






 这篇博客探讨了多种字符串处理问题,包括单词覆盖还原、查找字典序最大单词、家谱查询以及数字反转。涉及的算法有字符串匹配、排序和查找,并提到了在处理字符串时的注意事项,如大小写处理和数据格式约束。
这篇博客探讨了多种字符串处理问题,包括单词覆盖还原、查找字典序最大单词、家谱查询以及数字反转。涉及的算法有字符串匹配、排序和查找,并提到了在处理字符串时的注意事项,如大小写处理和数据格式约束。
T1
P1321 单词覆盖还原
题目描述
在一长串(3<=l<=255)中被反复贴有boy和girl两单词,后贴上的可能覆盖已贴上的单词(没有被覆盖的用句点表示),最终每个单词至少有一个字符没有被覆盖。问贴有几个boy几个girl?
输入输出格式
输入格式:
一行被被反复贴有boy和girl两单词的字符串。
输出格式:
两行,两个整数。第一行为boy的个数,第二行为girl的个数。
输入输出样例
输入样例#1: 复制
……boyogirlyy……girl…….输出样例#1: 复制
4
2首先boy和girl都有可能是被覆盖的,但至少有一个字符不被覆盖,那么可以通过这至少一个字符来判断
boy和girl都是连续的,那么每次从当前所在的这个字符来判断,例如Si,Si+1,Si+2对应boy,只要满足>=一个字符相等,就说明有boy
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<string>
using namespace std;
int main()
{
string s;
cin >> s;
int boy=0,girl=0;
for(int i=0;i<s.length(); i++)
{
if(s[i]=='b'||s[i+1]=='o'||s[i+2]=='y')
boy++;
if(s[i]=='g'||s[i+1]=='i'||s[i+2]=='r'||s[i+3]=='l')
girl++;
}
cout<<boy<<endl;
cout<<girl<<endl;
return 0;
}T2
P2412 查单词
题目背景
滚粗了的HansBug在收拾旧英语书,然而他发现了什么奇妙的东西。
题目描述
udp2.T3如果遇到相同的字符串,输出后面的
蒟蒻HansBug在一本英语书里面找到了一个单词表,包含N个单词(每个单词内包含大小写字母)。现在他想要找出某一段连续的单词内字典序最大的单词。
输入输出格式
输入格式:
第一行包含两个正整数N、M,分别表示单词个数和询问个数。
接下来N行每行包含一个字符串,仅包含大小写字母,长度不超过15,表示一个单词。
再接下来M行每行包含两个整数x、y,表示求从第x到第y个单词中字典序最大的单词。
输出格式:
输出包含M行,每行为一个字符串,分别依次对应前面M个询问的结果。
输入输出样例
输入样例#1: 复制
5 5
absi
hansbug
lzn
kkk
yyy
1 5
1 1
1 2
2 3
4 4输出样例#1: 复制
yyy
absi
hansbug
lzn
kkk
说明
样例说明:
第一次操作:在{absi,hansbug,lzn,kkk,yyy}中找出字典序最大的,故为yyy
第二次操作:在{absi}中找出字典序最大的,故为absi
第三次操作:在{absi,hansbug}中找出字典序最大的,故为hansbug
第四次操作:在{hansbug,lzn}中找出字典序最大的,故为lzn
第五次操作:在{kkk}中找出字典序最大的,故为kkk
数据规模:
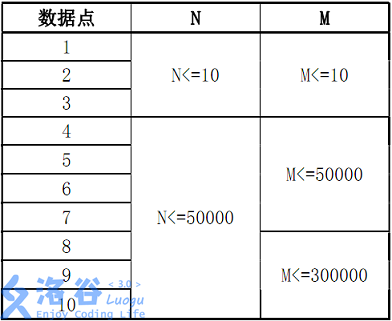
注意事项:1.该题目单词字典序比对过程中大小写不敏感,但是输出必须输出原单词
2.该题目时间限制为0.2s
本题目主要是通过对string类进行预先排序,然后查找的思路去写的题目
这道题要注意的是
1.sort()对string类的从大到小排序方法
2.本题目是对大小写字母没有要求,也就是不能直接进行排序,需要对大小写统一后进行排序
#include <iostream>
#include<string>
#include<cstdio>
#include<algorithm>
using namespace std;
struct node
{
string s;
string c;
int num;
};
node a[50005];
bool cmp(node a,node b)
{
return a.s>b.s;
}
int main()
{
int n,m;
cin >> n >> m;
string cj;
for(int i=1;i<=n;i++)
{
cin >> cj;
a[i].c=cj;
