







 本文详细介绍了线性分类器的设计,包括二分类问题、线性判别函数、多类决策问题以及感知器和最小平方误差准则。线性分类器主要通过寻找最佳参数来确定决策面,其中最小距离准则和感知器准则被用于优化设计。此外,还讨论了线性可分性和样本规范化,以及解向量和解区的概念。
本文详细介绍了线性分类器的设计,包括二分类问题、线性判别函数、多类决策问题以及感知器和最小平方误差准则。线性分类器主要通过寻找最佳参数来确定决策面,其中最小距离准则和感知器准则被用于优化设计。此外,还讨论了线性可分性和样本规范化,以及解向量和解区的概念。
线性分类器
二分类问题
直接假设判别函数具有某种形式,然后利用样本集确定出判别函数中的未知参数。
𝑔(𝑥)的具体形式需根据样本集在模式空间中的分布情况或相关领域的专业知识来确定。
本章研究𝑔(𝑥)为线性函数时,分类器参数的估计问题。
基于样本的直接确定判别函数方法:

如何估计这些未知参数?
(1)应针对不同的实际情况,提出不同的设计要求,使得所设计的分类器尽可能好地满足这些要求。
(2) 由于所提要求不同,结果也相各异,这说明上述“尽可能好”是相对于所提要求而言的。
这种设计要求,往往用某个特定的函数来表达,称之为准则函数,“尽可能好”的结果对应于准则函数取最优值。
虽然不知道上面那段估计未知参数的文字是什么意思,反正最后就是用函数来作为准则函数就行,然后用函数去分类
分类器设计问题就转化为求准则函数极值的问题了,因此就可以利用最优化技术解决模式分类问题。

