







机器学习分为三个步骤:
- 构建函数


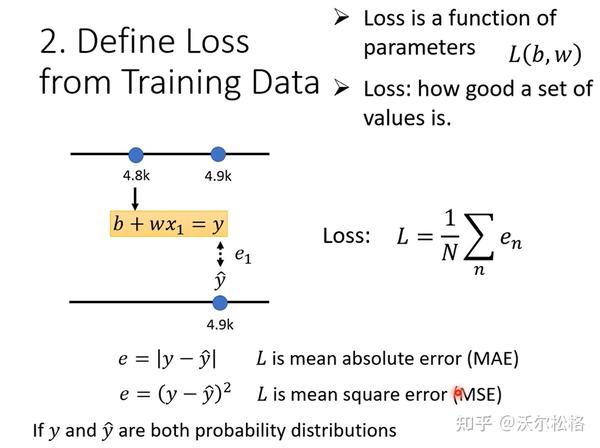
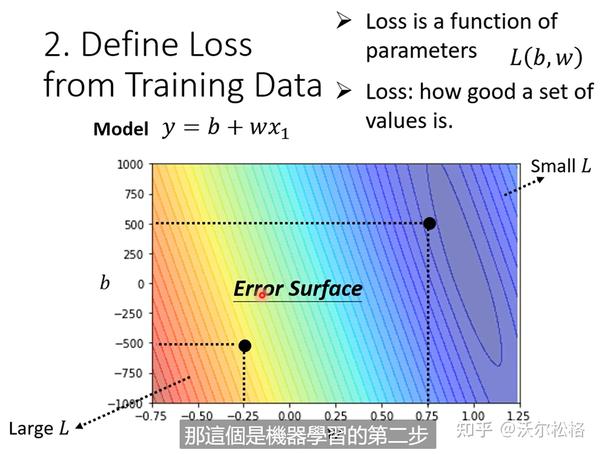
2. 定义loss(也是函数)




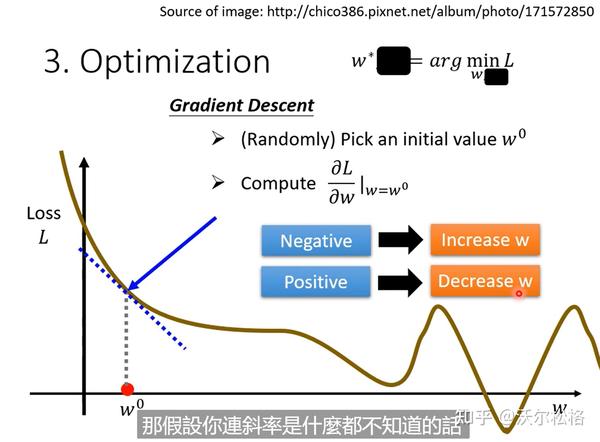
3.优化
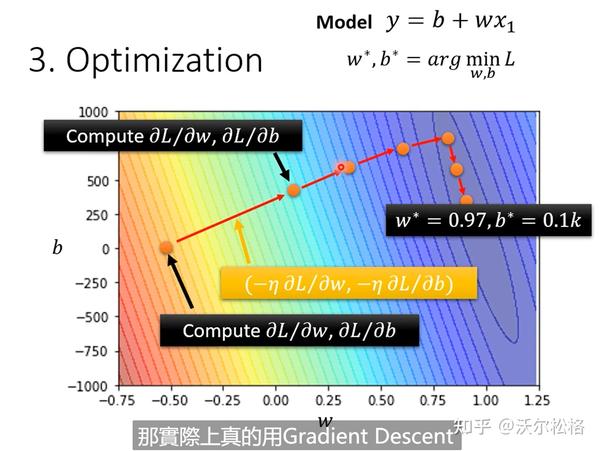
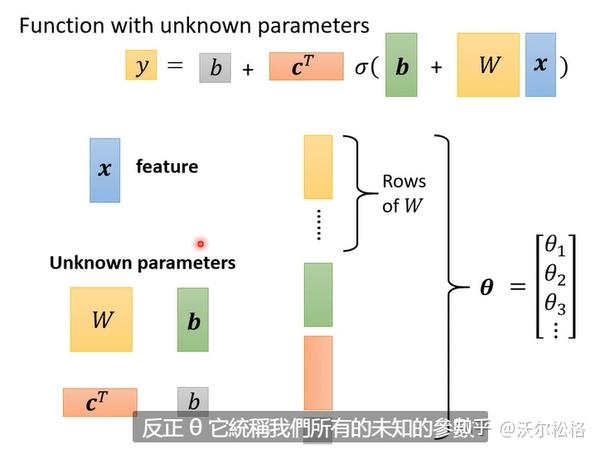
argminF(x,y) 就是指当 F(x,y) 取得最小值时,变量 x,y 的取值

