







一、多任务概念
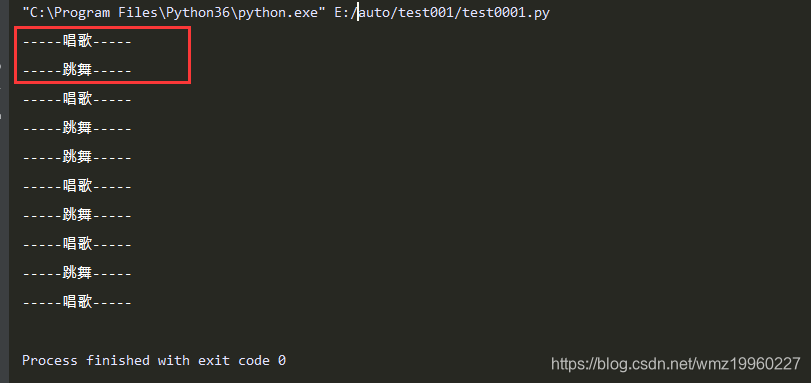
1、示例:
import time
import threading
def sing():
for i in range(0,5):
print("-----唱歌-----")
time.sleep(1)
def dance():
for i in range(0,5):
print("-----跳舞-----")
time.sleep(1)
def main():
t1=threading.Thread(target=sing)
t2=threading.Thread(target=dance)
t1.start() # 启动线程,让线程开始执行
t2.start()
if __name__=="__main__":
main()
2、概念:
- 同一时刻有多个任务在执行,同一时刻,一个核心的CPU只能执行一个任务(单核CPU可以同时执行多个任务,是因为任务之间切换的速度快,即时间片轮转)
- 并行:CPU核心数>任务数
- 并发:CPU核心数<任务数
二、线程:
t1=threading.Thread(target=sing)
t1.start() # 启动线程,让线程开始执行
- main函数为主线程,sing为子线程,sing函数运行结束,代表子进程结束了;
- 调用Thread时,不会创建线程,仅创建了个对象,调用start()之后,才会创建线程,以及让这个线程运行起来;
- 多个线程共享全局变量(会造成资源竞争等问题)
线程间常用方法及属性:
start():启动线程
join():阻塞线程直至线程终止,然后在继续运行
isAlive = is_alive(self):用于判断线程是否运行
1.当线程未调用 start()来开启时,isAlive()会返回False
2.但线程已经执行后并结束时,isAlive()也会返回False
name:表示线程的线程名 默认是 Thread-x x是序号,由1开始,第一个创建的线程名字就是 Thread-1
setName(): 用于设置线程的名称name
getName():获取线程名称name
daemon:
当 daemon = False 时,线程不会随主线程退出而退出(默认时,就是 daemon = False)
当 daemon = True 时,当主线程结束,其他子线程就会被强制结束
setDaemon():用于设置daemon值
1、同步概念
2、互斥锁
# 创建锁
mutex=threading.Lock()
# 锁定
mutex.acquire()
# 释放
mutex.release()
- 如果这个锁之前是没有上锁的,那么acquire不会堵塞;
- 如果在调用acquire对这个锁上锁之前,它已经被其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止;
- 锁应该加的尽量少
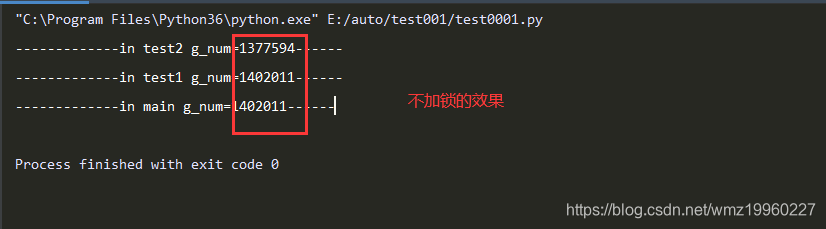
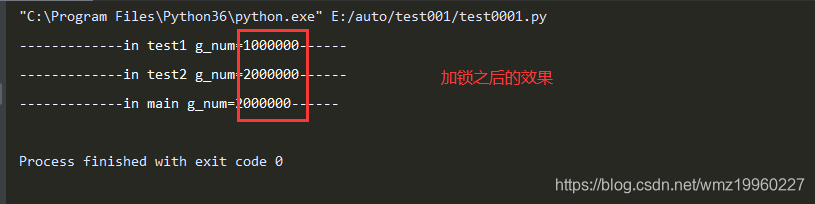
import time
import threading
g_num=0
def test1(num):
global g_num