for(int k=0;k<cj.size();k++)
{
if(cj[k]>='A'&&cj[k]<='Z')
cj[k]=cj[k]+32;
}
a[i].s=cj;
a[i].num=i;
}
sort(a+1,a+1+n,cmp);
while(m--)
{
int x,y;
scanf("%d%d",&x,&y);
if(x==1&&y==n)
cout << a[1].c << endl;
else
{
for(int i=1;i<=n;i++)
{
if(a[i].num>=x&&a[i].num<=y)
{
cout<<a[i].c<<endl;
break;
}
}
}
}
return 0;
}
T3
P2814 家谱
题目背景
现代的人对于本家族血统越来越感兴趣。
题目描述
给出充足的父子关系,请你编写程序找到某个人的最早的祖先。
输入输出格式
输入格式:
输入由多行组成,首先是一系列有关父子关系的描述,其中每一组父子关系中父亲只有一行,儿子可能有若干行,用#name的形式描写一组父子关系中的父亲的名字,用+name的形式描写一组父子关系中的儿子的名字;接下来用?name的形式表示要求该人的最早的祖先;最后用单独的一个$表示文件结束。
输出格式:
按照输入文件的要求顺序,求出每一个要找祖先的人的祖先,格式:本人的名字+一个空格+祖先的名字+回车。
输入输出样例
输入样例#1: 复制
#George
+Rodney
#Arthur
+Gareth
+Walter
#Gareth
+Edward
?Edward
?Walter
?Rodney
?Arthur
$输出样例#1: 复制
Edward Arthur
Walter Arthur
Rodney George
Arthur Arthur说明
规定每个人的名字都有且只有6个字符,而且首字母大写,且没有任意两个人的名字相同。最多可能有1000组父子关系,总人数最多可能达到50000人,家谱中的记载不超过30代。
此题将并查集和字符串结合在一起
因为此题目的输入格式是一个父节点+很多个子节点
所以可以采用map将父节点和子节点一一对应起来
#include <iostream>
#include<string>
#include<algorithm>
#include<map>
using namespace std;
map<string,string> p;
string find1(string r)
{
string t;
t=r;
while(t!=p[t])
{
t=p[t];
}
return t;
}
int main()
{
string s,flag;
char a;
while(cin >> a&&a!='$')
{
cin >> s;
if(a=='#')
{
if(p[s]=="")
p[s]=s;
flag=s;
}
else if(a=='+')
{
p[s]=flag;
}
else
{
cout<<s<<" "<<find1(s)<<endl;
}
}
return 0;
}
P1553 数字反转(升级版)(https://www.luogu.org/problemnew/show/P1553)
题目描述
给定一个数,请将该数各个位上数字反转得到一个新数。
这次与NOIp2011普及组第一题不同的是:这个数可以是小数,分数,百分数,整数。整数反转是将所有数位对调;小数反转是把整数部分的数反转,再将小数部分的数反转,不交换整数部分与小数部分;分数反转是把分母的数反转,再把分子的数反转,不交换分子与分母;百分数的分子一定是整数,百分数只改变数字部分。整数新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零;小数新数的末尾不为0(除非小数部分除了0没有别的数,那么只保留1个0);分数不约分,分子和分母都不是小数(约分滴童鞋抱歉了,不能过哦。输入数据保证分母不为0),本次没有负数。
输入输出格式
输入格式:
一个数s
输出格式:
一个数,即s的反转数
输入输出样例
输入样例#1: 复制
5087462输出样例#1: 复制
2647805输入样例#2: 复制
600.084输出样例#2: 复制
6.48输入样例#3: 复制
700/27输出样例#3: 复制
7/72输入样例#4: 复制
8670%输出样例#4: 复制
768%说明
所有数据:25%s是整数,不大于20位
25%s是小数,整数部分和小数部分均不大于10位
25%s是分数,分子和分母均不大于10位
25%s是百分数,分子不大于19位
(20个数据)
#include <iostream>
#include<string>
#include<algorithm>
using namespace std;