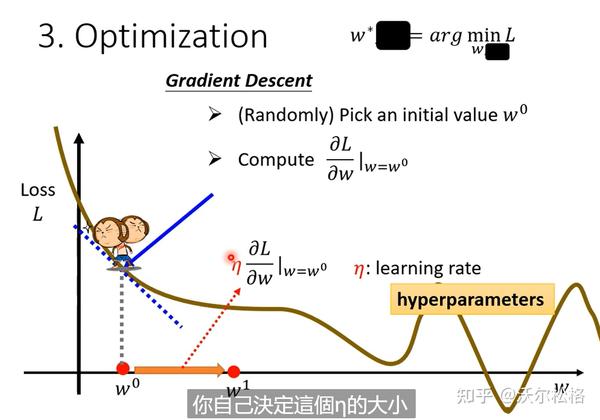

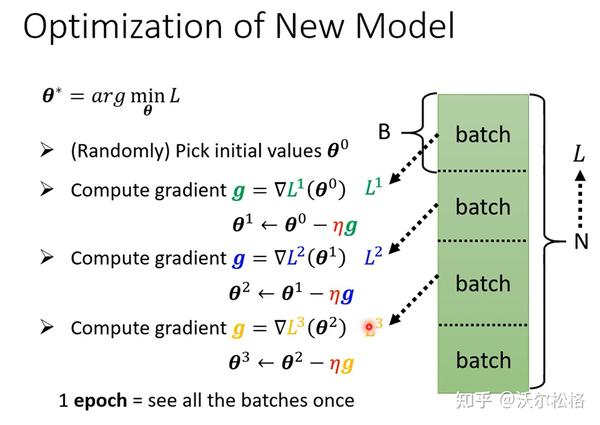
每一步的大小取决于:斜率的大小,自己设定的超参数学习率
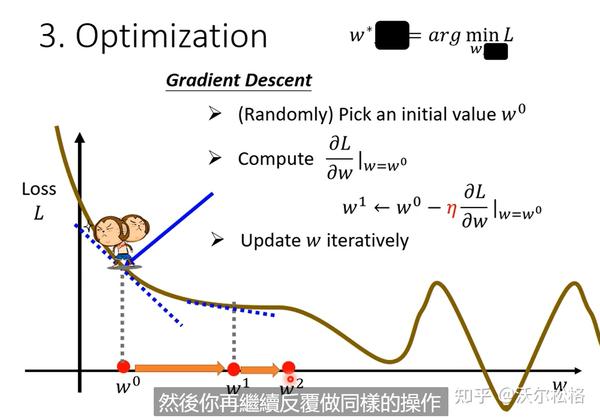

是负号才能保证,L随着w的增大而减小,此时dL/dw斜率是负的,所以w才能增大
gradient decent结束更新循环的方式:1. 达到上限自己设置的次数,2. 微分值dL/dw为0-->缺点:可能停在loss局部最小值处,而不是全局(global minimum)