# 上锁,如果之前没有被上锁,那么此时上锁成功;
# 如果上锁之前,已经被上锁了,那么此时会堵塞在这里,知道这个锁被解开为止
mutex.acquire()
for i in range(num):
g_num+=1
# 解锁
mutex.release()
print("-------------in test1 g_num=%d------" % g_num)
def test2(num):
global g_num
mutex.acquire()
for i in range(num):
g_num+=1
mutex.release()
print("-------------in test2 g_num=%d------" % g_num)
# 创建一个互斥锁,默认是没有上锁的
mutex=threading.Lock()
def main():
t1 = threading.Thread(target=test1,args=(1000000,))
t2 = threading.Thread(target=test2, args=(1000000,))
t1.start()
t2.start()
# 等待上边两个线程执行完
time.sleep(2)
print("-------------in main g_num=%d------" % g_num)
if __name__=="__main__":
main()
(1)死锁:
- 概念:在线程间共享多个资源的时候,如果两个线程分别占有一部分资源,并且同时等待对方的资源,就会造成死锁,一旦发生,应用就停止响应了;
- 避免死锁:添加超时时间、银行家算法
- 造成死锁的代码:
import threading
import time
class MyThread1(threading.Thread):
def run(self):
# 对mutexA进行上锁
mutexA.acquire()
# mutexA上锁后,延时1秒,等待另外那个线程,把mutexB上锁
print(self.name+"----------------doc1------up----------")
time.sleep(1)
# 此时会造成阻塞,因为这个mutexB已经被另外的线程抢先上锁了
mutexB.acquire()
print(self.name+"----------------doc1------down----------")
mutexB.release()
# 对mutexA进行释放
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
# 对mutexA进行上锁
mutexB.acquire()
# mutexA上锁后,延时1秒,等待另外那个线程,把mutexB上锁
print(self.name + "----------------doc2------up----------")
time.sleep(1)
# 此时会造成阻塞,因为这个mutexB已经被另外的线程抢先上锁了
mutexA.acquire()
print(self.name + "----------------doc2------down----------")
mutexA.release()
# 对mutexA进行释放
mutexB.release()
