







开发环境、工具
windows10 专业版
idea2020.1.4、anaconda3、python3.11.10
机器配置
I5-1240P、16GRAM
模型名称
huggingface 的 bert-base-chinese 的模型
是一个基于Transformer架构的中文预训练模型,使用了大量的中文语料进行训练。bert-base-chinese具有12层的Transformer编码器,包含约110万个参数。它在多个中文自然语言处理任务上表现出色,如文本分类、命名实体识别和情感分析等。
代码调用示例
准备训练语料train.json
包含4种意图,每个意图有20条训练数据
[
{"text": "我要查询我的订单状态。", "label": 0},
{"text": "我想了解我的订单发货了没有。", "label": 0},
{"text": "请问我的订单现在处于什么状态?", "label": 0},
{"text": "我的订单是否已经出库?", "label": 0},
{"text": "能帮我查一下我的订单状态吗?", "label": 0},
{"text": "我想知道我的订单是否已送达。", "label": 0},
{"text": "请告诉我我的订单最新状态。", "label": 0},
{"text": "我的订单状态更新了吗?", "label": 0},
{"text": "请问我的订单是否已付款成功?", "label": 0},
{"text": "我需要查看我的订单物流信息。", "label": 0},
{"text": "能否查一下我的订单是否已经发货?", "label": 0},
{"text": "我的订单详情和状态在哪里可以查看?", "label": 0},
{"text": "请提供我的订单当前状态。", "label": 0},
{"text": "我想知道我的订单还有多久到达。", "label": 0},
{"text": "我的订单是否遇到了什么问题?", "label": 0},
{"text": "请帮我确认一下我的订单状态。", "label": 0},
{"text": "我需要查询我的订单是否已完成。", "label": 0},
{"text": "能否告诉我我的订单是否已经签收?", "label": 0},
{"text": "请问我的订单发货时间是什么时候?", "label": 0},
{"text": "我的订单是否还在处理中?", "label": 0},
{"text": "我需要知道我的订单最新动态。", "label": 0},
{"text": "我想知道你们的退货政策。", "label": 1},
{"text": "请告诉我你们的退换货流程。", "label": 1},
{"text": "你们的退货规定是怎样的?", "label": 1},
{"text": "我想了解你们的退换货政策详情。", "label": 1},
{"text": "能否说明一下你们的退货流程?", "label": 1},
{"text": "我需要知道你们关于退货的具体规定。", "label": 1},
{"text": "请问你们的退换货服务是如何运作的?", "label": 1},
{"text": "你们的退货条件是什么?", "label": 1},
{"text": "请解释一下你们的退货政策。", "label": 1},
{"text": "我对你们的退货政策有疑问,能否解答?", "label": 1},
{"text": "你们的退换货期限是多久?", "label": 1},
{"text": "我想知道退货时需要提供哪些信息。", "label": 1},
{"text": "能否告诉我退货的运费由谁承担?", "label": 1},
{"text": "你们的退货政策是否支持无理由退货?", "label": 1},
{"text": "请告诉我退货时商品需要保持什么状态。", "label": 1},
{"text": "我对你们的退换货服务不满意,怎么办?", "label": 1},
{"text": "请问退货后,退款需要多久到账?", "label": 1},
{"text": "你们的退货政策是否包括商品损坏的情况?", "label": 1},
{"text": "我想了解退货时是否需要填写特定的表格。", "label": 1},
{"text": "能否提供一份详细的退货指南?", "label": 1},
{"text": "请问你们的退货政策是否适用于所有商品?", "label": 1},
{"text": "我需要帮助解决一个问题。", "label": 2},
{"text": "我有一个问题需要你们协助解决。", "label": 2},
{"text": "请帮我解决一下我遇到的问题。", "label": 2},
{"text": "我需要你们的帮助来解决这个问题。", "label": 2},
