






 本文主要讨论深度学习中遇到的问题,如如何区分local minima和saddle point,以及优化方法如Batch和Momentum。介绍了Batch Normalization的重要性,以及在训练过程中如何调整学习率。同时,对分类任务中的损失函数和训练难点进行了分析。
本文主要讨论深度学习中遇到的问题,如如何区分local minima和saddle point,以及优化方法如Batch和Momentum。介绍了Batch Normalization的重要性,以及在训练过程中如何调整学习率。同时,对分类任务中的损失函数和训练难点进行了分析。
目录
一、如何辨认梯度为0是处于local minima还是saddle point?
(如果卡在saddle point仍有路走)
1、用泰勒级数表示Loss函数形状

- 当处于critical point,一阶导数为0,即g为0,通过第一项和第三项判断是局部最大值、局部最小值还是鞍部
2、通过第三项的正负判断

3、如果是卡在saddle point

- 当特征值小于0,沿着此刻特征向量的方向更新
二、Batch和Momentum
2.1Batch
1、batch字面上是批量的意思,全部的batch构成一个epoch,在算完一个epoch后打乱重新构成新的batch组合,再接着做梯度下降更新参数

2、为什么要用小batch?
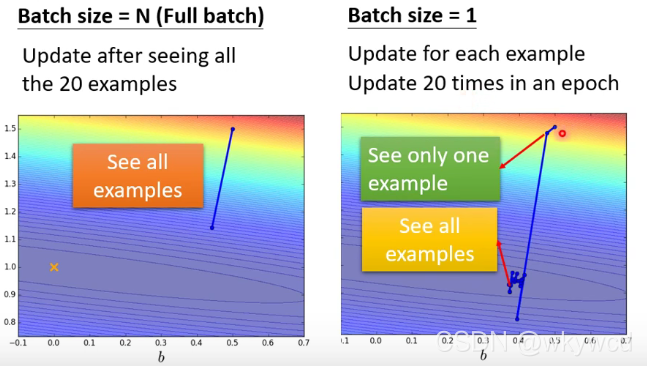
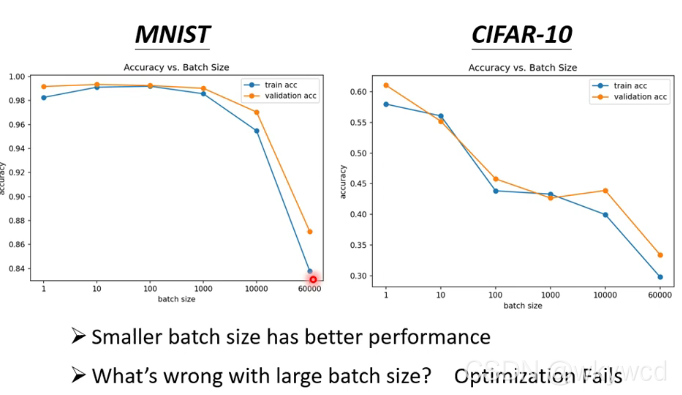
- 虽然batch size越小,越noisy,但是batch size小的准确性高,而batch size大的,系数最优化失败
为什么会这样,可能的原因: - 解释1

- 用不同的batch,模型形状类似但是不完全相同,不容易卡住
- 解释2
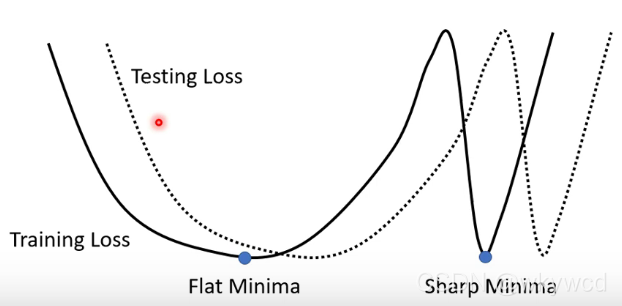
- 越平坦的minima好于峡谷中的minima,小的batch容易走出峡谷,所以小的batch较好(因为它不是顺着一个方向更新参数)
2.2 Momentum
1、在移动参数时,结合前一步移动的方向综合决定
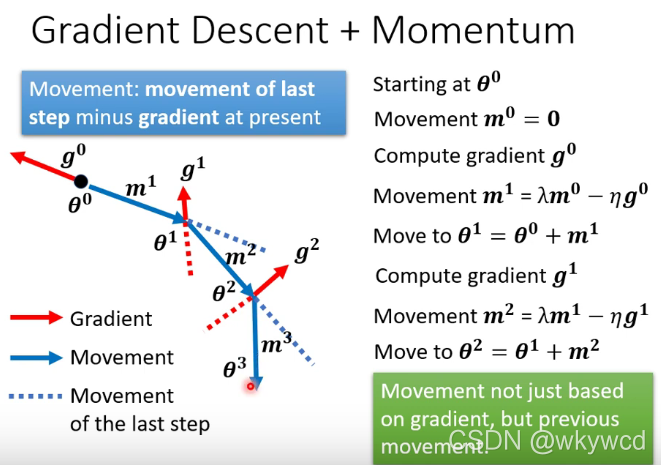
2、更新的方向考虑了过去所有的梯度

