







- 背景知识
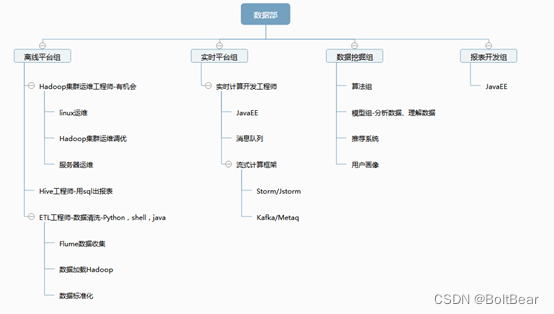
1.1、企业数据部的一般组织结构
企业数据部的一般组织结构,适用于大中型企业。
1.2、企业数据部的业务流程分析
业务流程:
电商业务人员:针对活动专题页(活动的效果)有业务需求
活动页的用户访问数、用户下单数、用户支付数、用户退单数
数据部部门:
数据分析人员(写sql),结果对外提供
数据展示:
报表平台组、发邮件excel
1.3、企业数据部的一般技术架构(重要)
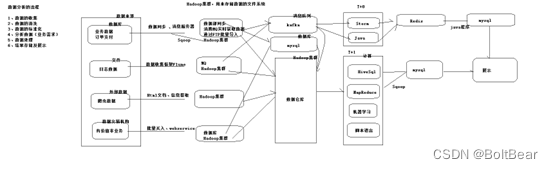
数据分析的两个流程:
实时分析流程:业务数据、消息队列、Storm实时编程、Redis、数据展示(秒级计算)
离线分析流程:不同数据源获取数据、Hadoop集群、数据计算(Hive、Spark、MapReduce)、数据展示(T+1计算)
2、Hadoop基础知识
Hadoop包括两个部分:对海量数据进行存储和操作
- 大数据分布式文件存储框架(HDFS)
- 大数据分布式数据计算框架(MapReduce)
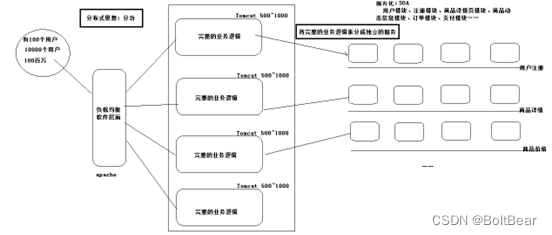
独立网站渐变到分布式网站的过程
数据库的读写分离、页面静态化、服务端的缓存、网络端的CDN、网络层面的负载均衡、软件层面的负载均衡。
业务逻辑的服务化及模块的集群服务
大数据的概念
产生数据的设备和系统越来越多
丰富数据来源及种类,从单一的业务数据库、企业数据到海量的外部数据
采集数据的手段变多
数据量变多了
数据处理方式和能力变多
问题:企业里面的数据是否是真的多了?
2.1、Hadoop是什么
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构
- Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
- Hadoop实现了一个分布式计算系统,MapReduce。
- Hadoop实现了一个资源管理系统,yarn。
2.2、Hadoop的特点
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
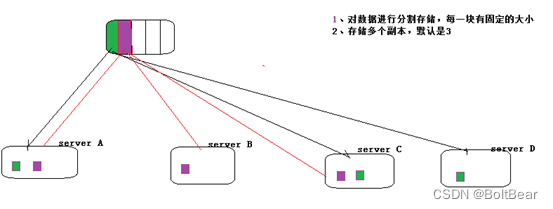
(HDFS的文件存储及可用性计算)
2.3、Hadoop HDFS核心组件
分布式的文件存储系统
- HDFS有两个核心角色:NameNode、DataNode
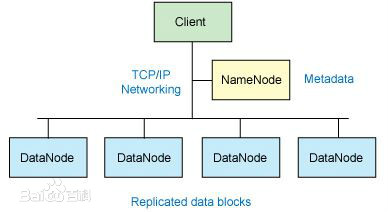
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等
这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode它为 HDFS 提供存储块
- NameNode的职责
它负责管理文件系统名称空间和控制外部客户机的访问
负责元数据信息管理
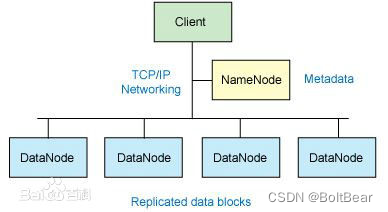
- DataNode的职责
数据存储
定期向NameNode汇报存储的文件信息
- 机架感知

2.4、Hadoop MapReduce核心组件
分布式计算框架
2.4.1 MapReduce是什么
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式计算系统上.
