



 本文详细介绍了K均值聚类算法的工作原理、步骤,以及如何在MATLAB中实现,包括优点、缺点和适用场景。通过实例展示了Aggregation.mat数据集的聚类过程。
本文详细介绍了K均值聚类算法的工作原理、步骤,以及如何在MATLAB中实现,包括优点、缺点和适用场景。通过实例展示了Aggregation.mat数据集的聚类过程。
K均值(K-means)是一种常用的聚类算法,用于将数据集划分为K个不同的组(簇),使得每个数据点属于与其最近的均值点所代表的簇。K均值算法的基本思想是通过迭代优化,将数据点分配到K个簇中,并调整簇的均值(中心)以最小化簇内数据点与对应中心点之间的距离。
K均值算法的步骤如下
①初始化:随机选择K个初始中心点(可以是数据集中的任意数据点)作为各个簇的中心。
②分配数据点:对于每个数据点,计算其与各个中心点的距离,并将其分配到距离最近的簇中。
③更新中心点:对于每个簇,计算该簇所有数据点的均值,更新该簇的中心点。
④重复步骤②和步骤③:直到满足停止条件(如中心点不再发生变化或达到最大迭代次数)。
K均值算法的目标是最小化所有数据点与其所属簇中心点之间的距离之和(即簇内的总方差)。这意味着每个簇的中心点应该尽可能代表该簇内的数据点,同时不同簇之间的中心点应该尽可能远离彼此。
K均值算法的优点包括简单易实现、计算效率高,适用于大规模数据集。然而,K均值算法也有一些缺点,例如对K值的选择敏感、对初始中心点的选择敏感,还有可能收敛到局部最优解等。
在实际应用中,K均值算法常用于聚类分析、图像分割、异常检测等领域。需要注意的是,K均值算法对于非凸形状的簇效果可能不佳,因此在某些情况下可能需要其他更复杂的聚类算法来处理数据。
纯MATLAB代码实现Kmeans
以UCI常用数据集Aggregation.mat为例进行展示。
Aggregation数据集具有两个特征,7种类别。matlab代码实现如下:
%% k-means聚类
clc
clear
close
load Aggregation.mat
data = Aggregation(:,2:3);
%% 聚类
N = 7; % 设定聚类数量
[m,n] = size(data);
pattern = zeros(m,n+1); % n+1列用于标记当前点所分配到的类索引号
center = zeros(N,n); % 初始化聚类中心
pattern(:, 1:n) = data(:,:);
for x=1:N
center(x,:) = data(randi(788,1), :); % 第一次随机产生聚类中心坐标
end
while 1
distance = zeros(1,N);
num = zeros(1,N); % 记录各个类中包含元素个数
new_center=zeros(N,n); % 保存新得到的聚类中心
for x=1:m
for y=1:N
distance(y) = norm(data(x,:)-center(y,:)); % 计算点到每个类的距离
end
[~, temp] = min(distance); % 获取当前点到几个类的最小距离
pattern(x, n+1) = temp; % 标记x位置的点分配到对应的类中
end
k = 0;
% 将同一个类中的点坐标相加,计算新的中心坐标
for y=1:N
for x=1:m
if pattern(x, n+1) == y
new_center(y,:) = new_center(y,:)+pattern(x, 1:n);
num(y) = num(y)+1;
end
end
% 计算得到新的聚类中心点
new_center(y,:) = new_center(y,:)/num(y);
if norm(new_center(y,:)-center(y,:))<0.1
% 是否接受当前新产生的聚类中心点
k=k+1;
end
end
if k==N
break;
else
center = new_center;
end
end
[m, n]=size(pattern);
%% 显示聚类后的数据
figure
hold on;
grid on;
for i=1:m
if pattern(i,n)==1
plot(pattern(i,1),pattern(i,2),'r.','Markersize', 8);
plot(center(1,1),center(1,2),'kx','Markersize', 18);
elseif pattern(i,n)==2
plot(pattern(i,1),pattern(i,2),'g.','Markersize', 8);
plot(center(2,1),center(2,2),'kx','Markersize', 18);
elseif pattern(i,n)==3
plot(pattern(i,1),pattern(i,2),'b.','Markersize', 8);
plot(center(3,1),center(3,2),'kx','Markersize', 18);
elseif pattern(i,n)==4
plot(pattern(i,1),pattern(i,2),'c.','Markersize', 8);
plot(center(4,1),center(4,2),'kx','Markersize', 18);
elseif pattern(i,n)==5
plot(pattern(i,1),pattern(i,2),'m.','Markersize', 8);
plot(center(5,1),center(5,2),'kx','Markersize', 18);
elseif pattern(i,n)==6
plot(pattern(i,1),pattern(i,2),'y.','Markersize', 8);
plot(center(6,1),center(6,2),'kx','Markersize', 18);
elseif pattern(i,n)==7
plot(pattern(i,1),pattern(i,2),'k.','Markersize', 8);
plot(center(7,1),center(7,2),'kx','Markersize', 18);
end
end
title('cluster result')结果如下:
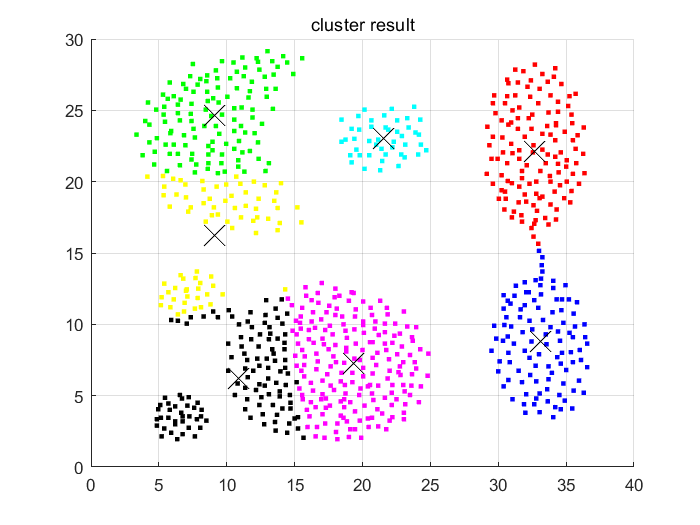
可以看到,数据集被完美的分为7类!