分析结果:
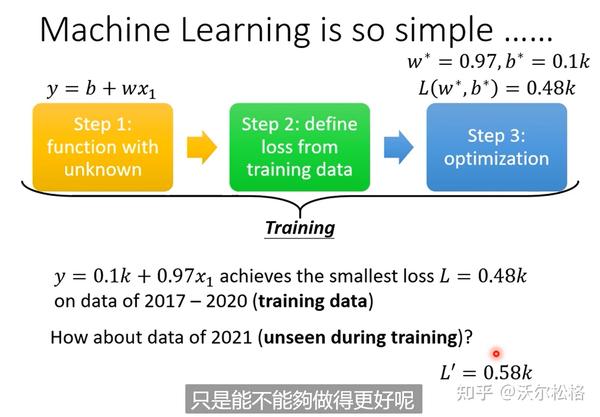

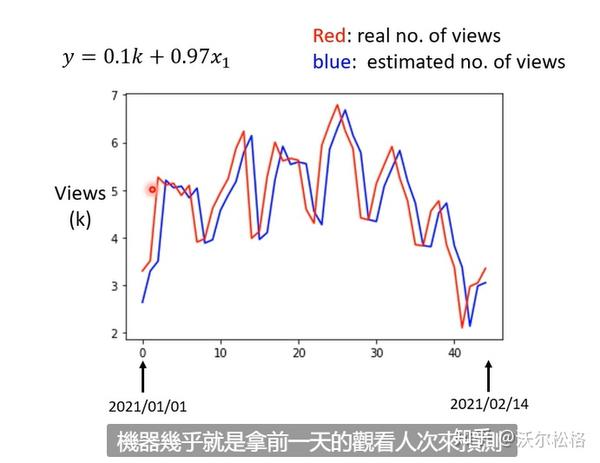

但是可以看出实际数据是有周期性的,定期会有峰谷。修改模型的时候要基于对此问题的理解:domain knowledge


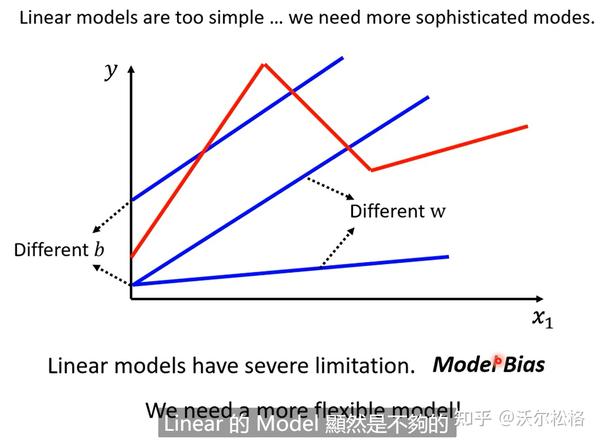
Linear model
可能x和y之间有很复杂的关系,但对linear model来说,关系就是一条直线。。

