




一、图片读取cv2.imread(路径,格式3选1)
格式=1:彩色;0:灰度;-1同1,数据结构如下:

前面是彩色图,三维;后面是灰度图,二维。
二、图像二值化cv2.threshold,cv2.adaptiveThreshold
1. cv2.threshold(对象,阈值,设定值,阈值规则5选1),可处理彩色图。比如:
ret,th1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY)。
ret:True或False,代表有没有读到图片;dst: 目标图像;
表示大于127值的全置为255,否则置为0。
2. cv2.adaptiveThreshold(加工对象,设定值,计算方法2选1,阈值规则5选1,阈值区域大小,常量),只能处理灰色图。比如:
th3 = cv2.adaptiveThreshold(~img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY,35,-5),35*35区域?加权平均加上5设为阈值(常量可以为负),大于阈值置为255,否则置0。文字表格效果不错,见下图:

不加“~”,即在源对象前不加“~”,cv2.adaptiveThreshold(img,255,...,效果如下:

三、图像平滑处理(滤波降噪)cv2.blur、cv2.boxFilter、cv2.medianBlur、cv2.GaussianBlur、cv2.bilateralFilter
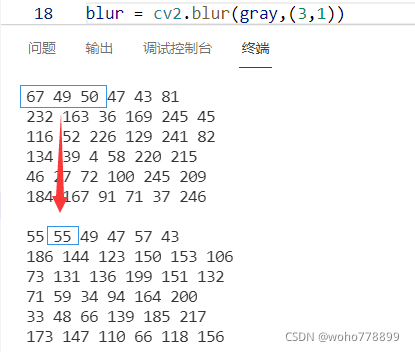
1. 均值滤波:cv2.blur(对象,核大小),如:blur = cv2.blur(img,(3,3)),该点对应核中中心,设定值为核大小范围内的所有值平均,边缘处理不详,如下:
2.方框滤波:类似均值滤波,最后一个参数Ture时取均值,为False时,取和。

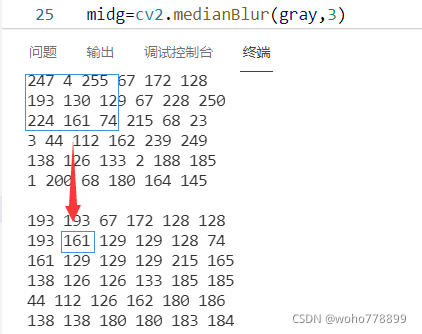
3.中值滤波:cv2.medianBlur(对象,n),n为大于1的奇数。取中位数,边缘处理不详,如下:
4.高斯滤波(貌似用的很多):cv2.GaussianBlur(对象,核,0,0),核中心权重最大,周围依次下降,后面两个参数,可只设置一个,应该是X、Y轴的计算微调,网上说是标准差之类。

3X1的核,权重为25%、50%、25%。3X3核依次为:0.0625、0.125、0.0625、0.125、0.25、0.125、0.0625、0.125、0.0625。如果将差参数置1,会产生小量变化。
5.双边滤波:cv2.bilateralFilter(对象,n,0,0),n代表核大小,又有说直径范围,后两个参数分别代表颜色、位置的微调值(标准差)。计算方法不详,同时考虑距离和差值,过于复杂,反应慢。能很好的保留边缘信息。用法举例:cv2.bilateralFilter(gray,9,75,75)。
6.网上小结:
- 在不知道用什么滤波器好的时候,优先高斯滤波
cv2.GaussianBlur(),然后均值滤波cv2.blur()。 - 斑点和椒盐噪声优先使用中值滤波
cv2.medianBlur()。 - 要去除噪点的同时尽可能保留更多的边缘信息,使用双边滤波
cv2.bilateralFilter()。 - 线性滤波方式:均值滤波、方框滤波、高斯滤波(速度相对快)。
- 非线性滤波方式:中值滤波、双边滤波(速度相对慢)。
四、图像边缘检测cv2.canny、cv2.sobel、cv2.Laplacian
1、cv2.Canny(对象,最小值,最大值),可选参数apertureSize=7,最大为7效果不错,线框闭合,对比如下:
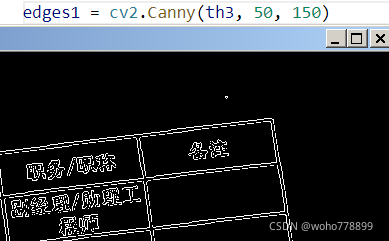
apertureSize: aperture size for the Sobel operator.算子的孔径大小。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 530
530




 到【灌水乐园】发言
到【灌水乐园】发言