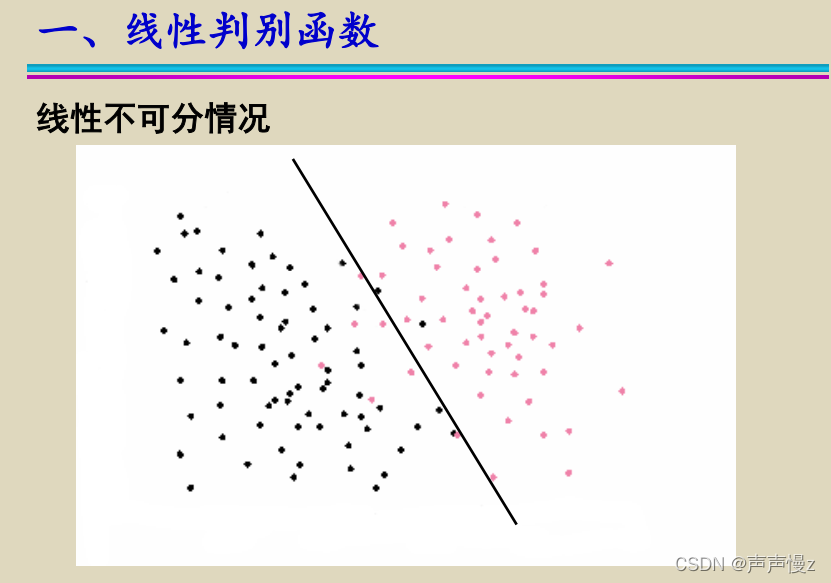
线性判别函数


上面两个形式是等价的
w
0
w_0
w0是形式一的阈值。
二分类问题的决策规则:
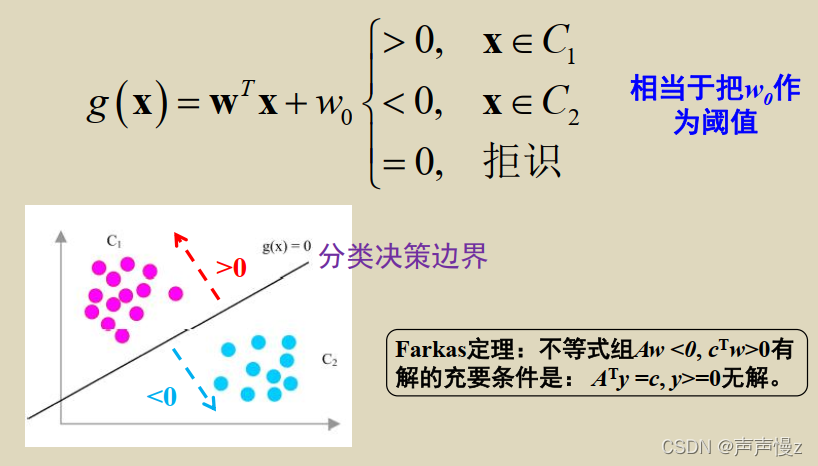
g
(
x
)
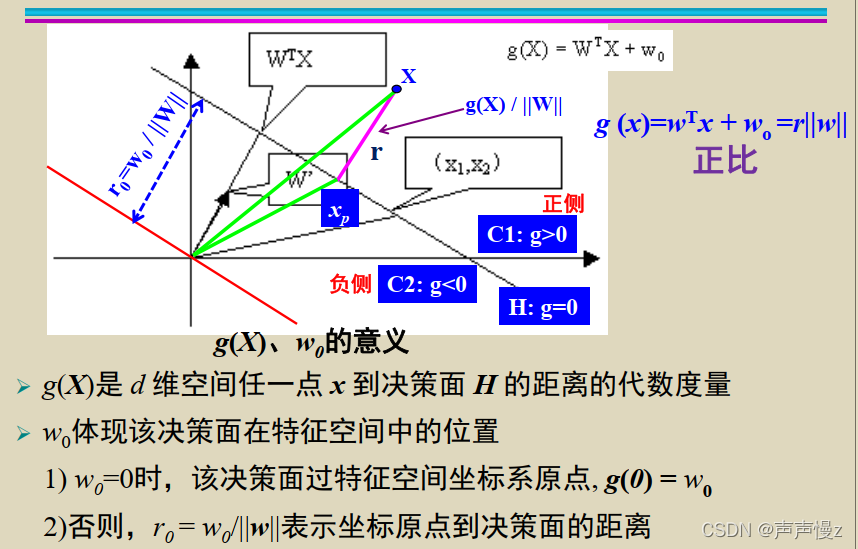
g(x)
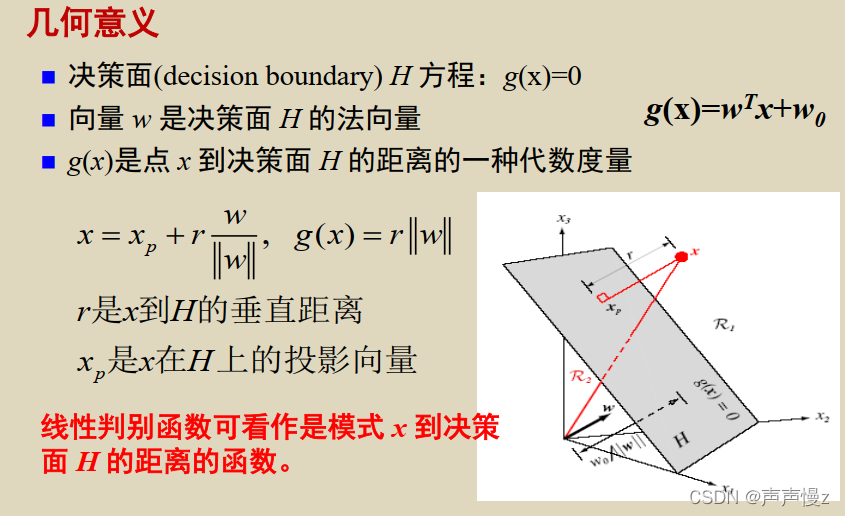
g(x)是点x到决策面
H
H
H的距离的一种代数度量。
w
0
w_0
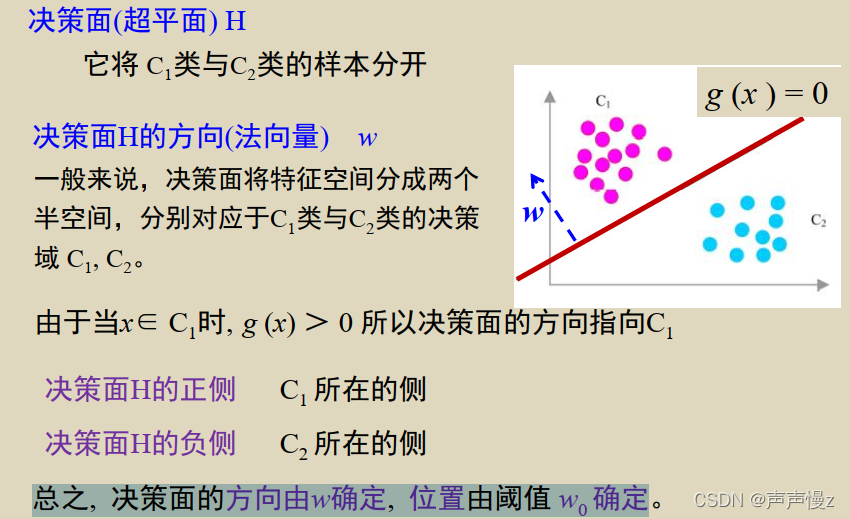
w0体现该决策面在特征空间中的位置
-
w
0
=
0
w_0=0
w0=0时,该决策面过特征空间坐标系原点,
g
(
0
)
=
w
0
g(0) = w_0
g(0)=w0
2)否则, r 0 = w 0 / ∣ ∣ w ∣ ∣ r_0 = w_0/||w|| r0=w0/∣∣w∣∣表示坐标原点到决策面的距离。