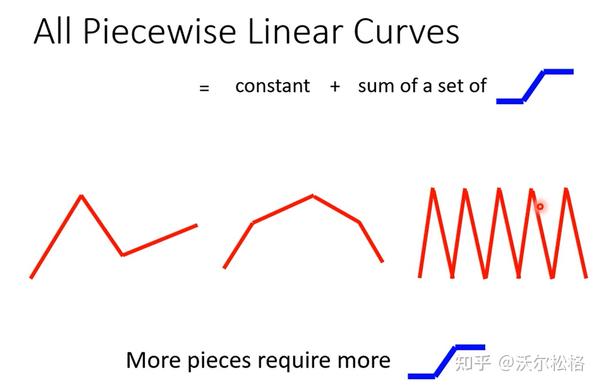

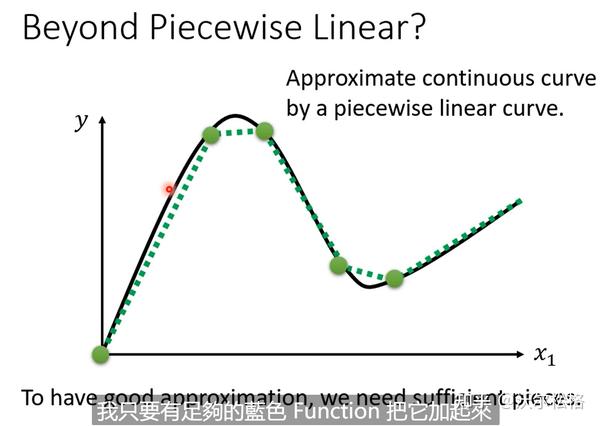

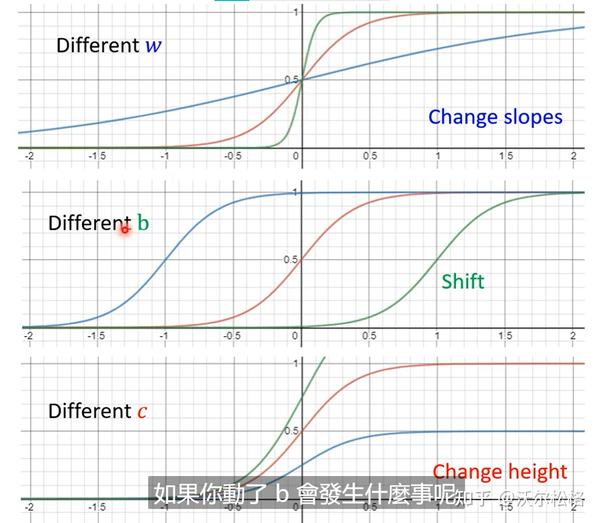
怎么获得蓝色曲线?
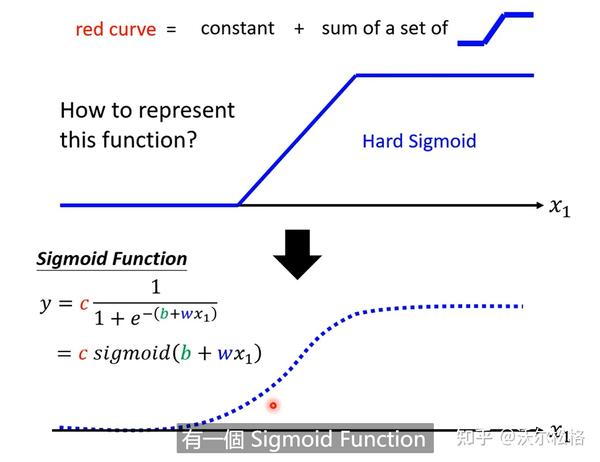