编程模型:
在一定的前提条件下,依据研究的程序特点,再现程序的结构、功能、属性、关系、过程等本质特征的过程;
软件开发的模型:输入、计算、输出,(JDK FileInputStream process FileOutputStream)
并行运算:
并行运算是针对串行运行来讲的,串行运算是依次执行几个事情,事情有前后的时间依赖关系,并行运算是指同时可以运行多个指定,相当于是同时执行多个事情。从而减少处理的总体时长,提高处理问题的效率。
分布式并行编程:
多线程、线程安全(同步)、线程池的问题
多个服务器之间通信的问题,RPC(远程过程调用)技术
代码的复杂度很高
2.4.2 MapReduce能解决什么问题
- 在Google,MapReduce用在非常广泛的应用程序中,包括"分布grep,分布排序,web连接图反转,每台机器的词矢量,web访问日志分析,反向索引构建,文档聚类,机器学习,基于统计的机器翻译..."值得注意的是,MapReduce实现以后,它被用来重新生成Google的整个索引,并取代老的ad hoc程序去更新索引。
- MapReduce会生成大量的临时文件,为了提高效率,它利用Google文件系统来管理和访问这些文件。
- 在谷歌,超过一万个不同的项目已经采用MapReduce来实现,包括大规模的算法图形处理、文字处理、数据挖掘、机器学习、统计机器翻译以及众多其他领域。
- 其他实现
Nutch项目开发了一个实验性的MapReduce的实现,也即是后来大名鼎鼎的hadoop
Phoenix是斯坦福大学开发的基于多核/多处理器、共享内存的MapReduce实现。
2.4.3 Hadoop的作者Doug Cutting
Doug Cutting是Lucene、Nutch 、Hadoop等项目的发起人
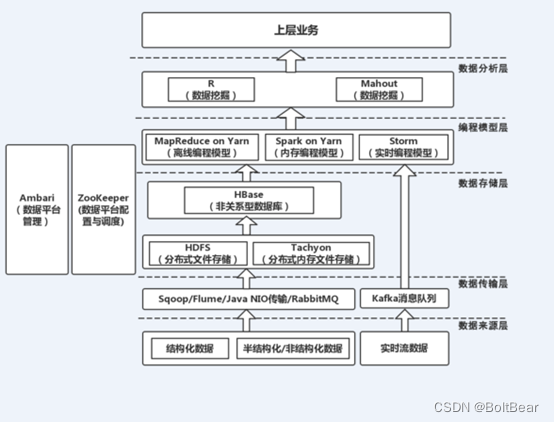
2.5、大数据技术生态体系
Hadoop(hdfs、mapreduce、yarn) 最基础数据处理技术框架,擅长离线数据分析
Zookeeper 分布式协调服务基础组件
Hbase 分布式海量数据库(基于HDFS),离线分析和在线业务通吃
Hive sql 数据仓库工具,使用方便,功能丰富,基于MR延迟大
Sqoop数据导入导出工具,关系型数据库和Hadoop HDFS的数据桥梁
Flume数据采集框架
Storm 实时流式计算框架,流式处理领域头牌框架
Spark 基于内存的分布式运算框架,一站式处理 all in one,新秀,发展势头迅猛。底层支持HDFS.