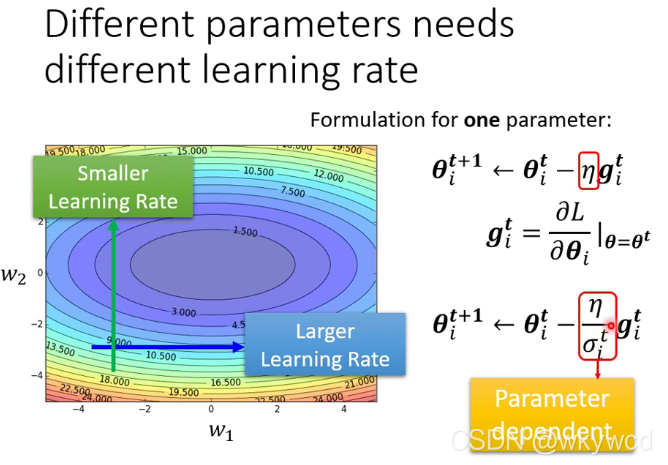
三、Adaptive learning rate
1、loss不再下降的时候,梯度不一定很小
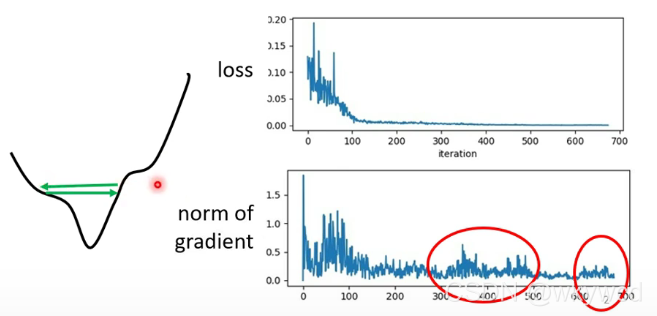
- 梯度在山谷间来回震荡,并没有卡在local minima 或saddle point
2、Adagrad
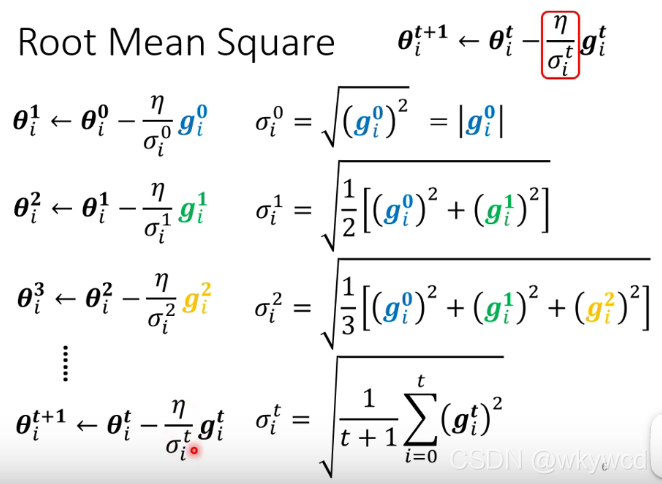
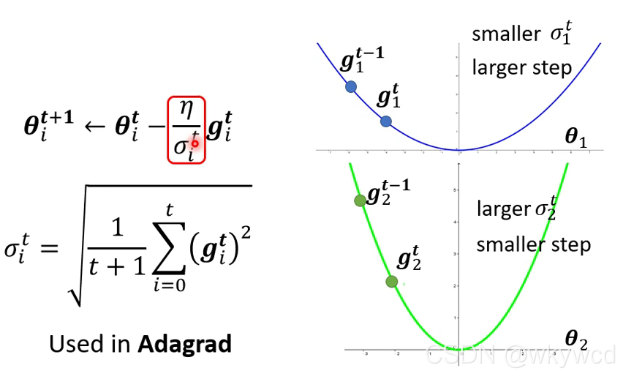
3、RMSProp
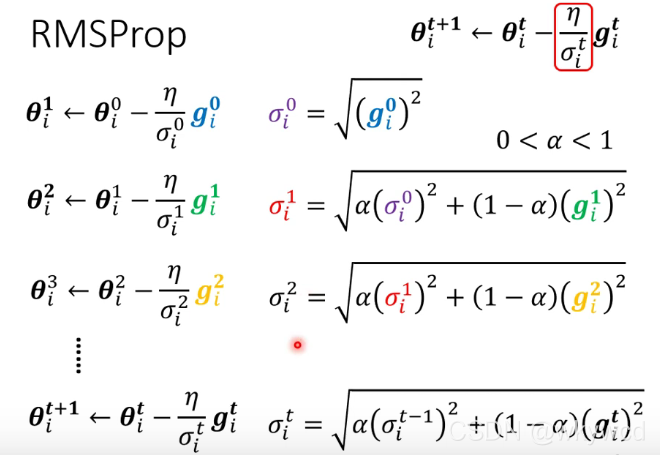
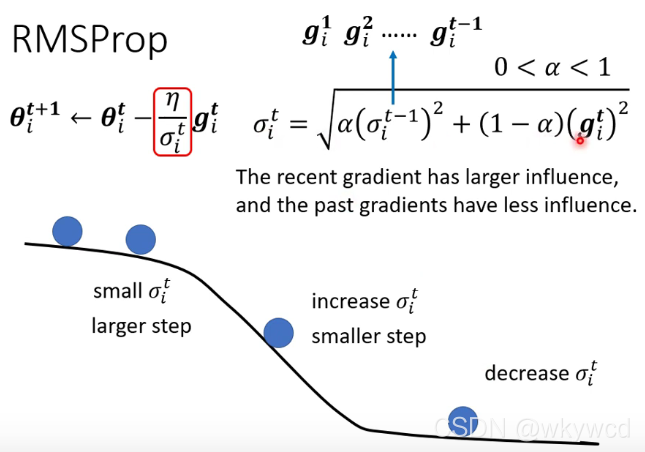
4、Adam