线性分类器设计的主要步骤
所谓设计线性分类器, 就是利用训练样本集建立线性判别函数。
(1) 估计其中未知参数
w
w
w和
w
o
w_o
wo, 即寻找最好参数的过程。
(2)最好的参数往往是准则函数的极值点。
(3)转化为利用训练样本集寻找准则函数的极值点
w
w
w和
w
o
w_o
wo 的问题。

分类决策问题
- 分类的基本原理
不同模式对应特征点在不同的区域中散布。运用已知类别的训练样本进行学习,产生若干个代数界面 g ( x ) = 0 g(x)=0 g(x)=0,将特征空间划分成一些互不重叠的子区域。 - 判别函数表示界面的函数 g(x) 称为判别函数(Discriminant Function) 。
多类决策问题

多分类学习方法:


一对其余
线性判别函数将属于
ω
i
ω_i
ωi类的模式与其余不属于
ω
i
ω_i
ωi类的模式分开,
m
m
m类分类问题转换成
m
−
1
m-1
m−1个两类问题。
m
m
m类问题要有
m
m
m个判别函数
d
i
,
i
=
1
,
2
,
…
,
m
d_i, i = 1, 2, …, m
di,i=1,2,…,m。
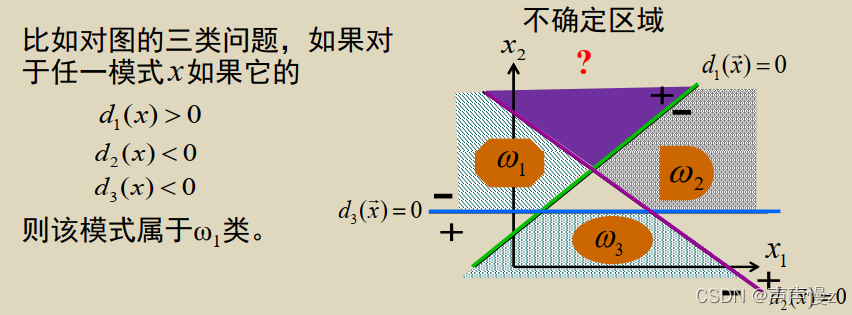
判别规则:
{
d
i
(
x
)
>
0
d
j
(
x
)
≤
0
∀
j
≠
i
\begin{cases}d_i(x)>0 \\ d_j(x) \leq 0 \quad \forall j\neq i \end{cases}
{di(x)>0dj(x)≤0∀j=i