2.6 Hadoop产生的历史
最早来自于google的三大论文(为什么google会需要这么一种技术)
后来经过doug cutting的山寨,出现了java版本的 hdfs mapreduce 和 hbase
以上三个组件整合起来成为apache的一个顶级项目 hadoop
到了v.0.20.2 雅虎搭建了2000节点的hadoop集群,参加了一次排序性能运算比赛,获得第一名,从此,hadoop声名鹊起,风靡全球
0.20.2 --à 1.2.1----------à|---à2.2.0(HDFS的namenode高可用)--à2.4.1 (YARN的高可用)--2.6à2.7。2
à0.23 ---à|
经过演化,hadoop的组件又多出一个yarn(mapreduce+ yarn + hdfs)
2.7 Hadoop Yarn和核心组件
ResourceManager 资源调度,管理集群中所有的物理机(内存、计算资源)
NodeManager 当前物理机上的管理者,用来创建具体执行任务进程。
2.8 Hadoop所有的核心组件汇总
Hadoop HDFS 分布式文件系统
NameNode 管理元数据(fsimage) 文件属性,节点属性,文件在哪些节点
DataNode 存储数据 文件块,block 128M 心跳(状态,资源信息)
SecondaryNameNode (合并元数据信息,fsimage--->NameNode)
Hadoop MapReduce 分布式计算系统
JobTracker 作业的管理和调度、资源分配
TaskTracker 作业的具体执行,发送心跳机制JobTracker汇报
MapTask Mapper.map() 执行用户自定的map函数
ReduceTask Reduce.reduce() 执行用户自定义的reduce函数
Hadoop Yarn 分布式资源管理系统
ResourceManager 资源调度,管理集群中所有的物理机(内存、计算资源)
NodeManager 当前物理机上的管理者,用来创建具体执行任务进程。
3、Hadoop基础知识
3.1、集群搭建的步骤
物理机、机架、联网 虚拟机,虚拟3台
初始化系统环境 linux CentOS 6.5
安装hadoop集群 Hadoop2.6
3.2、虚拟机安装
如何创建一个虚拟机?
1)服务名称修改
临时修改:hostname hadoop01 重启后失效
永久修改:vi /etc/sysconfig/network HOSTNAME=hadoop01 重启后生效
服务机组+部门+公司的域名
Hdp-node-01.bigdata.itcast.local
2)网卡配置
因为vm拷贝虚拟机时,会自动生成一个新的网卡,我们需要准备配置文件,并修改。
cd /etc/sysconfig/network-scripts/
cp ifcfg-eth0 ifcfg-eth1
vi ifcfg-eth1 修改device和mac
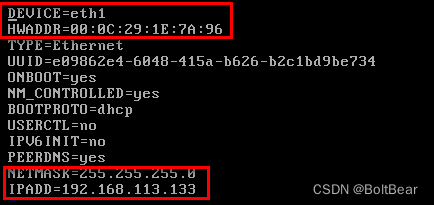
重启网卡
service network restart
DNS配置
cat /etc/resolv.conf
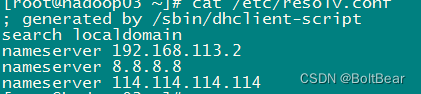
集群hosts ---用来内部通讯的

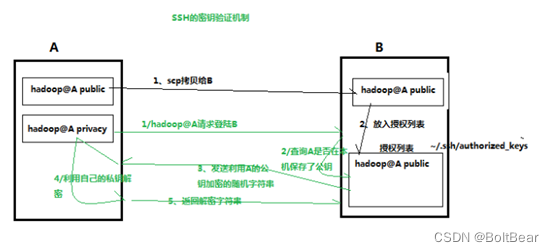
免密码登陆
ssh-keygen -t rsa
ssh-copy-id hostname
关闭防火墙和文件目录控制权限
临时关闭 service iptables stop && setenforce 0
永久关闭防火墙 chkconfig iptables off
安装环境的准备工作
编译Hadoop源码并部署Hadoop集群
新装的虚拟机,需要配置网卡
yum源配置
JDK安装
3.3、安装Hadoop
说明:在安装Hadoop之前需要安装JDK
JDK安装

步骤:
下载安装包、配置文件修改、将安装分发到其它机器、启动集群
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