mutexA=threading.Lock()
mutexB=threading.Lock()
(2)银行家算法:
- 原理:操作系统按照银行家制定的规则为进程分配资源,当进程首次申请资源时,要测试该进程对资源的最大需求量,如果系统现存的资源可以满足它的最大需求量则按当前的申请量分配资源,否则就推迟分配。当进程在执行中继续申请资源时,先测试该进程本次申请的资源数是否超过了该资源所剩余的总量。若超过则拒绝分配资源,若能满足则按当前的申请量分配资源,否则也要推迟分配。
二、进程
- 程序:例如xxx.py这是个程序,是一个静态的;
- 进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元,不仅可以通过线程完成多任务,进程也是可以的。
1、进程的状态:
新建->就绪->运行->等待->死亡
- 就绪态:运行的条件都已经满足,正在等待CPU执行;
- 执行态:CPU正在执行其功能;
- 等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待状态;
进程常用的方法:
start():启动子进程
join:主进程等待当前子进程执行结束后再执行后面的代码
terminate():立即销毁子进程
multiprocessing.current_process():查看当前进程
current_process.pid, os.getpid():查看当前进程编号
os.getppid:查看父进程编号
os.kill(os.getpid(), 9):根据进程编号杀死进程
2、进程间通信:
- 进程之间有时候需要通信,操作系统提供了很多机制来实现进程间的通信
(1)Queue的使用:
-
可以使用multiprocessing模块的Queue来实现多进程之间的数据传递,Queue本身是一个消息队列程序。
-
队列:先进先出
(2)队列的常用方法:
Queue.Queue(maxsize=0) FIFO, 如果maxsize小于1就表示队列长度无限
Queue.LifoQueue(maxsize=0) LIFO, 如果maxsize小于1就表示队列长度无限
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 读队列,timeout等待时间
Queue.put(item, [block[, timeout]]) 写队列,timeout等待时间
Queue.queue.clear() 清空队列
Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
Queue.join() 实际上意味着等到队列为空,再执行别的操作
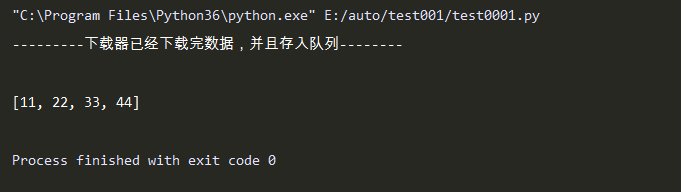
(3)使用对列实现从网上下载数据:
import multiprocessing
def download_from_web(q):
"""下载数据"""
# 模拟从网上下载数据
data=[11,22,33,44]
for temp in data:
q.put(temp)
print("---------下载器已经下载完数据,并且存入队列--------")
print()
def analysis_data(q):
"""数据处理"""
