




 本文探讨了Kafka的三种消费策略:精确一次、至少一次和最多一次消费,以及它们在数据丢失和重复消费场景下的表现。强调了在实时计算中,由于自动提交偏移量可能导致的数据不一致问题,并提出了利用关系型数据库事务和手动提交偏移量结合幂等性保存来确保数据一致性。同时,文章提到了使用Redis存储偏移量的方法,以及如何在保存数据到ES后提交偏移量。
本文探讨了Kafka的三种消费策略:精确一次、至少一次和最多一次消费,以及它们在数据丢失和重复消费场景下的表现。强调了在实时计算中,由于自动提交偏移量可能导致的数据不一致问题,并提出了利用关系型数据库事务和手动提交偏移量结合幂等性保存来确保数据一致性。同时,文章提到了使用Redis存储偏移量的方法,以及如何在保存数据到ES后提交偏移量。
- 精确一次消费(Exactly-once)
是指消息一定会被处理且只会被处理一次。不多不少就一次处理 - 至少一次消费(at least once)
主要是保证数据不会丢失,但有可能存在数据重复问题 - 最多一次消费 (at most once)
主要是保证数据不会重复,但有可能存在数据丢失问题
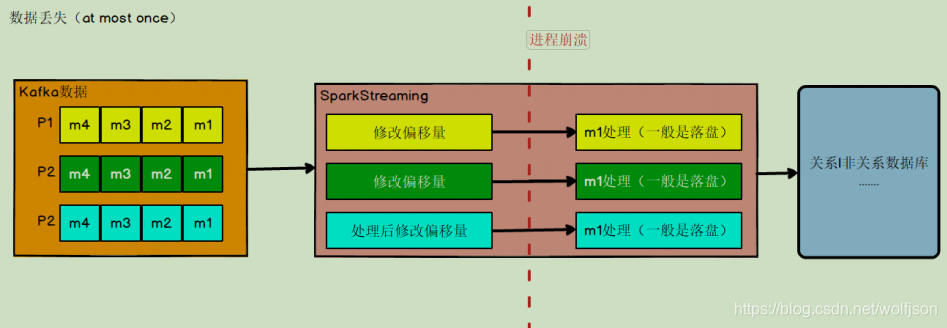
数据丢失
- 实时计算任务进行计算,到数据结果存盘之前,进程崩溃,假设在进程崩溃前 kafka
调整了偏移量,那么 kafka 就会认为数据已经被处理过,即使进程重启,kafka 也会从新的
偏移量开始,所以之前没有保存的数据就被丢失掉了
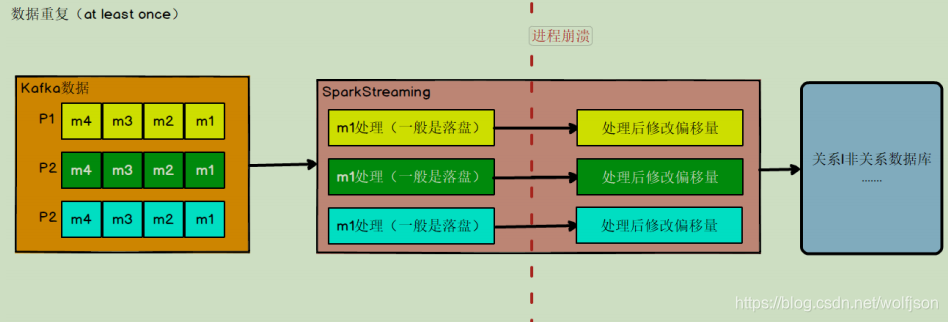
重复消费
- 如果数据计算结果已经存盘了,在 kafka 调整偏移量之前,进程崩溃,那么 kafka 会
认为数据没有被消费,进程重启,会重新从旧的偏移量开始,那么数据就会被 2 次消费,
又会被存盘,数据就被存了 2 遍,造成数据重复。
目前 Kafka 默认每 5 秒钟做一次自动提交偏移量,这样并不能保证精准一次消费
enable.auto.commit 的默认值是 true;就是默认采用自动提交的机制。
auto.commit.interval.ms 的默认值是 5000,单位是毫秒。
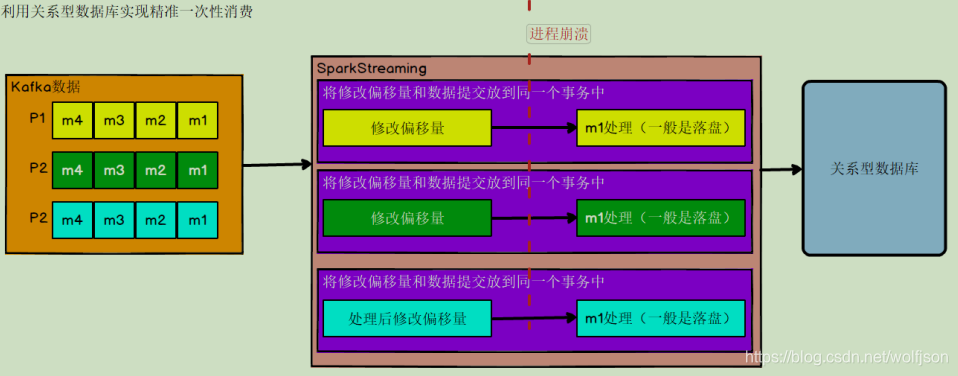