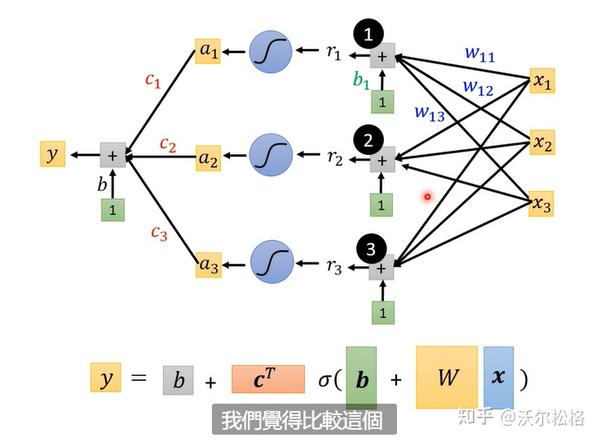
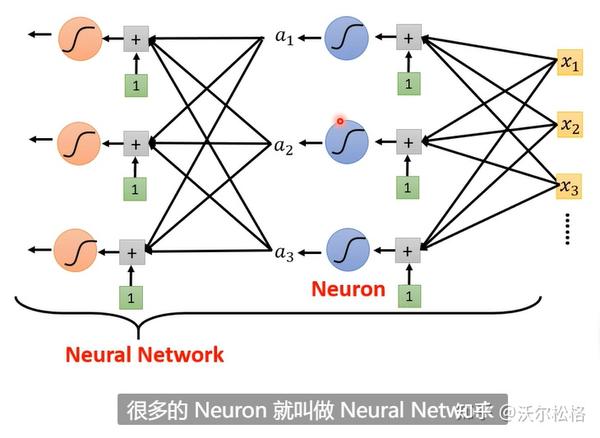
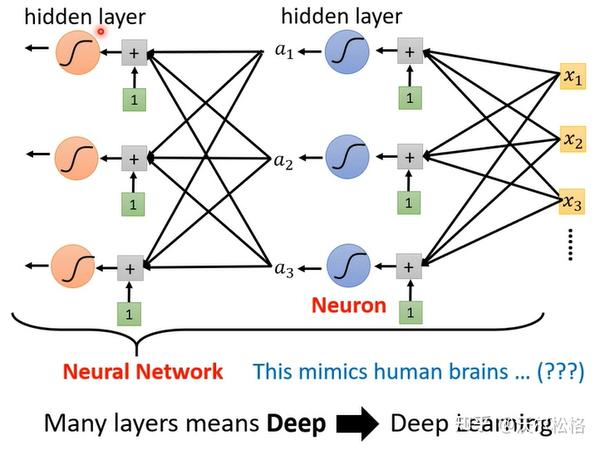
原理和正常理解是一样的,先是网络层输出y=b+wx,再加一个激活函数,z=sigmoid(y)=sigmoid(b+wx)
需要很多sigmoid逼近的时候,就会产生各种各样的sigmoid
sigmoid越多,能够逼近的越复杂(越像曲线)

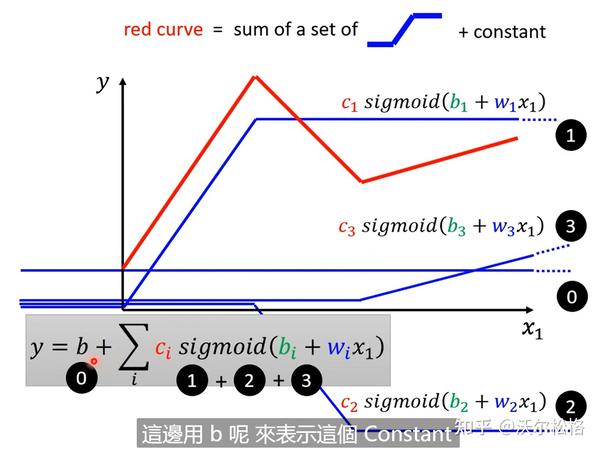
把各种sigmoid function组合在一起,就可以获得各种各样逼近于期望曲线的piecewise linear function