# 从队列中获取数据
waitting_analysis_data=list()
while True:
data=q.get()
waitting_analysis_data.append(data)
if q.empty():
break
print(waitting_analysis_data)
def main():
# 创建一个队列
q=multiprocessing.Queue()
# 创建多个进程,将队列的引用当做实参进行传递到队列里边
p1=multiprocessing.Process(target=download_from_web,args=(q,))
p2=multiprocessing.Process(target=analysis_data,args=(q,))
p1.start()
p2.start()
if __name__=="__main__":
main()
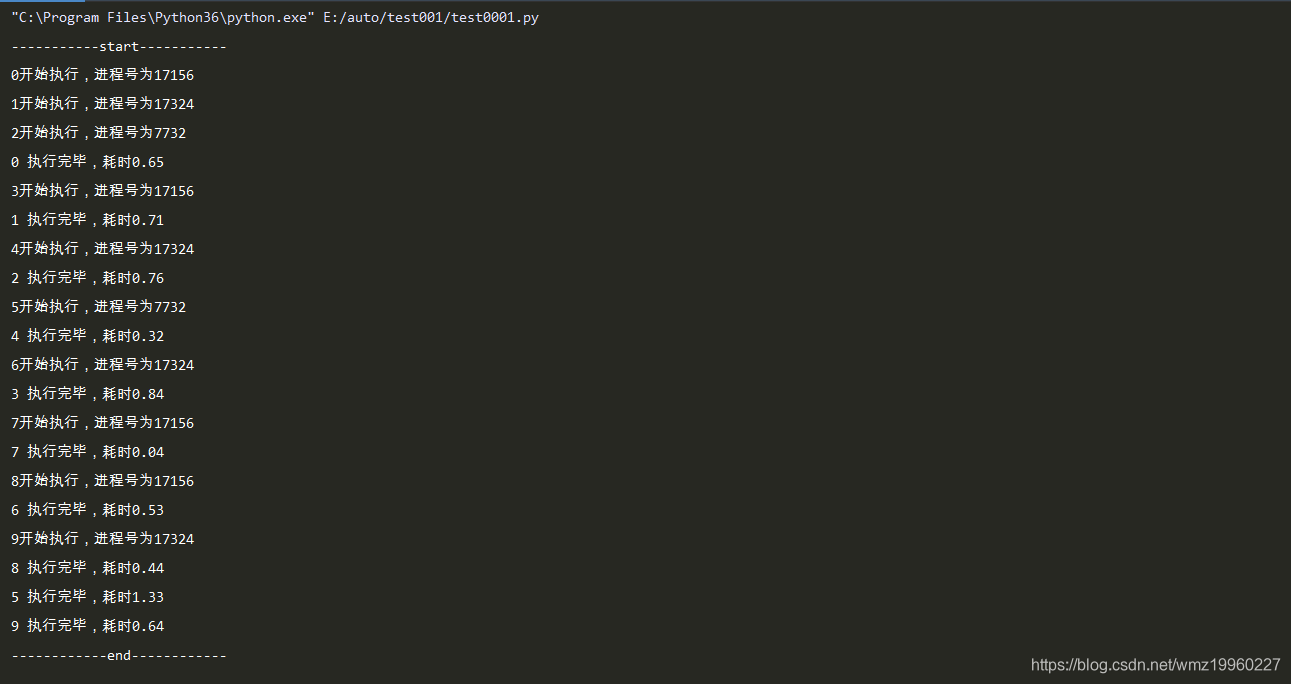
运行结果:
3、进程池Pool:
- 当需要创建的子进程不多时,可以直接利用multiprocessing中的Process董涛生成多个进程,但如果是上百甚至上千目标,手动的创建进程的工作量巨大,此时就可以用multiprocessing模块提供的Pool方法。
- 初始化Pool的时候,可以指定一个最大进程数,当有新的请求提交到Pool时,如果池还没有满,那么就会创建一个新的进程用来执行该请求,但如果池中的进程数已经达到了最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务:
模拟进程池操作:
from multiprocessing import Pool
import os,time,random
def worker(msg):
t_start=time.time()
print("%s开始执行,进程号为%d"%(msg,os.getpid()))
# random.random()随机生成0-1之间的浮点数
time.sleep(random.random()*2)
t_stop=time.time()
print(msg,"执行完毕,耗时%0.2f"%(t_stop-t_start))
if __name__ == '__main__':
po=Pool(3) # 定义一个进程池,最大进程数3
for i in range(0,10):
# Pool.apply_async(要调用的目标,(传递给参数的目标元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,))
print("-----------start-----------")
po.close() # 关闭进程池,关闭后po不会再接收新的请求
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("------------end------------")
运行结果:
三、协程
1、迭代器:
- 迭代是访问集合元素的一种方式,迭代器是一个可以记住遍历的位置的对象,迭代器对象从集合的第一个元素开始访问,知道所有的元素被访问完结束,迭代器只能往前不会后退;
- 如果想要一个对象成为一个可以迭代的对象,即可以使用for ,那么必须实现__iter__方法