一对一
对m类中的任意两类 ω i ω_i ωi和 ω j ω_j ωj都分别建立一个判别函数,这个判别函数将属于 ω i ω_i ωi类与 ω j ω_j ωj类的模式区分开,此函数对其他分类不提供信息,因此, m m m类问题需要建立 m ( m − 1 ) / 2 m(m-1)/2 m(m−1)/2 个判别函数 d i j , i = 1 , 2 , … , m d_{ij}, i = 1, 2, …, m dij,i=1,2,…,m
判别规则为:
若
d
i
j
(
x
)
>
0
,
j
≠
i
j
=
1
,
2
,
…
,
m
d_{ij}(x)>0,j\neq i \quad j=1,2,\dots,m
dij(x)>0,j=ij=1,2,…,m则判x属于
ω
i
ω_i
ωi
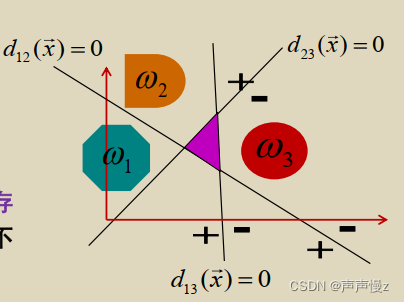
采用这种方案,判别空间中同样可能存在不确定区域,如图中的斜线区域。不确定区域中的模式无法确定其类别。

多对多
m类问题定义m个判别函数 d i , i = 1 , 2 , … , m d_i, i=1, 2, …, m di,i=1,2,…,m。
判别规则为: 若 d i ( x ) > d j ( x ) , j ≠ i ; i , j = 1 , 2 , … , m di_(x) > d_j(x) , j≠i; i, j=1, 2, …, m di(x)>dj(x),j=i;i,j=1,2,…,m则判 x x x属于 ω i ω_i ωi类。
决策面
H
i
j
H_{ij}
Hij方程为
d
i
(
x
)
=
d
j
(
x
)
j
≠
i
;
i
,
j
=
1
,
2
,
…
,
m
d_i (x) = d_j(x)\quad j≠i; i, j=1, 2, …, m
di(x)=dj(x)j=i;i,j=1,2,…,m
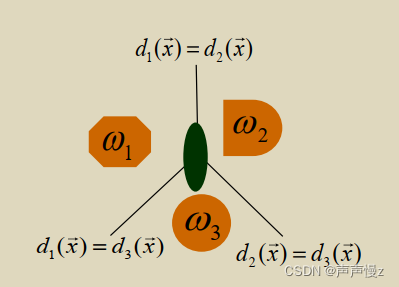

总结

最小距离准则
d 维空间中两个向量之间的欧氏距离
设
x
=
(
x
1
,
x
2
,
…
,
x
d
)
T
,
y
=
(
y
1
,
y
2
,
…
,
y
d
)
T
x = ( x_1 , x_2 , … , x_d)^T, y = (y_1 , y_2 , … , y_d )^T
x=(x1,x2,…,xd)T,y=(y1,y2,…,yd)T,则x, y之间的欧氏距离
d
d
d为
d
2
=
(
x
−
y
)
T
(
x
−
y
)
d^2= (x-y)^T(x-y)
d2=(x−y)T(x−y)。
同类模式在模式空间中应相互靠近,根据这一特点, 我们可利用距离最小准则来设计分类器。
设有m类已知类别的模式(样本)集。计算 ω i ω_i ωi类中所有样本的均值 μ i μ_i μi,记样本 x x x 到 ω i ω_i ωi 类的距离为: d i ( x ) = ( x − μ i ) T ( x − μ i ) , i = 1 , 2 , … , m d_i (x) = (x - μ_i)^T ( x - μ_i), i = 1, 2, …, m di(x)=(x−μi)T(x−μi),i=1,2,…,m。
按最小距离分类原理,决策规则为:
若
D
i
(
x
)
<
D
j
(
x
)
,
j
≠
i
;
i
,
j
=
1
,
2
,
…
,
m
D_i(x) < D_j (x) , j≠i; i, j = 1, 2, … , m
Di(x)<Dj(x),j=i;i,j=1,2,…,m则判x属于
ω
i
ω_i
ωi类。
就是离那里近归为哪里。


