




 本文详细介绍如何使用Python爬取有道翻译网站的内容,重点解析MD5加密过程及其实现方法,包括salt、bv和sign参数的生成。
本文详细介绍如何使用Python爬取有道翻译网站的内容,重点解析MD5加密过程及其实现方法,包括salt、bv和sign参数的生成。
python爬虫之js逆向(二)
写在前面
每天一更,养成好习惯从我做起。真正想做成一件事,不取决于你有多少热情,而是看你能多久坚持。千万别奢望光有热情就能得偿所愿。
网站分析
今天的带大家了解一下md5加密,目标网站是有道翻译:http://fanyi.youdao.com/
首先第一步打开网址(我用的是google)f12,查看是否是post请求,随便输入一个字,右击查看网页源代码,ctrl+f查看是否有你想要的结果,没有那么ok,肯定不是get请求。(可能有点片面,有错请大佬即时指出,感激不尽)。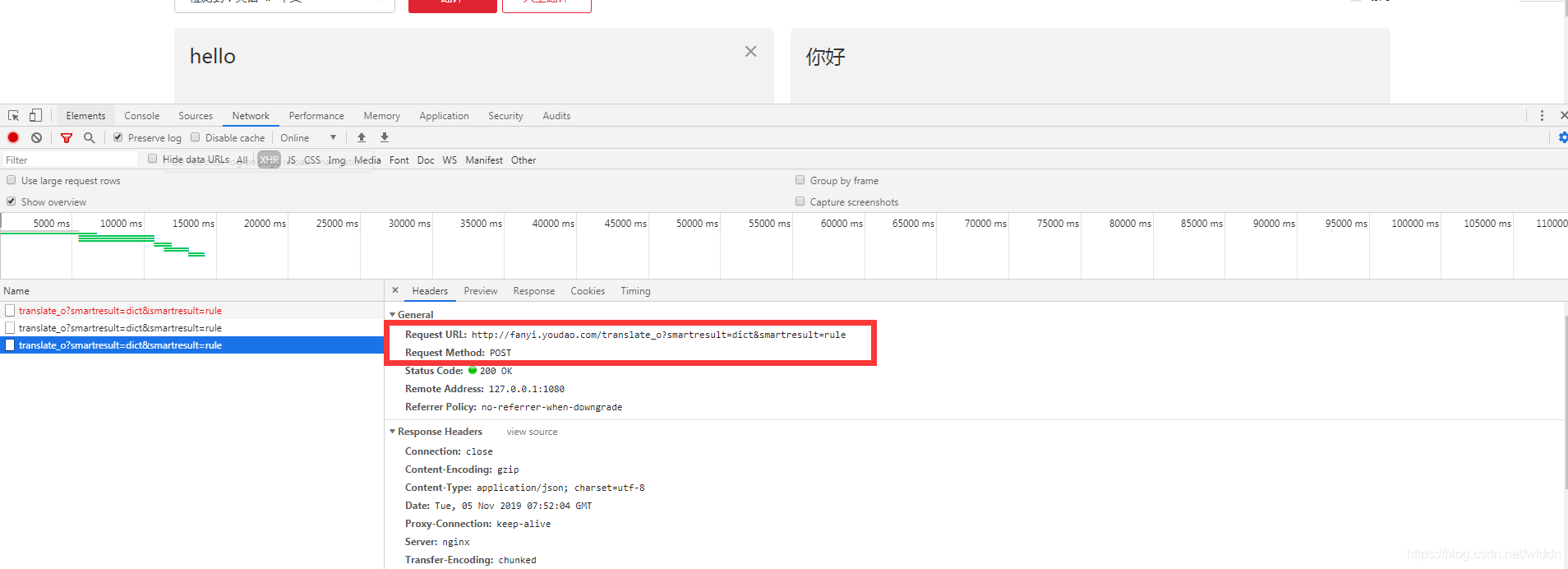
ok我们在这里可以看到请求的网址加POST请求
再接着往下看

然后这是我们所需要复制的请求头,在这可以教大家一个快速给请求头添加格式的方式,复制请求头到pycharm里,然后使用ctrl+r快捷键打开替换功能,并勾选Regex
替换源为:(.):\s(.)$
替换为:"$1": “$2”,