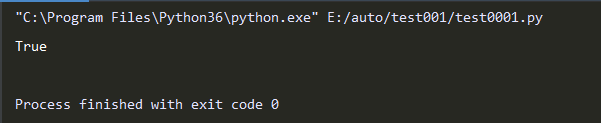
(1)判断对象是否是可迭代对象
from collections import Iterable
# 只要对象属于Iterable 的实例对象,就属于迭代类型
print(isinstance([11,22,33],Iterable))
# isinstance(object, classinfo),object -- 实例对象;classinfo -- 可以是直接或间接类名、基本类型或者由它们组成的元组。来判断一个对象是否是一个已知的类型
(2)创建一个可迭代对象
- 可迭代对象取值原理:
for temp in ***_obj:
pass
1、判断***_obj是否可以迭代;
2、在第一步成立的前提下,调用iter函数,得到***_obj对象的__iter__方法的返回值;
3、__iter__方法的返回值是一个迭代器。
from collections import Iterable
from collections import Iterator
class Classmate():
def __init__(self):
self.names=list()
def add(self,name):
self.names.append(name)
def __iter__(self):
"""如果想让一个对象成为一个可以迭代的对象,必须实现__iter__方法"""
return ClassIterator(self)
class ClassIterator(object):
"""迭代器"""
def __init__(self,obj):
self.obj = obj
self.current_num = 0
def __iter__(self):
pass
def __next__(self):
"""从next中取值"""
if self.current_num<len(self.obj.names):
ret=self.obj.names[self.current_num]
self.current_num+=1
return ret
else:
raise StopIteration
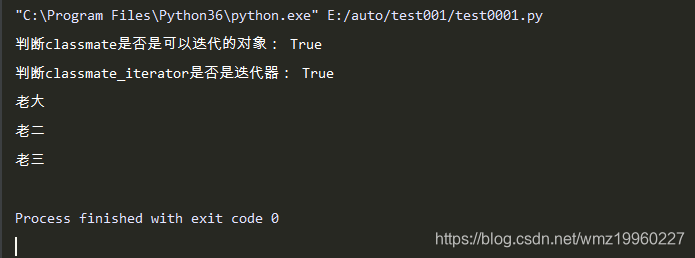
classmate=Classmate()
classmate.add("老大")
classmate.add("老二")
classmate.add("老三")
print("判断classmate是否是可以迭代的对象:",isinstance(classmate,Iterable))
classmate_iterator=iter(classmate)
print("判断classmate_iterator是否是迭代器:",isinstance(classmate_iterator,Iterator))
for temp in classmate:
print(temp)
(3)迭代器的应用
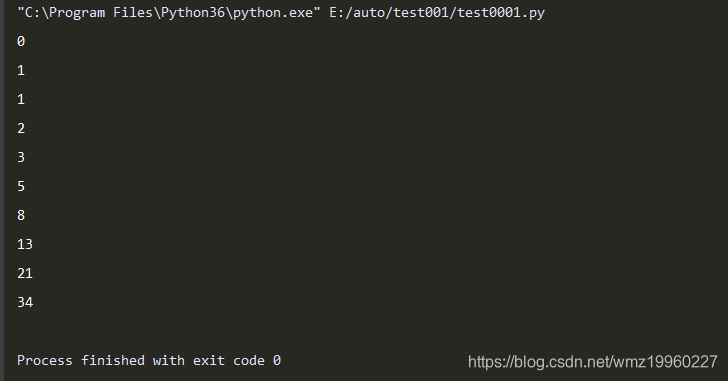
- 斐波那契数列迭代器
- 数列中第一个数字是0,第二个数是1,其后的每一个数都可由前两个数相加得到:0,1,1,2,3,5,8,13,21,34… …
class Fibonacci():