分类效果不好的原因在于判别函数的权向量及阈值仅仅利用了各类样本的均值信息,而没有充分利用样本的其它信息。

感知器准则
基本概念
(1) 线性可分性及其概率
假设已知一组容量为n的样本集 y 1 , y 2 , … , y n y_1,y_2,…,y_n y1,y2,…,yn, 其中 y i y_i yi为 d ’ d’ d’维增广样本向量, 分别来自 ω 1 ω_1 ω1类和 ω 2 ω_2 ω2类。 如果存在一个权向量 w w w, 使得对于任何 y ∈ ω 1 y∈ ω_1 y∈ω1, 都有 w T y > 0 w^Ty>0 wTy>0,而对于任何 y ∈ ω 2 y∈ ω_2 y∈ω2, 都有都有 w T y < 0 w^Ty<0 wTy<0, 则称这组样本集为线性可分的, 否则为线性不可分。
总结,就是对于 ω 1 ω_1 ω1类 w T y > 0 w^Ty>0 wTy>0,对于 ω 2 ω_2 ω2类 w T y < 0 w^Ty<0 wTy<0
反过来,如果样本集是线性可分的,则必存在一个权向量 w w w,能将这个样本集正确的分类。
(2) 样本的规范化
如果样本集
y
1
,
y
2
,
…
,
y
n
y_1,y_2,…,y_n
y1,y2,…,yn是线性可分的,则必存在某个或某些权向量
w
w
w,使得:
{
w
T
y
i
>
0
,
y
i
∈
ω
1
w
T
y
i
<
0
,
y
i
∈
ω
2
\begin{cases} w^Ty_i > 0,\quad y_i \in ω_1 \\ w^Ty_i < 0,\quad y_i \in ω_2\end{cases}
{wTyi>0,yi∈ω1wTyi<0,yi∈ω2
如果在来自
ω
2
ω_2
ω2类的样本
y
j
y_j
yj 前面加上一个负号,即令
y
j
’
=
−
y
j
y^’_j= -y_j
yj’=−yj,其中
y
j
∈
ω
2
y_j∈ ω_2
yj∈ω2,则有
w
T
y
j
’
>
0
w^Ty_j^’>0
wTyj’>0。因此,令
y
n
’
=
{
y
i
,
对
于
一
切
y
i
∈
ω
1
−
y
j
,
对
于
一
切
y
j
∈
ω
2
y^’_n=\begin{cases}y_i,\quad 对于一切y_i \in ω_1 \\ -y_j,\quad 对于一切y_j \in ω_2\end{cases}
yn’={yi,对于一切yi∈ω1−yj,对于一切yj∈ω2
上述过程称为样本的规范化,
y
n
’
y_n^’
yn’ 叫做规范化增广样本向量。
上面这段话的意思大概是,把原本需要用 w T y i w^Ty_i wTyi判别的样本集,现在简单地根据符号的正负便能判断相应的样例是属于 ω 1 ω_1 ω1还是 ω 2 ω_2 ω2
