或不相等的支路、组合)。

结果(输出)
你可以从这里查看相关的 github 存储库:https://github.com/ramazanaydinli/Steel-AI/tree/main/final
摘要
这项工作的目的是从与钢结构相关的技术图纸中获取尺寸信息。然而,本文的目的是解释工作的细节,任何感兴趣的人都可以理解背后的想法,并使用类似的技术来解决他们的问题。它仅涵盖一些案例,以证明可以将计算机视觉方法应用于该领域。如果你需要,可以在之后进行一些改进。
要求

深度学习
你必须至少了解一种深度学习框架。就个人而言,使用 TensorFlow,但其他人(例如 PyTorch)也可以完成这项工作。如果你想学习 TensorFlow ,建议:
TensorFlow 简介:https://www.coursera.org/learn/introduction-tensorflow
Tensorflow 高级技术:https://www.coursera.org/specializations/tensorflow-advanced-techniques
光学字符识别
有许多可用的光学字符识别工具,请确保根据你的目标选择最合适的工具。在备选方案中,Keras-OCR 和 Tesseract-OCR 是最受欢迎的。但由于 Tesseract 不支持自定义训练,我们将使用Keras(此功能的优势将在本文的后期详细介绍)。
OpenCV
我相信官方文档绰绰有余,但你需要了解更多信息。
介绍
如果你是一名土木工程师,对你来说,下图应该比较容易看懂。但是考虑到不是每个人都有这方面的知识,在这里提供简单的描述,以便非土木工程师可以看到他们的领域与这个领域之间的相似之处,使用相同的技术,通过稍微调整代码来解决他们的问题。
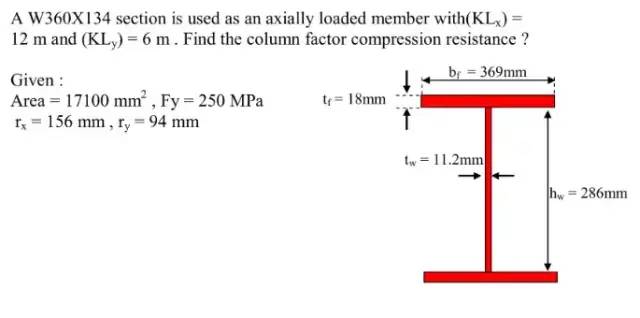
简单描述一下:你可能会以文本或图像的形式,得到不同的形状、材料或属性,你需要根据这个给定的数据计算指定的属性。
所有的计算都是按规格规范化的,所以如果你知道你需要计算什么,你就可以猜出该计算需要哪些属性。
我们该怎么做?
阅读问题
首先我们需要阅读问题。此时,使用任何OCR读取文本并提取所需内容非常容易。以下示例将帮助你理解:

为简单起见,输入图像被裁剪
上图是我们的输入。我们将使用 Keras-OCR 通过使用下面的代码块来阅读文本:
import keras_ocr
image_path = "Path of the image" # Something like C:\..\image.png
pipeline = keras_ocr.pipeline.Pipeline()
image = keras_ocr.tools.read(image_path)
prediction = pipeline.recognize([image])[0]
boxes = [value[1] for value in prediction]
canvas = keras_ocr.tools.drawBoxes(image=image, boxes=boxes, color=(255, 0, 0), thickness=1)
阅读结果
此外,我们可以使用以下方式访问图像的内容:
for text, box in prediction:
print(text)
文本的输出
我觉得思路很清晰。你将图像提供给 ocr,ocr 读取它并将输出返回给你。之后我们可以处理这个输出来学习属性。
NLP(自然语言处理——机器阅读文本、理解文本并返回响应)不是这里的主要主题,因此在本文中我们不会对其进行详细介绍,但我们可以使用简单的正则表达式方法将关键字与值匹配。
如果你听说过 ChatGPT——一种最近非常流行的高级聊天机器人,你可以猜到将文本理解为机器并不是这里的大问题。
到目前为止,我们为与读数相关的假设提供了一些基础。接下来我们需要为我们的对象检测做一些准备。
对象检测
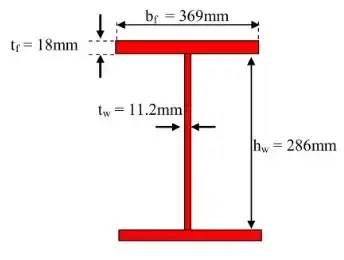
我们需要识别绘图和获取尺寸
由于我们在前一部分从文本中获取了信息,因此我们继续分析绘图。但在继续之前,请先看看这篇文章:https://arxiv.org/ftp/arxiv/papers/2205/2205.02659.pdf
我们可以看到,更复杂的绘图在形状和注释方面的识别准确率为 80%。要点是:
Faster-RCNN ResNet50为绘图识别提供了良好的结果。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