def __init__(self,all_num):
self.all_num=all_num
self.current_num=0
self.a=0
self.b=1
def __iter__(self):
return self
def __next__(self):
if self.current_num<self.all_num:
ret=self.a
self.a,self.b=self.b,self.a+self.b
self.current_num+=1
return ret
else:
raise StopIteration
fibo=Fibonacci(10)
for num in fibo:
print(num)
- 并不是只有for循环能接收可迭代对象,list、tuple等也能接受,通过迭代器,取一个值再生成一个
li=list(Fibonacci(15))
print(li)
tp=tuple(Fibonacci(6))
print(tp)
2、生成器:
- 生成器是一种特殊的迭代器,当我们在现实中使用一个迭代器时,关于当前迭代器的状态需要我们自己记录,进而才能根据当前状态生成下一个数据,为了达到记录当前状态,并配合next()函数进行迭代使用,我们可以采用更简便的语法,即生成器。
(1)创建一个生成器
- 把列表推导式的中括号换成小括号
nums1=[x*2 for x in range(10)]
print(nums1)
print("----------------------------------------------")
nums2=(x*2 for x in range(10))
print(nums2)
print("----------------------------------------------")
for num in nums2:
print(num)
print("----------------------------------------------")
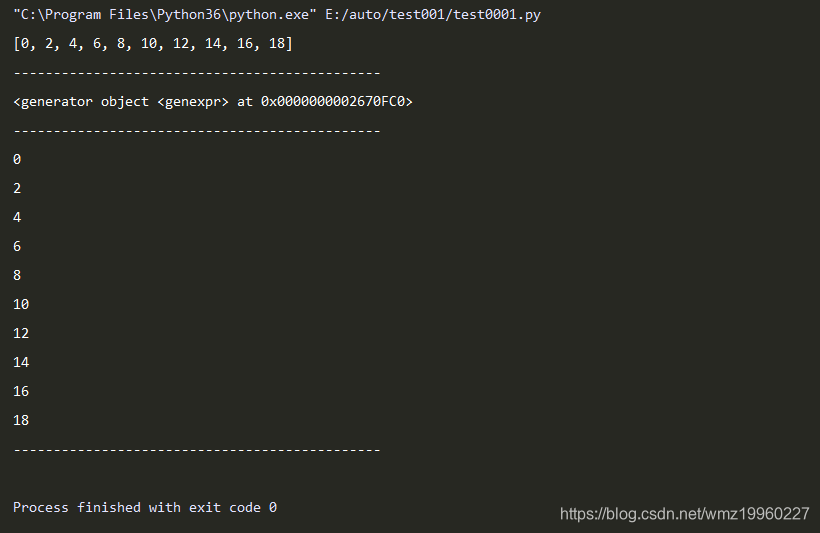
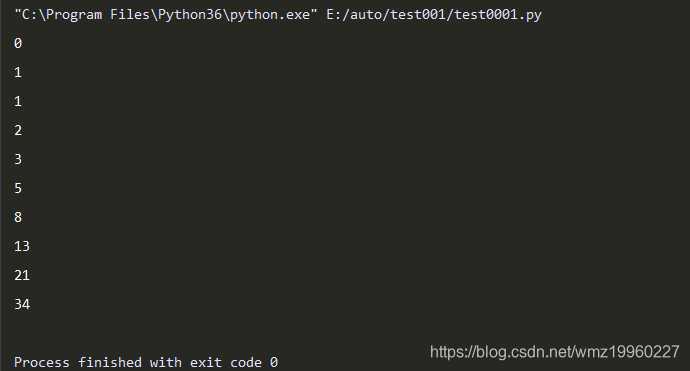
- 定义一个函数,函数中包含yield,函数自动变成生成器
def creat_num(all_num):
a, b = 0, 1
current_num=0
while current_num<all_num:
yield a # 如果一个函数中有yield语句,那么这就不再是函数,而是一个生成器模板
a, b = b, a+b
current_num+=1
# 创建一个生成器对象,可以生成多个生成器对象,相互之间不受影响
obj=creat_num(10)
for num in obj:
print(num)
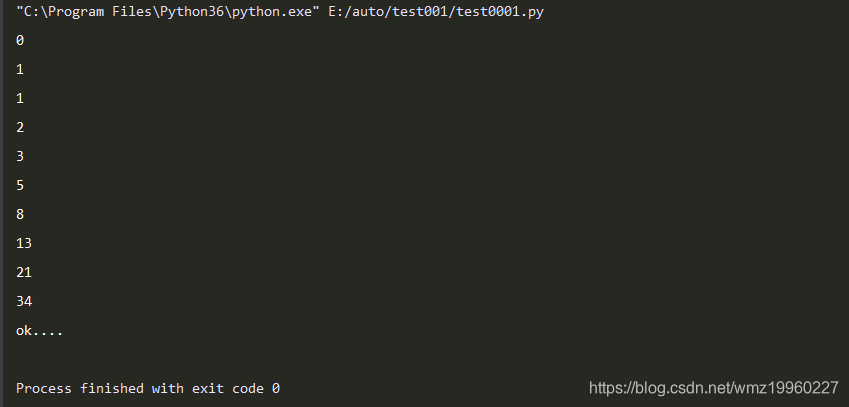
获取return的值:
def creat_num(all_num):
a, b = 0, 1
current_num=0
while current_num<all_num:
yield a # 如果一个函数中有yield语句,那么这就不再是函数,而是一个生成器模板
a, b = b, a+b
current_num+=1
return "ok...."