MATLAB自带Kmeans
%% matlab自带k-means聚类
clc
clear
close
load Aggregation.mat
data = Aggregation(:,2:3);
%% 使用matlab自带k-means聚类
x = data;
[idx, c] = kmeans(x, 7); % 聚成7类
figure
plot(x(idx==1, 1), x(idx==1,2), 'r.', 'MarkerSize', 10)
hold on
plot(x(idx==2, 1), x(idx==2,2), 'g.', 'MarkerSize', 10)
plot(x(idx==3, 1), x(idx==3,2), 'b.', 'MarkerSize', 10)
plot(x(idx==4, 1), x(idx==4,2), 'c.', 'MarkerSize', 10)
plot(x(idx==5, 1), x(idx==5,2), 'm.', 'MarkerSize', 10)
plot(x(idx==6, 1), x(idx==6,2), 'y.', 'MarkerSize', 10)
plot(x(idx==7, 1), x(idx==7,2), 'k.', 'MarkerSize', 10)
plot(c(:,1),c(:,2), 'kx', 'MarkerSize', 12, 'LineWidth',3)
legend('cluster 1', 'cluster 2', 'cluster 3','cluster 4','cluster 5','cluster 6','cluster 7', 'center', 'Location', 'NW')
title('cluster result')
grid on
hold off代码更简洁!且分类效果更好:
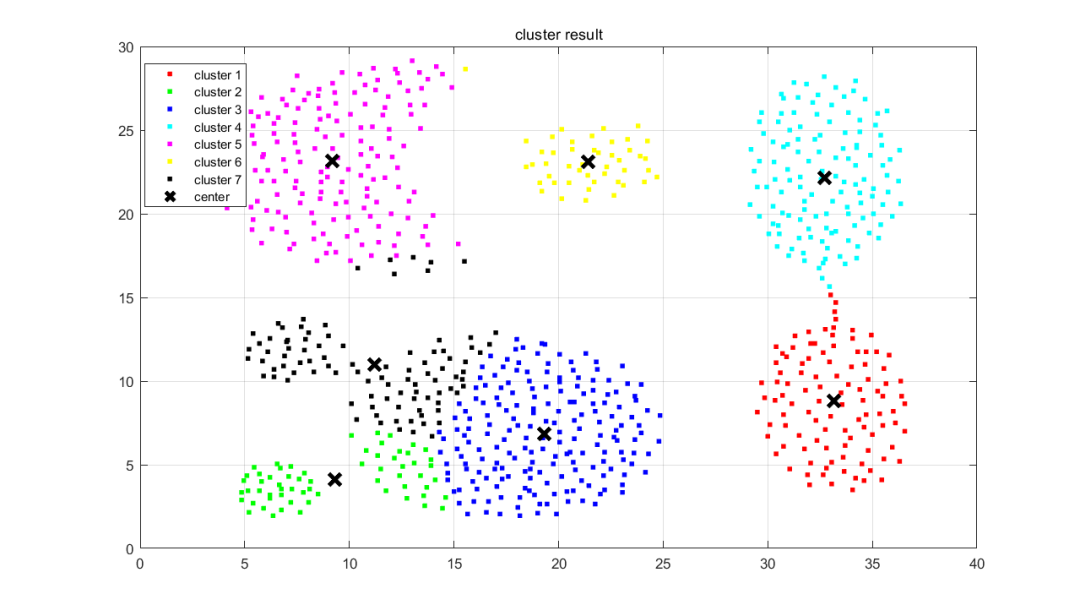
好啦,本期分到此结束。完整代码免费获取,请后台回复关键词:
K均值


















 2215
2215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