最后再ctrl+alt+L键,整理一下格式就行了
接下来进入正题,看好了,最最最重点的地方来喽。
看我们下面的
看Form data 的请求参数:
salt: 15729403285424
sign: 9fc6c309e0686edbbc3262034face7da
ts: 1572940328542
bv: 6ba427a653365049d202e4d218cbb811
这四个看着都是加密过来的 我们需要一个个的来看,首先全局搜索salt
在f12下全局搜索 可以按ctrl+shift+f 最下面会出现一个搜索框我们只需将salt复制进去,搜索就会出现所有包含这个单词的文件
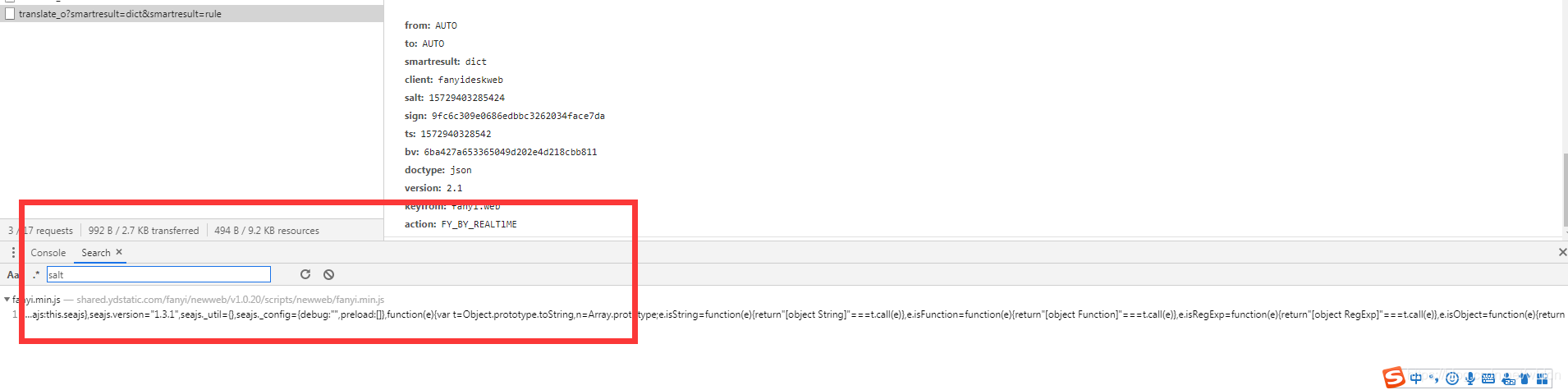
那么我们点进去看一下

ok那么我们可以清晰地看都之前的四个参数的数据都在这里
ts 是获取了当前的时间戳
bv是 MD5 加密
salt 随机数
sign是 MD5 加密

可以看到bv只是请求头的md5加密
r = “” + (new Date).getTime()
i = r + parseInt(10 * Math.random(), 10)
转成python生成就是(通过看其他大佬写的发现,之前还是将四个参数全部放上去):
i = str(time.time()*1000 + random.randint(1, 10))
接下来就是代码实现,很简单的代码:
import requests
import random
import time
import hashlib
headers={
"Cookie": "OUTFOX_SEARCH_USER_ID=760236899@61.181.7.3; P_INFO=guanjingtao1@126.com|1570869772|0|other|11&15|tij&1570868005&carddav#tij&null#10#0#0|139090&0||guanjingtao1@126.com; JSESSIONID=aaa-VPo4LHTMo-fd09q4w; OUTFOX_SEARCH_USER_ID_NCOO=772066246.9827566; ___rl__test__cookies=1572245122603",
"Referer": "http://fanyi.youdao.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
}
data = {
"i": "look",
"client": "fanyideskweb",
"keyfrom": "fanyi.web",
}
i = str(time.time()*1000 + random.randint(1, 10))
e=input("请输入单词>>")
tmp="fanyideskweb" + e + i + "n%A-rKaT5fb[Gy?;N5@Tj"
sign=hashlib.md5(tmp.encode('utf-8')).hexdigest()
data['i']=e
data['salt']=i
data['sign']=sign
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
res = requests.post(url,headers=headers, data=data)
print(res.text)
博主也是一个刚刚开始学习的小白,有错误希望大佬指导,希望大家一起学习进步。有想探讨的问题可以评论我加你。


















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