# 创建一个生成器对象
obj=creat_num(10)
while True:
try:
ret=next(obj)
print(ret)
except Exception as ret:
print(ret.value) # 获取return中的值
break
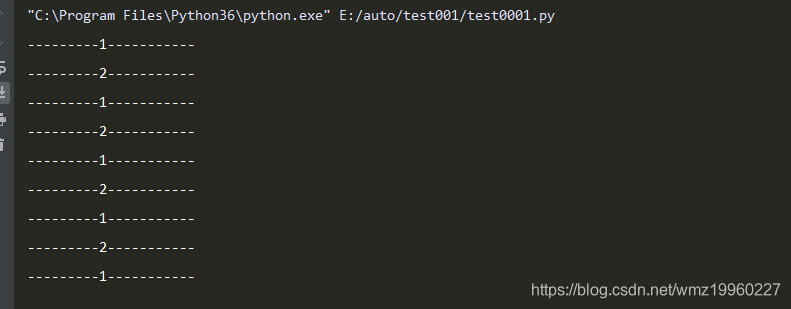
(2)用生成器生成多任务
- 切换任务时所有资源最少(并发,一个进程中的一个线程)
import time
def task_1():
while True:
print("---------1-----------")
time.sleep(1)
yield
def task_2():
while True:
print("---------2-----------")
time.sleep(1)
yield
def main():
t1=task_1()
t2=task_2()
# 先让t1运行一会儿,当t1中遇到yield时,再返回至while True,然后
# 执行t2,当他遇到yield时,再切换至t1
# 这样t1、t2交替运行,最终实现了多任务......协程
while True:
next(t1)
next(t2)
if __name__=="__main__":
main()
(3)greenlet 对多任务内容进行封装,使得切换任务边的更加简单
from greenlet import greenlet
import time
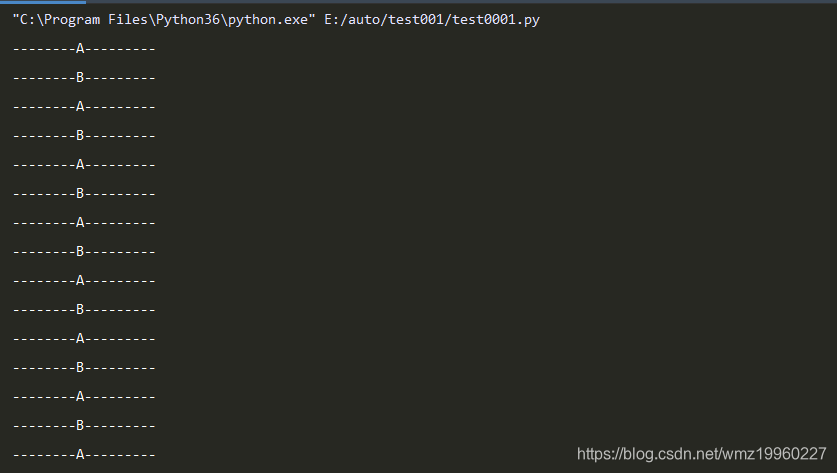
def test1():
while True:
print("--------A---------")
gr2.switch()
time.sleep(1)
def test2():
while True:
print("--------B---------")
gr1.switch()
time.sleep(1)
gr1=greenlet(test1)
gr2=greenlet(test2)
# 切换至gr1中运行
gr1.switch()
(4)gevent
- 原理:当一个greenlet遇到IO(input Output)时,比如网络、文件操作等操作时 ,比如访问网络,就自动切换至其他greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