5、warm up - 学习率先变大后变小
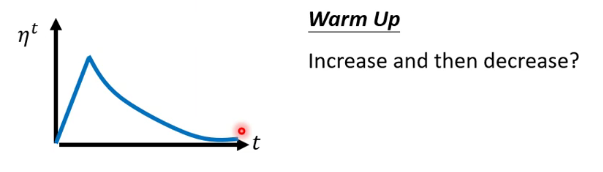
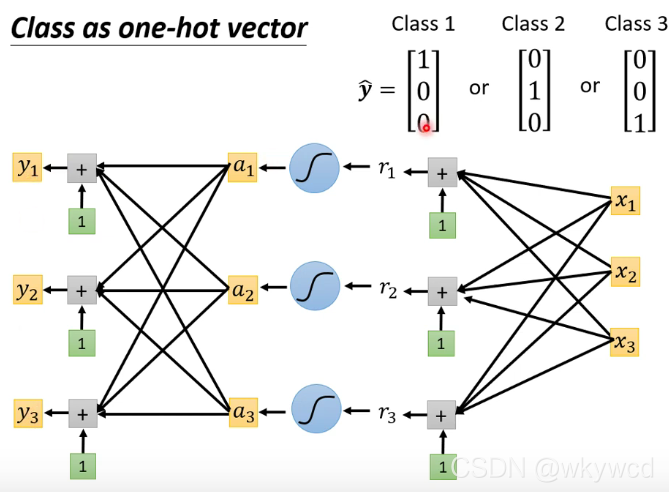
四、Classification
4.1 分类简单介绍
1、以回归的方法看待分类
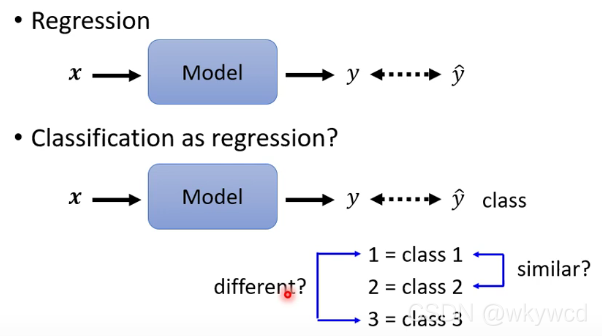
- 存在一个问题:这样得出的结果默认为1与2关系比较接近,1与3的关系较远