利用关系型数据库的事务进行处理
- 偏移量的提交与数据的保存,不是原子性的。如果能做成要么数据保存和偏移量都成功,要么两个失败,那么就不会出现丢失或者重复了。
- 数据必须都要放在某一个关系型数据库中,无法使用其他功能强大的 nosql 数据库
- 事务本身性能不好
- 如果保存的数据量较大一个数据库节点不够,多个节点的话,还要考虑分布式事务
的问题。分布式事务会带来管理的复杂性,一般企业不选择使用,有的企业会把分
布式事务变成本地事务,例如把 Executor 上的数据通过 rdd.collect 算子提取到
Driver 端,由 Driver 端统一写入数据库,这样会将分布式事务变成本地事务的单
线程操作,降低了写入的吞吐量
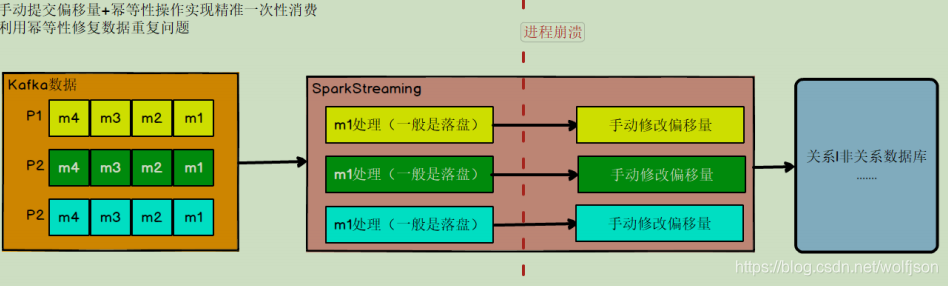
手动提交偏移量+幂等性处理
- 数据丢失问题,办法就是要等数据保存成功后再提交偏移量,所以就必须手工
来控制偏移量的提交时机 - 把数据的保存做成幂等性保存。即同一批数据反复保存多次,数据不会翻倍,保存一次和保
存一百次的效果是一样的。利用数据存储的唯一约束、索引、主键保证插入、更新操作的幂等性
xxDstream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
因为 offset 的存储于 HasOffsetRanges,只有 kafkaRDD 继承了他,所以假如我们对
KafkaRDD 进行了转化之后,其它 RDD 没有继承 HasOffsetRanges,所以就无法再获取
offset 了。
利用 ZooKeeper,Redis,Mysql 等工具手动对偏移量进行保存
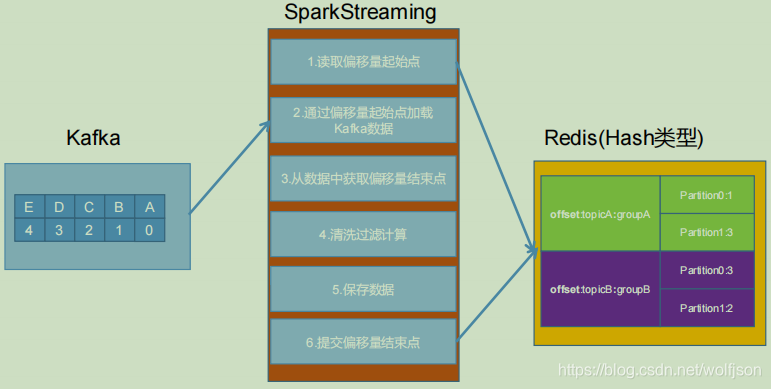
- 从Redis中获取偏移量
// type:hash key: offset:topic:groupId field:partition value: 偏移量
def getOffset(topic: String, groupId: String): Map[TopicPartition 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