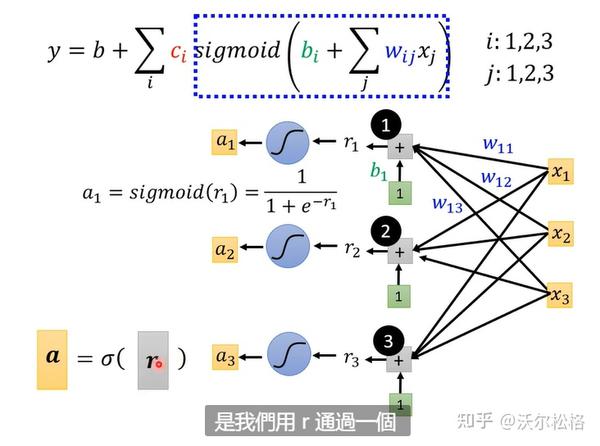

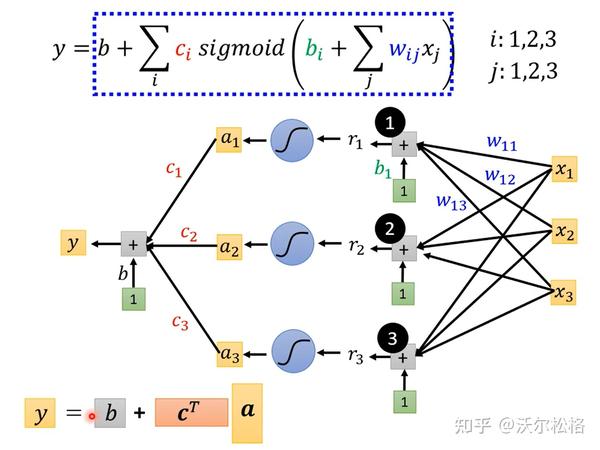






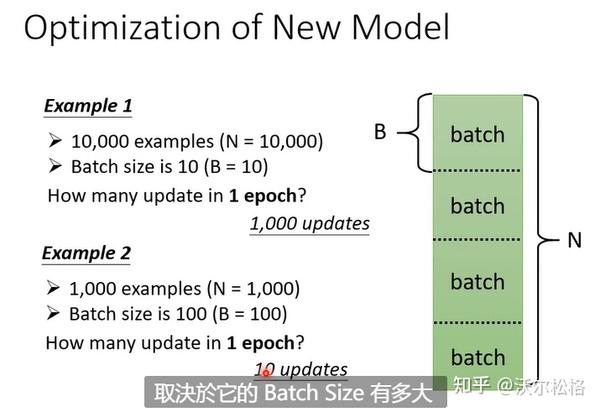
有全局梯度下降和小批量梯度下降




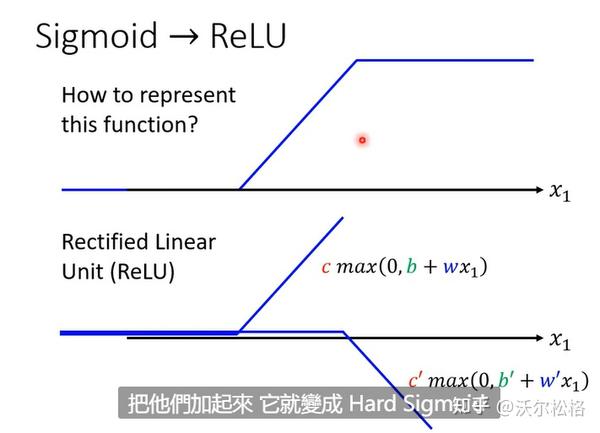
为啥Sigmoid去拼凑各种曲线(先拼出一个Hard sigmoid)?
不是必须的!两段ReLU也可以凑出Hard sigmoid









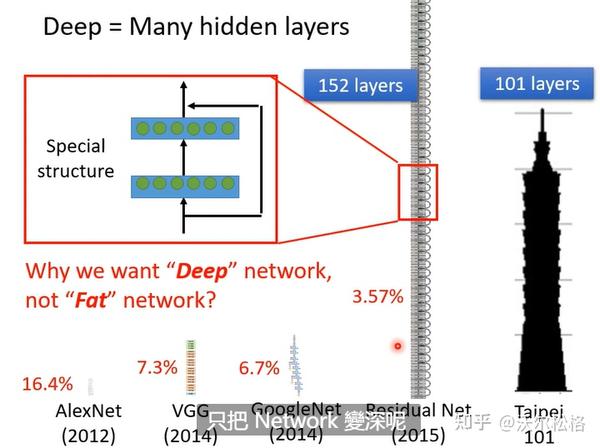



编辑于 2022-08-04 06:23
赞同
添加评论
喜欢
收藏
申请转载
分享
赞同
 分享
分享
写下你的评论...
转载自:https://zhuanlan.zhihu.com/p/549552812

















 4294
4294


 到【灌水乐园】发言
到【灌水乐园】发言