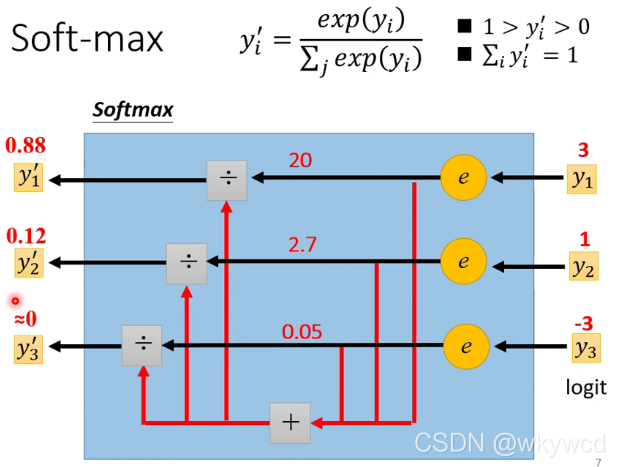
2、softmax函数的内部操作
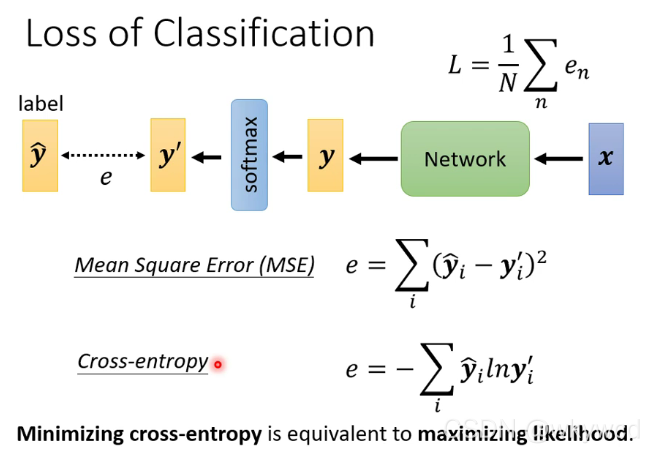
4.2 分类的损失函数
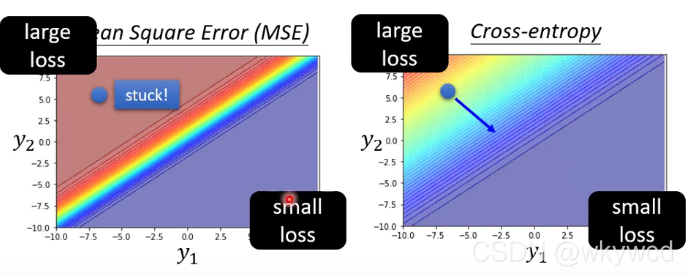
- 如果初始点在左上角,用MSE分类有很大的可能。、。性train不起来
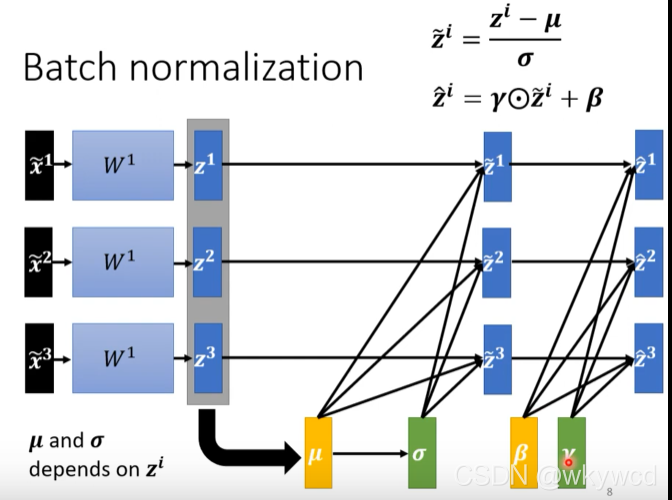
五、批次标准化(Batch Normalization)
1、两个参数的斜率不同,不好训练
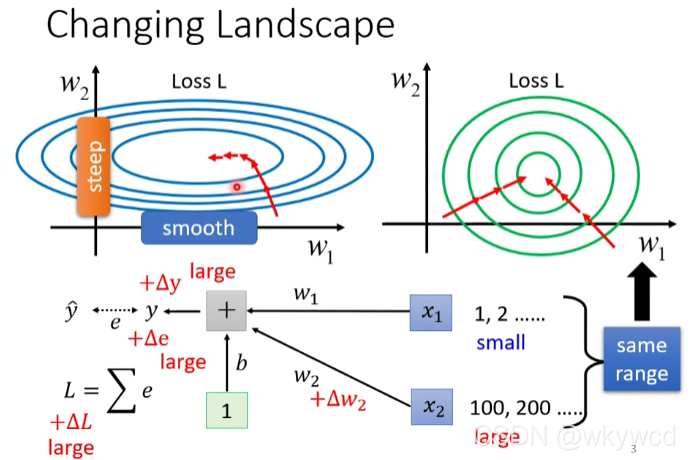
- 让不同的维度有接近的数值,能够较好的训练
