







 本文介绍了一种使用Python库docTR来精确提取车辆识别号(VIN)的方法,针对户外噪声图像和非标准字体的挑战。通过微调docTR的预训练模型,实现了对VIN检测和识别的高性能,最终在测试集中达到90%的端到端准确率。
本文介绍了一种使用Python库docTR来精确提取车辆识别号(VIN)的方法,针对户外噪声图像和非标准字体的挑战。通过微调docTR的预训练模型,实现了对VIN检测和识别的高性能,最终在测试集中达到90%的端到端准确率。

VIN(车辆识别号)是一个17个字符的字符串,由数字和大写字母组成,用作汽车的指纹。
它可以帮助识别任何一辆汽车的寿命,并获得有关它的具体信息。该唯一标识符在制造过程中打印在车辆的某个位置,以便人们在租车或销售等过程中需要时读取。
几个月前,我们的朋友联系了我们,他们来自Monk:一家AI公司,为汽车、保险和移动市场提供最先进的计算机视觉解决方案。他们正在开发一种视觉智能技术,能够在车辆生命周期的每个阶段对车辆进行检查。
他们唯一的重点是建立检测、分类和评估车辆损坏的最佳技术。能够自动读取VIN对他们来说很重要。
VIN用例
请注意,本文中VIN的任何照片都是伪造或模糊的。
问题的定义很简单:
输入是写在汽车上的VIN的照片
输出是一个17个字符长的字符串:VIN

以高精度自动执行此任务比看起来要困难。主要困难是:
输入的照片大多是在室外拍摄的,有很多噪音(亮度、水渍、阴影等),这会使车辆识别码的检测和识别变得困难
虽然VIN是以相当标准的格式书写的,但所使用的字体并不标准,也不总是相同的,字母间距可能会有很大差异。
存在一种校验和验证方法来验证VIN,但它并不适用于所有车辆。我们拒绝了这个后处理解决方案。
最后但并非最不重要的一点是,VIN并不总是照片中唯一的文字,使用传统的OCR方法是不够的,因为我们需要添加一层后处理来过滤掉不需要的字符。
以下是一些噪声图像的示例:

我们做的第一件事就是运行现成的OCR,既可以从开源库中运行,也可以从基于云的API中运行。
VIN是写在汽车上的,而不是写在纸上的,而且它不是字符识别技术的常见用例。我们必须找到另一种使用Python和docTR的方法。
为什么要使用docTR?
DocTR是一个面向数据科学家和开发人员的Python光学字符识别库。端到端OCR使用两个阶段的方法实现:文本检测和文本识别。
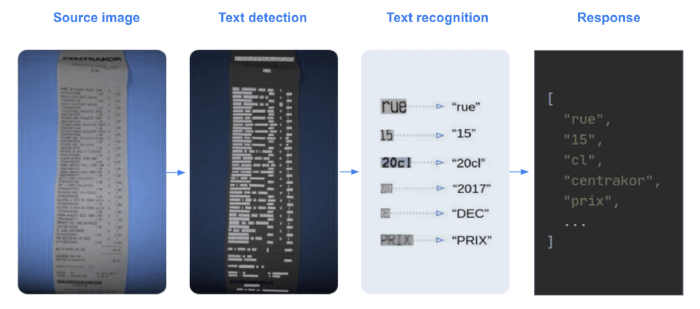
DocTR包括用于检测和识别任务的预训练模型。任何人都可以使用它从图像或pdf中提取单词。你可以非常轻松地测试它(更多信息请参阅docTR文档)
1.安装
pip install python-doctr2.Python hello world
from doctr.io import DocumentFile
from doctr.models import ocr_predictor
model = ocr_predictor(pretrained=True)
# PDF
doc = DocumentFile.from_pdf("path/to/your/doc.pdf").as_images()
# Analyze
result = model(doc)但正如我们之前提到的,没有OCR能很好地解决我们的VIN问题。通用OCR不是这个用例的好解决方案,因为:
OCR应该是通用的,而文本检测和文本识别的问题在涉及“野外”数据(如VIN的照片)时非常困难。
通用OCR的输出列出了写入图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2267
2267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