{"text": "我碰到了一个难题,需要你们的帮助。", "label": 2},
{"text": "请问你们能帮我解决一下这个问题吗?", "label": 2},
{"text": "我需要你们的支持来解决当前的问题。", "label": 2},
{"text": "我遇到了一个需要解决的紧急情况。", "label": 2},
{"text": "请提供帮助,我需要解决这个问题。", "label": 2},
{"text": "我有一个困难,希望你们能帮我解决。", "label": 2},
{"text": "请问谁能帮我解决一下这个问题?", "label": 2},
{"text": "我遇到了一个麻烦,需要你们的协助。", "label": 2},
{"text": "请帮我解决这个让我困扰的问题。", "label": 2},
{"text": "我需要你们的帮助,这个问题让我很头疼。", "label": 2},
{"text": "我碰到了一个难题,请帮我解决一下。", "label": 2},
{"text": "我遇到了一个需要你们帮助的问题。", "label": 2},
{"text": "请问有没有办法解决我当前的问题?", "label": 2},
{"text": "我遇到了一个棘手的问题,需要你们帮忙。", "label": 2},
{"text": "我需要你们的帮助,这个问题我无法独自解决。", "label": 2},
{"text": "请伸出援手,帮我解决这个问题。", "label": 2},
{"text": "我遇到了一个难题,希望能得到你们的帮助。", "label": 2},
{"text": "我想了解你们的服务时间。", "label": 3},
{"text": "请问你们的服务时间是什么时候?", "label": 3},
{"text": "我需要知道你们的服务时间安排。", "label": 3},
{"text": "请告诉我你们的服务时间范围。", "label": 3},
{"text": "你们的服务时间具体是怎样的?", "label": 3},
{"text": "请问你们的服务时间是几点到几点?", "label": 3},
{"text": "我想了解你们每天的服务时间。", "label": 3},
{"text": "能否告诉我你们的服务时间是什么时候开始和结束的?", "label": 3},
{"text": "我对你们的服务时间很感兴趣,请告诉我。", "label": 3},
{"text": "请问你们周末是否提供服务?服务时间是什么时候?", "label": 3},
{"text": "我需要知道你们的工作时间,以便安排我的事情。", "label": 3},
{"text": "你们的服务时间是全天候的吗?", "label": 3},
{"text": "请告诉我你们的服务时间是否包括晚上?", "label": 3},
{"text": "我对你们的服务时间有查询需求,请告知。", "label": 3},
{"text": "请问你们的服务时间是否会有所调整?", "label": 3},
{"text": "我需要确认一下你们的服务时间是否适合我。", "label": 3},
{"text": "请问你们的服务时间是否包括节假日?", "label": 3},
{"text": "请告诉我你们的服务时间是否方便我前来办理业务。", "label": 3},
{"text": "我对你们的服务时间有些疑问,能否解答一下?", "label": 3},
{"text": "请问你们的服务时间是否灵活可变?", "label": 3},
{"text": "请告诉我你们的服务时间是否覆盖了整个工作日?", "label": 3}
]训练代码 IntentTrain.py
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset, DatasetDict
import torch
# 1. 加载数据集
# 假设你有一个 JSON 文件,包含训练数据
data_files = {'train': './train.json', 'test': './test.json'}
dataset = load_dataset('json', data_files=data_files)
# 2. 预处理数据
tokenizer = BertTokenizer.from_pretrained('D:\\work\program\\pytorch_models\\bert-base-chinese')
def preprocess_function(examples):
return tokenizer(examples['text'], truncation=True, padding=True, max_length=128)