5.1 特征标准化
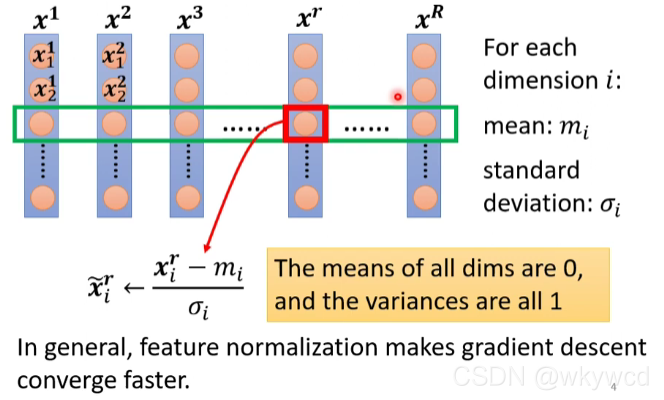
- 在深度学习中每一层都做特征标准化
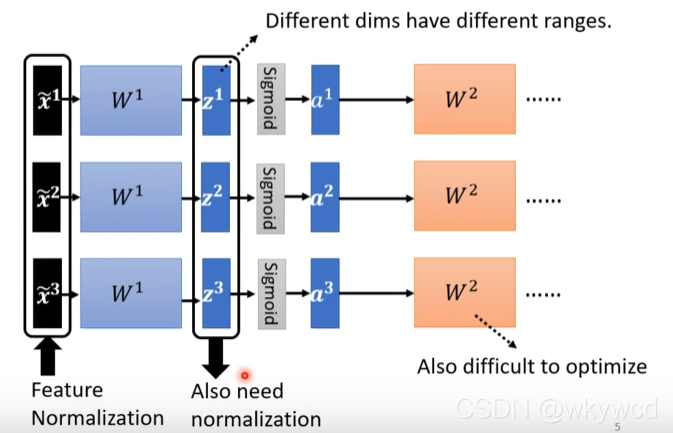
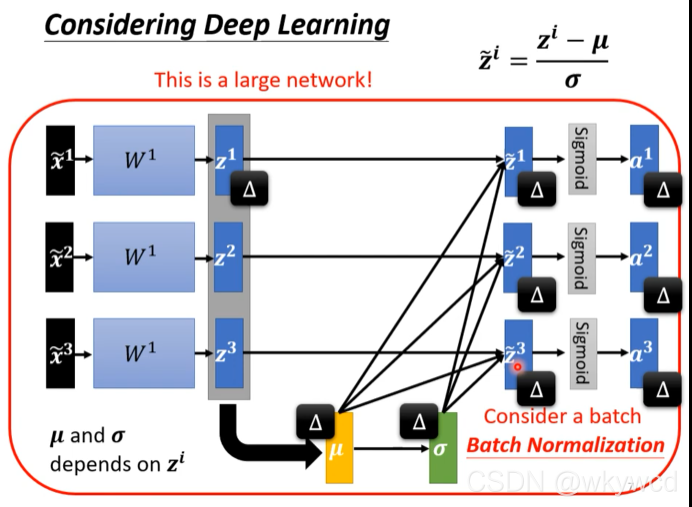
5.2 Batch normalization
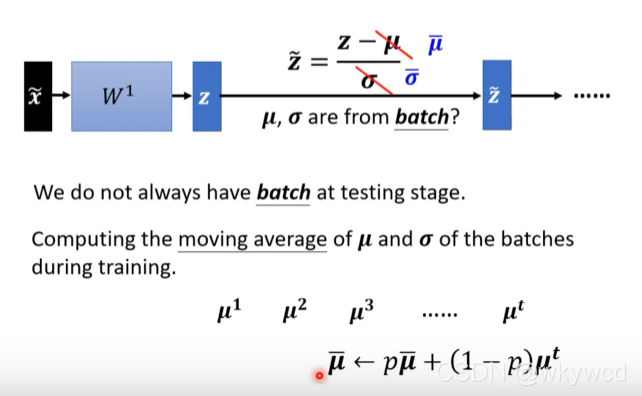
1、Batch normalization——Testing
如果没有一个Batch怎么算均值和方差呢?
- 移动平均


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