void zero(string &w)
{
int i=10000;
for(i=w.size()-1;i>=0;i--)
{
if(i==w.size()-1)
{
if(w[i]=='0')
{
w.erase(i,1);
}
else
break;
}
else
{
if(w[i]=='0')
{
w.erase(i,1);
}
else
break;
}
}
if(i<0)
w="0";
}
int main()
{
string s;
cin >> s;
if(s.find(".")!=s.npos)
{
int ans=s.find(".");
string q,p;
q=s.substr(0,ans);
p=s.substr(ans+1,s.size()-ans);
zero(q);
zero(p);
reverse(q.begin(),q.end());
reverse(p.begin(),p.end());
zero(q);
zero(p);
cout<<q<<"."<<p<<endl;
}
else if(s.find("/")!=s.npos)
{
int ans=s.find("/");
string q,p;
q=s.substr(0,ans);
p=s.substr(ans+1,s.size()-ans);
zero(q);
zero(p);
reverse(q.begin(),q.end());
reverse(p.begin(),p.end());
cout<<q<<"/"<<p<<endl;
}
else if(s.find("%")!=s.npos)
{
int ans=s.find("%");
string q;
q=s.substr(0,ans);
zero(q);
reverse(q.begin(),q.end());
cout<<q<<"%"<<endl;
}
else
{
zero(s);
reverse(s.begin(),s.end());
cout<<s<<endl;
}
return 0;
}
CSL 的字符串
链接:https://ac.nowcoder.com/acm/contest/551/D
来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 524288K,其他语言1048576K
64bit IO Format: %lld
题目描述
CSL 以前不会字符串算法,经过一年的训练,他还是不会……于是他打算向你求助。
给定一个字符串,只含有可打印字符,通过删除若干字符得到新字符串,新字符串必须满足两个条件:
- 原字符串中出现的字符,新字符串也必须包含。
- 新字符串中所有的字符均不相同。
- 新字符串的字典序是满足上面两个条件的最小的字符串。
输入描述:
仅一行,有一个只含有可打印字符的字符串 s。
|s|≤105|s|≤105
输出描述:
在一行输出字典序最小的新字符串。
示例1
输入
复制
bab
输出
复制
ab
示例2
输入
复制
baca
输出
复制
bac
备注:
ASCII字符集包含 94 个可打印字符(0x21 - 0x7E),不包含空格。
#include <iostream>
#include<string>
#include<stack>
#include<string.h>
using namespace std;
stack<char>q;
int v[1000];
bool vis[1000];
string t;
int main()
{
string s;
cin >>s;
for(int i=0;i<s.size();i++)
v[s[i]]++;
q.push(s[0]);
v[s[0]]--;
vis[s[0]]=true;
for(int i=1;i<s.size();i++)
{
v[s[i]]--;
if(!vis[s[i]])//保证如果s[i]之前没有比重复的字母更小的字母的话,删去后边出现的重复字母
{
while(!q.empty()&&q.top()>s[i]&&v[q.top()]>0)
{//出现了比重复字母更小的字母,那么要删去前边的重复字母
vis[q.top()]=false;
q.pop();
}
q.push(s[i]);
vis[s[i]]=true;
}
}
while(!q.empty())
{
t+=q.top();
q.pop();
}
for(int i=t.size()-1;i>=0;i--)
cout<<t[i];
return 0;
}

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