(3)解向量和解区
在线性可分情况下,满足
w
T
y
i
>
0
,
i
=
1
,
2
,
…
,
n
w^Ty_i > 0, i=1,2,…,n
wTyi>0,i=1,2,…,n 的权向量
w
w
w称为解向量。
方程
w
T
y
i
=
y
i
T
w
=
0
w^Ty_i = y_i^Tw = 0
wTyi=yiTw=0确定了一个以yi为法向量的超平面,
n
n
n个样本将产生
n
n
n个超平面,每个超平面把权空间分为两个半空间,且
w
w
w位于正半空间。 解向量若存在,必在
n
n
n 个正半空间的交迭区,且该区任意向量都是解向量
w
w
w。可见解向量往往不只一个,而是无穷多个解向量组成的区域,称之为解区。
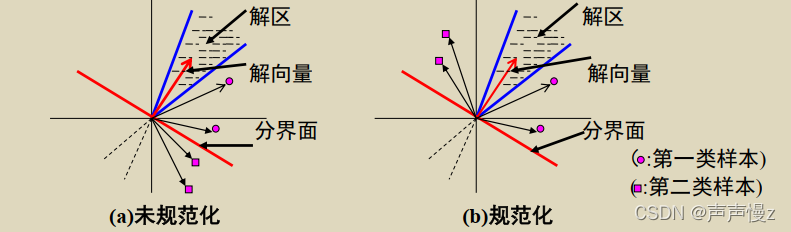
(4)对解区的限制
对解区加以限制的目的在于使解向量
w
w
w更可靠。通常认为,越靠近解区中心的解向量,似乎越能对新的样本正确分类。
因此,引入余量
𝑏
>
0
𝑏 > 0
b>0,并寻找满足
𝑤
𝑇
𝑦
𝑖
≥
𝑏
𝑤^𝑇𝑦_𝑖 ≥ 𝑏
wTyi≥b的解向量。显然,由
𝑤
𝑇
𝑦
𝑖
≥
𝑏
>
0
𝑤^𝑇𝑦_𝑖 ≥ 𝑏 > 0
wTyi≥b>0所产生的正半空间的交迭区(即新解区)位于原解区之中。
它的边界离开原解区边界的距离为
𝑏
/
∣
∣
𝑦
𝑖
∣
∣
𝑏 / ||𝑦𝑖||
b/∣∣yi∣∣。如图所示。
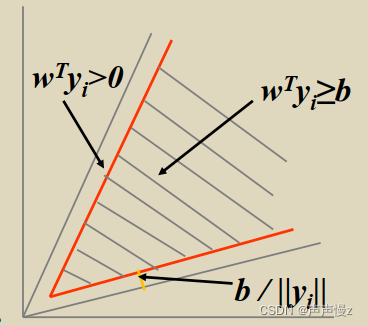
引入余量的目的是使解向量𝑤不至于解区的边界点上。
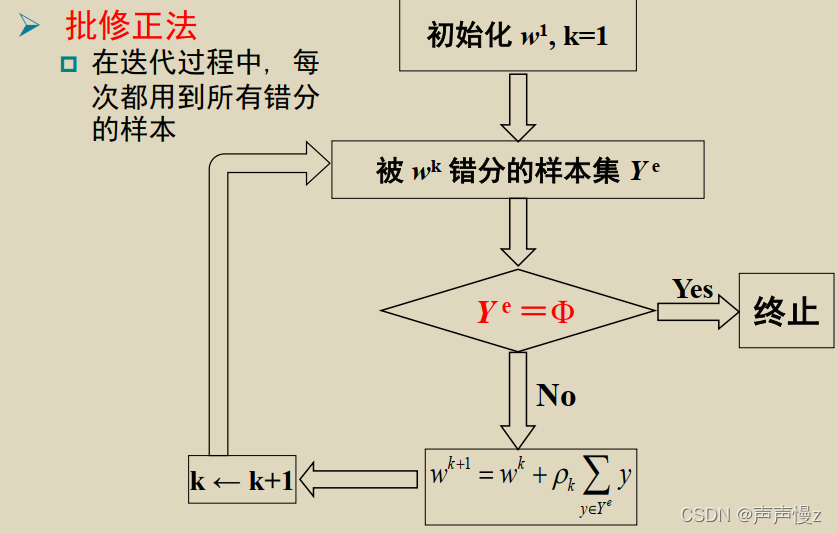
感知器准则函数

注意事项:
(1)
y
i
y_i
yi是规范化增广样本,所以
w
T
y
i
>
0
w^Ty_i>0
wTyi>0,所以当
y
y
y 被错分类时
w
T
y
≤
0
w^Ty ≤ 0
wTy≤0,即
−
w
T
y
≥
0
− w^Ty ≥ 0
−wTy≥0。
(2)准则函数是根据被错分的样本来计算的

最小平方误差准则
由于感知器准则及其梯度下降算法只适用于线性可分情况,对于线性不可分情况,迭代过程永远不会终结,即算法不收敛,实际问题事先无法确定是否线性可分。
所以希望得到一种对两种情况都可适用的线性判别算法:
➢ 对线性可分问题,可得到一个如感知器准则函数那样的解向量;
➢ 对线性不可分问题,能够得到一个使某种度量误差(或损失)的准则函数达到最小值的解向量。
最小平方误差准则函数





















 1932
1932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