encoded_dataset = dataset.map(preprocess_function, batched=True)
# 3. 定义模型
num_labels = len(set(dataset['train']['label'])) # 假设标签列名为 'label'
model = BertForSequenceClassification.from_pretrained('D:\\work\program\\pytorch_models\\bert-base-chinese', num_labels=num_labels)
# 4. 定义训练参数
training_args = TrainingArguments(
output_dir='./results',
evaluation_strategy='epoch',
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
# 5. 定义 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=encoded_dataset['train'],
eval_dataset=encoded_dataset['test'],
)
# 6. 训练模型
trainer.train()
# 7. 评估模型
results = trainer.evaluate()
print(results)
# 保存模型和 tokenizer
model_save_path = 'D:/work/code/clark/gitee/py_llm/bert/train/eval'
model.save_pretrained(model_save_path)
tokenizer.save_pretrained(model_save_path)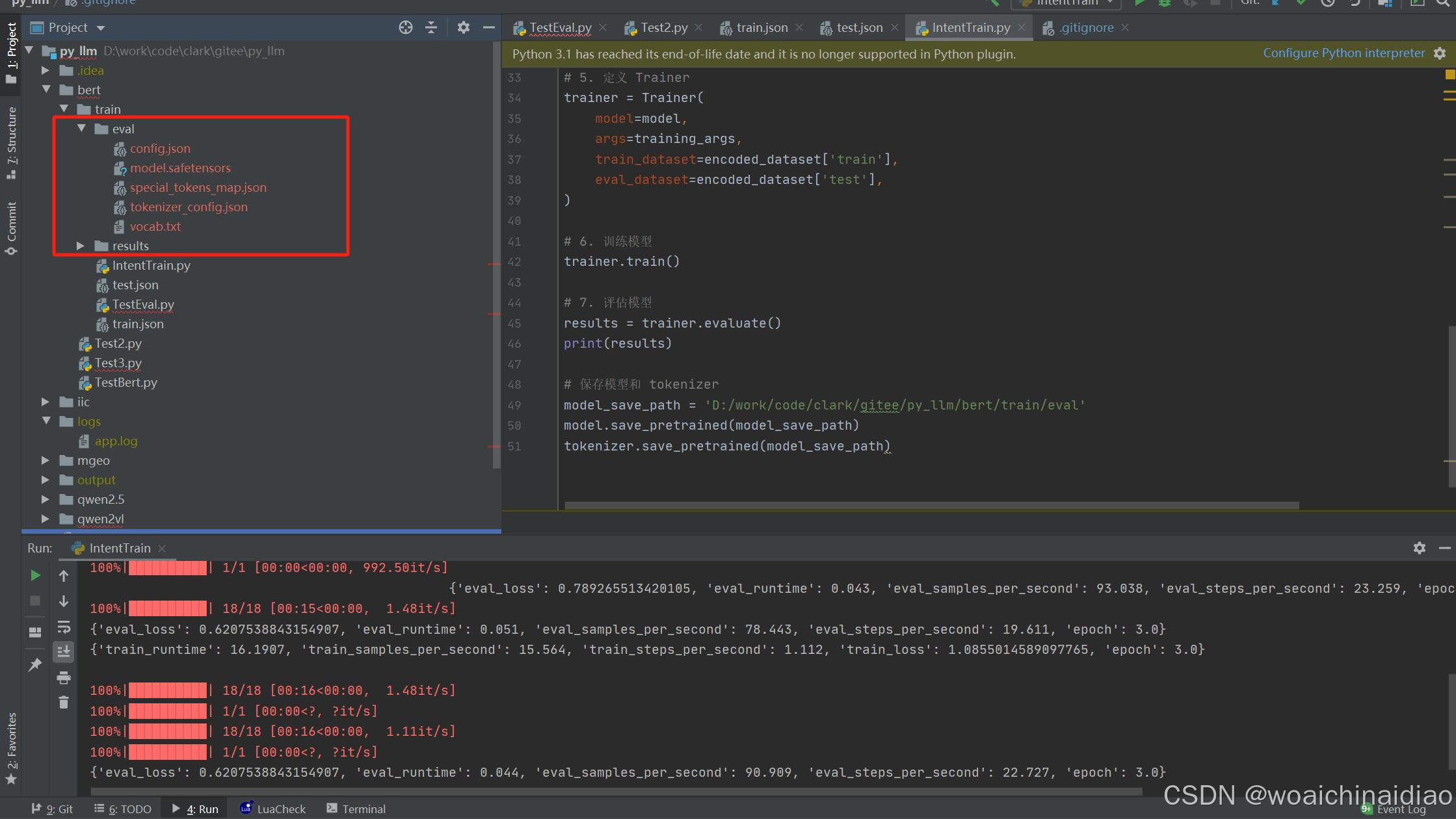 训练输出结果
训练输出结果
使用训练结果模型执行推理调用 TestEval.py
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# 指定模型和 tokenizer 的路径
model_path = 'D:\\work\\code\\clark\\gitee\\py_llm\\bert\\train\\eval' # 替换为你保存模型的实际路径
# 加载 tokenizer
tokenizer = BertTokenizer.from_pretrained(model_path)
# 加载模型
model = BertForSequenceClassification.from_pretrained(model_path)
model.eval() # 设置模型为评估模式
def preprocess_input(text):
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=128)
return inputs
def predict_intent(text):
inputs = preprocess_input(text)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probabilities = torch.softmax(logits, dim=-1)
predicted_class_id = torch.argmax(probabilities, dim=-1).item()
return predicted_class_id, probabilities
# 假设你有标签的映射关系
label_mapping = {0: "查询订单状态", 1: "了解退货政策", 2: "寻求帮助", 3: "了解服务时间"}
# 输入文本
input_text = "查下我的订单状态"
# 进行推理
predicted_class_id, probabilities = predict_intent(input_text)
# 解析输出结果
predicted_label = label_mapping[predicted_class_id]
confidence = probabilities[0][predicted_class_id].item()
print(f"Predicted Intent: {predicted_label}")
print(f"Confidence: {confidence:.4f}")输出结果
Predicted Intent: 查询订单状态
Confidence: 0.4380
总结:百万级参数的bert模型在训练与推理成本、性能方面和大模型相比优势明显。
来个好看的配图

工程代码
https://gitee.com/clark2020/py_llm.git
欢迎交流讨论


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