- 由于IO操作非常耗时,经常试程序处于等待状态,有了genvent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。
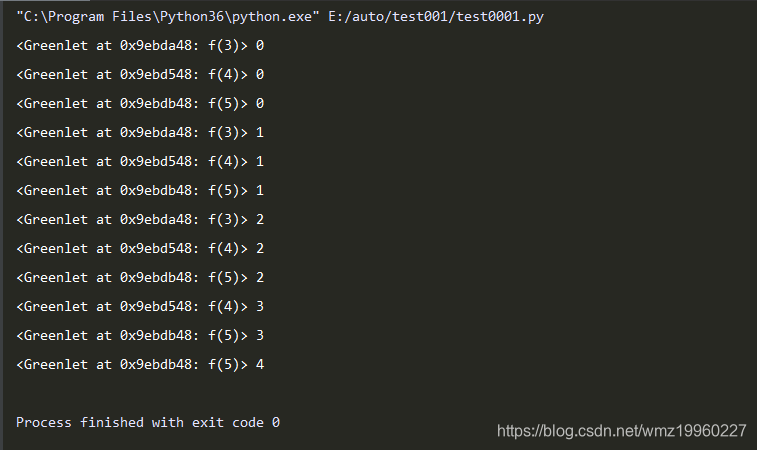
import gevent
def f(n):
for i in range(n):
print(gevent.getcurrent(),i)
# 使用gevent增加耗时
gevent.sleep(1)
# 使用spawn创建一个greenlet对象,第一个参数是方法名
g1=gevent.spawn(f,3)
g2=gevent.spawn(f,4)
g3=gevent.spawn(f,5)
# g1.join()
g1.join()
g2.join()
g3.join()
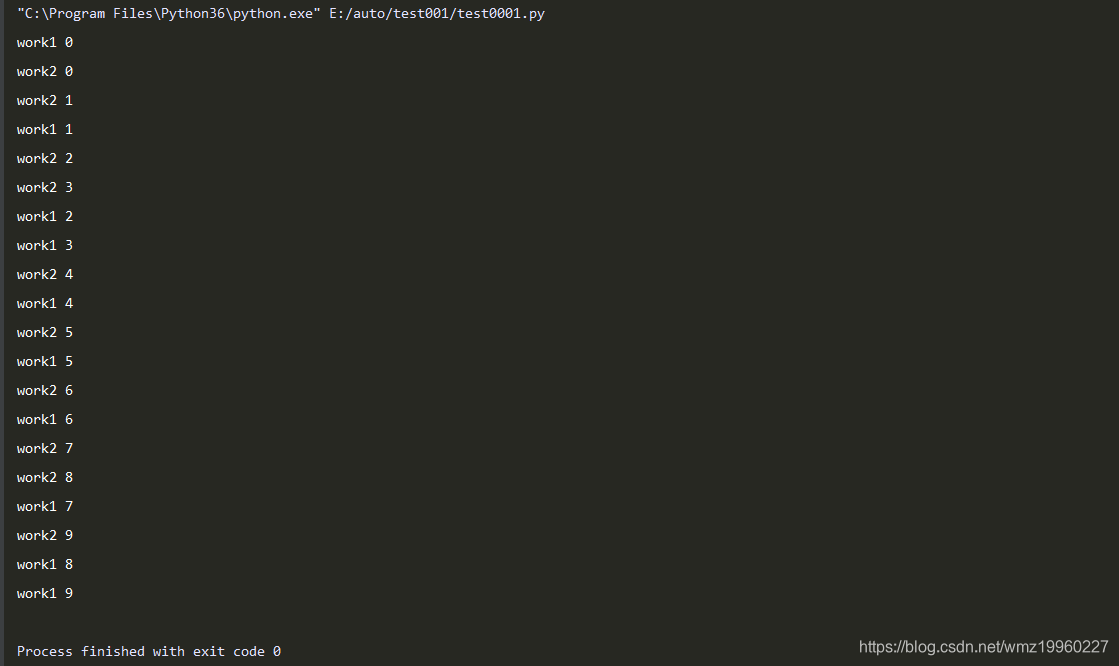
import random
import time
from gevent import monkey
import gevent
# 有耗时操作时需要,将程序中用到的耗时操作的代码,换为gevent中自己实现的模块
monkey.patch_all()
# 业务代码
def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name,i)
time.sleep(random.random())
# 将需要运行的任务加入gevent中
gevent.joinall(
[
gevent.spawn(coroutine_work,"work1"),
gevent.spawn(coroutine_work,"work2")
]
)
四、总结
- 进程是资源分配的基本单位;
- 线程是操作系统调度的基本单位;
- 进程切换需要的资源最大,效率很低;
- 协程切换需要的资源最小,效率高;
- 多进程、多线程根据CPU核数不一样可能是并行的,但是协程是在一个线程中,所以是并发。
注:从网上的视频学习到的内容,有些知识点并非原创。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









